

紧接着上次说到的RDB文件解析功能,数据解析步骤完成后,下一个问题就是如何保存解析出来的数据,Redis有多种数据类型,string、hash、list、zset、set,一开始想到的方案是为每一种数据定义一种数据结构,根据不同的数据类型,将数据保存到不同的数据结构,但是这样的做法带来了比较多的冗余代码,以string和hash为例,一开始的代码是这样的:
type Rdb struct {
… // 其他属性
strObj map[string]string
hashObj map[string]map[string]string
…// 其他结构体定义
}
// 保存string的函数
func (r *Rdb) saveStrObj(redisKey string, redisVal string) {
r.strObj[redisKey] = redisVal
}
// 保存hash的函数
func (r *Rdb) saveHashObj(redisKey string, hashField string, hashVal string) {
item, ok := r.hashObj[redisKey]
if !ok {
item = make(map[string]string)
r.hashObj[redisKey] = item
}
item[hashField] = hashVal
}
这种方式有比较多的冗余代码,比如保存字符串和保存哈希结构需要编写两套相似代码了,且在初始化Rdb结构体的时候,还需要初始化所有结构体之后,再传递到Rdb的初始化函数中,比如:
strObj := make(map[string]string)
hashObj := make(map[string]map[string]string)
rdb := &Rdb{…, strObj, hashObj}
这样的代码写起来比较繁琐,且不好维护,如果在更多数据类型的项目中,这样的代码看起来简直令人发指。比如在这次的实践中,redis的数据都是键值对,键的类型是固定的-字符串,但是值的类型就有map、string等等各种类型,于是乎就想到是否有泛型这种技术可以协助实现想要的功能。
泛型编程
泛型程序设计(generic programming)是程序设计语言的一种风格或范式。泛型允许程序员在强类型程序设计语言中编写代码时使用一些以后才指定的类型,在实例化时作为参数指明这些类型。(摘自维基百科)
简单地理解,泛型编程指的是不针对某一种特定的类型进行编程,一个方法不是针对了某几种特定的数据类型,而是对大部分数据类型都有效。
比如开发一个加法功能,不只是支持整型做加法,浮点型、字符串、数组等等类型的加法,都可以实现。
在开始介绍Go语言的泛型编程实现之前,我想先聊一聊C语言的泛型实现,还是那句话,最喜欢C语言。
C语言的泛型实现
以交换变量的函数为例子,在C语言的实现,是通过无类型指针void *来实现,看下面的代码:
// 交换函数,泛型实现版本
void swap(void *p1, void *p2)
{
size_t size = (sizeof(p1) == sizeof(p2)) ? sizeof(p1) : -1;
char temp[size];
memcpy(temp, p1, sizeof(p1));
memcpy(p1, p2, sizeof(p2));
memcpy(p2, temp, sizeof(temp));
}
那么,有了泛型版本的交换函数后,通过执行整型、浮点数和字符串的交换验证一下:
int main()
{
int a = 1;
int b = 42767;
swap(&a, &b);
float f1 = 1.234;
float f2 = 2.345;
swap(&f1, &f2);
char str1[6] = "hello";
char str2[10] = "world ooo";
swap(str1, str2);
printf("a: %d, b: %d\n", a, b);
printf("f1: %f, f2: %f\n", f1, f2);
printf("str1: %s, str2: %s\n", str1, str2);
}
编译执行后结果如下:
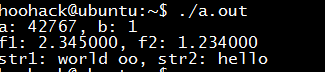
泛型版本的交换函数实现的关键是void *和memcpy函数,是拷贝内存的操作,因为数据在内存中都是保存二进制,只要操作交换的类型是一致的,那么通过memcpy会拷贝类型占用字节大小的数据,从而实现同类型的数据交换。需要注意一点的是,C语言下的泛型编程是不安全的,比如在这个交换函数中,如果操作了不同类型数据的交换,比如short和int的交换:
short a = 1;
int b = 5;
swap(&a, &b);
这个调用时不会报错,且可运行的,但是交换的结果依赖于系统的字节序,这种交换是没有意义的,需要程序员去做更多的检查和特殊判断。
Go语言的泛型
在Go语言里面,没有真正的泛型,它的泛型是通过利用interface{}的特性来实现,因为interface{}也是一种类型, 只要实现了interface{}里面的方法就可以归属为同一种类型,空的interface{}没有任何方法,那么任何类型都可以作为同一类(这一点有点类似Java的Object,所有类的超类)。
interface{}
interface{}是Go语言的一种类型,可以类比理解为Java的接口类型,在Go语言里,interface{}定义了一个方法集合,只要实现了interface{}里面的方法集,那就可以说是实现了该接口。Go语言的interface{}类型是一种静态的数据类型,在编译时会检查,但是它也算是一种动态的数据类型,因为它可以用来保存多种类型的数据。
Go语言的interface{}提供了一种鸭子类型(duck typing)的用法,用起来就好像是PHP中的动态数据类型一样,但是如果企图使用一个有其他方法声明的interface{}来保存int,编译器还是会报错的。
以开头的代码为例,改为使用interface{}后,代码是怎么样呢?
定义保持Redis对象的RedisObject结构体,保存对象的类型、占用长度,对象值,值使用了空interface{}类型:
type RedisObject struct {
objType int
objLen int
objVal interface{}
}
当保存值时,只需要将值直接赋值给RedisObject即可:
func (r *Rdb) saveStrObj(redisKey string, strVal string) {
redisObj := NewRedisObject(RDB_TYPE_STRING, r.loadingLen, strVal)
r.mapObj[redisKey] = redisObj
}
func (r *Rdb) saveHash(hashKey string, hashField string, hashValue string) {
item, ok := r.mapObj[hashKey]
if !ok {
tmpMap := make(map[string]string)
item = NewRedisObject(RDB_TYPE_HASH, 0, tmpMap)
r.mapObj[hashKey] = item
}
item.objVal.(map[string]string)[hashField] = hashValue
}
对于字符串类型而言,它的值就是简单的字符串,使用语句r.mapObj[redisKey] = redisObj赋值即可,而哈希对象相对复杂一些,首先检查保存键hashKey的是否为有效对象,如果不是,则需要新建一个哈希对象,在保存时,需要将objVal(interface{}类型)解析为键值对对象,然后再进行赋值,具体代码是objVal.(map[string]string),意思是将类型为interface{}的objVal解析为map[string][string]类型的值。
类型断言
上面对objVal进行类型转换的技术称之为类型断言,是一种类型之间转换的技术,与类型转换不同的是,类型断言是在接口间进行。
语法
<目标类型的值>,<布尔参数> := <表达式>.( 目标类型 ) // 安全类型断言
<目标类型的值> := <表达式>.( 目标类型 )  //非安全类型断言
如果断言失败,会导致panic的发生,为了防止过多的panic,需要在断言之前进行一定的判断,这就是安全与非安全断言的区别,安全类型断言可以获得布尔值来判断断言是否成功。
另外,也可以通过t.(type)得到变量的具体类型。
var t interface{}
t = functionOfSomeType()
switch t := t.(type) {
default:
fmt.Printf("unexpected type %T", t) // %T prints whatever type t has
case bool:
fmt.Printf("boolean %t\n", t) // t has type bool
case int:
fmt.Printf("integer %d\n", t) // t has type int
case *bool:
fmt.Printf("pointer to boolean %t\n", *t) // t has type *bool
case *int:
fmt.Printf("pointer to integer %d\n", *t) // t has type *int
}
总结
通过这次的小实践,除了对泛型编程有了更多的了解,学习到了Go语言的泛型编程原理,认识到interface{}也算是Go语言中的一个亮点,同时对计算机底层操作数据的本质也有所了解,程序的数据是在底层是一堆二进制,解析数据不是去识别数据的类型,而是程序根据变量的类型读取对应的字节,然后采取不同的方式去解析它。所谓类型, 只是读取内存的方式不同罢了。
原创文章,文笔有限,才疏学浅,文中若有不正之处,万望告知。
如果本文对你有帮助,请点个赞吧,谢谢^_^
更多精彩内容,请关注个人公众号。

