

ELK Tips 主要介绍一些 ELK 使用过程中的小技巧,内容主要来源为 Elastic 中文社区。
一、Logstash
1、Filebeat :Non-zero metrics in the last 30s
- 问题表现:Filebeat 无法向 Elasticsearch 发送日志数据;
- 错误信息:
INFO [monitoring] 1og/log.go:124 Non-zero metrics in the last 30s; - 社区反馈:在 input 和 output 下面添加属性 enabled:true。
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/*.log
output.elasticsearch:
hosts: ["https://localhost:9200"]
username: "filebeat_internal"
password: "YOUR_PASSWORD"
enabled: true
input 和 output 下 enabled 属性默认值为 true,因此怀疑另有其因。
2、Logstash 按月生成索引
output {
if [type] == "typeA"{
elasticsearch {
hosts => "127.0.0.1:9200"
index => "log_%{+YYYY_MM}"
}
}
}
按照日的原理类似:%{+YYYY.MM.dd}
3、Filebeat 通过配置删除特定字段
Filebeat 实现了类似 Logstash 中 filter 的功能,叫做处理器(processors),processors 种类不多,尽可能在保持 Filebeat 轻量化的基础上提供更多常用的功能。
下面列几种常用的 processors:
add_cloud_metadata:添加云服务器的 meta 信息;add_locale:添加本地时区;decode_json_fields:解析并处理包含 Json 字符串的字段;drop_event:丢弃符合条件的消息事件;drop_fields:删除符合条件的字段;include_fields:选择符合条件的字段;rename:字段重命名;add_kubernetes_metadata:添加 k8s 的 meta 信息;add_docker_metadata:添加容器的 meta 信息;add_host_metadata:添加操作系统的 meta 信息;dissect:类似与 gork 的正则匹配字段的功能;dns:配置 filebeat 独立的 dns 解析方式;add_process_metadata:添加进程的元信息。
processors 的使用方式:
- type: <input_type>
processors:
- <processor_name>:
when:
<condition>
<parameters>
...
4、LogStash 采集 FTP 日志文件
exec {
codec => plain { }
command => "curl ftp://server/logs.log"
interval => 3000}
}
5、Logstash docker-compose 启动失败(Permission denied)
在 docker-compose 中使用 user 选项设置使用 root 用户启动 docker,能解决权限问题。
$ cat docker-compose.yml
version: '2'
services:
logstash:
image: docker.elastic.co/logstash/logstash:6.4.2
user: root
command: id
6、Metricize filter plugin
将一条消息拆分为多条消息。
# 原始信息
{
type => "type A"
metric1 => "value1"
metric2 => "value2"
}
# 配置信息
filter {
metricize {
metrics => [ "metric1", "metric2" ]
}
}
# 最终输出
{ {
type => "type A" type => "type A"
metric => "metric1" metric => "metric2"
value => "value1" value => "value2"
} }
二、Elasticsearch
1、ES 倒排索引内部结构
Lucene 的倒排索引都是按照字段(field)来存储对应的文档信息的,如果 docName 和 docContent 中有“苹果”这个 term,就会有这两个索引链,如下所示:
docName:
"苹果" -> "doc1, doc2, doc3..."
docContent:
"苹果" -> "doc2, doc4, doc6..."
2、Jest 和 RestHighLevelClient 哪个好用点
RestHighLevelClient 是官方组件,会一直得到官方的支持,且会与 ES 保持同步更新,推荐使用官方的高阶 API。
Jest 由于是社区维护,所以更新会有一定延迟,目前最新版对接 ES6.3.1,近一个月只有四个 issue,说明整体活跃度较低,因此不推荐使用。
此外推荐一份 TransportClient 的中文使用手册,翻译的很不错:github.com/jackiehff/e…。
3、ES 单分片使用 From/Size 分页遇到重复数据
常规情况下 ES 单分片使用 From/Size 是不会遇到数据重复的,数据重复的可能原因有:
- 没有添加排序;
- 添加了按得分排序,但是查询语句全部为 filter 过滤条件(此时得分都一致);
- 添加了排序,但是有索引中文档的新增、修改、删除等操作。
对于多分片,推荐添加 preference 参数来实现分页结果的一致性。
4、The number of object passed must be even but was [1]
ES 在调用 setSource 的时候传入 Json 对象后会报错:The number of object passed must be even but was [1],此时可以推荐将 Json 对象转为 Map 集合,或者把 Json 对象转为 json 字符串,不过传入字符串的时候需要设置类型。
IndexRequest indexRequest = new IndexRequest("index", "type", "id");
JSONObject doc = new JSONObject();
//indexRequest.source(jsonObject); 错误的使用方法
//转为 Map 对象
indexRequest.source(JSONObject.parseObject((String) doc.get("json"), Map.class));
//转为 Json 字符串(声明字符串类型)
indexRequest.source(JSON.toJSONString(doc), XContentType.JSON);
5、跨集群搜索
ES 6.X 原生支持跨集群搜索,具体配置请参考:www.elastic.co/guide/en/ki…
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
ES 6.5 推出了新功能,跨集群同步(Cross-cluster replication),感兴趣的可以自行了解。
6、ES 排序时设置空值排序位置
GET /_search
{
"sort" : [
{ "price" : {"missing" : "_last"} }
],
"query" : {
"term" : { "product" : "chocolate" }
}
}
7、ES 冷归档数据如何处理
使用相对低配的大磁盘机器配置为 ES 的 Warm Nodes,可以通过 index.routing.allocation.require.box_type 来设置索引是冷数据或者热数据。如果索引极少使用,可以 close 索引,然后在需要搜索的时候 open 即可。
8、ES 相似文章检测
对于大文本的去重,可以参考 SimHash 算法,通过 SimHash 可以提取到文档指纹(64位),两篇文章通过 SimHash 计算海明距离即可判断是否重复。海明距离计算,可以通过插件实现:github.com/joway/elast…
9、Terms 聚合查询优化
- 如果只需要聚合后前 N 条记录,推荐在 Terms 聚合时添加上
"collect_mode": "breadth_first"; - 此外可以通过设置
"min_doc_count": 10来限制最小匹配文档数; - 如果对返回的 Term 有所要求,可以通过设置
include和exclude来过滤 Term; - 如果想获取全部 Term 聚合结果,但是聚合结果又很多,可以考虑将聚合分成多个批次分别取回(Filtering Values with partitions)。
10、Tomcat 字符集造成的 ES 查询无结果
两个系统连接同一个 ES 服务,配置和代码完全一致,同一个搜索条件,一个能够搜索出来东西,一个什么都搜索不出来,排查结果是因为其中一个系统的 tomcat 配置有问题,导致请求的时候乱码了,所以搜不到数据。
11、ES 索引设置默认分词器
默认情况下,如果字段不指定分词器,ES 或使用 standard 分词器进行分词;可以通过下面的设置更改默认的分词器。
2.X 支持设置默认的索引分词器(default_index)和默认的查询分词器(default_search),6.X 已经不再支持。
PUT /index
{
"settings": {
"analysis": {
"analyzer": {
"default": {
"type": "ik_max_word",
"tokenizer": "ik_max_word"
}
}
}
}
}
12、ES 中的魔法参数
- 索引名:_index
- 类型名:_type
- 文档Id:_id
- 得分:_score
- 索引排序:_doc
如果你对排序没有特别的需求,推荐使用 _doc 进行排序,例如执行 Scroll 操作时。
13、ES 延迟执行数据上卷(Rollup )
Rollup job 有个 delay 参数控制 job 执行的延迟时间,默认情况下不延迟执行,这样如果某个 interval 的数据已经聚合好了,该 interval 迟到的数据是不会处理的。
好在 rollup api 可以支持同时搜索裸索引和 rollup 过的索引,所以如果数据经常有延迟的话,可以考虑设置一个合适的 delay,比如 1h、6h 甚至 24h,这样 rollup 的索引产生会有延迟,但是能确保迟到的数据被处理。
从应用场景上看,rollup 一般是为了对历史数据做聚合存放,减少存储空间,所以延迟几个小时,甚至几天都是合理的。搜索的时候,同时搜索最近的裸索引和历史的 rollup 索引,就能将两者的数据组合起来,在给出正确的聚合结果的情况下,又兼顾了性能。
Rollup 是实验性功能,不过非常有用,特别是使用 ES 做数据仓库的场景。
14、ES6.x 获取所有的聚合结果
ES2.x 版本中,在聚合查询时,通过设置 setSize(0) 就可以获取所有的聚合结果,在ES6.x 中直接设置 setSize(Integer.MAX_VALUE) 等效于 2.x 中设置为 0。
15、ES Jar 包冲突问题
经常会遇到 ES 与业务集成时出现 Jar 包冲突问题,推荐的解决方法是使用 maven-shade-plugin 插件,该插件通过将冲突的 Jar 包更换一个命名空间的方式来解决 Jar 包的冲突问题,具体使用可以参考文章:www.jianshu.com/p/d9fb7afa6…。
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<relocations>
<relocation>
<pattern>com.google.guava</pattern>
<shadedPattern>net.luculent.elasticsearch.guava</shadedPattern>
</relocation>
<relocation>
<pattern>com.fasterxml.jackson</pattern>
<shadedPattern>net.luculent.elasticsearch.jackson</shadedPattern>
</relocation>
<relocation>
<pattern>org.joda</pattern>
<shadedPattern>net.luculent.elasticsearch.joda</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.common</pattern>
<shadedPattern>net.luculent.elasticsearch.common</shadedPattern>
</relocation>
<relocation>
<pattern>com.google.thirdparty</pattern>
<shadedPattern>net.luculent.elasticsearch.thirdparty</shadedPattern>
</relocation>
</relocations>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer" />
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
16、ES 如何选择 Shard 存储文档?
ES 采用 djb2 哈希算法对要索引文档的指定(或者默认随机生成的)_id 进行哈希,得到哈希结果后对索引 shard 数目 n 取模,公式如下:hash(_id) % n;根据取模结果决定存储到哪一个 shard 。
三、Kibana
1、在 Kiabana 的 Discovery 界面显示自定义字段
Kibana 的 Discovery 界面默认只显示 time 和 _source 两个字段,这个界面的左半部分,在 Popular 下面展示了很多,你只需要在你需要展示的字段后面点击 add 即可将自定义的字段添加到 discovery 界面。
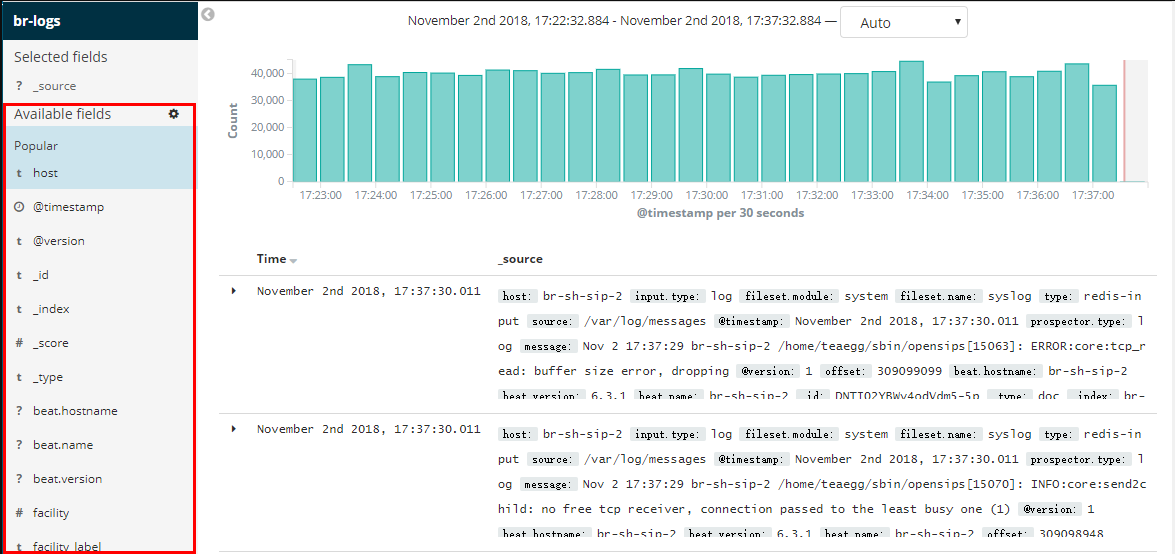
2、filebeat 的 monitor 指标的说明
- Total:'All events newly created in the publishing pipeline'
- Emitted: 'Events processed by the output (including retries)'
- Acknowledged:'Events acknowledged by the output (includes events dropped by the output)'
- Queued:'Events added to the event pipeline queue'
四、社区文章精选
- Elastic认证考试心得
- 一文快速上手Logstash
- 当Elasticsearch遇见Kafka--Kafka Connect
- elasticsearch冷热数据读写分离
- elasticsearch优秀实践
- ELK 使用小技巧(第 1 期)
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。

