

内容来源:2018 年 10 月 24 日,VMware高级讲师寇雪旭在“VMware技术专题分享”进行《NSX高级路由架构》演讲分享。IT 大咖说作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:12502 | 32分钟阅读

摘要
本次主题,第一个单元我们会跟大家简要的去介绍一下传统数据中心路由架构面临的挑战。第二个小节是NSX的路由组件。第三个小节是NSX的逻辑路由,涉及到等价多路径及HA。
传统数据中心路由架构面临的挑战
首先请大家来看一下我们今晚的第一个话题,在传统数据中心当中路由架构面临的挑战。其实我们在座的很多朋友包括我在内,以前都是从事物理的数据中心架构设计。
随着虚拟化的发展,当前的软件定义数据中心,虚机的网关成为一个非常重要的设计架构。传统物理的数据中心当中,虚拟机的网关通常是指向到我们的物理的路由器或者说三层交换机。
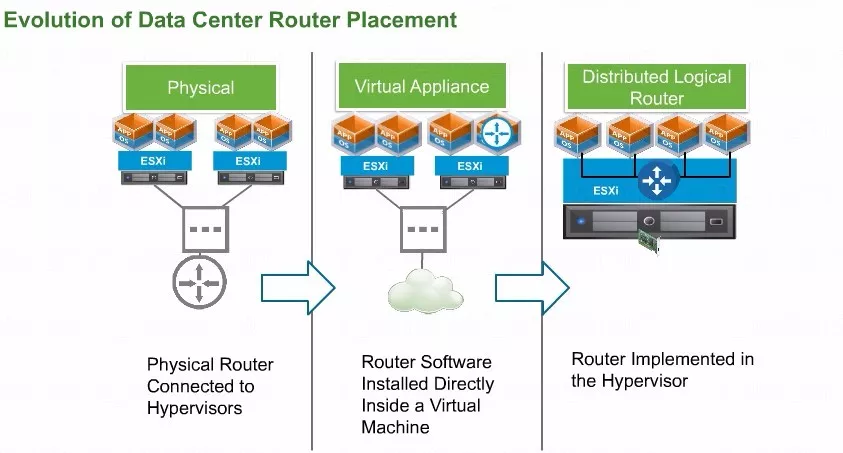
上图是数据中心的路由位置进化史。最早的时候,应该是图中左侧的这张图,可以看到物理数据中心当中有很多的ESXI,ESXI内部运行了用户的虚机。传统情况下ESXI的内部可以创建VDS,就是我们所说的分布式虚拟交换机, 或者VSS(虚拟标准交换机),在没有NSX介入的情况下,VDS包括VSS上面都可以创建基于虚拟机的VLAN的端口组。
虚拟机的网关是指向外围的路由器上面,所以一旦我们需要跨VLAN的来进行通信,即便两个虚机是在同一个Hypervisor内部流量也会势必的形成发卡。再可以看一下中间的这张图,其实不管是vmware的NSX,还是一些其他厂家,都应该有虚拟机版的路由器,虚拟机版的路由器仍然会产生发卡的流量。
最右侧这张图应该是NSX非常核心的一个功能,它通过部署一个控制平面的组件,可以把路由网关分布式架构的能力部署到多个ESXI内部,在ESXI的Kernel中生成一致的分布式网络。
假设右侧图中的这台ESXI内核当中是有一个软件的分布式逻辑路由内核,这时虚机的网关只要各自的指向到分布式逻辑路由左侧和右侧的端口,两个不同网段的虚机就直接可以在内核当中完成高速转发。
当然这种东西向的三层转发并不仅仅只限于同一个Hypervisor内部,即便虚拟机跨了不同的Hypervisor,借助这个一致的分布式逻辑路由网关仍然能够完成高效的三层通信。
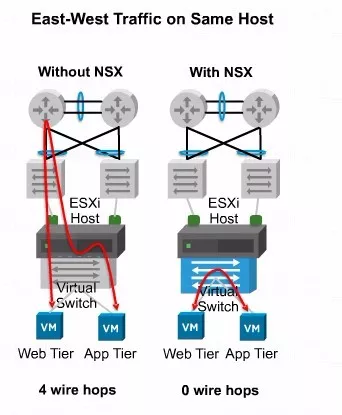
关于传统物理数据中心当中的发卡的问题,上面这张图应该画得非常清晰。图中这两个虚拟机,它们是在同一个主机内部,
但是却属于不同的VLAN。由于虚机的网关是我们的路由器,所以通信过程中会形成发卡。
那大家可以想象一下,在实际场景当中, Hypervisor的数量是非常多的,而且每个Hypervisor内部虚拟机的数量也应该是非常多的。
这些东西方向的流量,频繁要借助物理网络来转发,效率势必会不好。如果借助高效的基于Hypervisor内核的分布式逻辑路由组件进行虚机之间的通信,效果会好很多,
而且这种一致性的分布式三层路由的网关架构,还有一个巨大的好处。从虚机的角度来讲,它的缺省网关指向分布式逻辑路由器接口的地址,虚机如果发生故障转移的时候,虚机的网关不会有任何变化,因为在新的vShpere主机内部,仍然是有一致的分布式逻辑路由,从网关的IP到接口的MAC地址都没有任何的变化。
这种模式同样适用于vMotion,如果我们对虚拟机进行集群之间做迁移,由于分布式网关的存在,无论虚机vMotion到哪台主机,三层网关仍然不会有任何变化。
再次声明一下发卡的问题。大家可以看到我们上面的图,如果两个虚机在没有NSX分布式逻辑路由介入的情况下,分别处于不同的ESXI主机,他们之间的三层转发仍然是要经过我们物理路由器发卡的流量。
如果左侧ESXI主机上的一个虚拟机要和右侧ESXI主机上的一个虚拟机,在不同的网段当中通信,借助分布式逻辑路由,即便我们的柜顶交换机是二层交换机,也无所谓,只要能够保证这两个主机的VTEP的可达,信息就可以借助分布式逻辑路由,直接来完成转发。
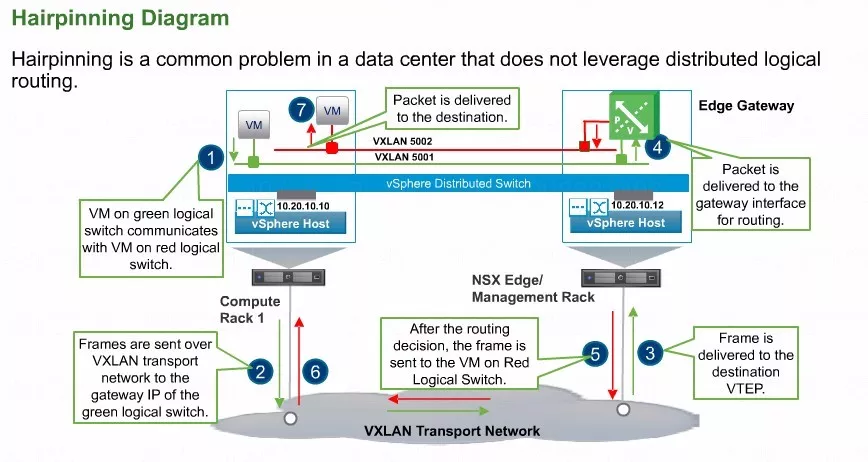
上面这张图,其实是通过NSX的软件平台,部署了一个叫边界服务网关虚拟机。
大家都知道ESG主要是完成南北方向的路由转发,把它部署的这个位置,其实只是想探讨一下虚机版路由器发卡的问题。
当然了我们东西向的路由转发,像图当中所示,5001 VXLAN、VXLAN 5002两个不同的虚拟机,建议还是通过分布式逻辑路由,直接完成基于Hypervisor内核的高速转发。
假设在当前的展示系统的左右这两个Esxi内核中,并没有去部署分布式逻辑路由,而是部署了一个边界服务网关的虚拟机,此时ESG并不会跟左侧的两个虚拟机在同一个Hypervisor内部。
信息如果到了右侧的ESG,可以做一个常规路由。在这种架构当中,ESG根本无需配置任何路由协议,就可以把报文路由到接口,但这个信息并不能直接发给虚拟机,会被我们右侧主机的VTEP通过VxLan再次封装发到我们的左侧。左侧Hypervisor的VTEP接收到这个报文以后,将VXLAN的外部报头头去掉,内部的信息直接丢给这个虚拟机。
所以大家可以看到,虽然说在没有部署分布式逻辑路由的情况下,NSX的另外一个组件,ESG也能够完成东西向路由转发的功能,但是这个并不是我们推荐的分布式报文转发方式。
NSX路由组件

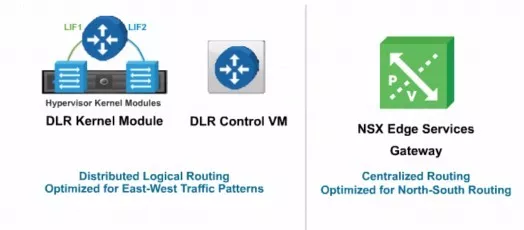
首先看一下当前的这张图,图中蓝色的图标叫分布式逻辑路由器。NSX的软件平台能够支持两种路由的子系统,一个是分布式逻辑路由,第二个是边界服务网关。
我们首先来观察一下分布式逻辑路由,它能够完成数据中心当中东西向的高速三层路由转发,可以在逻辑空间当中完成路由。这个逻辑空间指的就是我们的NSX的内部。
对于分布式逻辑路由来讲,它除了基础的像静态路由以外,大家还可根据情况去配置动态路由。但需要我们注意的是,动态路由并不是在分布式逻辑路由的内核当中启动的,而是在分布式逻辑路由的控制平面,就是后面我们要说到的分布式逻辑路由控制虚机上来启动
分布式逻辑路由控制虚拟机,可以通过比较复杂的方式,将路由信息,通过NSX的另外一个组件去更新到每个ESXI内核当中的分布式逻辑路由转发模块。
再看一下右侧的这个对象,它被称之为叫边界服务网关,这个组件可以完成南北向的路由。它主要是用于数据中心当中的南北方向的路由转发,能够完成物理数据中心到NSX软件定义数据中心之间的路由报文转发,起到一个承上启下的作用。
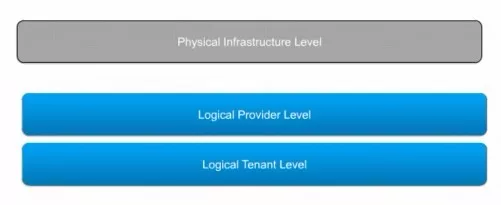
请看上图。物理网络的基础架构是灰色的框,在物理网络的数据中心中可能会启动OSPF甚至BGP,所以NSX的路由体系在最终接入到物理网当中的时候,我们都要考虑一下整体路由协议策略的问题。
从NSX的角度来讲,它的路由体系就应该包含蓝色的第一个框,叫做逻辑的供应商级别的路由,属于ESG上的路由。第二个蓝色框是逻辑的租户级别路由,属于DLR级别路由。
那从当前的这个图当中可以看到,中间灰色线是一个分水岭,左侧是分布式逻辑路由,从NSX角度来讲,它的管理平面是NSX管理器。它的控制平面是图中所示的组件,其实体以虚机的方式呈现,我们称之为叫分布式逻辑路由控制虚拟机。
分布式逻辑路由控制虚拟机的源程序其实就是大家所熟知的OVF格式的文件,在NSX Manager 磁盘中。NFX Manager通过注册到VC的API,可以把OVF格式的DLR控制虚拟机部署到VCenter Server集群中预置的主机上。
通常可能我们在网络架构设计的时候会单独设计一个集群用于承载DLR控制虚机以及ESG。
需要注意的是DLR控制虚机只是我们的分布式逻辑路由的控制平面,大家可以认为它是DLR接口包括路由的一个配置入口点,它自己保持这些信息,其实并不做真的报文转发,真正的数据平面的报文转发,仍然是由数据转发平面当中的DLR的Kernel来实现。这个Kernel是叫一个DLR的内核模块。
在做NSX主机准备的时候,NSX管理器会将一组VIB推送到VCenter server,由VCenter server安装到目标的ESX的主机内部。
如果VIB安装成功,在目标的ESX的内核当中会生成很多NSX的内核模块,当中就包含了我们的分布式逻辑路由转发模块。
这个模块的名字在文档中也称之为叫VDR-B,VDR的全称就是虚拟的分布式路由,减号B的含义是VDR的内核可以完成桥接的功能。
左侧图的设备就是在ESXI内核中的VDR-B的软件模块,我们可以在软件允许的上限之内灵活的配置LIF口。
图中左右两侧端口都连接了一个逻辑交换机,虚机的网关分别指向到LIF1和LIF2,这样就可以完成高速的三条转发。
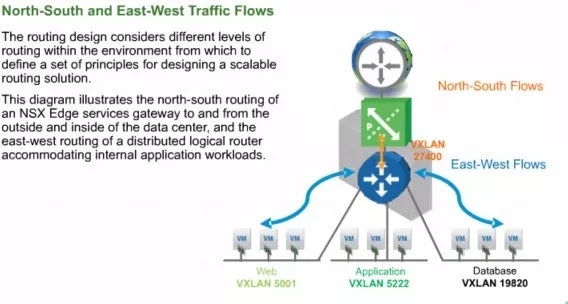
这张图应该在官方的安装配置手册当中出现的频率非常高。一般意义来讲,这是一张逻辑转发图。
分布式逻辑路由是深蓝色的模块,连接了我们内网的虚拟机。从内网的角度来看,它设定了三个LIF口,每个LIF口分别作为web、APP、db的三层网关。
从web到APP或到db,在没有防火墙阻隔的情况下,虚机直接就可以通过我们的路由模块来完成高速的三种转发。
当然了这三个不同部门的虚拟机,有可能是在同一个Hypervisor内部。因为Hypervisor内核当中的DLR的kernel直连了这三个网段,所以报文转发没有任何的发卡,直接就可以在内核当中高效的完成。
从动态路由的角度来讲分布式逻辑路由控制虚拟机,是能够支撑IGP的,也就是大家熟知的OSPF协议是OK的。
如果有研究NSX的BGP的配置的话朋友,可能会知道在ESG包括DLR的控制虚机上,其实是可以设定BGP的基础参数。
需要我们注意的是ESG跟我们的物理网络,可以考虑使用OSPF或BGP。在NSX国内落地的项目当中比较多的应该是使用我们的内部网关路由协议。

以上是DLR的一些简要属性。分布式逻辑路由的控制平面是一个设备,名字叫DLR-C-VM。它的数据转发平面叫DLR的内核,也称之为叫VDR的kernel。
借助分布式逻辑路由,Hypervisor可以完成高性能低延迟的第一跳路由转发,而且它可以近乎线性的随着主机的数量增加而增长。
如果两台ESXI内部的虚机之间的通信是在同一个Hypervisor上,那在主机内核内部就可以完成转发。如果在两个不同的ESXI主机上,报文转发会牵扯到当前这两台主机的DLR的内核,但是不会牵扯到第三台ESXI主机,所以这个转发速度是非常理想的。
分布式逻辑路由还能够支持八条等价多路径。每个ESXI主机创建的分布式逻辑路由最多可以有一千个分布式逻辑路由的实例。
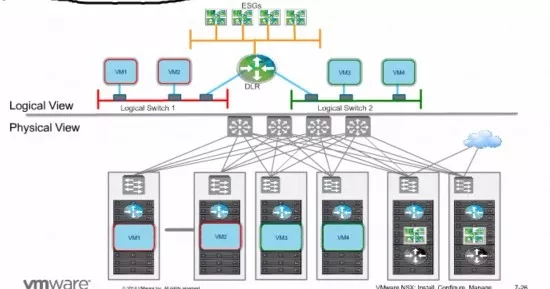
如何理解一千个分布式逻辑路由的实例呢?在云环境中经常需要租户有一整套的SDN的财产,比如软件的逻辑交换机,租户专用的路由模块,甚至一些VPN、防火墙之类组件。
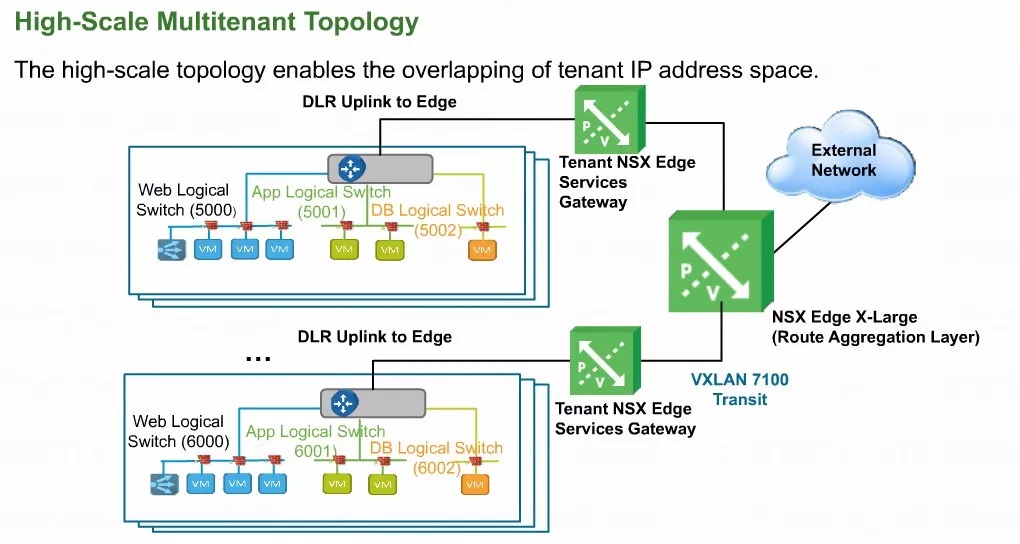
以当前这张多租户的路由拓扑为例。在NSX系统内部假设有两个租户,租户A有一个分布式逻辑路由接口分别连接了三个不同的网段。而另一个租户B想要有一个自己专用的分布式逻辑路由。
而从基础架构的角度来讲,NSX可以在一个ESXI主机内部部署多个分布式逻辑路由模块,来满足在同一个Hypervisor内部多租户的需求,就相当于在一个ESXI内部可能会有多个租户的组件。
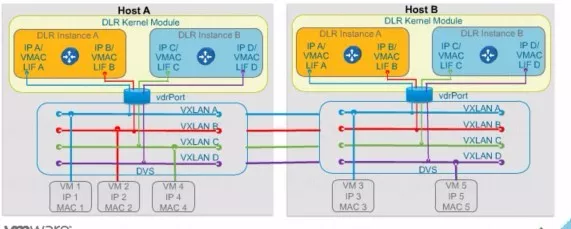
上面这张图就清晰的描述了前面提到的观点,前面理论当中的观点是每个ESXI极限情况下可以创建将近一千个的分布式逻辑路由。注意,这是内核当中的组件,并不是虚拟机。
图中左边ESXI主机中黄色的图标代表,ESXI的分布式逻辑路由内核,这个内核也称之为叫VDR内核。
当前的ESXI内部有两个分布式逻辑路模块,那左边的这个租户的分布式逻辑路由A有两个接口,一个是蓝色的,一个是红色的。可以看到租户A的两个虚机之间的通信可以通过它内核当中的分布式逻辑路由A完成。
在同一个Hypervisor当中还有一个虚拟机VM4,它显然是属于另外一个租户的。它所连的VXLAN是这个绿色的这条,显然连接到了另外的一个分布式逻辑路由下面。
那租户之间的隔离呢不单是可以解决地址重叠的问题,而且从路由架构的角度来讲,也可以变得更加的清晰。

DLR instances是内核当中的数据平面的组件,内核的控制平面的组件是DLR控制虚拟机,内核当中的这数据转发平面的组件可以创建许多的LIF口。
每个LIF口可以作为虚机所在VXLAN的网关,LIF口的ip可以根据情况规划,极限情况下,分布式逻辑路由的一个实例可以创建将近一千个左右的LIF口。
其实在生产环境当中,未必能够使用到如此之多的LIF口,但它的弹性还是给大家保留了未来扩展的空间。
虽然理论上每个ESXI内核当中,可以创建将近一千个左右的DLR instances,每个DLR的实例又可以有将近一千个左右的LIF口,但每个主机内部的LIF口并没有到1000×1000。实际上是有另外一种限制,就是在每个主机内部,DLR LIF口的数量也不能超过1万个。
另外我们北向的ESG是一个虚拟机,它的源文件其实也是在NSX Manager中。需要注意的是这个ESG的虚机,在通过NSX Manager部署的时候,图形界面允许大家选择四种不同的尺寸。
因为ESG本身是一个VM,如果选择最小的尺寸,那么部署完毕之后,只有一个CPU,内存是512兆。最大尺寸下CPU默认有6个,内存是8G。所以建议在一些极小的环境,包括POC的环境中部署ESG的时候,为了降低资源消耗,使用最低尺寸,但是在生产环境当中,我们还是建议选择大一点的ESG尺寸,这样的话大家可以获得一个较佳的吞吐量。
ESG还可以完成我们内部的分布式逻辑路由到外部的物理设备之间的转发,这是因为ESG是一个虚拟机,从vSphere的观点上来看,虚机最多有十张网卡,也称之为叫vNIC。
理论来讲,每一个vNIC可以连接一个端口组,如果是跟内网通信,应该连接基于vLAN的端口组,如果跟外网通信,我们要连接VXLAN端口组。
那除了我们肉眼可见的十个端口以外,大家如果去编辑ESG的某个接口的话,在接口类型当中还可以选择上联或者说内联的口。另外还有一种特殊类型的端口,叫主干端口,这个端口上不能配置任何的ip地址,取而代之的,大家可以在这个主干类型的端口上划分多个子接口,有点类似于我们物理网络当中那个单臂路由的概念。子接口的数量有一个比较硬性的限制,整个ESG最多只能够创建200个子接口。相对的ESG也可以挑选最多八条相等价值的路径放在路由表当中。
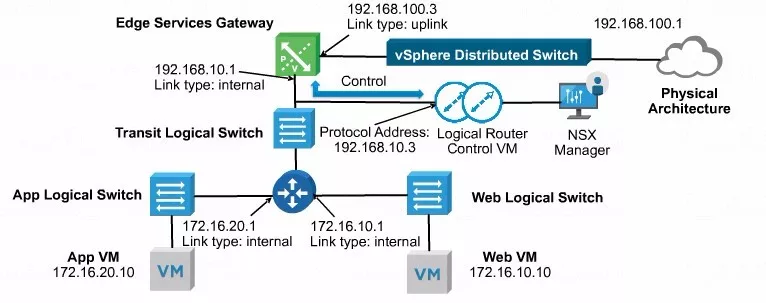
上图是一个标准的视图,分布式逻辑路由有三个LIF口,作为APP包括web这两个虚机的对应的网关。分布式逻辑路由除了能够完成东西向的路由转发以外,它的北向的接口通过VXLAN能够直接达到ESG的internal端口。ESG通过外网口应该接入了VDS上基于VLAN的端口组。
我们的物理网络不用感知VXLAN的存在,物理网络当中的节点要跟内部的虚机通信,其实就是VLAN先进来到达ESG,然后ESG将它路由到我们的分布式逻辑路由,由分布式逻辑路由找到内部的虚拟机。
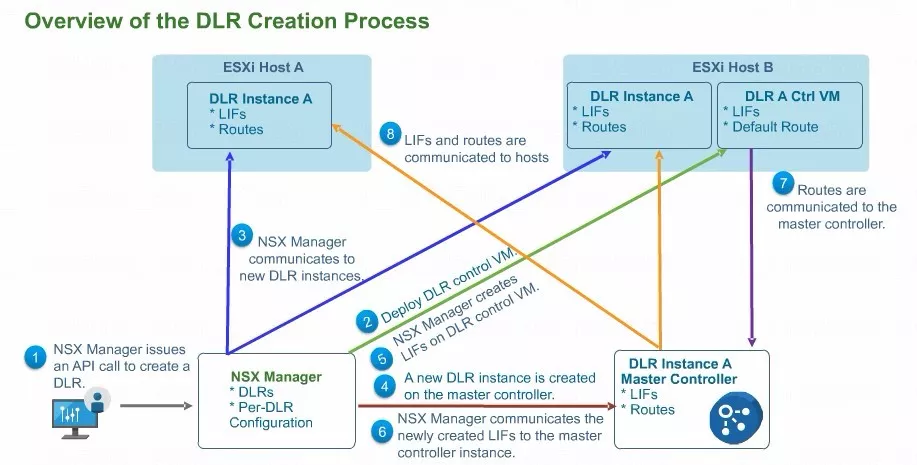
这张图就有些深度了,它阐述了分布式逻辑路由创建的过程。左下角这个图标代表的是NSX管理器,由它去发API创建分布式逻辑路由,配置参数由我们的NSX Manager保存。
大家应该记得分布式逻辑路由两个平面的组成,其中一个平面是分布式逻辑路由控制虚机。图中2号绿线表示的就是NSX Manager通过API要求在某一个ESXI上面创建一个分布式逻辑路由控制虚拟机。实质上是通过VC完成,这是第二步。
前面提到过NSX Manager 跟每个主机的就是消息总线之间是有连接的。所以你会看到编号3那条线的NSX Manager 会通过消息组件,要求ESXI在DLR内核中创建出DLR instances。
编号5这条线通过CP组件创建LIF口的信息。虽然DLR的控制虚机能够保存分布式逻辑路由的LIF口的信息,但DLR控制虚机显然不能作为虚机端到端转发的一个数据平面,所以要把LIF口的信息。以及路由的信息传导到ESXI内核当中的分布式逻辑路由模块当中。
编号6这条线NSX Manager也会把LIF口的信息推送到master的控制器。DLR控制虚机如果从北向的ESG接收到了路由,那么这个路由会通过DLR控制虚机跟控制器之间的通道,被刷新到NSX的控制器中。
由NSX控制器跟每个主机的TCP 1234(两个橙色的线路)把接口包括路由信息刷新或同步到每个主机的内核当中。
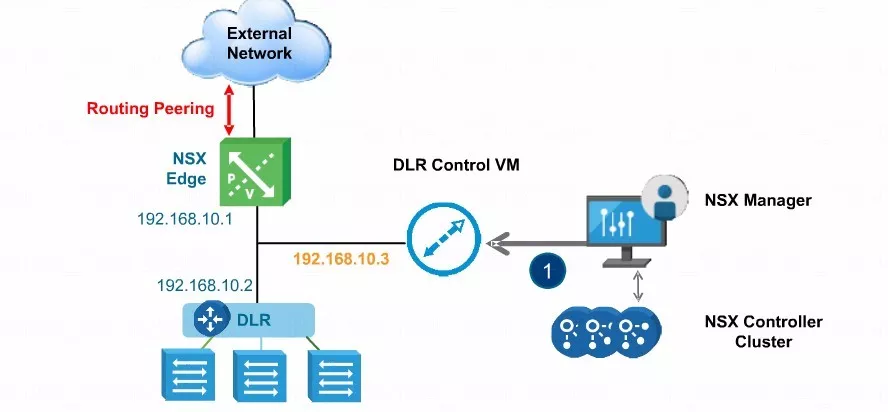
上图也是在三方手册中常见的。NSX Manager创建了分布式逻辑路由控制区机包括NSX控制器。控制器通过tcp的1234能够跟每个ESXI的NETCPA建立通信,未来控制器也要把路由更新到主机内部。
我们可以看到ESG北向是跟物理网络建立通信,与内部的DLR控制虚机之间也能够建立动态路由直接关系的。
所以大家可以看下3的位置,我们在部署分布式逻辑路由控制虚机的过程当中,部署完毕后可能后期要配动态路由,无论是OSPF还是BGP都要给这个DLR控制虚机创建一个叫协议地址的参数。这个地址其实就是我们图中的192.168.10.3,它用于跟我们北向的ESP建立路由的这种关系。
如果ESG把动态路由传导到DLR控制虚拟机,路由就会被发到NSX控制器,由NSX控制器将它刷新到每个主机内核当中的分布式逻辑路由模块当中,图中的4就是控制虚机把路由推送到控制器,5是控制器把路由刷新的这个主机内核当中的分布式逻辑路由,6在做南北向转发的时候,仍然是由我们数据平面的DLR到ESG再到Web。
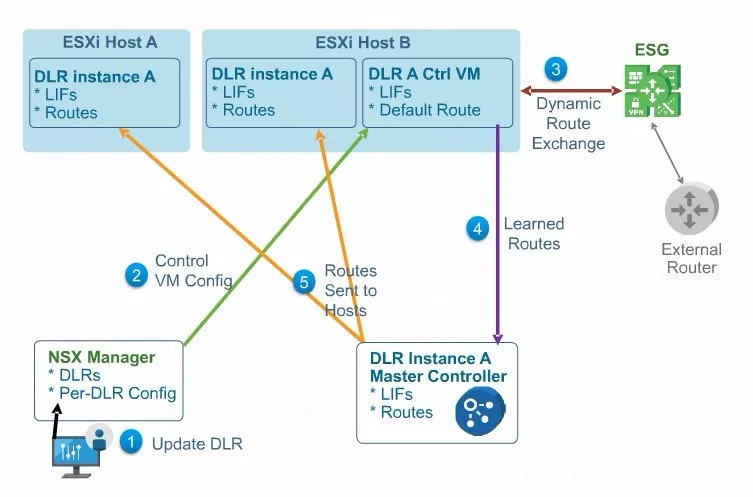
上图中NSX Manager是DLR Controll VM的管理平面,给DLR创建路由或者静态的任务都要通过NSX Manager完成。
NSX Manager针对DLR控制虚机的路由参数的更改,会传导到DLR控制的虚机。
假如管理器给DLR控制虚机重新配了一种动态路由,动态路由和DLR控制虚机以及ESG之间就会建立了连接关系,由于 ESG跟我们的物理路由器建立了连接关系,物理网络当中的路由表借助ESG可以传到DLR控制虚机,DLR控制虚机会把收到的路由沿着跟控制器之间的链路发送到NSX控制器中。
另外NSX控制器收到路由后,会把路由通过tcp的1234刷新到每个主机内核当中的分布式逻辑路由,完成更新。
从逻辑的角度来讲,红色网端内部的虚机要跟绿色网络内部的相互通信,没有必要借助ESG,直接通过Hypervisor内核当中的分布式逻辑路由,即可完成高效的三层转发。但这其实是一个逻辑视图,从Physical的角度来讲,VM1要通信的对象VM3很有可能是在另外的一个主机上。
此时进行通信,本质上是由最左侧机架当中的主机通过分布式逻辑路由模块,并经过VTEP的封装发到我们接收端虚机所在的ESXI,由ESXI的VTEP解封装,跳过接收端的分布式逻辑路由,直接丢到接收端的虚拟机。
看似简单的一个分布式逻辑路由转发,真正在物理网络当中是要穿过物理网络。前提是这两个虚机不在同一个Hypervisor,也不在一个主机内部。
如果在同一个Hypervisor就不用出内核,如果在同一个机架内部,连柜顶交换机都不会出,直接在交换机的端口之间完成转发。
我们可以配置很多租户,租户甚至可以有自己专用的ESG,配置一个我们物理网络当中非常普遍的协议,公有地址到私有地址转换。
这样的话公网设备就无需去接收用户内部私有网络路由,直接通过公网地址就可以访问到租户的内部。
NSX逻辑路由的ECMP与HA
ECMP可以类比传统物理路由,传统路由的原点路由器到达目标的路径中间有多条价值相等开销的路由,从源到目标的报文转发,可以按照负载均衡来把流量均衡到不同的物理链路中。所以ECMP的功能可以被GSG,及分布式逻辑路由来实现。
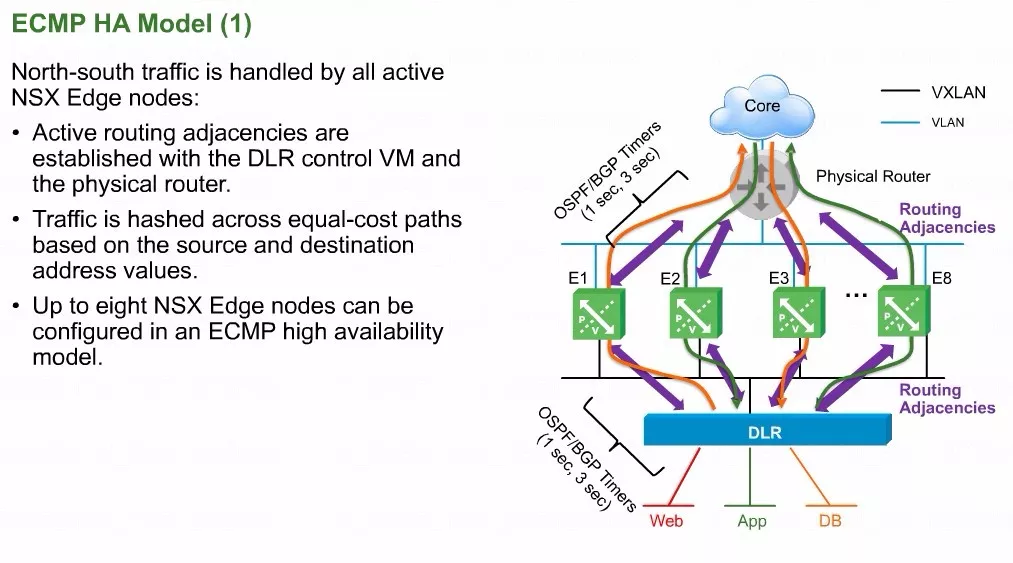
不管是分布式逻辑路由还是ESG都具备最大八条等价多路径的路由能力。图中蓝色块代表分布式逻辑路由,它在去往物理数据中心的途中,中间会可能经过Edge 1到Edge 8,这就叫做等价多路径。
ESG虽然是一个虚拟机,但是它应该被管理员有目的去放置到不同的Hypervisor,这样的话南北向的流量就可以经由不同节点的ESXI来向外转发。
所以DLR到达ESG之间是由ECMP存在的,ECMP的功能在DLR的控制平面上是可以开启或关闭的。当要启动ECMP的时候,请务必打开DLR控制虚机上的等价多路径的功能。
另外ESG它作为南北向的一个中转节点,到达物理网络,很可能也是有多条相等开销路径。所以这个等价多路径理论也适用于ESG,等价多路径主要是为了提高南北向通信的可用带宽,而且也可以在ESG万一发生故障的时候,减少宕机时间。
从负载均衡的角度来讲,如果ESG到外网有多条相等开销路由的话,那么它内部实际上是有一个算法来完成报文的等价多路径
分布式逻辑路由器上,如果到达外网有多条路由的话,它其实也有一个关于等价多路径的算法,叫源IP与目标IP哈希。
如果web当中有两个虚拟机A、B访问的物理网络是同一个对象,那很有可能是因为等价多路径,A被DLR哈希把流量发到E1去访问到外部,B通过E2访问外部,由此实现出口方向的路由的负载均衡。
当然入口方向不是NSX说了算。通过核心网络返回到内部的虚拟机,由于第一跳是物理路由器,物理路由器会使用它内部的等价多路径算法来考虑报文是从哪一个ESG进入到NSX的系统,这个时候很可能会产生等价多路径导致的非对称路径路由。
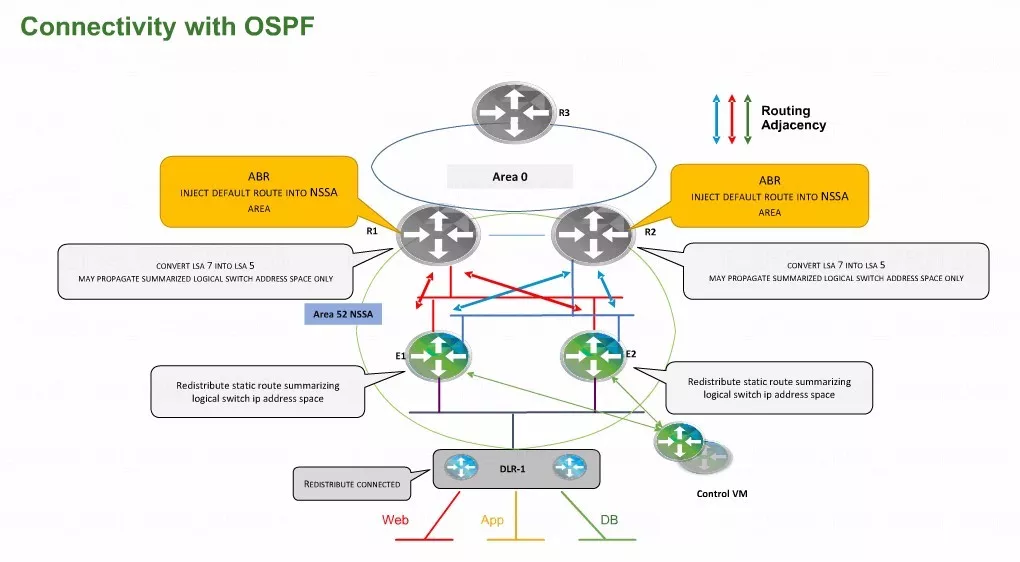
上图是物理网络当中的一个0区,图中上方3个灰色的东西是物理路由器,属于OSPF的骨干区域。
这种情况下,比较建议使用物理网络的路由器作为OSPF的区域边界路由器ABR。图中E1和E2是ESG,ESG会与更下方的DLR控制虚拟机建立OSPF的邻接关系。
将物理路由器作为边界路由器有很多的优点。举个很简单的例子,以前在使用OSPF的时候,我们可能经常会把一个区域的路由通过汇总的方式发到另外一个区域。而这个功能ESG上是不支持的,在当前那个架构当中物理的ABR为了降低对NSX内部系统的开销,会在区域边界路由器上做一个区域的路由汇总,来减少ESG包括DLR控制虚机的OSPF骨干的路由表,来提高稳定性。
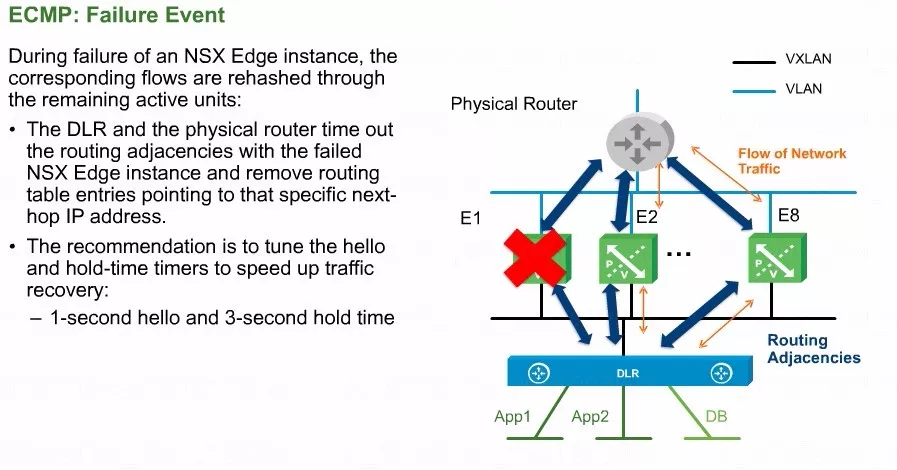
再来看下故障倒换,因为等价多路径的问题,DLR到达北向是有多个ESG的,且跟ESG建立连接关系的并不是内核当中的分布式逻辑路由,而是DLR控制虚拟机。
所以DLR控制虚机会通过OSPF的hello 包以及保持时间检测到E1设备故障
NSX内部OSPF的通信时间,默认的hello包是十秒,保持间隔是40秒。但是等价多路径的时候,这个时间过长可能会导致收敛变得缓慢,所以建议稍加调整一下。
按照OSPF的理论,DLR控制虚机的hello包保持时间降低后,ESG也要做相应地降低。
ESG、DLR以及外部物理路由器在做等价多路径的时候,通过调整hello包的报文,可以有助于设备发生故障以后,链路的快速收敛,这是VMware的一个建议。其实从物理网络的角度来讲,物理的路由器跟ESG之间,如果想降低物理的路由器的hello包,那么也要分别在ESG和物理路由器上将OSPF的通信时间做一个统一调整。
但是要注意一个问题,即南向到北向的返回报文很可能沿着另外一个路径回来。也就是进出走的是不同的ESG。ESG防火墙会话表不同步导致在返回方向上ESG流量被防火墙阻隔。
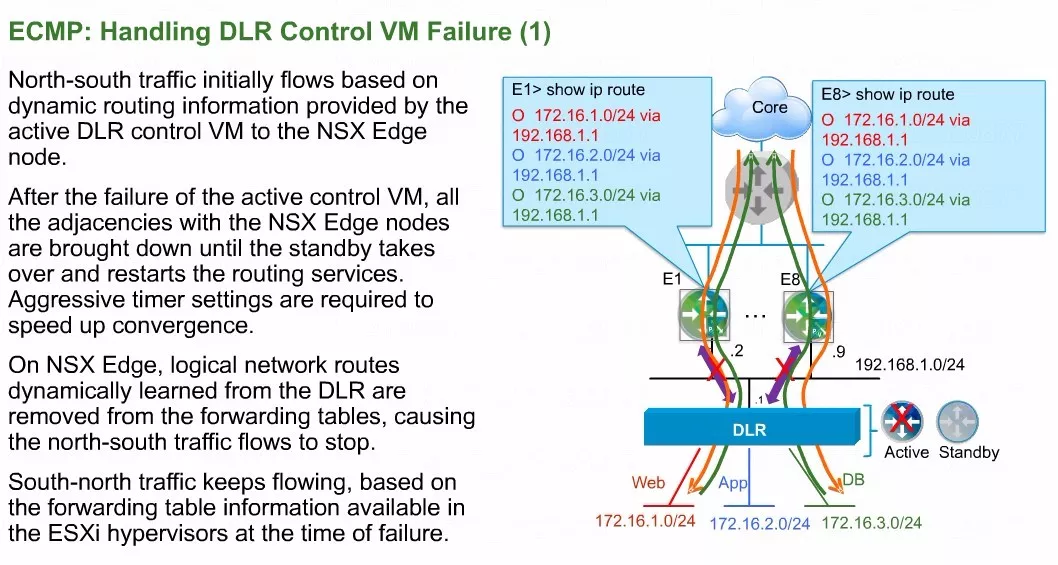
现在假设ESG没有发生任何故障,DLR控制虚机有高可用,此时主DLR控制虚机发生了一个故障,会发生什么样的行为呢?
图中绿色的线代表从内网发到外网的流量,橙色的线是代表从内外网进入到内网。如此可以看出当DLR控制虚拟机发生意外故障的时候,南向到北向转发仍然是正常的。但北向进入南下,可能会产生一些中断的问题。
备份的DLR控制虚机启动之前,DLR的CP平面发生了故障,但因为这是一个等价多路径系统,OSPF的时间调整可能比较激进的。hello包的间隔是一秒,保持时间是三秒。这意味着在三秒钟左右的时间过去以后,8个ESG都会认为DLR控制虚机是不存在的。
我们可以看到DLR内部有3个网段,这3个网段曾经通过DLR控制虚机发到了ESG。所以在ESG上会有三条路由,能够到达DLR内部的网段,下一跳接口分别是DLR的上行口的地址。
但由于DLR控制虚机的损坏,三秒钟之后,ESG会在邻居列表中把DLR控制虚机去掉,并且将通过DLR控制虚机接收的所有路由全部丢弃。具体为逐条的把路由撤销,反馈到我们的物理路由器。
此时核心网当中的设备,再要去访问我们内网的时候,第一跳会发到物理路由器,由于ESG已经撤销了内网路由,所以在没有类似浮动静态路由支撑的基础之上,北向到南向的转发就会被丢弃了,因为他根本就没有可用的路由。
为什么南向到北向是建立的?这是因为DLR控制虚机在挂掉之前,曾经通过ESG接收了到达互联网的路由。这个路由曾经通过控制器被刷新到主机内部,虽然DLR控制虚机发生了故障,但是控制器将最早的来自于DLR控制虚机的那个互联网路由,更新了主机内部。所以除非新的DLR控制虚机来刷新,否则它会一直凝结在或者说叫冻结在ESXi的DLR内核中的。
DLR控制虚机损坏后,北向进南向如果提前能够配置一个浮动静态路由,物理设备和ESG借助这个浮动静态路由也能够把报文顺利地转发到内部。
从内网到外网的那条路由由于是被冻结在分布式逻辑路由器内核中,所以南向到北向转发仍然是没有任何问题的。
原来的内网路由消失后,静态路由会浮动出现在路由表当中,而通过ESG所接收的外网的路由,由于在挂掉之前传输到了控制器,控制器又发到了主机的VDR的内核,所以它仍然是被冻结在Hypervisor的内部。ESXI在转发的时候,北向仍然认为是有1到8个不同的等价多路径的设备。
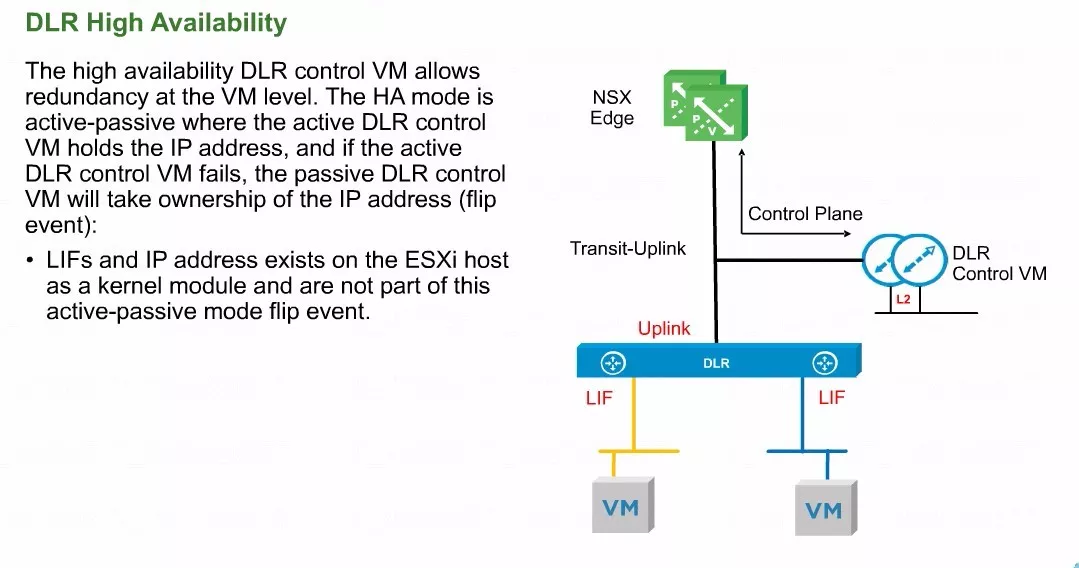
其实不管是DLR控制虚拟机还是ESG都可以去配置HA,这个HA指的是NSX系统内部的HA,并不是vSphere的HA。当然它可以和我们vSphere集群当中的HA功能来进行联动。
现在我们有两个ESG,一个是active的,一个是standby的。它们之间要通过一个预设的心跳网络来同步心跳以及左右两个设备的配置参数。active上的配置参数会被直接通过心跳网络同步到standby的ESG。
在standby的设备能够接收active设备心跳的时候,会一直是处于静默状态,不会对外对内响应任何的报文。当active的设备发生故障,standby的设备会在15秒钟左右做出响应。这个时间是心跳的最大的中断时间,可以通过图形界面来调整,最低可以降到六秒(NSX6.2)。
所以大家可以把这个时间呢调得更加激进一些。这个时间如果调整以后,standby设备做出故障响应的感知就会更加的敏感。
Active的设备发生了一个故障后,standby的设备就会对外提供服务,当那个保持时间到了以后,它就会变成新的Active设备。
这个设备对外对内来说,地址都是一模一样的。可能在早期的NSX的版本中故障倒换官方说是要大概一分钟左右,实际我们测试大概花了将近三四十秒左右的中断时间。
如果在NSX 6.4的中,要把中断的敏感保持时间降得低一些,从Ping的角度来讲,最多就是能丢一个包左右。所以VMware的官方说法是在十秒钟之内可以完成Standby到Active的故障倒换。
不过现在的技术还不能够类似物理网络,实现主备引擎之间完成亚秒级切换。
另外DLR控制虚机我们也建议配置主辅。当然从我们高可用的角度来讲,主辅的DLR控制虚机和ESG应该分配到不同的Hypervisor的主机上,以免主机挂掉形成一个单点故障的损坏。

在当前的这个案例中,DLR北向有两个绿色的设备,Edge-1和Edge-2,与ECMP不同的是它们是active和standby架构,这意味着它俩之间实际上有一个心跳,它会实时的去把来自于E1的心跳信号,包括设备的配置参数同步过来。
正常情况下,DLR的内部看不到E2这个设备,它只会认为南向到北向下一跳就是左侧的E1。
如果E1发生了一个不可逆的故障,在中断时间超时以后,E2会变成新的active的设备,E1内外网的接口IP、配置的路由,甚至连防火墙的规则和连接跟踪会话表都可以被同步捕捉到E2设备。E2设备对外工作以后,路由转发会平滑的切换到右侧,所以在做HA的时候是可以打开ESG的这个状态防火墙的。
要注意的是万一E1跟E2之间的心跳网络中断,很有可能会产生一个脑裂的行为。就是有两个一模一样的ESG对内对外来提供工作,但由于他俩的ip是完全一样,很有可能会导致网络IP出现冲突。
虽然说我们没有通过存储端去控制ESG脑裂的技术,但是在NSX 6.4的管理平面当中设计了一个脑裂检测的机制。
因为毕竟这两个ESG的管理平面都是NSX Manager。NSX Manager发现原本处于active和standby的这两个设备突然变成了AA的状态后,就会意识到发生一个脑裂的行为。
此时NSX Manager会发指令给原本处在active状态下的E2设备让回归到standby的状态,这样的话脑裂的现象就消失了。
在NSX早期的版本中脑裂出现后是需要管理员手工关掉某一个ESG来消除脑裂的影响。
由于ESG的HA跟vSphere的HA完全兼容,所以我们建议把ESG部署到vSphere的集群当中。这样的好处就是万一我们的ESG所在主机发生了故障,可能几秒或十几秒钟之后,standby的设备先会变成active设备,与此同时vSphere会检测到这台主机上一个虚拟机挂掉了。
vSphere HA级群当中的另外一个主机会在共享存储当中,把这个ESG的虚拟机重启,当它重启完毕以后,这台虚机跟原来的E2仍然是保持是高可用的。
但是ESG并没有抢占优先参数,所以这个新的ESG(E1)仍然是处在standby状态,E2处在active的状态。
从这一点来看,ESG的HA可以非常完美的与vSphere HA联动使用,同时配置,互相之间是一个完美的结合,并不会出现彼此影响问题。
当acvtive的ESG所在的主机突然挂掉后,active的角色会由standby的ESG扮演,这个跟vSphere HA无关,是ESG内部的心跳来感知的。
有问题可以在评论区讨论,以上为所有分享内容,谢谢大家!
