

上一篇transformer写了整整两周。。解读太慢了。。主要是自己也在理解,而且没有时间看源码,非常惭愧,如果哪里说错了希望大佬们可以提醒一下
之前细细研究了attention和transformer之后,universal transformer读了一遍就理解了,缺乏之前基础的童鞋们请先移步:
Universal Transformer的产生是因为Transformer在实践上和理论上的两个缺点(参考上篇文章),universal代表的是computationally universal,即图灵完备(参考Transformer详解第三节)。主要的改动就是加上了循环,但不是时间上的循环,而是depth的循环。注意到Transformer模型其实分别用了6个layer,是fixed depth,而universal中应用了一个机制对循环的次数进行控制。
1. 模型结构
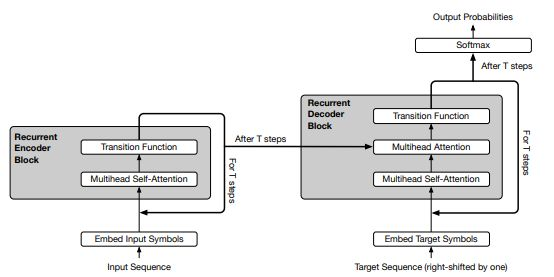
模型的结构还是和传统Transformer很相似,这里就不重复解读了,主要讲一下universal transformer的几点改动:
1.1 Recurrent机制
在Transformer中,input在经过multihead self-attention后会进入fully connected层,这里则进入了Transition层,通过一个共享权重的transition function继续循环计算:
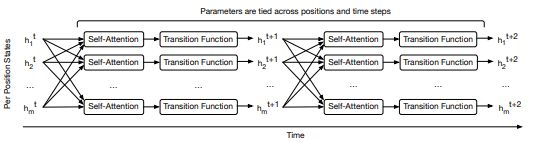
这里纵向的position指的就是一个序列中各个symbol的位置(也就是在rnn中的time step),横向的time指的主要是计算上的先后顺序,比如一个序列 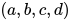 ,先经过embedding表示成
,先经过embedding表示成 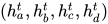 ,在经过一层attention+transition表示成
,在经过一层attention+transition表示成 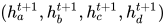 。如果是rnn,那就要先计算
。如果是rnn,那就要先计算 ,再计算
和
,而transformer的self-attention可以同时计算
,再计算t+1的。
这样,每个self-attention+transition的输出 可以表示为:
这里Transition function可以和之前一样是fully-connected layer,也可以是separable convolution layer。
1.2 Coordinate embeddings
Transformer的positional embedding只用考虑symbol的position就可以了,这里又多了一个time维度,所以每一次循环都会重新做一次coordinate embedding,图上没有表示出来,需要看源码确认一下。Embedding公式如下:
暂时还没想清楚为什么这么运算,想清楚了说一下。。
1.3 Adaptive Computation Time (ACT)
ACT可以调整计算步数,加入ACT机制的Universal transformer被称为Adaptive universal transformer。要注意的细节是,每个position的ACT是独立的,如果一个position a在t时刻被停止了, 会被一直复制到最后一个position停止,当然也会设置一个最大时间,避免死循环。
2. 总结
Universal Transformer对transformer的缺点进行了改进,在问答、语言模型、翻译等任务上都有更好的效果,成为了新的seq2seq state-of-the-art模型。它的关键特性主要有两点:
- Weight sharing:归纳偏置是关于目标函数的假设,CNN和RNN分别假设spatial translation invariace和time translation invariance,体现为CNN卷积核在空间上的权重共享和RNN单元在时间上的权重共享,所以universal transformer也增加了这种假设,使recurrent机制中的权重共享,在增加了模型表达力的同时更加接近rnn的inductive bias。
- Conditional computation:通过加入ACT控制模型的计算次数,比固定depth的universal transformer取得了更好的结果
细读下来,还是有很多细节值得深挖,我浅挖了一下,各位感兴趣的再去多看看
划重点:computationally universal, inductive bias, coordinate embedding
以上。
【参考资料】:
