

废话:
之前蹭上了BERT的热度,粉以个位数每天的速度增长,感谢同学们的厚爱!弄得我上周本来打算写文本分类,写了两笔又放下了,毕竟文本分类有很多SOTA模型,而我的研究还不够深入。。慢慢完善吧,今天看到一篇You may not need attention,写attention起家的我怎么能放过,立刻打印出来读了读,下面详细说一下。其实每次在写的过程中我也在思考,希望一会儿可以给自己和大家带来不同的东西。
正文:
1. 背景
其实no attention只是个噱头,这篇文章的本质是去除encoder-decoder的架构,用简单的LSTM去实现seq2seq任务。我当时看到这个网络结构的第一想法,就是好奇之前的seq2seq任务是如何做的,于是这次我们先来看一下seq2seq模型的发展脉络。
Seq2seq模型的出现主要是为了解决翻译任务。最初的机器翻译是词典规则匹配,之后是统计机器学习方法,主要是基于概率的思想。12年深度神经网络开始兴起后,图像、语音识别都取得了很好的进展,其中有一位Schwenk在文章Continuous Space Translation Models for Phrase-Based Statistical Machine Translation中提出了基于神经网络的翻译模型,如图:
Schwenk在文章中介绍了三个模型结构,具体内容我没有细读,但是从左往右我们可以看到两种思想:hidden layer的加入和time step上的依赖。
在这篇文章的奠基下,Bengio在13年发表了文章Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation,提出了沿用到现在的encoder-decoder框架。后来的seq2seq任务,默认代表机器翻译、文本摘要等输入输出不等长的任务,而对于这种任务默认使用encoder-decoder架构。
故事的之后,就有了facebook的convolutional seq2seq模型和RNN encoder-decoder + Attention和Transformer。
相信大多数在最近一两年接触NLP的同学们都一样,学到seq2seq任务的经典模型们,也没想太多就直接用了。直到今天读这篇论文时我才发现,在之前竟没有想过为什么不能用LSTM去解决seq2seq问题,即使想到了,也会因为输入输出长度不一致而让自己忘记这个疑问。
之所以要写这篇论文详解,不是他文章难懂需要我来翻译,而是想写下来告诉自己:不要让自己的思维限定在别人的框架里,遵守规则不牛b,定义规则才是。
上面说了太多废话,也可能有不对的地方,希望有经验的老玩家指教。
接下来我们一起好好看一下作者如何用LSTM去解决不等长输入输出的问题。
2. 模型
2.1 预处理
翻译的一个难点在于两种语言的语序可能不一样,面对这样的问题,作者对训练数据都进行了对齐处理,图示比较直观:
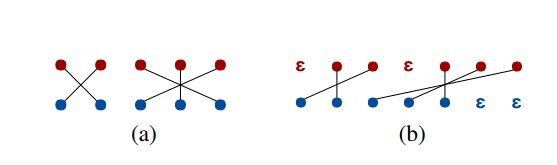
红色是target句子,蓝色是source,作者用了两种预处理方法:
- 遍历target句子,一旦碰到target word在对应source word之前的,就添加占位符
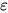 直到两者位置一样或者target word位置偏后。这个算法很直观,看图就懂了。
直到两者位置一样或者target word位置偏后。这个算法很直观,看图就懂了。 - 直接在target句子前插入0-5个占位符,这样的话之后的占位符就会少一些。
注:处理完target句子之后,作者直接在source句子结尾补齐占位符
2.2 Aligned Batching
经过预处理步骤之后,target句子和source句子的长度就一样了,作者直接把一个batch的句子收尾拼接程一个长字符串,然后像训练语言模型一样去训练。(这一节没什么创新点)
2.3 Model
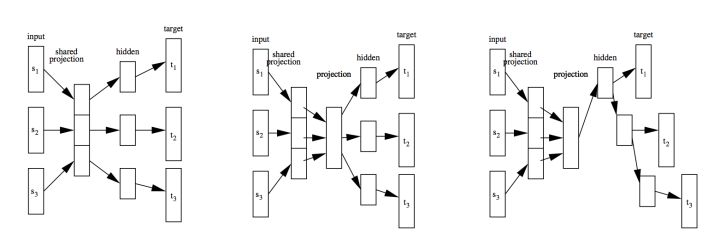
模型结构很好理解,如图:
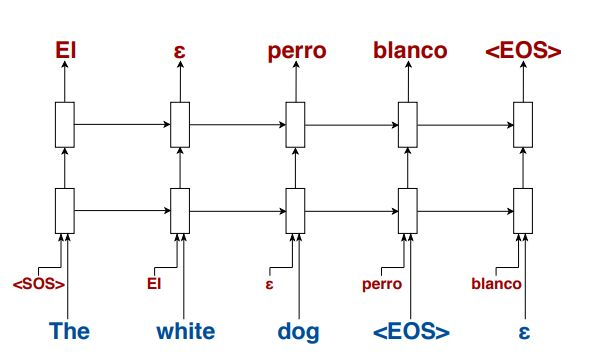
每个time step(比如输入white时),将El和white分别进行embedding,一个词的维度为E,两个的拼起来变成2E,然后经过两层LSTM,之后通过FC层把维度变成E维,就可以在target语言的词向量矩阵里找到概率最大的词了。
以上模型中包含着三个embedding matrix:source language的input(用来embed 单词white),target language的input(用来embed单词El),target language的output(用来embed单词perro)。值得注意的是,作者使这三个词向量矩阵保持相等。也就是西语和英语中相同词根的词向量是相同的。(具体请看评论区大佬留言)至于为什么这么做,是因为参考了其他研究,说这样做的效果会更好。说不定这就是模型有效的原因,因为它其实是预测之前出现的word。那么问题来了,如果目标语言或者源语言有各种近义词,那预处理阶段做这个词典的代价就比较大了。
2.4 Decoding
解码阶段,作者对beam search做了两个改进,可以看到作者碰到问题和解决的思路:
- Padding limit:如果后面一直解码成占位符怎么办?那就限制占位符的个数,超了之后概率就置为0。但是最先开始的占位符不能限制,模型可能一直在酝酿之后的大招。
- Source padding injection(SPI):作者在模型训练时发现,如果碰到了source句子的结束标志<EOS>,那大概率也会输出<EOS>。所以作者的解决方法是拖延,在输出句子的<EOS>之前找位置插入一些占位符,这样输出的句子就会更长。
3. 优缺点
3.1 优点
- 跳出encoder-decoder框架,解决了如何用RNN语言模型的架构做seq2seq任务
- 训练消耗的资源更少了,每一步预测只需要上一步的结果
- 预测更加快速,输入一个词就能立刻给出输出,不像encoder要都过完一遍才可以
- 在预测长句子的任务上表现更好
3.2 缺点
- 效果其实没有那么好。。。
- 比起经得起考验的SOTA模型,这个模型还需要多多改进,经得住其他seq2seq任务的考验
4. 总结
这篇文章没什么难理解的东西,但是却让读论文很少的我陷入了思考。其实encoder-decoder的intuition很简单,就是读完一句英文,理解了,再用中文说出来。加attention也好,就是我虽然理解了,但翻译的时候还要回去看一眼斟酌一下。那这篇文章,其实就是我读一个词看看能翻译就先翻译了,不能翻译我先差不多理解意思留到后面翻译。都是符合我们平常翻译的逻辑,直觉上讲得通的东西。
很多时候可能跳出原有的框架,去思考解决遇到的问题,就会有独特的contribution,希望大家在学习工作生活中多多思考,以上。
【参考资料】:
