

1. 变量对象和堆内存
变量对象是生成执行上下文时创建的一个特殊的对象。JS的基础数据类型(number,string,boolean,undefined),按值访问,通常保存在变量对象中。JS的引用数据类型(如对象、数组、函数, new Number(4))的值保存在堆内存中,而JS不允许直接访问堆内存,只能通过引用访问。引用其实就是保存在变量对象中的一个地址指针,这个地址指向堆内存中的实际值。
🌰:
var a = 0 // 变量a和值0都寸与变量中对象
var b = 'string' // 变量b和值0都寸与变量中对象
var c = null // 变量c和值0都寸与变量中对象
var d = { m: 1 } // 变量d存在于变量对象中,{m: 1} 作为对象存在于堆内存中
var e = [1, 2, 3] // 变量e存在于变量对象中,[1, 2, 3] 作为对象存在于堆内存中
var f = function () {...} // 变量f存在于变量对象中,function作为对象存在于堆内存中
内存存储方式示意图:
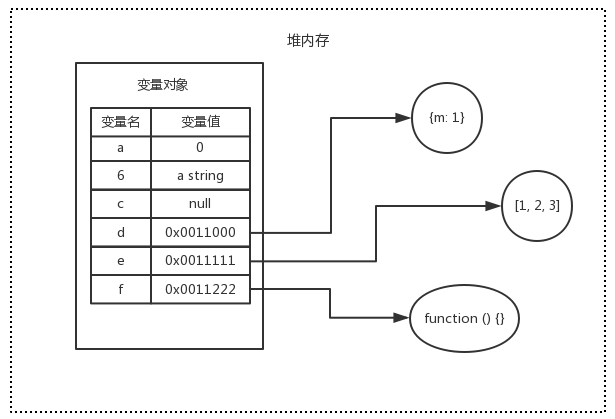
访问引用数据类型时,实际上是先从变量对象中获取地址,再根据地址从堆内存中取值。
🌰:
// demo1
var a = 20;
var b = a;
b = 30;
console.log(a) // 20
// demo2
var m = { a: 10, b: 20 }
var n = m;
n.a = 15;
console.log(m.a) // 15
2. 执行上下文
执行上下文可以理解为代码的运行环境,会形成一个作用域。JS主要有两种执行上下文:
- 全局执行上下文:JS代码运行起来会首先进入全局执行上下文
- 函数执行上下文:当函数被调用执行时,会进入当前函数的执行上下文
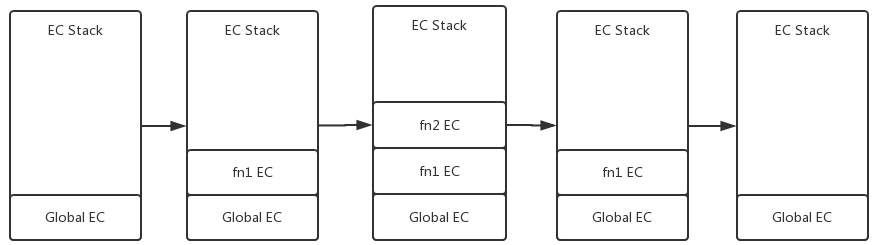
JS代码通常是函数内调用函数,必然产生多个执行上下文,JS引擎会以栈(FILO)的方式来处理他们,这个栈就是函数调用栈(callstack)。函数调用栈栈底定是全局执行上下文,栈顶是当前正在执行的函数的执行上下文。栈顶的上下文执行完之后,该上下文出栈。
🌰:
function fn1 () {
var a = 1
function fn2 () {
const b = 2
console.log(a + b)
}
fn2()
}
fn1()
Call Stack示意图:
浏览器查看代码执行过程的call stack:
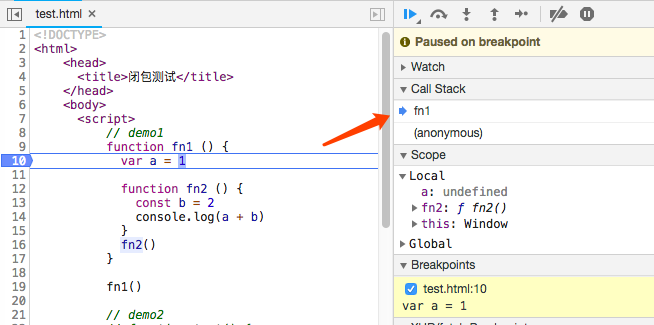
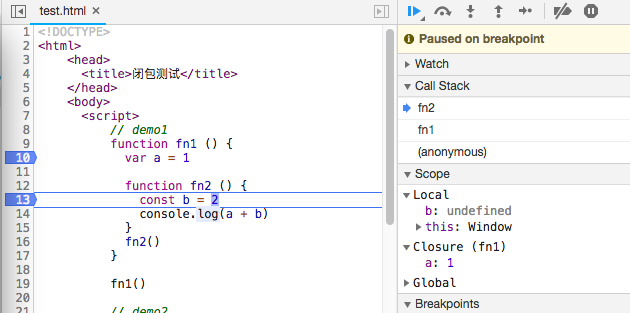
3. 变量对象(Variable Object)
本节探讨的时生成执行上下文的时候都做了什么。 执行上下文生命周期:
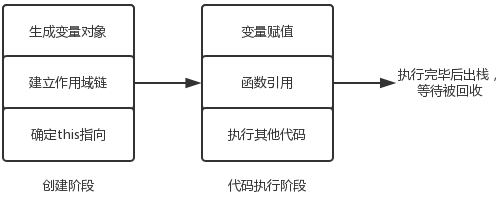
执行上下文的创建阶段其实就是为代码执行做准备,准备工作就包含了生成变量对象。 变量对象的生成过程包含以下三个步骤。

- 建立arguments对象。
- 检查函数声明(function):在变量对象中以函数名建立一个属性,属性值为指向该函数所在内存地址的引用。如果函数名的属性已经存在,那么该属性将会被新的引用所覆盖。
- 检查变量声明(var):每找到一个变量声明,就在变量对象中以变量名建立一个属性,属性值为undefined。如果该变量名的属性已经存在,为了防止同名的函数被修改为undefined,则会直接跳过,原属性值不会被修改。
- 注意:函数声明比变量声明优先级高。
创建完成之后在代码执行阶段,JS解析器就能在变量对象中找到声明的变量或者函数,进行一系列的操作。现在明白变量提升咋个回事儿了吧。
🌰:
function fn1 () {
console.log(a) // undefined
console.log(fn2) // f fn2(){}
console.log(fn2()) // 2
var a = 1
function fn2 () {
return 2
}
console.log(a) // 1
}
fn1()
创建阶段:fn1执行上下文,创建阶段生成变量对象
fn1EC = {
VO: {
arguments: { ... },
fn1: <fn1 reference>,
a: undefined
}
...
}
执行阶段: VO --> AO(Active Object)
fn1EC = {
AO: {
arguments: { ... },
fn1: <fn1 reference>,
a: 1
}
...
}
执行阶段变量对象变为活动对象,可以访问属性了,上面代码相当于
function fn1 () {
function fn2 () {
return 2
}
var a
console.log(a) // undefined
console.log(fn2) // f fn2(){}
console.log(fn2()) // 2
a = 1
console.log(a) // 1
}
fn1()
- 注:全局上下文VO = window
4. 作用域链
第二节讲到在执行上下文的创建阶段,有三个任务:创建变量对象、建立作用域链、明确this指向。 本节讲作用域链。
作用域链,是由当前环境与上层环境的一系列变量对象组成,它保证了当前执行环境对符合访问权限的变量和函数的有序访问.
🌰:
var a = 1
function fn1 () {
var b = a + 1
var c = 3
function fn2 () {
var c = 4
return b + c // 6
}
fn2()
}
fn1()
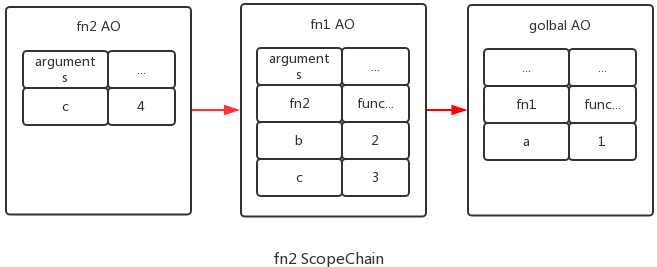
我们知道,fn1能够访问全局变量a,fn2能够访问fn1中的变量b、c,但是c使用的是本作用域的c,反过来fn1不能访问fn2种的变量c,JS引擎是如何实现变量的查找?答案就是:沿着作用域链查找
fn2 Scope Chain:
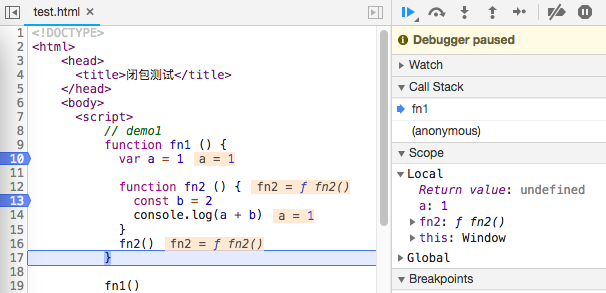
5. 闭包
JS的函数外部无法读取到函数内的局部变量:
function fn1() {
var a = 1
console.log(a)
}
console.log(a) // error
如何从外部读取局部变量:
var a = 1
function fn1 () {
var b = a + 1
function fn2 () {
console.log(b) // 2
console.log(c) // error: c is not defined
}
return fn2
}
var res = fn1()
function fn3() {
var c = 3
res()
}
fn3()
在函数fn1内部定义一个函数fn2,fn2内访问fn1的变量,并把fn2作为返回值,在外部执行fn2的时候,就访问到fn1的局部变量了。 这就形成了闭包,有些地方称fn1是闭包,有的称fn2为闭包, 我们和chrom保持一致,称父函数fn1为闭包。
闭包可以理解为集中技巧,使得在函数外部能够访问函数内部的变量,且这些变量的值始终保存在内存中。例子中,fn1是fn2的父函数,而fn2被赋给了一个全局变量,这导致fn2始终在内存中,而fn2的存在依赖于fn1,因此fn1也始终在内存中,不会在调用结束后,被垃圾回收机制回收。
此时:fn2 ScopeChain = [fn2 VO, fn1 VO, global VO], 因此fn2能访问b, 但不能访问c, fn1执行完了,fn1已经出栈,但是fn1并没有被释放。
所以,使用闭包会造成内存占用较大。
练习:
for (var i=0; i<5; i++) {
setTimeout( function () {
console.log(i);
}, i*1000 );
}
输出什么??
如何改动实现输出1,2,3,4,5: 每次循环将i值保存到了闭包中:
for (var i=0; i<5; i++) {
setTimeout((function (i) {
function () {
console.log(i);
}, i*1000 )
}(i)
}
闭包最大的应用就是模块化。
