

前言:
本文非常浅显易懂,可以说是零基础也可快速掌握。如有疑问,欢迎留言,笔者会第一时间回复。本文代码存于github
一、分析表情包网址
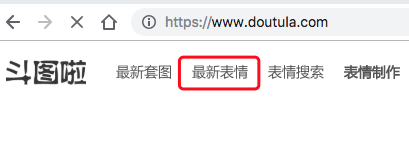
第一页:www.doutula.com/photo/list/… 第三页:www.doutula.com/photo/list/… 第四页:www.doutula.com/photo/list/…
可以看出,page 的值跟点击的页数有关,因此,我们就拿到了要爬取的 url
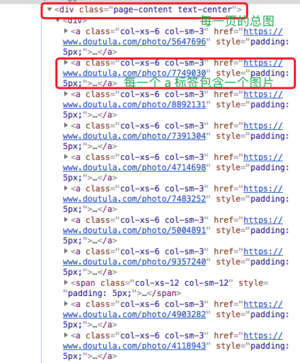
2、打开检查元素,可以看到html源码

二、实践
a、获取 img 标签取到的 img 有 gif 的信息,我们需要过滤掉
imgs = html.xpath("//div[#class='page-content text-center'//img[@class != 'gif']")
b、接下来是获取图片的 url,上面的代码如下:
for img in imgs:
# print(etree.tostring(img))
img_url = img.get('data-original') # 不知道为什么多个 !data ,去掉它
img_url = img_url.replace("!dta", "")
c、截取后缀,得到文件名,并保存
alt = img.get('alt') # 获取图片名字
# alt 可能某些情况下需要处理非法字符(这些字符不可以当做名字保存)
suffix = os.path.splitext(img_url)[1] # 对url进行分割,取数组中的第二位,得到后缀名
filename = alt + suffix
request.urlretrieve(img_url, 'images/' + filename) # 保存图片
这样下来,就已经可以快速保存你所需要的表情包了,论斗图,谁比得过你

全部代码如下:
def parse_page(url):
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
response = requests.get(url, headers=headers)
# print(response.text) # 打印html源代码
html = etree.HTML(response.text)
imgs = html.xpath("//div[@class='page-content text-center']//img[@class!='gif']")
for img in imgs:
# print(etree.tostring(img))
img_url = img.get('data-original') # 不知道为什么多个 !data ,去掉它
img_url = img_url.replace("!dta", "")
# print(img_url)
alt = img.get('alt') # 获取图片名字
# alt 可能某些情况下需要处理非法字符(这些字符不可以当做名字保存)
print(alt)
suffix = os.path.splitext(img_url)[1] # 对url进行分割,取数组中的第二位,得到后缀名
filename = alt + suffix
print(filename)
request.urlretrieve(img_url, 'images/' + filename) # 保存图片
def main():
for x in range(1,51): # # 爬取前50页 range(1,3) 这里相当于 1 2
url = 'https://www.doutula.com/photo/list/?page=%d' % x
parse_page(url)
break
最终结果:

区区20几行代码,就可以造就一个斗图西方求败的你,赶快来行动吧!

当然,还可以更高级一点,就是利用多线程,异步进行爬取、下载,几秒钟就可以下载到上千张的表情包!相关代码,我也放到了 github ,需要的朋友自行去look look!
更多精彩内容,请关注公众号 “bigdeveloper”——程序员大咖秀
