


在 RTC 2018 实时互联网大会上,Visionular Inc 联合创始人兼首席科学家 Zoe Liu 进行了主题演讲,与大家一起分享了一场视频编解码的前沿探索。
欢迎访问 RTC 开发者社区,与更多实时音视频、编解码开发者交流经验。

Why Video Codec Matters?
大家都知道,从技术复杂度来讲,视频的编码和解码并不对称,编码器要比解码器复杂很多。那么,机器学习对编码可以做哪些优化呢?
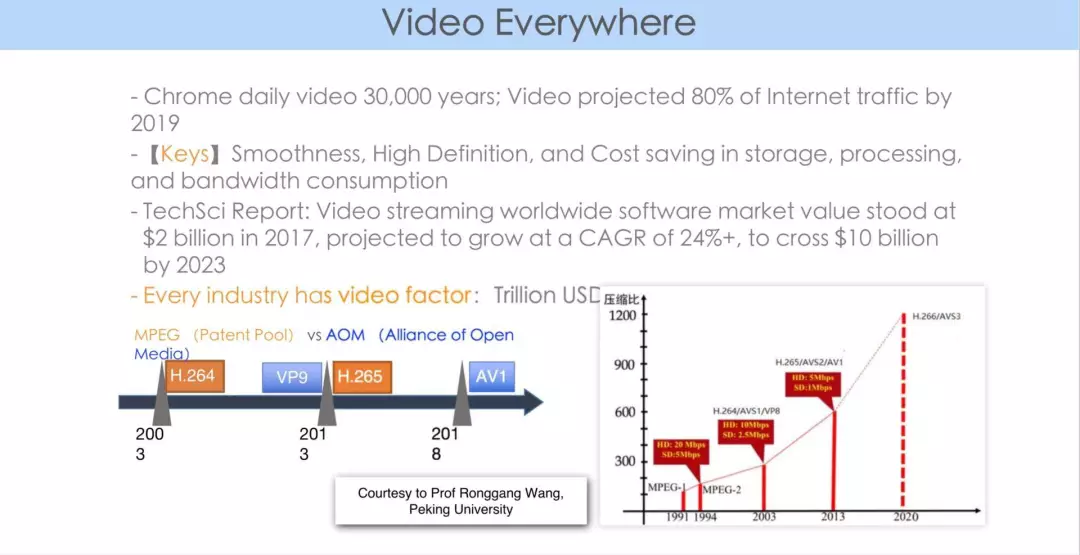
大家目前讨论的比较多的是3个编码标准:一个是 MPEG 组织的,一个是从 VP9 到 AV1 的开源、免除版权税的,另外一个是我们自己在国内研发的从 AVS 到 AVS2、AVS3 系列。
编码的标准日新月异,一直在向前发展。而大家都会问,为什么视频编码那么重要?
以 JPEG 为例,它是一个图像标准,经历了几十年的发展。那么为什么几十年来 JPEG 没有被打败,反而被广为应用呢?很大程度上受益于它的广泛的商业用途和易实现性。接下来,我希望通过下图,和大家解释为什么视频编解码这么重要。

2013 年时,为了取代 H.264 编码器,谷歌推出了 VP9。海外用户看 YouTube,一般是两类手机,Android 上看到的是 VP9 的码流。由于 Apple 不支持 VP9 硬件解码,因此 iPhone 用户看到的是 H.264 码流。
谷歌曾做过一个统计,对比了世界范围内(不包含中国), VP9 和 H.264 的播放时长。从上图中我们可以看到,在印度、非洲等网络带宽不佳的市场,由于 VP9 的应用,大大优化了用户体验,首屏时间大幅缩短,并且卡顿大幅减少。
与此同时,采用新一代 codec 的应用,带来了用户体验的提升和新业务推进的可能性,这正印证了 Video codec 的重要性。
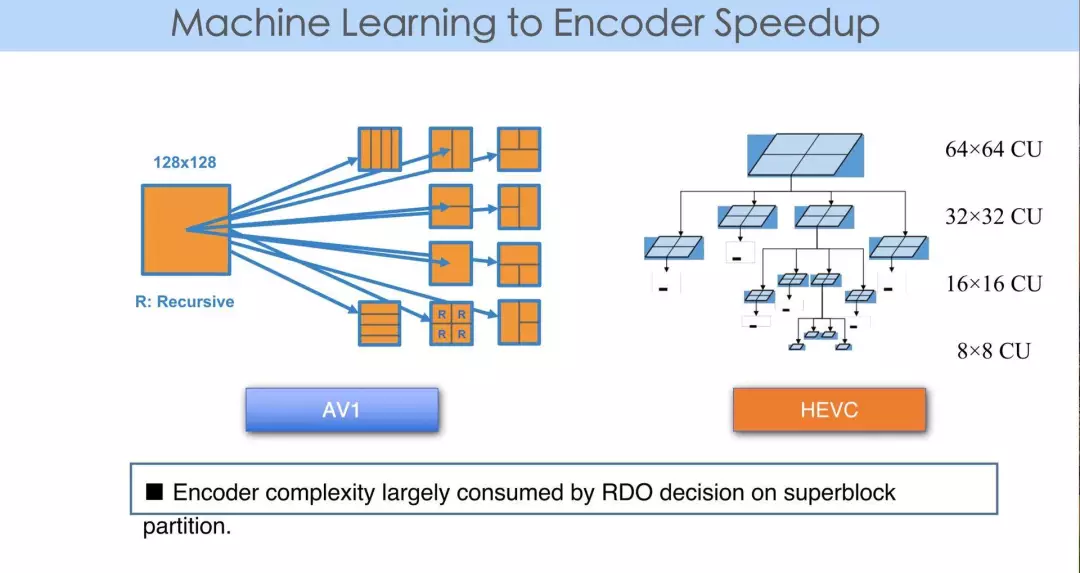
在编码器中,不论是 HEVC 或 AV1,都有 partition 的概念。熟悉编码的朋友都知道,HEVC 和 AV1 中都有一个四叉树的 partition。
比如,它的 superblock 在 AV1 中的大小是 128*128,它可以继续向下做四叉树的划分,每个 128*128 的图像块可以分成 4 个 64*64,每个 64*64 又可以分成 4 个 32*32。以此类推,例如在 AV1 中可以分解到最小为 4*4 的图像块。
对于图像宏块而言,要做出一个 partition 的 map。统计表明,Video encoder 端 partition RDO 评估的计算会占到编码器复杂度的 80% 以上。
那么此时如何利用机器学习来尝试做优化呢?
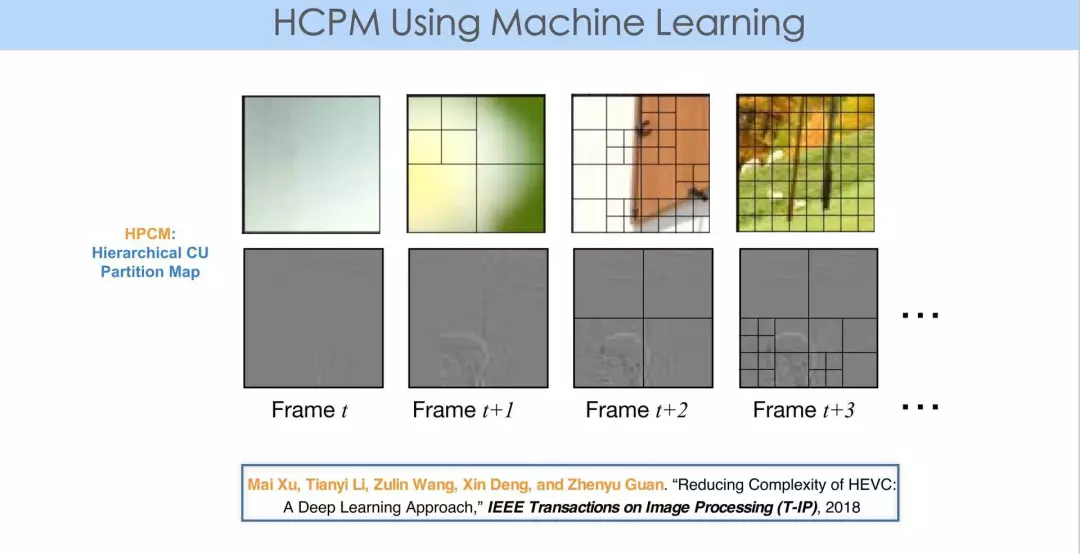
如上图所示,第一行四张图是帧内压缩,第二行四张图是帧间压缩的实例。它展示了对于不同的图像块需要有不同的 partition。
原因就在于,每个图像块内容不同。对于帧内压缩,细节、纹理越多的地方,分块就越细致。对于帧间压缩,主要是对残差分块,主要是要看帧间的预测是如何进行的。从这个角度来讲,分块本身是由内容和预测模式决定的。
那么,对任一图像块,我们可以在内容上提取一定的 feature。大家都知道,当 QP 取值比较大时,即失真度比较高时,整块的内容就趋于平滑,那就会选择比较大一些的分块。QP 比较小时,会选择比较细致的分块。从这些方面可以看出,从块的角度,在 partition 的情况下,可以从内容、编码模式中提取相应的 feature,通过离线训练可以从机器学习中获得决策结果。
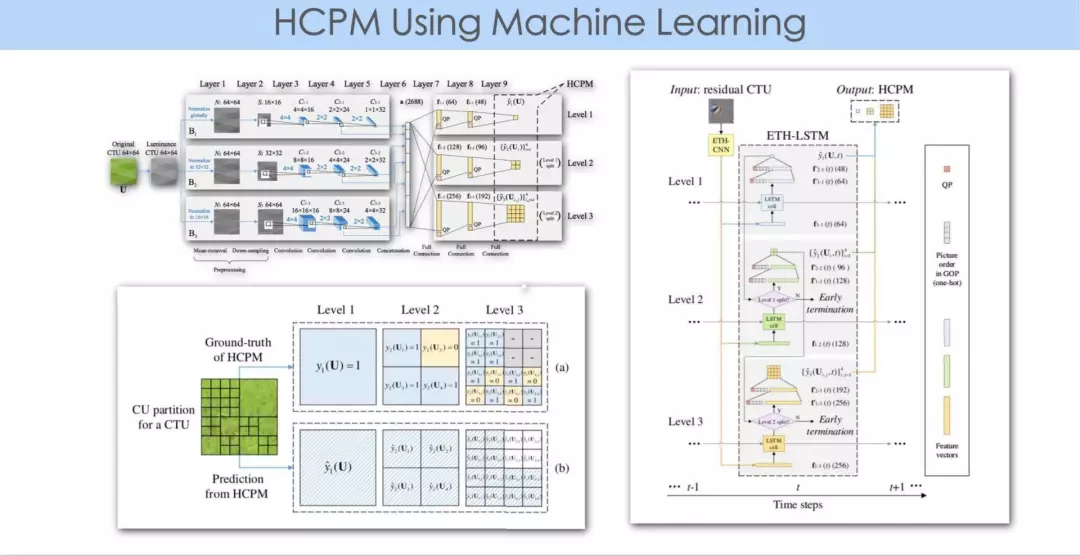
上图中这篇论文是北航的徐迈老师与他的学生们所做的一项工作。他们基于神经网(这里主要用卷积神经网)做出的对 partition 的基本分类。
在真正做 partition 时,一般的做法是分级进行的,比如块的大小是 64*64,此时需决策是否要往下走,做 4 个 32*32,到 32 再往下做决策是否继续划分,即决策是一层一层向下推进的。
这篇论文做了一个初步的尝试,经过神经网的训练学习,输出的是图像块最终的完整的划分结果,将多级的决策结果一次性输出为最终的划分图。这种方法的优势在于,能够最大限度地降低神经网本身带来的复杂度,一次性导出结果。
另外,它在采用卷积神经网络决策的过程中,包含了 early termination 的决策。因为当网路深度和每层节点数增加的情况下,神经网本身也会引入一些新的复杂度。这篇论文的结果是跟 HM 比对的,在 encoder 端的速度大约提升了 50%。

AV1 是开放的标准,是一个开源的 codec。我们和谷歌合作一起贡献了 libaom 开源代码。上图是我们的截屏。由于采用了机器学习的方法,使得 encoder 进一步优化。
从图中可以看到,这个 CL 中不是深度学习,而是采用了一个非常简捷的神经网。一般 CL 中的神经网构造是一层到两层,每一层的节点在 128 个左右。所以这里并不是深度学习,是采用了一个比较简捷的网络结构。
以往在优化编码器时,常常采用 empirical 的想法,即做 partition 时,从一级、二级到三级,可以提取当前 block 层的方差,也可以将当前的 block 一分为四,提取每一个 subblock 的方差,对其进行一些分析,然后做出决策,给出 hard-coded 阈值。当块参数的大小低于某个阈值或高于某个阈值时,继续往下做 partition。所有这些决策可以用神经网代替,因为此时可以通过积累大量数据对一个简单的网络进行训练,同时再用这个网络生成决策,判断是否需要四叉树继续下分。
从上图可以看出,用一个简单的神经网就可以把 encoder 速度提升 10 - 20%。所以,我们在采用机器学习的方法时,不一定是深度学习,因为神经网的概念已经存在很久了,主要是用大数据做训练,从数据集中设计网络,对相对复杂的非线性关系建模,从而使得 encoder 的速度以及编码效率进一步提升。
ML to Coding Performance
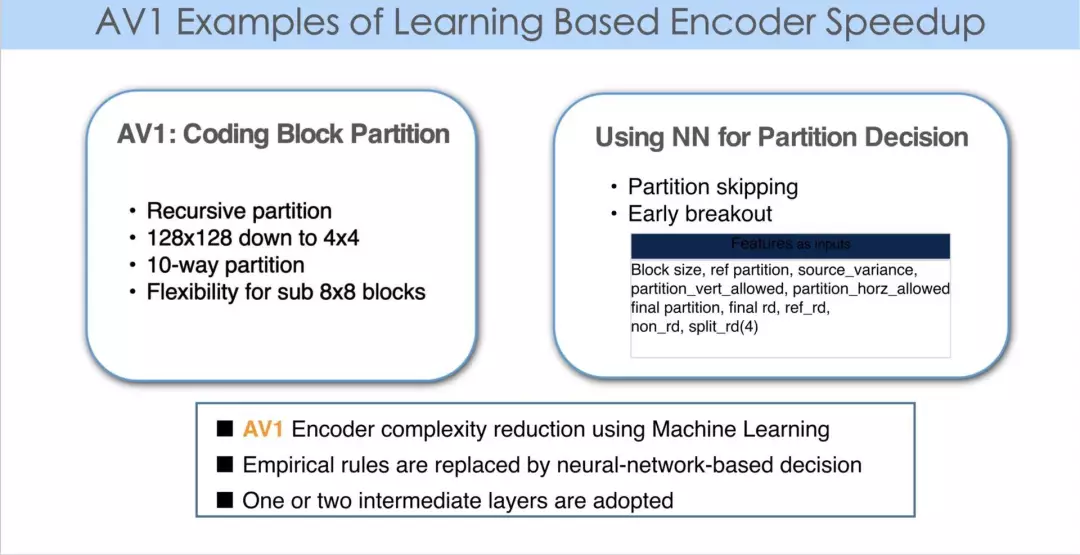
AV1 是一个实例,它采用了神经网络、机器学习的概念,使得 encoder 进一步提速。使得用神经网代替经验决策。
那么,神经网是不是可以帮助我们对视频压缩做压缩性能提升?下面,我举三个例子,分享一下我们从哪些方面可以把神经网和深度学习用在编码性能提升上。
第一个,是从超分的概念来分享。大家都知道,压缩造成了信息丢失。信息丢失以后我们希望在解码端或者编码端的 inloop 过程中,重建丢失的信息。如果我们可以做到,就可以达到编码性能的进一步提升。因为压缩是一体两制,或在一定码率下提升画质,或在一定画质下节省码率。如果可以在一定的码率下重建失去的信息,就可以进一步提升画质,之后可以进一步节省码率,通过画质提升将降码率后失真图像的质量还原到原来码率的画质水平。
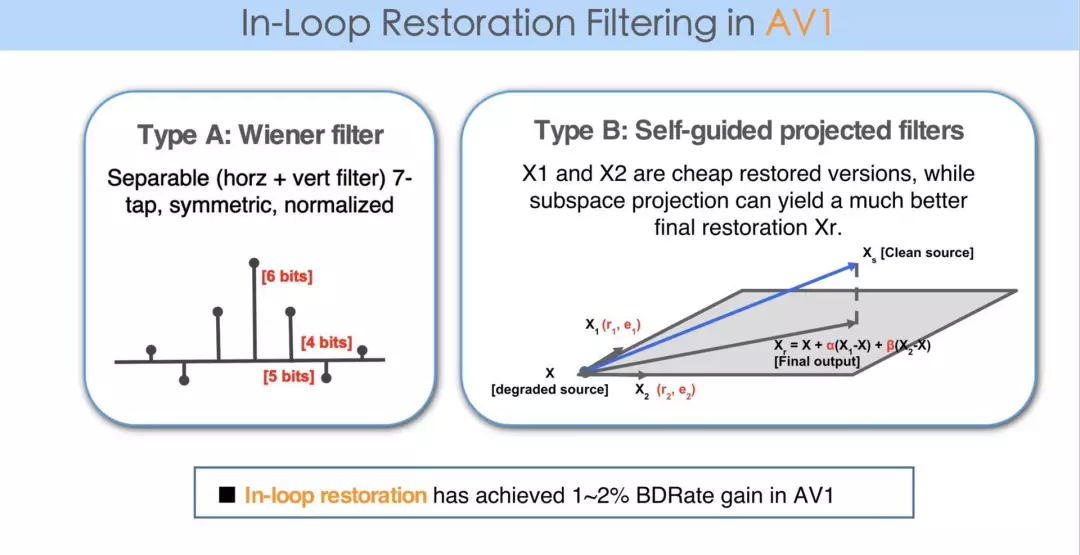
AV1 中采用了更多的工具,从而使其可以比已有编码标准,比如 HEVC 有进一步的提高。其中一个工具称作 restoration,里面提供两个滤波器,一个是 Wiener filter,一个是 Self-guided projected filters,仅这一个工具的 BDRate 性能提升在 1 - 1.5% 之间。
如上方右图所示,它是一个 restoration 的描述。那么它是如何把信息恢复出来的呢?我们可以想象,任何一个像素点是多维空间的一点,那么一个小时的视频一定有 n 个图像帧,每个帧里有 m 个像素点。如果把每个点都想象成一维的话,任何一个视频实际上是高维空间中的一点。做这种想象以后,上方图右侧的 Xs 就是原始的视频,经过压缩,就得到了高维空间中的另一点,如果这两点重合,就是 lossless coding 的过程。这两点在高维空间中距离越远,失真度就越大。重建的过程就是力图将压缩后的X那一点带回来与原来的点越来越近的过程。
AV1 中有一个 guided filter 的概念,通过这个 filter 可以从解压以后的 X,恢复成 X1、X2 两点,也就是得到两个滤波器的结果。做完后发现,这两点离原来那点还是差得非常远。那么 AV1 进一步通过 X1、X2 建立一个平面,把原有的视频所对应的点,在现在这个平面上做投影。可以看到投影以后所得点就离原点近了很多,这就是一个重建的过程。
最终 AV1 只要求在码流中传递两个参数 α 和 β,需要高精度传输过去,在解码端用同样的 restoration 就可以恢复出比较高质量的图像。从这点可以看出,这一个工具就可以达到 BDRate 的 1% 以上的提升,我们可以用学习的概念得到更好的图像复原,所以很自然而然就想到超分方法的运用。
现在,超分辨率在机器学习中已经得到广泛应用。压缩以后的图像,通过学习可以重建出一个更高质量的图像,利用这个图像可以在我们现有的编码结构中加以运用,从而达到更好的 coding performance。
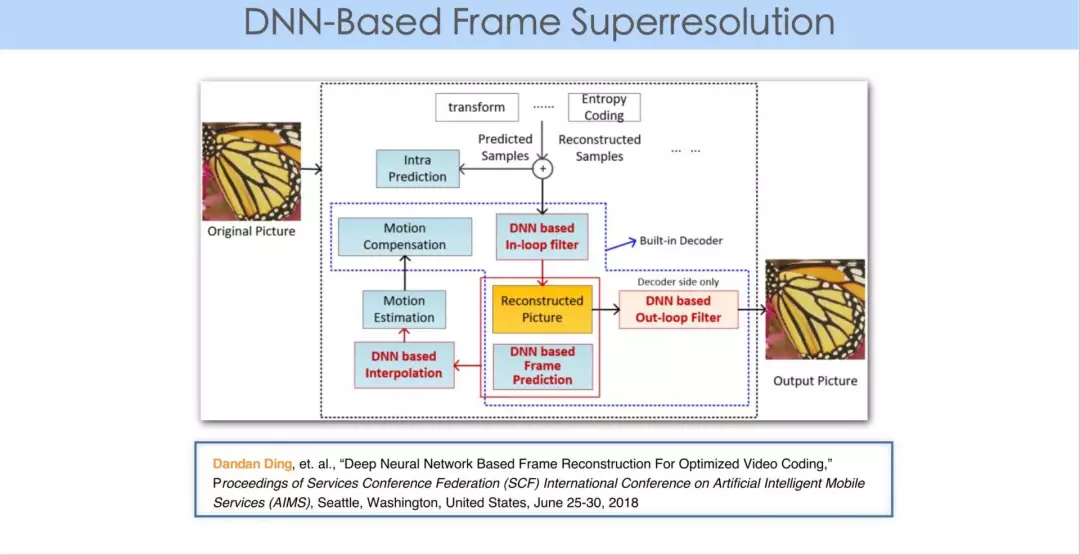
这是我们和杭师大的丁丹丹老师合写的一篇论文,主要探索重建图像。可以在四方面加以应用:第一,插值滤波;第二,In loop filter;第三,可以通过利用多个参考帧,重现出一个更清晰的参考帧;第四,Out loop post-processing filter。
这些都是从学习的角度,利用已知的参考帧重建出更高清晰更高质量的参考帧。或者是利用插值滤波,因为插值的获取也等价于重建出一些原有的信息。从我们训练集数据中得到的信息,存储到神经网络结构以及其相应的参数中,再加上已有的视频数据得到重建的信息,利用重建信息帮助我们提升编码的性能。
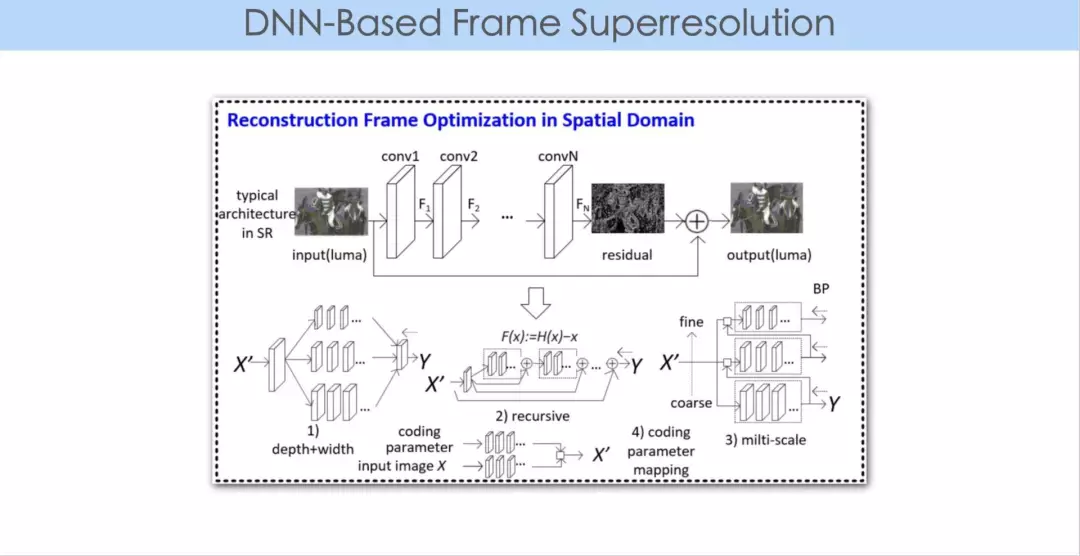
上图是进一步的一个例子,包括前向帧和后向帧在时空上进行的联合重建。

最后重建的结果是一个超分辨率图像。同样的码率,在解码端可以运用该技术使得视频质量得到进一步提升。视频在用多帧分辨率做重建的过程中,由于每帧的视频中有一个运动矢量的概念,所以这篇论文最主要的贡献,是在原有方法的基础上做了一个像素对齐,这是视频相对于图像在处理上比较特别的地方。
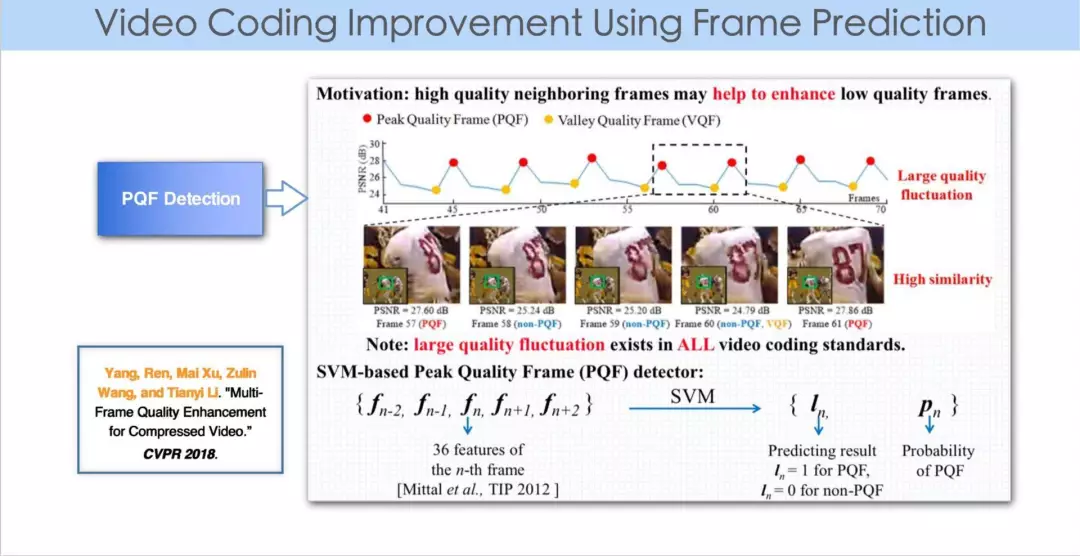
徐迈老师的另外一个工作,也是利用学习恢复在编码过程中失去的信息,不过不是提高分辨率,而是提高图像的质量,去除编码后图像的 artifacts。
我们在编码解码过程中会发现,每一帧的质量有波动,任何一个图像帧由于 QP 的不同,每帧质量会不同,有些帧的质量比较好,比如我们通常说的 Key frame,这篇论文中把这样的帧叫做 PQF。
如果我们可以把 PQF 的帧识别出来,用学习的办法把质量比较差的帧的质量弥补、提升,这样不仅可以提高原本质量差的帧的质量,更可以优化序列中各帧的质量到更高的水平。
视频帧与帧间的质量保持平稳是比较关键的。举一个例子,做针灸的时候要扎很多针,如果每一针的力度相差不多,患者会觉得ok。如果突然一针的力度很大,人就会记住那一针的感觉。而人眼观看视频也是一样的。
首先第一个工作就是识别视频中哪些帧质量比较高,因为此时解码端的原视频是不可得的。这个工作主要利用类似无参考图像质量评价(no reference image quality assessment)的方法来进行。在没有原视频的基础上,有一项研究是无参考质量评估,这篇论文借鉴于那个领域的工作。
第一步,从每一帧里提取 36 个 feature,5 个连续帧提取一共 180 个 feature 做训练。这里采用的是支持向量机方法作聚类,经过训练识别帧的质量。
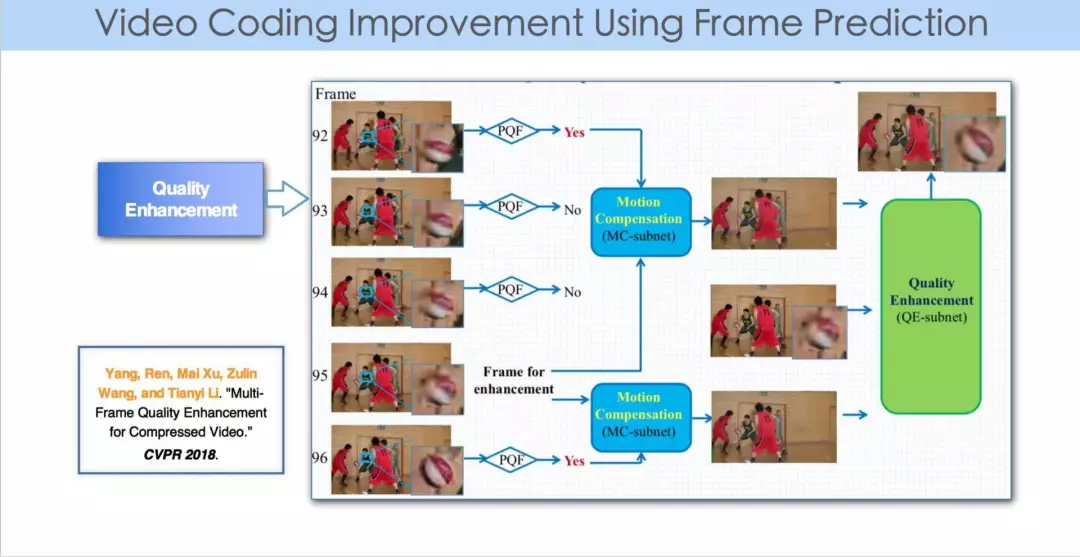
第二步,判断出比较好的帧以后,利用神经网络来提升质量差帧的图像质量。先做运动补偿,即:找到质量比较低的帧,及其前后质量比较高的两帧(PQF),三帧之间做像素级的运动估计的过程。做完运动估计和运动补偿之后,再做质量提升。
大家都知道,在神经网训练的过程中我们需要 ground truth,motion vector 很难获取 ground truth,所以这里不是要去训练 motion vector,而是得到的重建帧和原有的帧之间能达到差异最小值,来训练神经网。这个神经网有两个部分,MC-subnet 和 quality enhancement subnet,对构成的MSE函数实现最小化,进而用训练出的神经网去重建质量比较低的图像帧,最终达到整体视频质量的一致性。
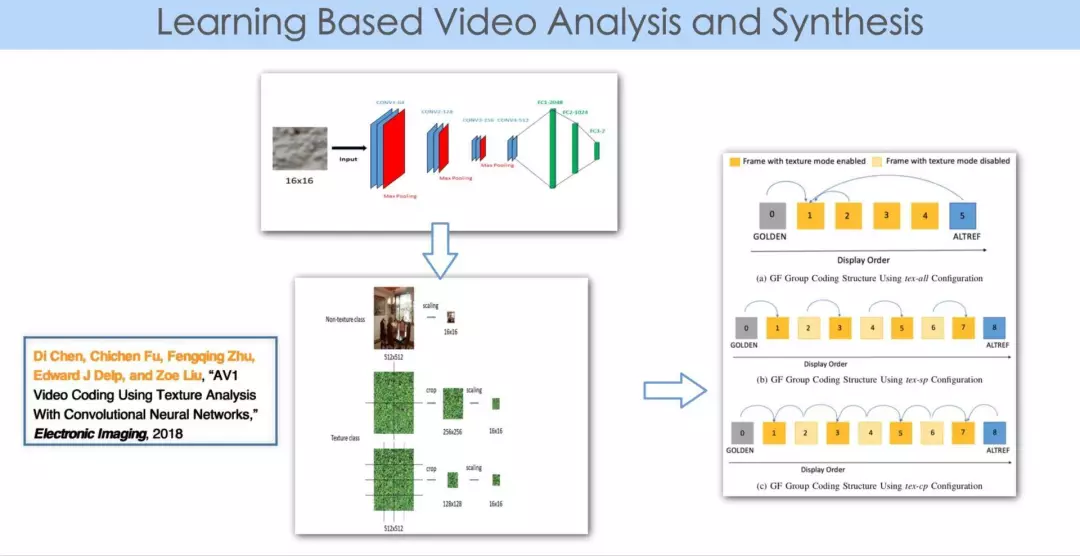
第三个工作也是用深度学习对视频编码效率的提高,它的想法是这样的,人眼看视频,会对某些区域比较敏感,对某些区域没那么敏感。
譬如我们看足球比赛,会对球的质量比较敏感,对草地的失真不那么敏感。不同的区域人眼的敏感度不同,那么那些区域我就可以不做压缩和传输,即在 encoder 端进行分析,识别出这些区域,在 decoder 端再进行合成,编码、解码的工作就是分析加合成的过程。
由于其中有内容的分析,而机器学习在这方面有比较大的优势,所以这个工作就是用学习的办法把每帧图像分割成两个区域,一部分区域是人眼不敏感的,另一部分区域就保留下来,对于那些保留下来的区域可以用传统的(比如 AV1 的办法)进行压缩,对于那些容错性比较大的区域,可以去合成。
我们的具体工作中,实际上是用 AV1 的 global motion 概念,首先识别这些区域相应的全局运动矢量,最终用参考帧和全局运动矢量重建在编码端省去的区域,等同于通过 motion warp 的方法来代替、合成某些区域。这个工作的神经网络主要用于前处理,分割图像。在编码的过程中,由于运用了 AV1 里的 global motion 工具,所以最终这个工作是 AV1 aligned 的编码过程。
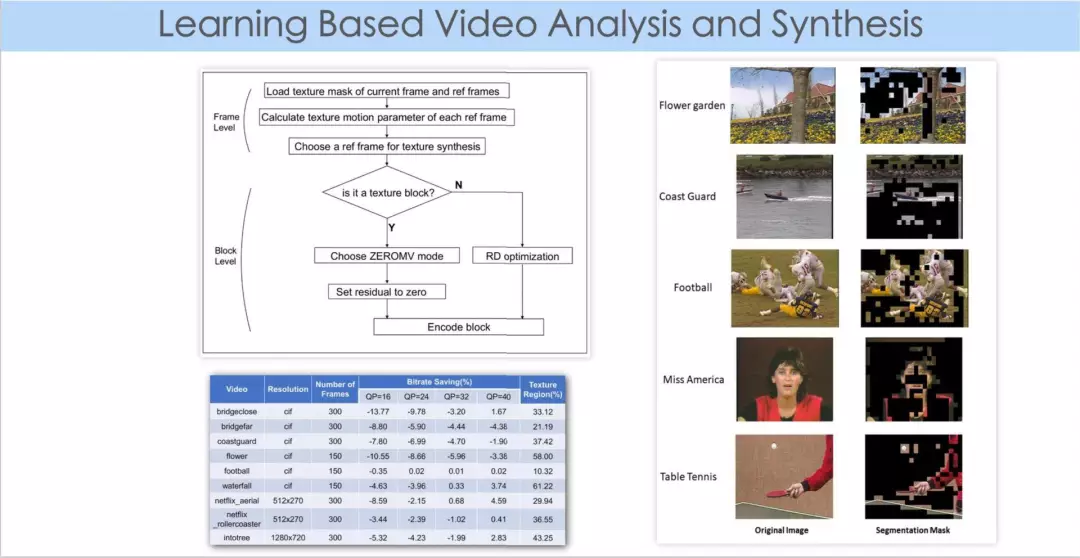
右图是图像分割的实验结果,哪些是 texture 比较复杂的区域,哪些是人眼比较敏感的区域。在这个工作中我们发现,把一帧图像划分为两个区域- 纹理区和非纹理区,然后对纹理区做 warping 合成,效果相对比较好。
视频相比图像,由于引入了 temporal 这个第三维时间轴,如果每一帧做 motion warping,出来后帧与帧间效果不一致,那么人眼就很容易看到差别,主观感知效果比较差。
举个简单的例子,以前我们在做实时通信(比如 Facetime),在手机上,手机有两个 CPU 核,自然而然会想到并行。比如 H.264,可以采用编码器端 slice 并行的概念,每一个图像帧会分成上面一个 slice 和下面一个 slice。
譬如一帧图像一共 22 行,你可以对上下 11 行进行单独编码。但是在 QP 比较大,码率比较低的情况下,由于上下两个 slice 的独立编码,失真结果差异比较大,这样编出来的视频中间会有一条线被观测到。如果单独看每一帧,是看不到那条线的,但是如果播放视频,那条线就显现出来了。这就是视频和图像不一样的地方,有一个帧间 consistent 的问题。
我们当时分析,出现中间这条线,主要是两个 slice 的划分过于一致,每帧都是上面一半下面一半,过于齐整了。一个处理办法,是让上下两个 slice 的行数近似但又不完全固定,这样使得每一个 CPU 核的计算量基本等同,达到并行的目的,但同时引入了一个 random variable(随机变量),让上下两个 slice 的行数会稍有不同,而且不同的行数帧与帧之间是随机变换的,那条线就看不到了。
这个实例是进一步说明,在处理视频的时候,必须要考虑到视频播放在时间连续上的感知效果。这是视频相对图像在主观质量评估上,一个比较大的挑战。因此,我们在用视频纹理分析与合成提升视频压缩性能的方法中,并不是对每一帧都去做 motion warping,而是利用编码器中所采用的hierarchical结构,只对位于这个结构中最上面一层的图像帧(或者简单来讲,只针对B帧)采用warping的办法。这样所得到的视频其感知效果相对比较理想。
ML to Perceptual Coding

机器学习还可以用在视觉感知编码(perceptual coding)。我们做视频编码器的都有质量评估标准。质量评估是大概经历了三代的变迁:
第一代,更多的是采用 PSNR。信号在丢失的过程中,一般评测都是想知道信息到底丢失了多少,所以用 PSNR 来衡量。
第二代,当我们衡量视频质量时,想到视频是给人眼看的,人眼不敏感的区域就不需要花很大的力气,即使失真再大,人眼感知不到即可。所以视频编码的评测标准发展为用那些可以跟人的主观视觉更加匹配的指标去衡量。
第三代,随着机器学习或人工智能的发展,很多时候,比如大量的监控视频不再是给人眼看的,而是为机器分析所用。
举个例子,我们的编码一般来讲是一个低通的过程,通常人眼对低频的信号会更敏感,不管是 JPEG、MPEG 还是 AV1,当我们对块做码率分配的时候,之所以做 transform,是希望把 energy 更多的 conpress 到 lowpass 那端,而 highpass 那端很多时候我们会大量的丢弃掉,去掉人眼不敏感的信息。但机器在分析的过程中和人眼的观测不是完全一致的,比如在监控视频中,大部分时候视频都是稳定的,突然有一个人或者一个物体出现时,即高频的信息出现,这类信息对机器分析更加有用。
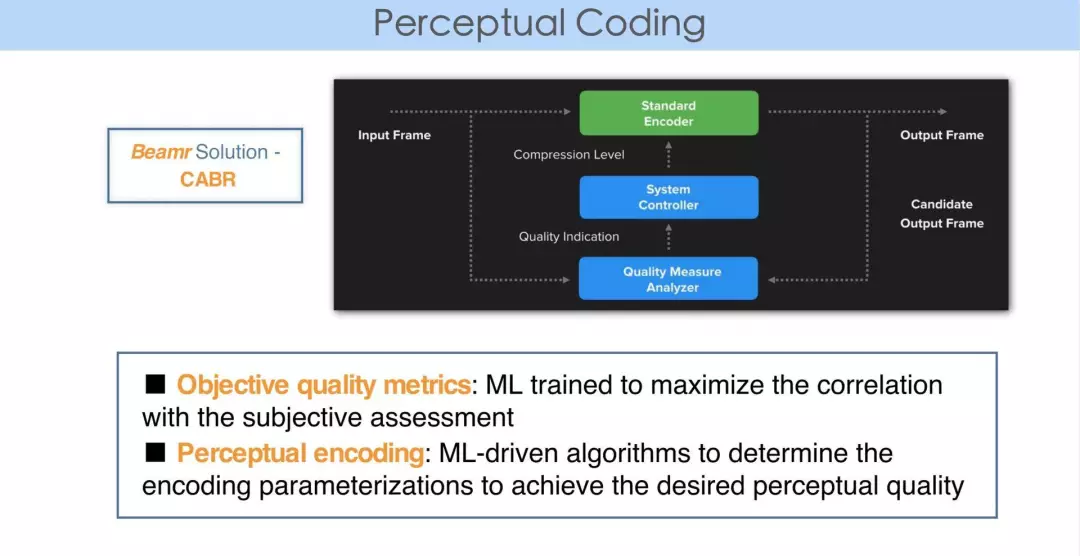
由于机器分析的引用,使得 quality matrics 会有不同的评判标准出现。
What’s Next

这是今年 CVPR 的一篇 paper,是从其网页上下载的视频,原文作 video translation。前面有提到,这是一个 video Analysis + Synthesis 的过程。

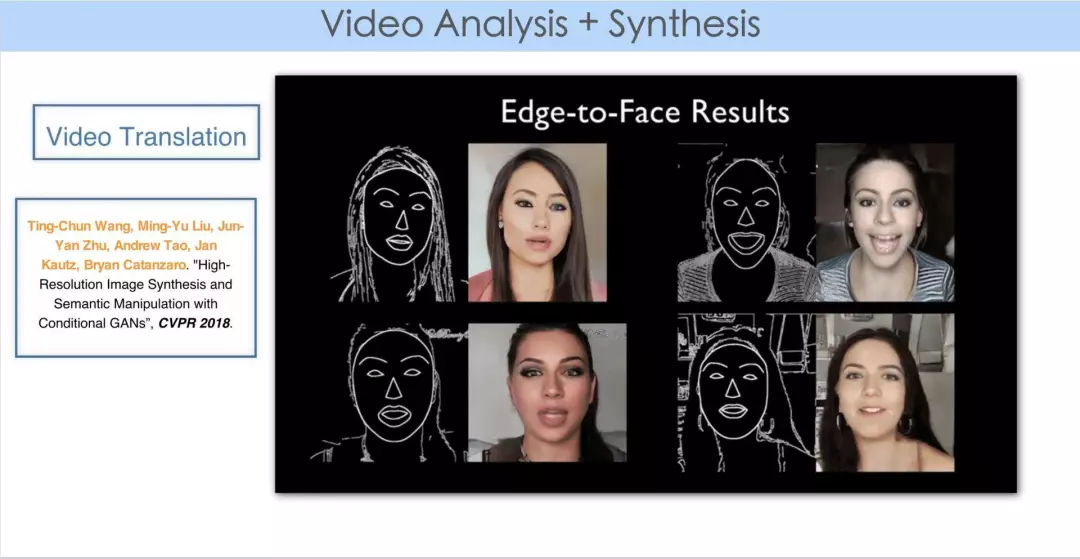
可以想像,视频这么大的量,从一个简洁的图形恢复出一个复杂的高清的视频内容,这时候你会看到它神奇的变换阈。这实际上是对视频压缩提供了新的视角。我们创业之初,投资人也会说,你们现在在做压缩,而机器学习 AI 发展到一定程度,所有图像、视频是否都可以用一个很复杂的深度学习神经网络来代替,最终就能在 decoder 端通过神经网络,再加上从码流中提取出来的信息作为神经网络的输入重建任一视频呢?

最后学习对我们的压缩到底产生什么样的影响?通常大家都会说“一图胜千言”,一帧图像可以表达那么多的内容,对于一个视频远远不止“千言”,那刚刚关于我提出的问题,是不是能用机器学习代替所有的压缩标准和以前采用的运动补偿+变换阈的传统做法呢?我今天的回答是否定的。
我们认为在可预见的未来 5 到 10 年,压缩还会按照现有的基本的 coding structure 的方向发展,但是每个模块都有可能被神经网络或者机器学习代替,但是基本的框架不会改变。
总结下来主要有两点:一是通过机器学习,视频的分析、理解和压缩之间的连接会更加紧密。举个例子,高速上很多视频作为交通监控,采用车牌识别,但对于一个视频,如果你关注的只有车牌的话,会把很大的高清视频压缩成一串数字。那么不同场景的压缩,需要对视频做一些前期的分析。二是通过机器学习,视频的重建技术会在视频编码流程中扮演越来越重要的角色。视频可以用一些神经网络的工具,重建出很复杂的信息。特别针对视频编码和解码,一些有助于解码端重建的信息可以在编码端生成,因为编码端是有源视频的。这些信息可以放在码流中传送到解码端,进一步辅助解码端重建出更高质量的视频。这样的方法可称作“编码器引导下的解码端重建”,比解码端的独立重建技术应该会有更大的潜力。机器学习在其中也会有更大的施展空间。
关注声网Agora微信公众号,观看演讲视频回顾、下载演讲 PPT,以及更多干货内容。
