

- 原文地址:GraphQL Server Design @ Medium
- 原文作者:Sasha Solomon
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:EmilyQiRabbit
- 校对者:KarthusLorin,weibinzhu
Medium 的 GraphQL 服务设计
前一段时间,我们已经介绍了如何使用 GraphQL 将项目迁移为 React.js 和面向服务的结构。现在,我们想要介绍 GraphQL 服务结构是如何帮助我们更加平滑顺利地完成迁移的。
在开始设计 GraphQL 服务之前,我们必须要牢记三件事情:
方便修改数据格式 目前我们使用协议缓冲区 protocol buffers 来作为来自后端的数据模型 schema。但是,我们使用数据的方式会变化,而协议缓冲却没有跟进。这就意味着我们的数据格式并不总是客户端需要的那样。
清楚地区分哪些数据是用于客户端的 在 GraphQL 服务中,被传递的数据都处于客户端的“准备就绪”的不同阶段。我们应当让每个准备就绪的状态更加清晰,而不是把它们混合起来,这样我们就能确切的知道那些数据是用于客户端的。
方便添加新的数据源 既然我们要转型为面向服务的结构,我们就希望确保为 GraphQL 服务添加新的数据源是很容易的,同时明确数据来源。
牢记这些,我们就可以构造出一个有三种不同角色的服务框架:
获取器 Fetchers、存储库(Repos)和 GraphQL 模式。

责任分层块
每一层都有自己的职责,并且只与它的上层交互。让我们来谈谈每一层都具体做了什么。
获取器 Fetchers
从任意数量的源获取数据
获取器的目的是为了从数据源获取数据。GraphQL 服务获取的数据应该已经完成了业务逻辑的添加或更改。
获取器应该与 REST 或 gRPC 端口相对应。获取器需要一个协议缓冲区 protobuf。这意味着由获取器获取的任何数据都必须遵循协议缓冲区定义的模式。
存储库
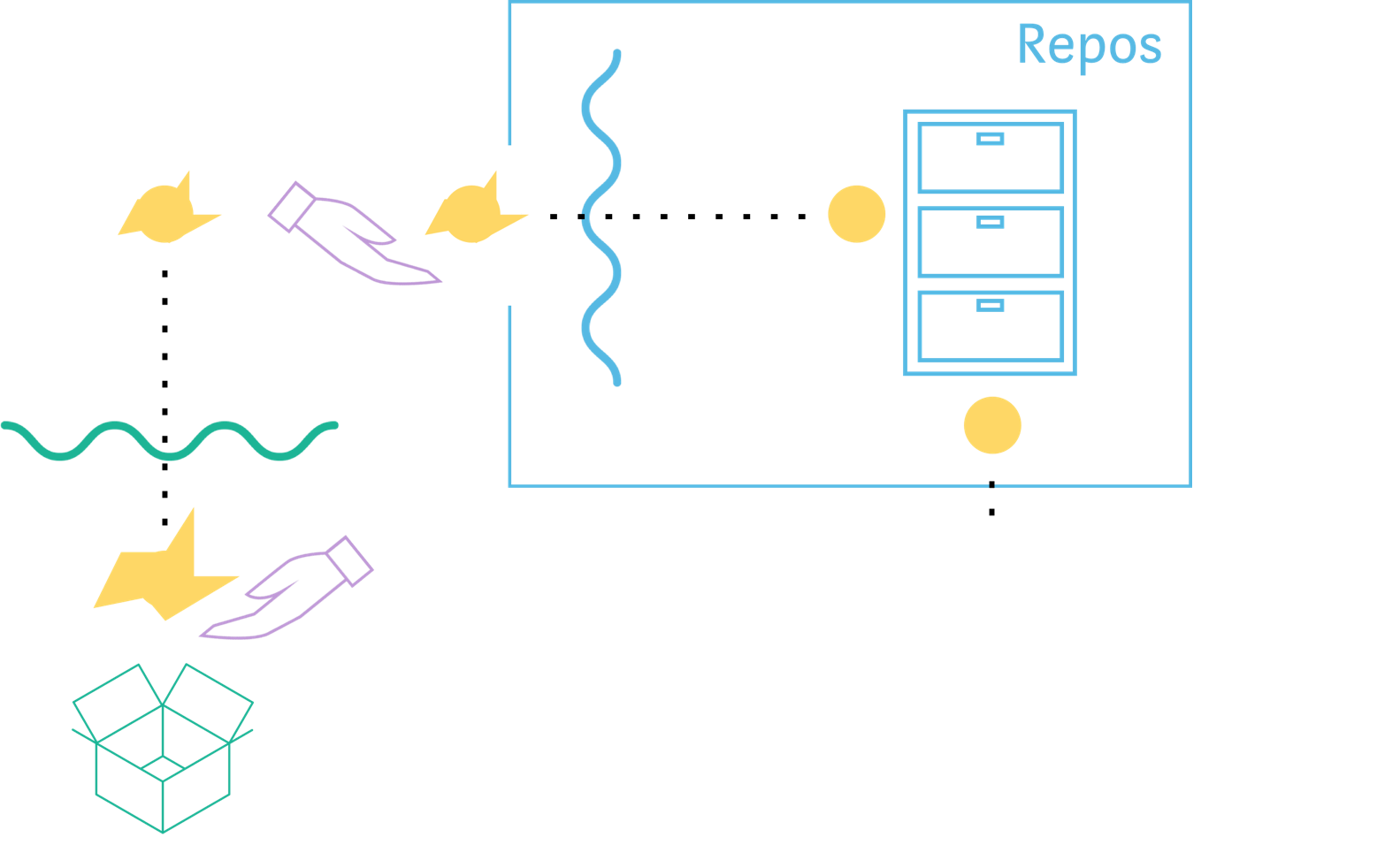
根据客户端需要设计数据
GraphQL 模型用存储库来做数据仓库。存储库“存储”了来自数据源的已处理过的数据。
在这一步,我们可以打包或展开字段和对象、移动数据,等等,将数据转化为客户端需要的格式。
从遗留的系统转型,这一步是必须的,因为它给了我们为客户端更新数据格式的自由,同时不用更新或者添加接口和相应的协议缓冲区。
存储库仅从获取器获取数据,实际上从不自己请求外界数据。换句话说,存储库只创建我们需要的数据格式,但是它们并不“知道”数据是从哪里获取的。
GraphQL 模型
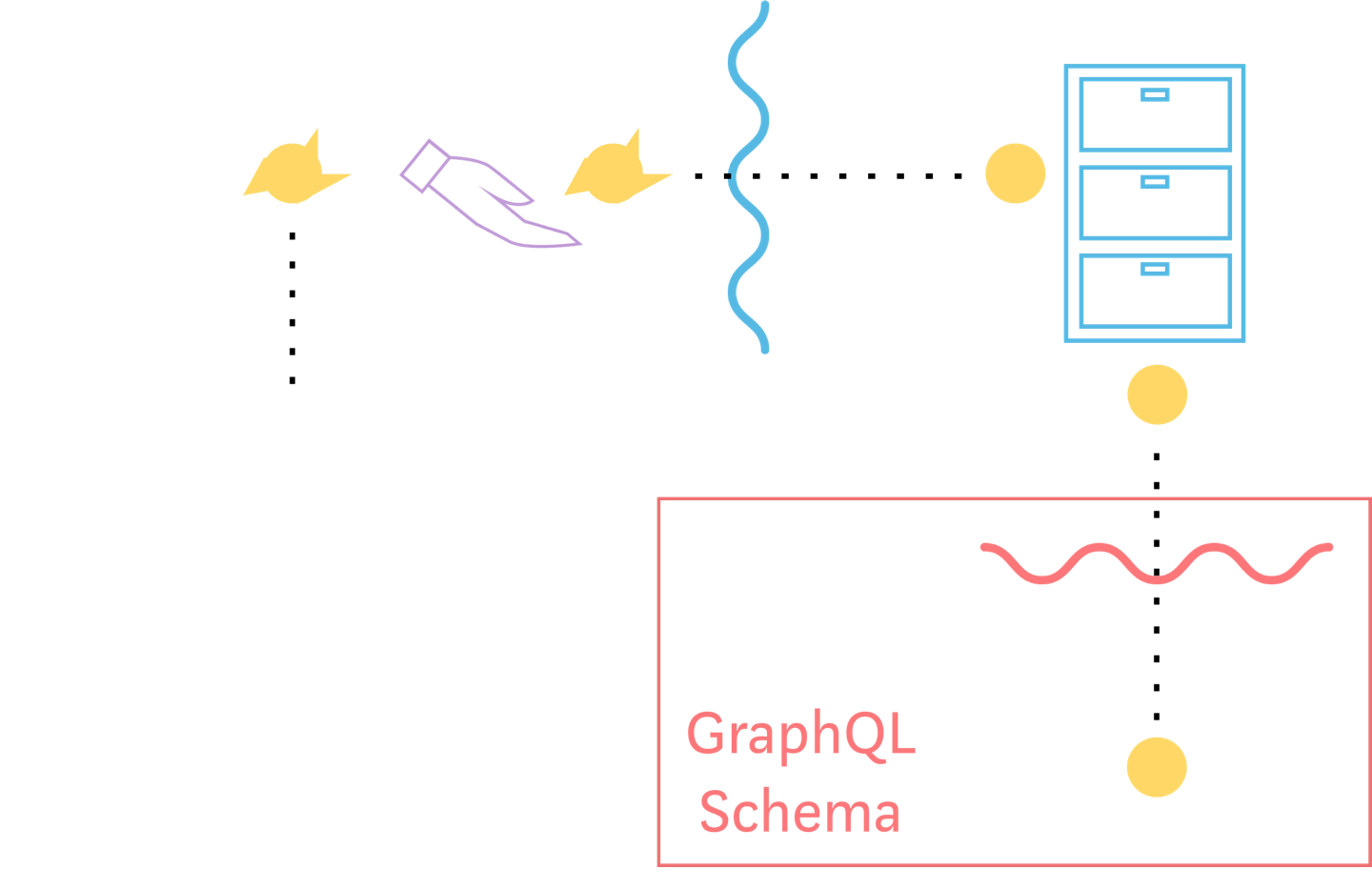
从存储库对象派生出客户端模型
GraphQL 模型是是数据发送到客户端的时候选取的格式。
GraphQL 模型仅使用存储库的数据,从不会直接和获取器交互。这使得我们能够清楚地将关注点分离开。
另外,GraphQL 模型是完全从存储库模型派生出来的。模型完全不会改变数据,它也并不需要:存储库已经将数据转化为我们需要的格式,所以模型只需要使用数据即可。这样,关于数据格式是什么样的或者是我们可以在哪里操作数据格式,就没有可混淆的了。
GraphQL 服务数据流
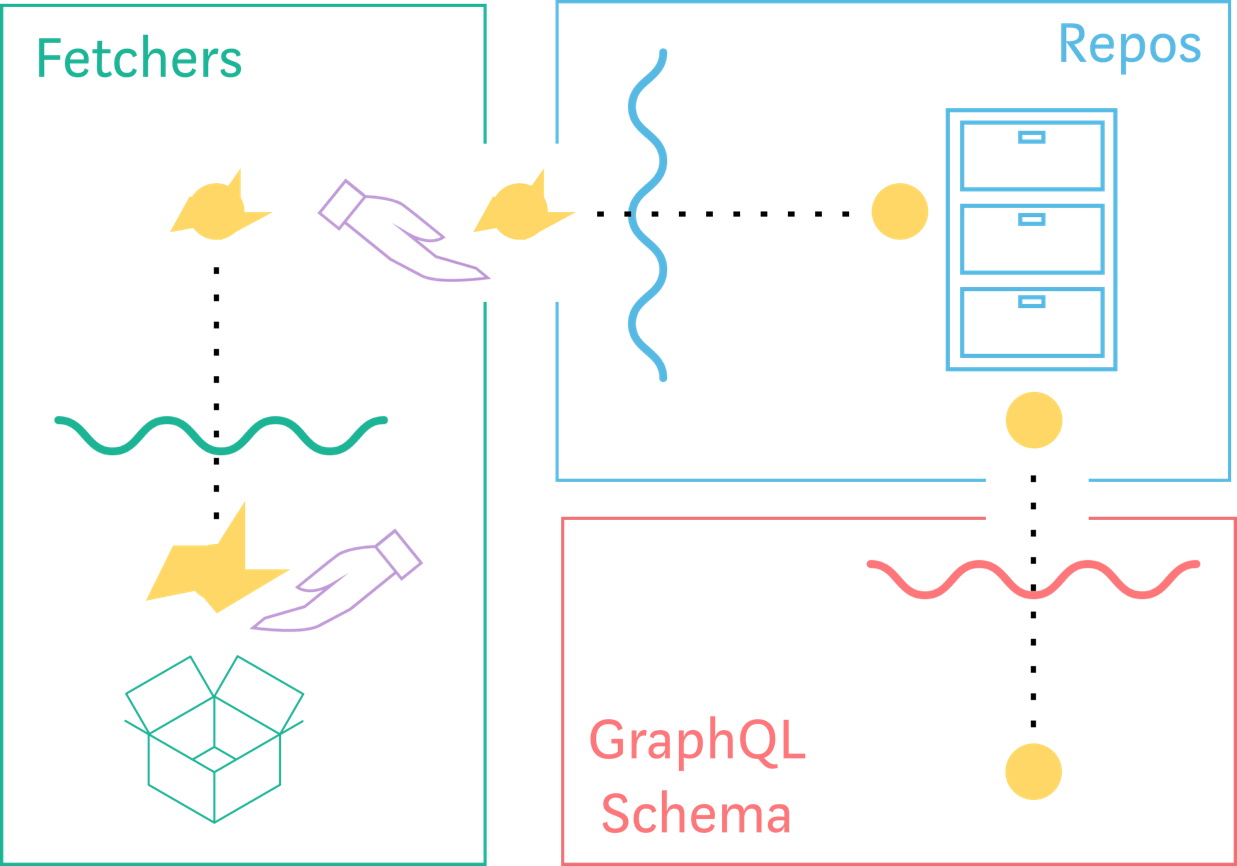
数据是如何在 GraphQL 服务中流动的
当数据通过不同的层时,它的格式都会变得更像客户端所需要的。每一步的数据来自哪里是很清楚的,我们也知道服务的每一部分都负责什么。
这些抽象边界意味着,我们可以通过替换不同的数据源增量地迁移遗留系统,但无需重写整个系统。这使我们的迁移方法清晰且易于遵循,同时在不立即更改所有内容的情况下,可以轻松地朝着面向服务的体系结构完成工作。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
