

前言
你想一夜暴富吗?你想一夜成名吗?你想开兰博基尼泡妞吗?你想拿钞票点烟吗?你想成为世界主宰吗?不,我不想,我只想把我喜欢的教程转成PDF文件,放到我的手机或者阅读器中,什么?你也想,那来吧,本文将介绍:
- 通过命令行将某网站的内容转成PDF文件
- 通过NodeJS爬虫将某网络教程(例如阮一峰的JavaScript教程和ES6教程等)转成PDF文件
- 通过NodeJS或者VScode插件将Markdown文件转成PDF文件
依赖模块
cheerio是nodejs的抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现。适合各种Web爬虫程序
Request是Node.js中的一个模块,目标是用最可能简单的方式,在Node.js发起HTTP请求。此外也支持最新的HTTPS协议
一个通过网址将网页转成PDF的命令行工具,NodeJS版本要大于8.6.0,如果出现安装失败,请翻墙后再安装
将markdown文件转成PDF文件
命令行导出PDF文件
percollate是一位外国友人做的一个命令行工具,是对puppeteer做了一层封装,暴露出常用的API, 我们来看下文档中的例子
一个页面
percollate pdf --output some.pdf https://example.com
多个页面
percollate pdf --output some.pdf https://example.com/page1 https://example.com/page2
操作很简单是不是,哇哦,我们是不是可以美滋滋的将自己喜欢的文章转成PDF在手机或者电脑上看了,嗯,没错是的,不过这也就能玩个文章,如果想拿下整个网站的所有文章就心有余而力不足了,比如下面的这个
NodeJs爬虫将整个网站生成PDF文件
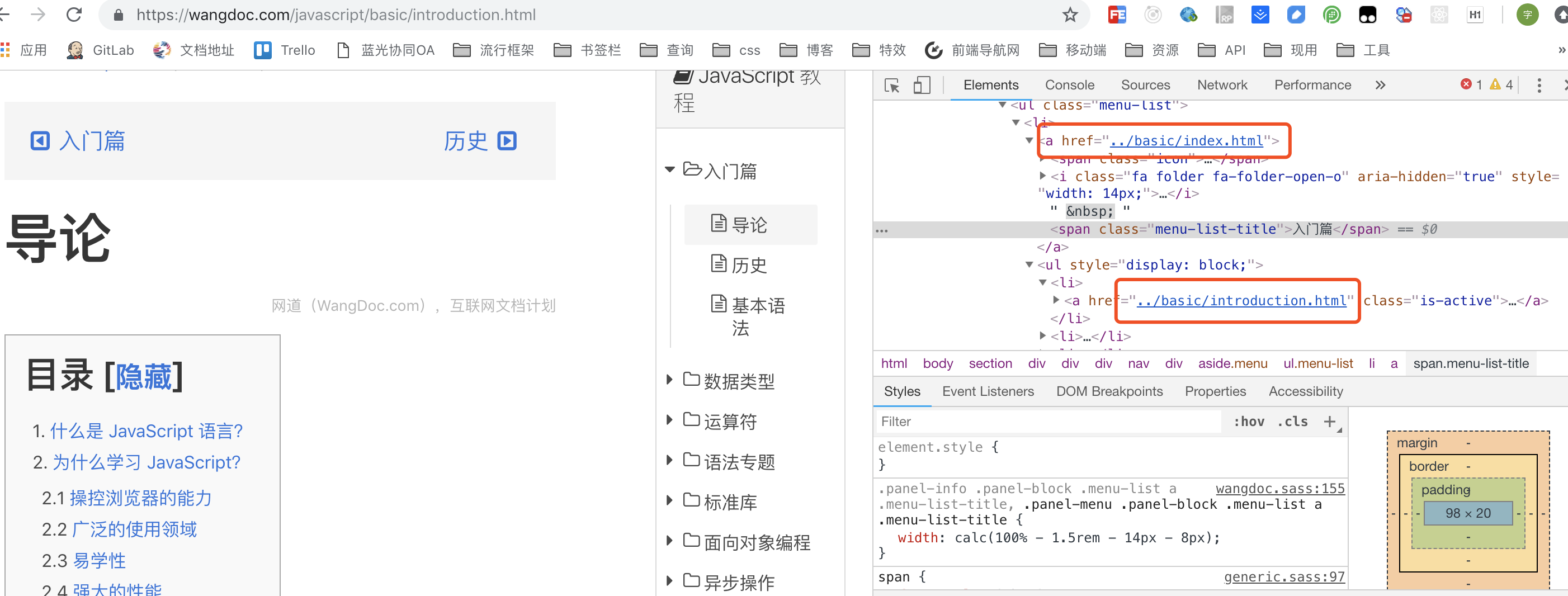
首先我们来瞅一眼阮大神的Javascript教程的网站,地址为 wangdoc.com/javascript/…, 我们能看到网页右边为所有章节的导航,打开Chrome开发者工具,我们能看到
那么我们想在NodeJs中使用percollate,该如何操作呢?前面已经说了percollate是个命令行工具,文档上并没有告诉我们怎么在Node环境中怎么调用,难道我们要放弃,直接用puppeteer或者phantomjs去撸吗?怎么可能?秉着你是NodeJs的包,肯定能在NodeJs环境跑的宗旨,我把percollate打印出来瞅瞅

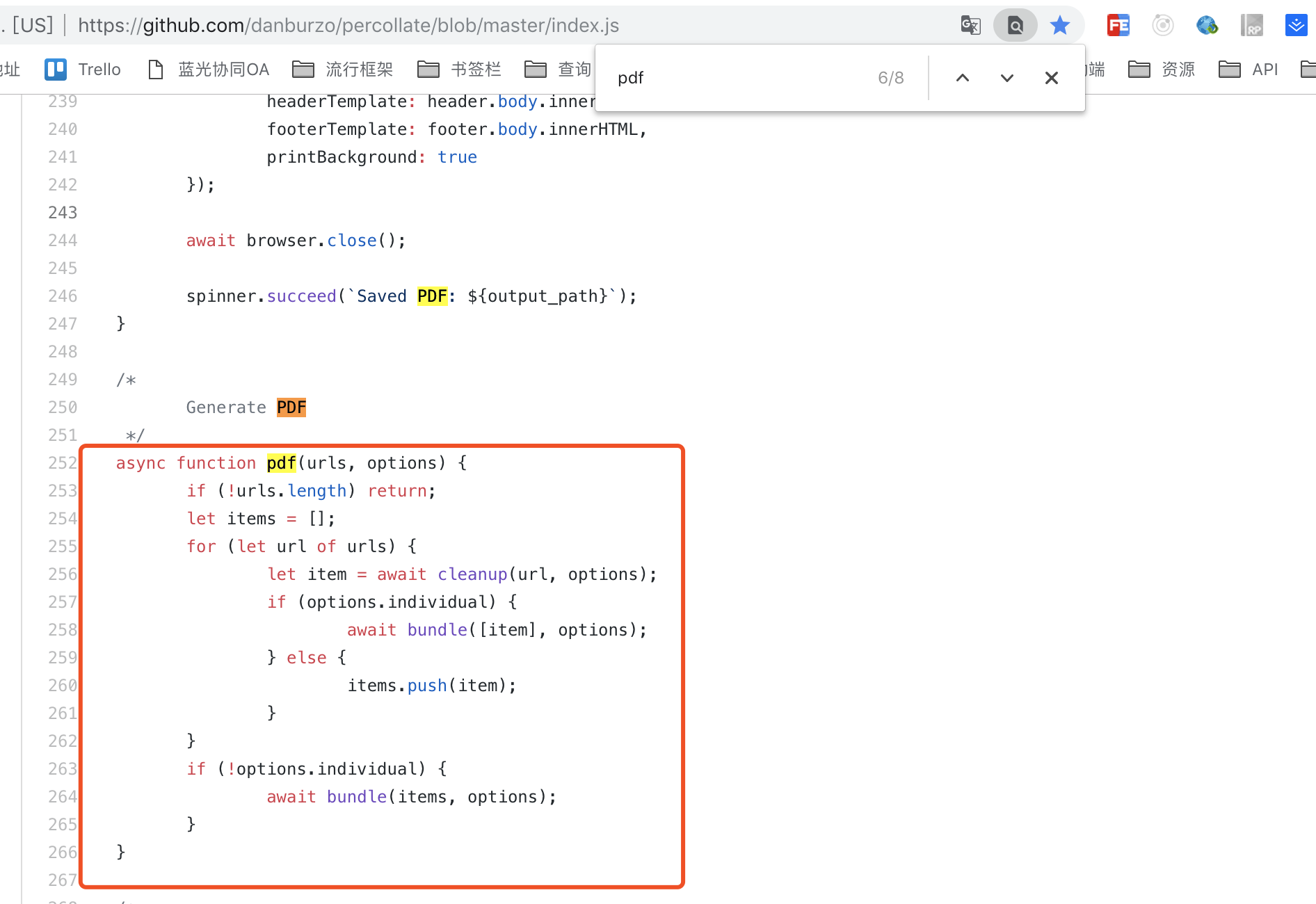
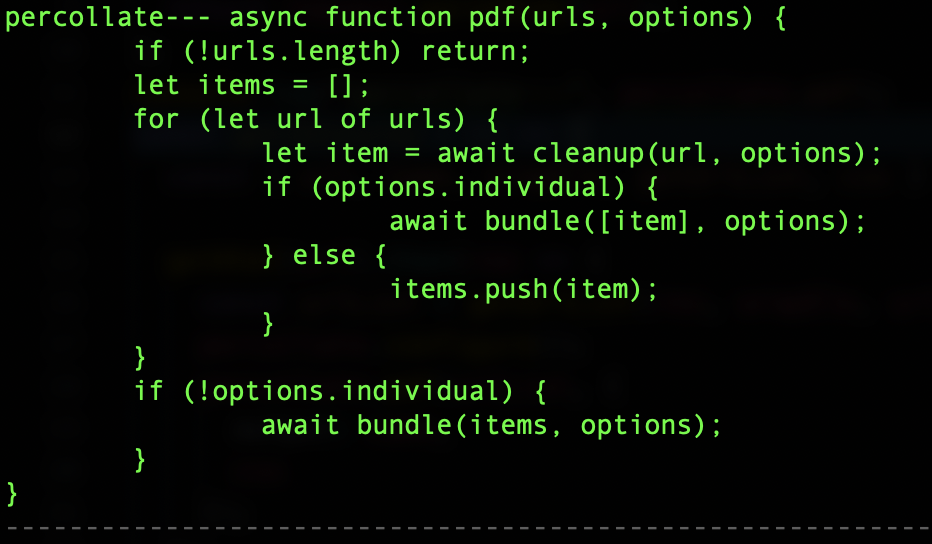


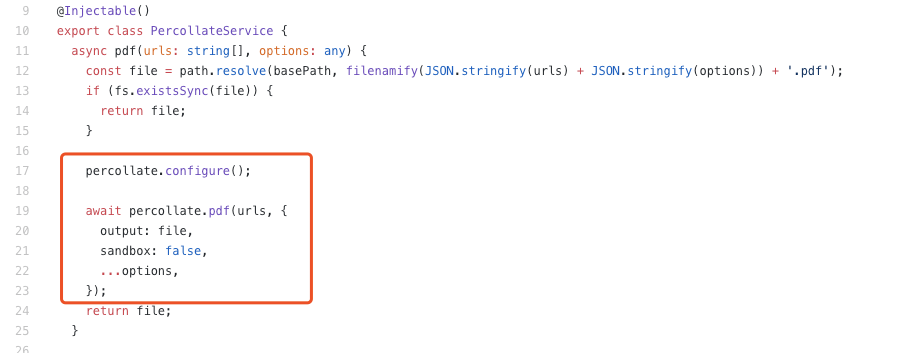
这下真的美滋滋了,当然这样生成的PDF文件使用的是默认配置,如果你想生成适配你手机或者阅读器的PDF文件,就需要添加你的自定义配置了,
percollate.pdf(urlList, {
output: "阮一峰JavaScript教程.pdf",
css: "@page { size: A6 landscape } html { font-size: 18pt } "
});
关于css属性的文档,点击查看。
完整代码
新建一个util.js,增加一个用于发送请求的方法:
const request = require("request");
function parseBody(url) {
return new Promise((resolve, reject) => {
request(url, (error, res, body) => {
if (!error && res.statusCode === 200) {
resolve(body);
} else {
reject("获取页面失败" + error);
}
});
});
}
module.exports = {
parseBody
};
新建config文件,添加配置
// 阮一峰JS教程
const javaScriptCourse = {
url: "https://wangdoc.com/javascript", // 要爬取的网站地址
name: "阮一峰JavaScript教程.pdf", // 导出的文件名字
wrapEle: ".menu-list", // 导航父元素的class
css: "@page { size: A6 landscape } html { font-size: 18pt } ", // 生成pdf的大小和字体
getUrlList(body, ele, url) {
// 从返回的html中获取章节地址
let urlList = [];
$(body)
.find(ele)
.eq(0)
.find("li a")
.each((i, v) => {
const pathStr = $(v).attr("href");
const path = pathStr.slice(pathStr.indexOf("/"));
urlList.push(url + path);
});
return urlList;
}
};
新建index.js为项目的入口文件,引入相关依赖
const request = require("./util"),
percollate = require("percollate"),
markdownpdf = require("markdown-pdf"),
fs = require("fs"),
{ javaScriptCourse, es6Course, baseOpt } = require("./config");
const getHtml = url => {
return request.parseBody(url);
};
const getJSCourse = () => {
const { url, name, wrapEle, getUrlList, css } = javaScriptCourse;
getHtml(url).then(res => {
const urlList = getUrlList(res, wrapEle, url);
percollate.configure();
percollate.pdf(urlList, {
output: name,
css
});
});
};
// 生成pdf文件
getJSCourse()
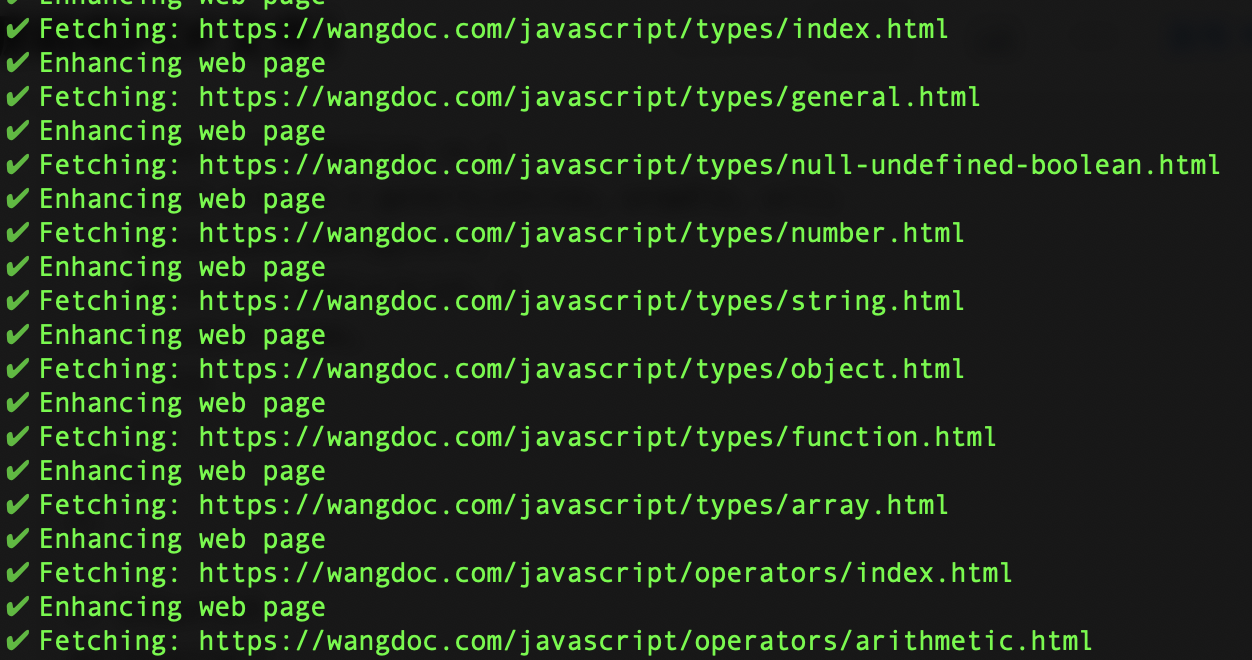
以上是全部代码,总共不超过80行,执行之后,我们能看到终端打印的日志
将Markdown文件生成PDF
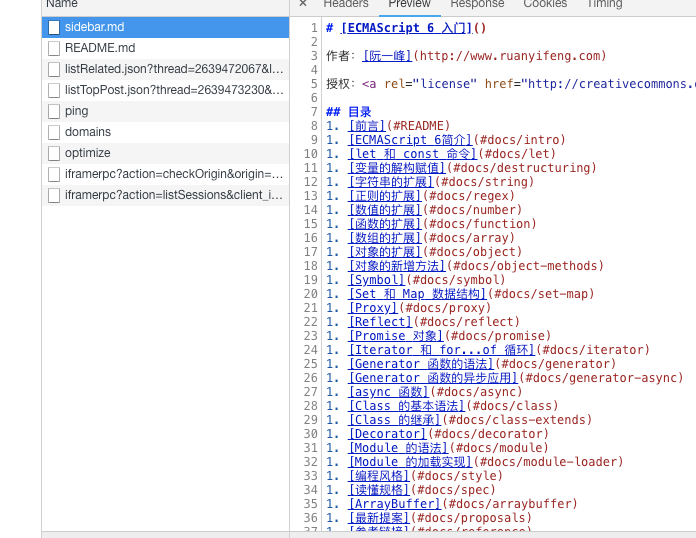
这个以阮一峰大神ES6教程为例,地址为:es6.ruanyifeng.com ,打开网站后,我们发现,网站是通过接口动态生成内容的,网站请求返回的内容都为Markdown,
percollate.configure();
percollate.pdf(urlList, {
output: name,
css: baseOpt.css,
sandbox: true // 设置为false,动态生成的内容抓取不到
});
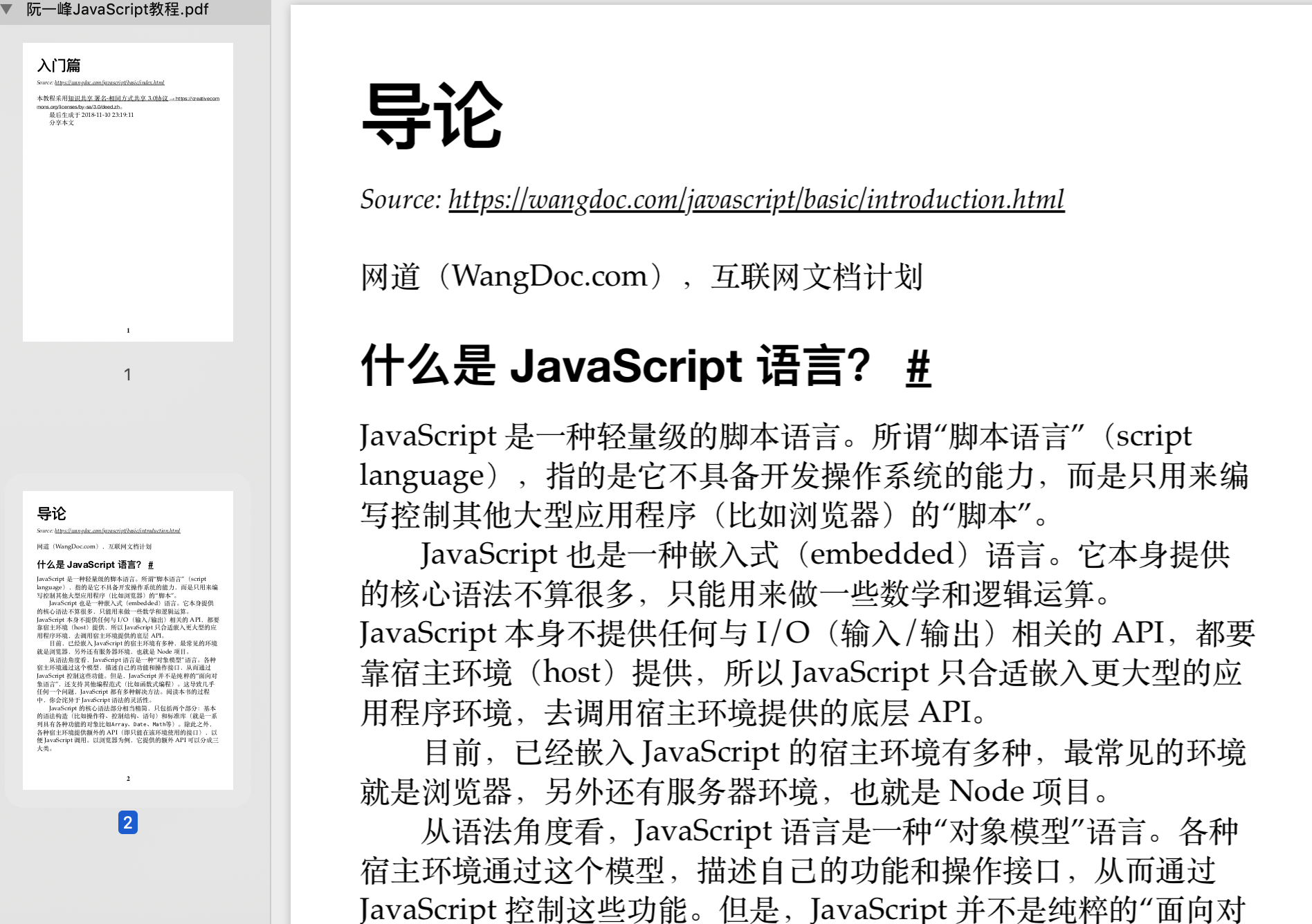
生成的PDF文件如下,没有转成我们希望的样子,内容为原始的Markdown语法

percollate添加某个配置之后,是否就可以完美的将Markdown转成PDF文件,因为我知道Node有一个包markdown-pdf可以将Markdown转成PDF文件,还知道VScode有一个插件也可以将Markdown转成PDF文件,这样的话,我们首先要生成一个包含所有内容的Markdown文件,Node的fs模块可以很容易的完成这件事情,生成Markdown文件以后,再使用上面讲述的两种方法将Markdown转成PDF即可,代码如下
const urlList = getUrlList(res, wrapEle, url);
const reqList = [];
urlList.forEach(v => {
console.log("请求地址---", v);
reqList.push(getHtml(v));
});
console.log("开始发出请求...");
Promise.all(reqList)
.then(arrRes => {
console.log("所有请求都成功了---");
const md = arrRes.join(" ");
// console.log(md);
const optPath =
"/Users/apple/Documents/my/LearningLog/NodeJs/网页生成pdf/";
fs.writeFileSync(`${name}.md`, md, function(err) {
if (err) {
return console.error(err);
}
console.log("数据写入成功!");
});
console.log("开始生成pdf文件...");
markdownpdf({
paperFormat: "A6"
// paperOrientation: "landscape"
})
.from(`${optPath}${name}.md`)
.to(`${optPath}${name}.pdf`, function() {
console.log("生成pdf文件成功");
});
})
.catch(err => {
console.log("请求报错---", err);
});
关于使用VScode将Markdown文件转为PDF的方法,我这里就不赘述了,参考markdown-preview-enhanced 。
写在最后
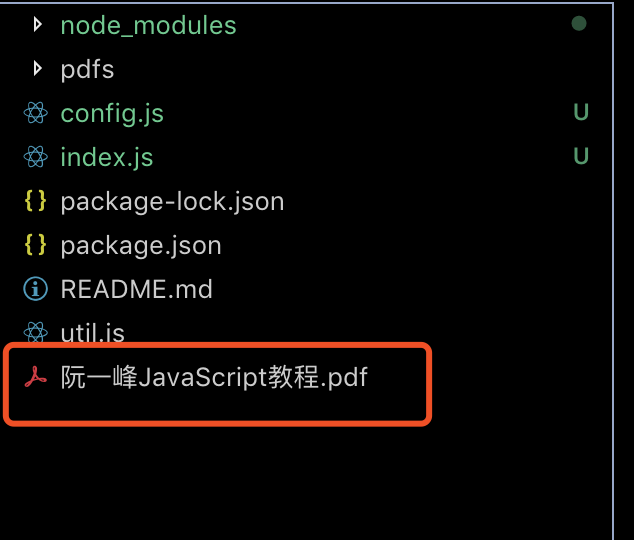
本文的所有代码以及生成的PDF文件都在下面的地址,后续会更新更多的大佬免费教程的PDF文件
已生成的免费网络教程PDF文件:
如需调整大小、字体或者样式,请fork源码自行生成。
