

此前为了学习Vue的源码,我决定自己动手写一遍简化版的Vue。现在我将我所了解到的分享出来。如果你正在使用Vue但还不了解它的原理,或者正打算阅读Vue的源码,希望这些分享能对你了解Vue的运行原理有所帮助。
目标
今天我们的目标是,对于以下的html模板:
<div class="outer">
<div class="inner" v-on-click="onClick($event, 1)">abc</div>
<div class="inner" v-class="{{innerClass}}" v-on-click="onClick">1{{name}}2</div>
</div>
我们希望生成如下的js代码:
with(this) {
return _c(
'div',
{
staticClass: "outer"
},
[
_c(
'div',
{
staticClass: "inner",
on: {
"click": function($event) {
onClick($event, 1)
}
}
},
[_v("abc")]
),
_c(
'div',
{
staticClass: "inner",
class: {
active: isActive
},
on: {
"click": onClick
}
},
[_v("1" + _s(name) + "2")]
)
]
)
}
(注:对于生成的代码,为了方便展示,这里手动的添加了换行与空格;对于模板,接下来将实现的代码还不能正确处理换行和空格,这里也是为了展示而添加了换行和空格。)
解析html
我们的工作将分为两步进行:
- 首先将字符串形式的模板解析后处理为我们需要的数据格式,这里将其称为
AST Tree(抽象语法树)。 - 接着,我们将遍历这颗树,生成我们的代码。
首先,我们创建类ASTElement,用来存放我们的抽象语法树:ASTElement实例拥有一个数组children,用来存放这个节点的子节点,一棵树的入口是它的根节点;节点类型我们简单地划分为两类,文本节点和普通节点(分别将通过document.createTextNode和document.createElement创建);文本节点拥有text属性,而普通节点将包含标签tag信息和attrs列表,attrs用来存放class、style、v-if、@click、:class这类的各种信息:
const ASTElementType = {
NORMAL: Symbol('ASTElementType:NORMAL'),
PLAINTEXT: Symbol('ASTElementType:PLAINTEXT')
};
class ASTElement {
constructor(tag, type, text) {
this.tag = tag;
this.type = type;
this.text = text;
this.attrs = [];
this.children = [];
}
addAttr(attr) {
this.attrs.push(attr);
}
addChild(child) {
this.children.push(child);
}
}
解析模板字符串的过程,将从模板字符串头部开始,循环使用正则匹配,直至解析完整个字符串。让我们用一张图来表示这个过程:
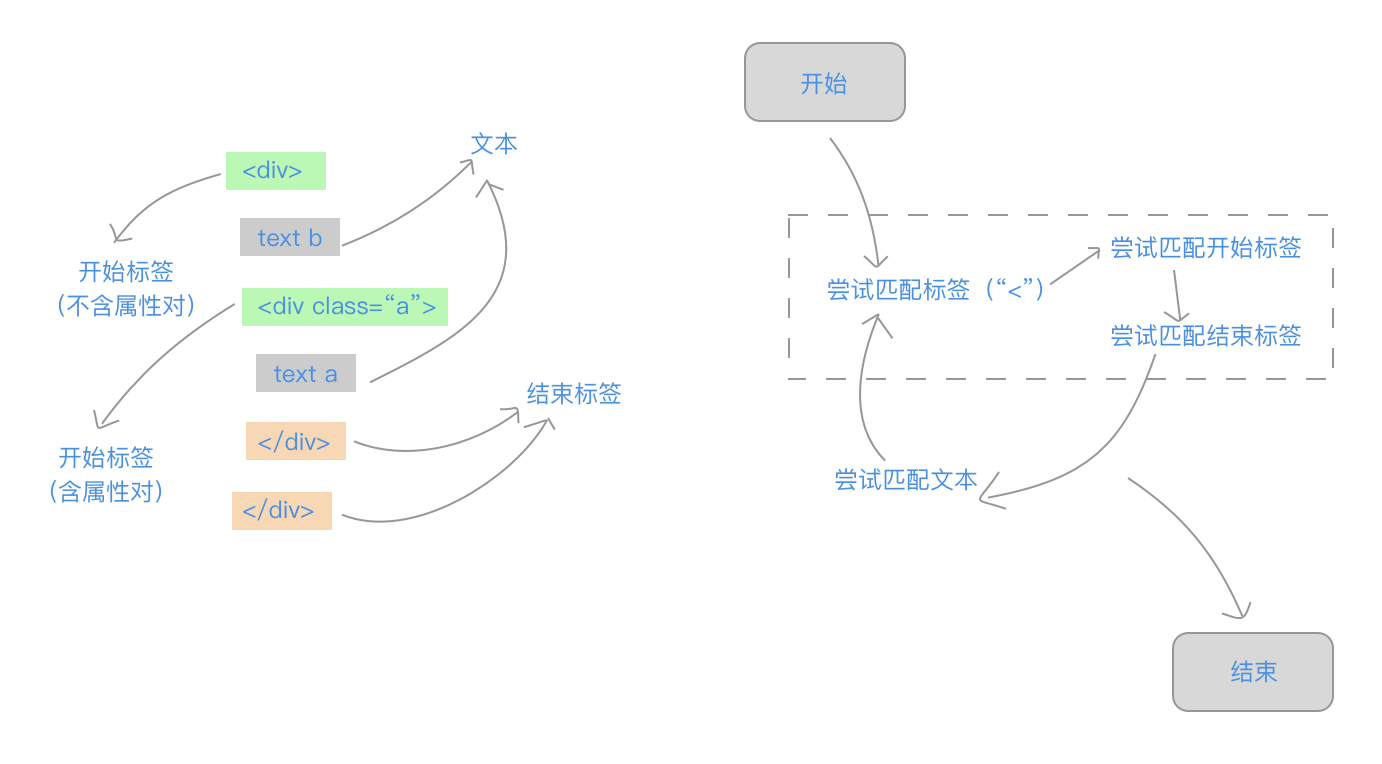
在左边的图中,我们看到,示例模板被我们分为多个部分,分别归为3类:开始标签、结束标签和文本。开始标签可以包含属性对。
而在右边的解析过程示意图中,我们看到我们的解析是一个循环:每次循环,首先判断下一个<字符是不是就是接下来的第一个字符,如果是,则尝试匹配标签,匹配标签又分为两种情况,先后尝试匹配开始标签与结束标签;如果不是,则将当前位置直到下一个<字符之间字符串都作为文本处理(为了简化代码这里忽略了文本中包含<的情况)。如此循环直至模板全部被解析:
const parseHtml = function (html) {
const stack = [];
let root;
let currentElement;
...
const advance = function (length) {
index += length;
html = html.substring(length);
};
while (html) {
last = html;
const textEnd = html.indexOf('<');
if (textEnd === 0) {
const endTagMatch = html.match(endTag);
if (endTagMatch) {
...
continue;
}
const startTagMatch = parseStartTag();
if (startTagMatch) {
...
continue;
}
}
const text = html.substring(0, textEnd);
advance(textEnd);
if (text) chars(text);
}
return root;
};
我们申明了几个变量,它们分别表示:
- stack:存放
ASTElement的栈结构,例如对于<div class="a"><div class="b"></div><div class="c"></div></div>,则会依次push(.a) -> push(.b) -> pop -> push(.c) -> pop -> pop。通过这个栈结构的数据我们可以检查模板中的标签是否正确地匹配了,不过在这里我们会略去这种检查,认为所有的标签都正确匹配了。 - root:表示整个
ASTElement树的根节点,在遇上第一个开始标签并为其创建ASTElement实例时会设置这个值。一个模板应当只有根节点,这也是可以通过stack变量的状态来检查的。 - currentElement:当前正在处理的
ASTElement实例,同时也应当是stack栈顶的元素。
处理闭合标签
在循环体中,我们使用了正则endTag来来尝试匹配闭合标签,它的定义如下:
const endTag = /^<\/([\w\-]+)>/;
用图来表示:
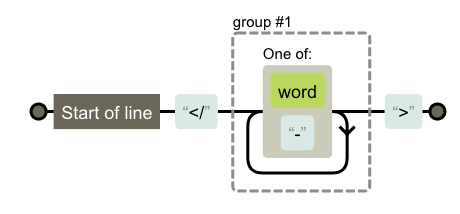
\w匹配包括下划线的任何单词字符,类似但不等价于“[A-Za-z0-9_]”。这个正则可以匹配</item>、</Item>、</item-one>等字符串。当然有很多符合规范的闭合标签的形式被排除在外了,不过出于理解Vue原理的目的这个正则对我们来说就够了。
如果我们比配到了闭合标签,那我们需要跳过被匹配到的字符串(通过advance)并继续循环,同时维护stack和currentElement变量:
const end = function () {
stack.pop();
currentElement = stack[stack.length - 1];
};
const parseEndTag = function (tagName) {
end();
};
...
const endTagMatch = html.match(endTag);
if (endTagMatch) {
const curIndex = index;
advance(endTagMatch[0].length);
parseEndTag(endTagMatch[1], curIndex, index);
continue;
}
这时我们可以进行一些容错性判断,比如标签对是否正确的匹配了等等,这些步骤我们就先统统跳过了。
处理文本
如果下一个字符不是<,那直到此之前的字符串我们将为其生成一个文本节点,并将其加入当前节点作为子节点:
const chars = function (text) {
currentElement.addChild(new ASTElement(null, ASTElementType.PLAINTEXT, text));
};
处理开始标签
对于开始标签,因为我们会将0、1或多个属性对写在开始标签中,因此我们需要分为3部分处理:开始标签的头部、尾部,以及可缺省的属性部分。于是,我们需要创建一下3个正则表达式:
const startTagOpen = /^<([\w\-]+)/;
const startTagClose = /^\s*>/;
const attribute = /^\s*([\w\-]+)(?:(=)(?:"([^"]*)"+))?/;
通过图(由regexper.com生成)来表示:
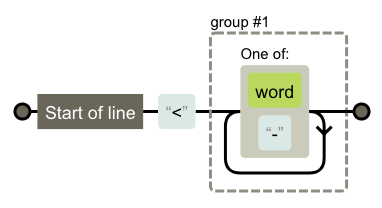
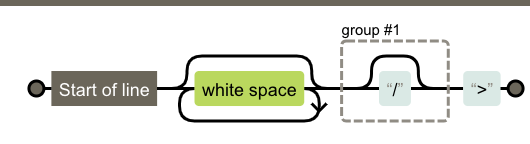
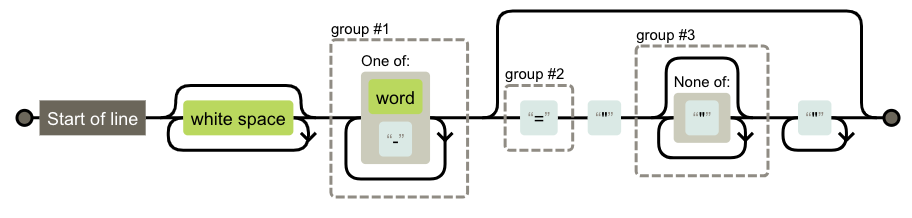
startTagOpen和startTagClose都比较简单,这里不赘述了(需要注意的一点是,我这里并没有考虑存在自闭合标签的情况,例如<input />)。对于属性对,我们可以看到=以及之后的部分是可缺省的,例如disabled="disabled"和disabled都是可以的。
因此整个匹配过程也分为3步:
- 匹配头部
- 逐一匹配属性对,并加入当前
ASTElement的属性对中 - 匹配尾部
最后,将新创建的ASTElement压入栈顶并标记为当前元素:
const start = function (match) {
if (!root) root = match;
if (currentElement) currentElement.addChild(match);
stack.push(match);
currentElement = match;
};
const parseStartTag = function () {
const start = html.match(startTagOpen);
if (start) {
const astElement = new ASTElement(start[1], ASTElementType.NORMAL);
advance(start[0].length);
let end;
let attr;
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length);
astElement.addAttr([attr[1], attr[3]]);
}
if (end) {
advance(end[0].length);
return astElement;
}
}
};
const handleStartTag = function (astElement) {
start(astElement);
};
const startTagMatch = parseStartTag();
if (startTagMatch) {
handleStartTag(startTagMatch);
continue;
}
生成代码
经过以上的步骤,我们便可以解析模板字符串并得到一颗由ASTElement组成的树。接下来,我们就需要遍历这棵树,生成用于渲染这棵树的代码字符串。最终在得到代码字符串之后,我们将其传入Function构造函数来生成渲染函数。
首先要做的事,便是用with(this)来包裹整段代码:
const generateRender = function (ast) {
const code = genElement(getRenderTree(ast));
return 'with(this){return ' + code + '}';
};
这样当我们正确的指定this之后,在模板中我们就可以书写{{ calc(a + b.c) }}而非啰嗦的{{ this.calc(this.a + this.b.c) }}了。
getRenderTree将递归地遍历整棵树:
const getRenderTree = function ({ type, tag, text, attrs, children}) {
return {
type,
tag,
text: parseText(text),
attrs: parseAttrs(attrs),
children: children.map(x => getRenderTree(x))
};
};
在此过程中,我们将对原先的ASTElement树进行进一步的处理,因为原先的书保留的都是原始的数据,而这里我们需要根据我们的渲染过程对数据进行进一步的加工处理。
这里的加工处理分为两个部分:
- 处理文本节点的文本
- 处理属性列表
接下来我们就通过代码来看看我们要进行哪些预处理。
首先对于文本节点,我们需要从中找到包含方法/变量的部分,即被{{}}所包含的部分。这里我们来举几个例子,例如abc需要被转换为代码'abc',{{ getStr(item) }}需要被转换为代码getStr(item),abc{{ getStr(item) }}def需要被转换为代码'abc' + getStr(item) + 'def'。
也就是说,我们需要不断的匹配文本中包含{{}}的部分,保留其中的内容,同时将其余部分转换为字符串,并最终拼接在一起:
const tagRE = /\{\{(.+?)\}\}/g;
const parseText = function (text) {
if (!text) return;
if (!tagRE.test(text)) {
return JSON.stringify(text);
}
tagRE.lastIndex = 0;
const tokens = [];
let lastIndex = 0;
let match;
let index;
let tokenValue;
while ((match = tagRE.exec(text))) {
index = match.index;
if (index > lastIndex) {
tokenValue = text.slice(lastIndex, index);
tokens.push(JSON.stringify(tokenValue));
}
tokens.push(match[1].trim());
lastIndex = index + match[0].length;
}
if (lastIndex < text.length) {
tokenValue = text.slice(lastIndex)
tokens.push(JSON.stringify(tokenValue));
}
return tokens.join('+');
};
对于属性部分(或者说,指令),首先来说一下我们将支持的(相当有限的)属性:
- class:例如
class="abc def",将被处理为'class': 'abc def'这样的键值对。 - v-class::例如
v-class="{{innerClass}}",将被处理为'v-class': innerClass这样的键值对。这里我们偷个懒,暂时不像Vue那样对动态的class实现对象或数组形式的绑定。 - v-on-[eventName]:例如
v-on-click="onClick",将被处理为'v-on-click': onClick这样的键值对;而v-on-click="onClick($event, 1)",将被处理为'v-on-click': function($event){ onClick($event, 1) }这样的键值对。
由于之前实现属性匹配所使用的正则比较简单,暂时我们并不能使用:class或者@click这样的形式来进行绑定。
对于v-class的支持,和处理文本部分是相似的。
对于事件,需要判断是否需要用function($event){}来包裹。如果字符串中仅包含字母等,例如onClick这样的,我们就认为它是方法名,不需要包裹;如果不仅仅包含字母,例如onClick(),flag = true这样的,我们则包裹一下:
const parseAttrs = function (attrs) {
const attrsStr = attrs.map((pair) => {
const [k, v] = pair;
if (k.indexOf('v-') === 0) {
if (k.indexOf('v-on') === 0) {
return `'${k}': ${parseHandler(v)}`;
} else {
return `'${k}': ${parseText(v)}`;
}
} else {
return `'${k}': ${parseText(v)}`;
}
}).join(',')
return `{${attrsStr}}`;
};
const parseHandler = function (handler) {
console.log(handler, /^\w+$/.test(handler));
if (/^\w+$/.test(handler)) return handler;
return `function($event){${handler}}`;
};
在Vue中对于不同的属性/绑定所需要进行的处理是相当复杂的,这里我们为了简化代码用比较简单的方式实现了相当有限的几个属性的处理。感兴趣的童鞋可以阅读Vue源码或者自己动手试试实现自定义指令。
最后,我们遍历被处理过的树,拼接出我们的代码。这里我们调用了_c和_v两个方法来渲染普通节点和文本节点,关于这两个方法的实现,我们将在下一次实践中介绍:
const genElement = function (el) {
if (el.type === ASTElementType.NORMAL) {
if (el.children.length) {
const childrenStr = el.children.map(c => genElement(c)).join(',');
return `_c('${el.tag}', ${el.attrs}, [${childrenStr}])`;
}
return `_c('${el.tag}', ${el.attrs})`;
} else if (el.type === ASTElementType.PLAINTEXT) {
return `_v(${el.text})`;
}
};
你还可以尝试...
- 在解析模板时,我们没有考虑注释节点,对于匹配标签的正则我们实现的很简单,因为无法匹配类似
<?xml、<!DOCTYPE或是<xsl:stylesheet这样的标签 - 我们并没有正确处理模板中的换行和空格
- 在处理文本时我们没有考虑如果字符串中包含
<那该怎么处理 - 我们没有考虑自闭和标签而是假设所有的标签都有开始和闭合标签
- 我们不会对匹配错误的标签做容错性处理,不会考虑必须包含/无法包含的标签关系(例如
table下应当先包含tbody,而不应当直接包含tr;p内部不能包含div等等) - 对于属性的正则我们也实现的很简单,以至于无法匹配
@click和:src这种形式 - 支持的指令/属性相当有限,注意还需要支持例如
disabled与disabled="disabled"这样的缩写格式
如果你想自己动手实践一下,这些都将是很有趣的功能点。
总结
这一次,我们实践了怎样去解析模板字符串并由此生成一颗抽象语法树,同时由此生成了渲染代码。
在最后一次实践中,我们将把我们已经完成的内容结合起来,最终完成前端的渲染工作。
参考:
