

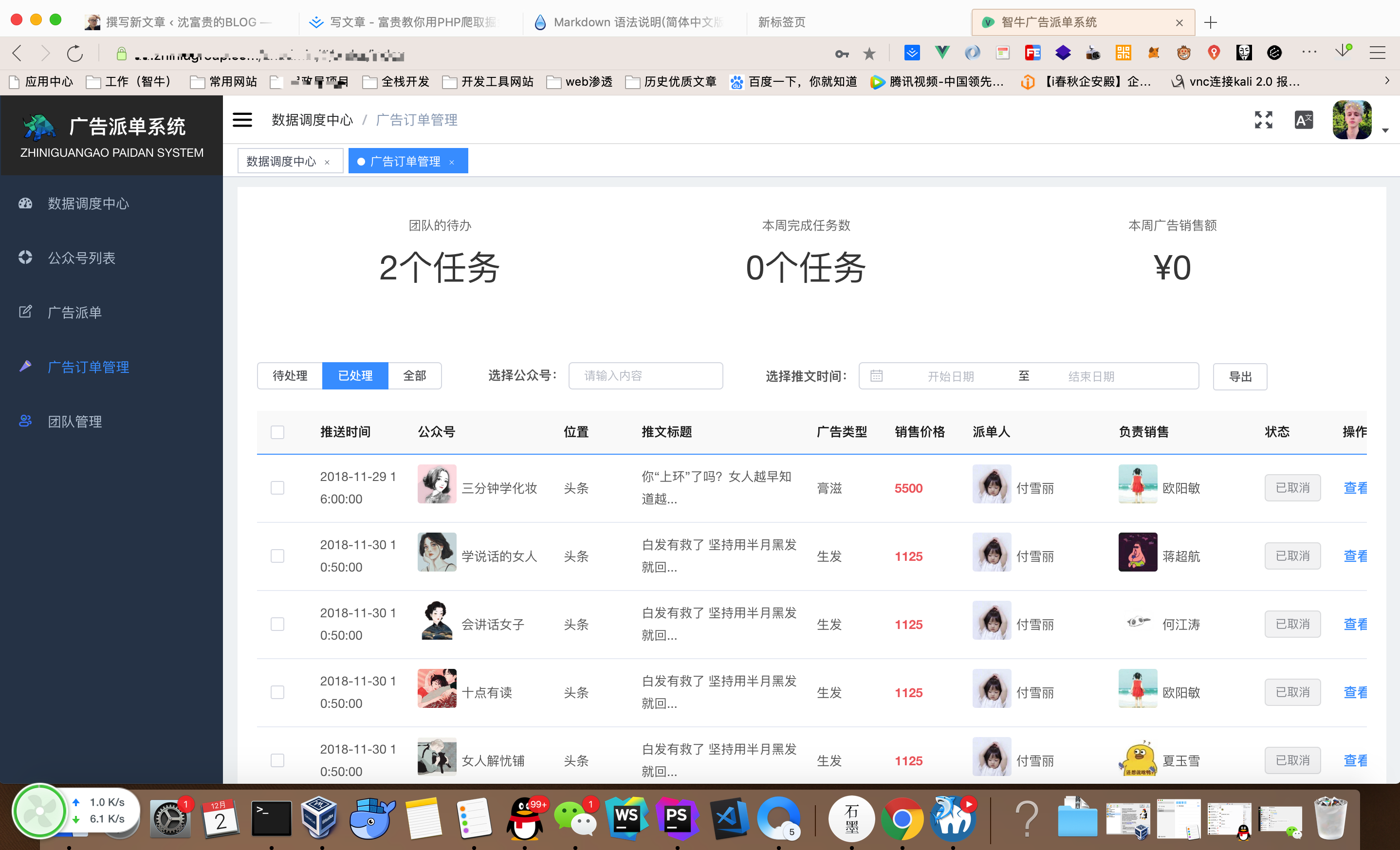
前言
新手村任务
下面这些是我2018年这半年业余时间研究的一些小东西,比较适合刚开始接触爬虫的人
- 文章爬虫(搜狗微信文章、某书、还有今日头条等)
- 音乐类的数据爬虫(主要基于NodeJS,网易云音乐的社区API)
- 微信文章点赞爬虫
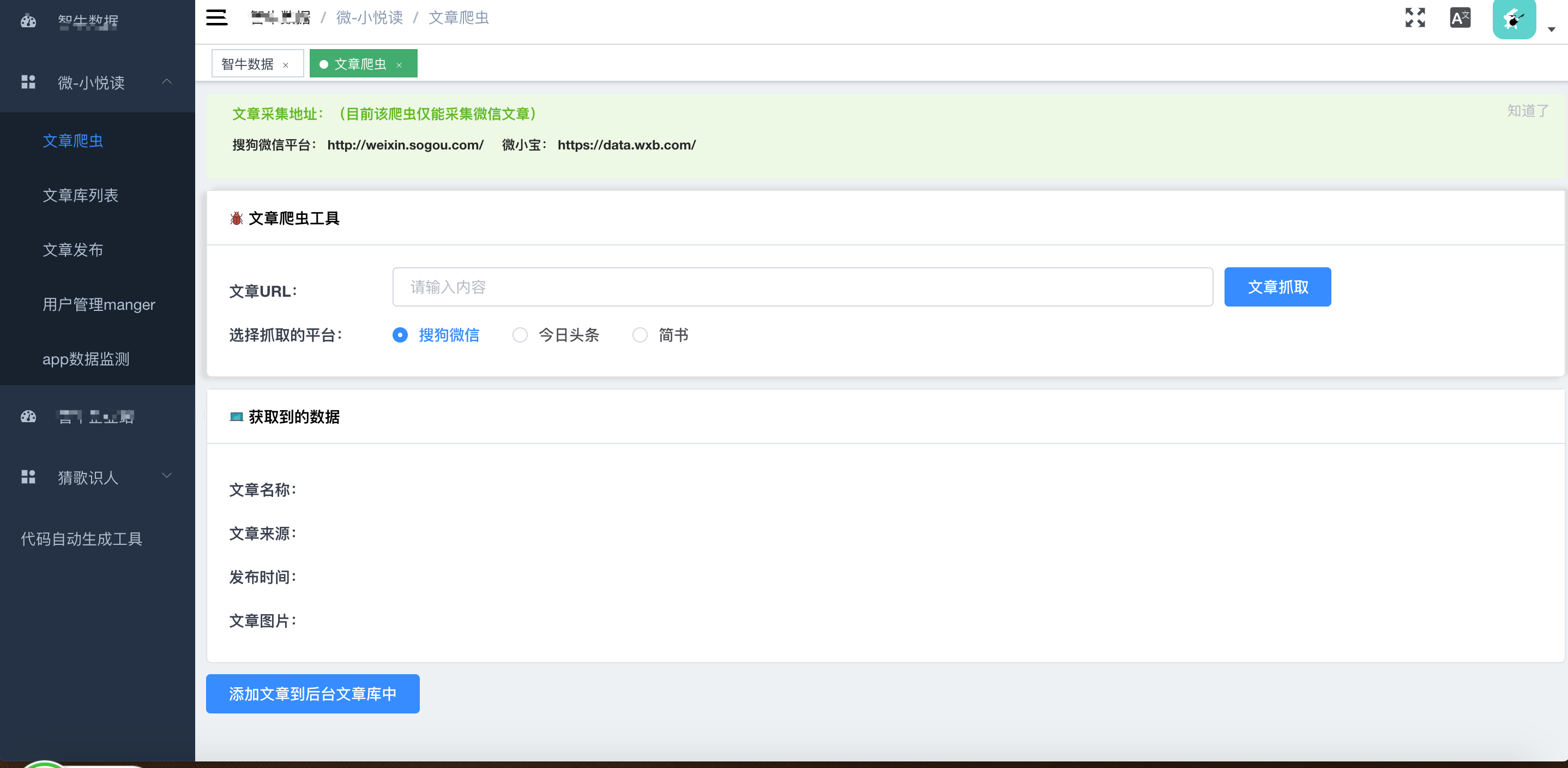
平时爬东西常用的工具推荐
- Charles (抓包工具)
- Anyproxy 也是一个抓包工具但是可以编程比较好玩
- adb 安卓调试桥 可以用python脚本控制安卓手机自动执行脚本
- simulator 网页抓包必备、还可以写自动化测试脚本
回归正题爬掘金文章
首先我打算使用最原始的方式去获取掘金的文章内容。我使用了PHP的curl和phpQuery来做这件事情。我发现文章内容获取到的是空。而且像图片这些资源是用<image>这样的标签包起来的没有得到正常解析。
很显然掘金的文章是异步加载的。而且通过curl去获取文章会发现文章内容是加密过的。
(我没有太多时间去研究他的加密规则)
我的思路很简单直接抓取渲染过后的数据。一般来讲要达到这个效果可以使用 simulator和phantomjs。使用simulator我本地是OK的好想服务器爆错了后来就用了phantomjs。
下面讲解一下这个项目需要的依赖和注意事项
1、注意事项(选择国内的源)
composer 方法一: 修改 composer 的全局配置文件(推荐方式) 打开命令行窗口(windows用户)或控制台(Linux、Mac 用户)并执行如下命令:
composer config -g repo.packagist composer https://packagist.phpcomposer.com
方法二: 修改当前项目的 composer.json 配置文件: 打开命令行窗口(windows用户)或控制台(Linux、Mac 用户),进入你的项目的根目录(也就是 composer.json 文件所在目录),执行如下命令:
composer config repo.packagist composer https://packagist.phpcomposer.com
2、需要安装的依赖
composer require "jonnyw/php-phantomjs:4.*"
3、Linux环境的特殊需求(修改依赖文件)
namespace JonnyW\PhantomJs\DependencyInjection;
/**
* Load service container.
*
* @access public
* @return void
*/
public function load($file = null)
{
$loader = new YamlFileLoader($this, new FileLocator(__DIR__.'/../Resources/config'));
$loader->load('config.yml');
$loader->load('services.yml');
$this->setParameter('phantomjs.cache_dir', sys_get_temp_dir());
$this->setParameter('phantomjs.resource_dir', __DIR__.'/../Resources');
}
修改PHP.ini开启一些系统函数
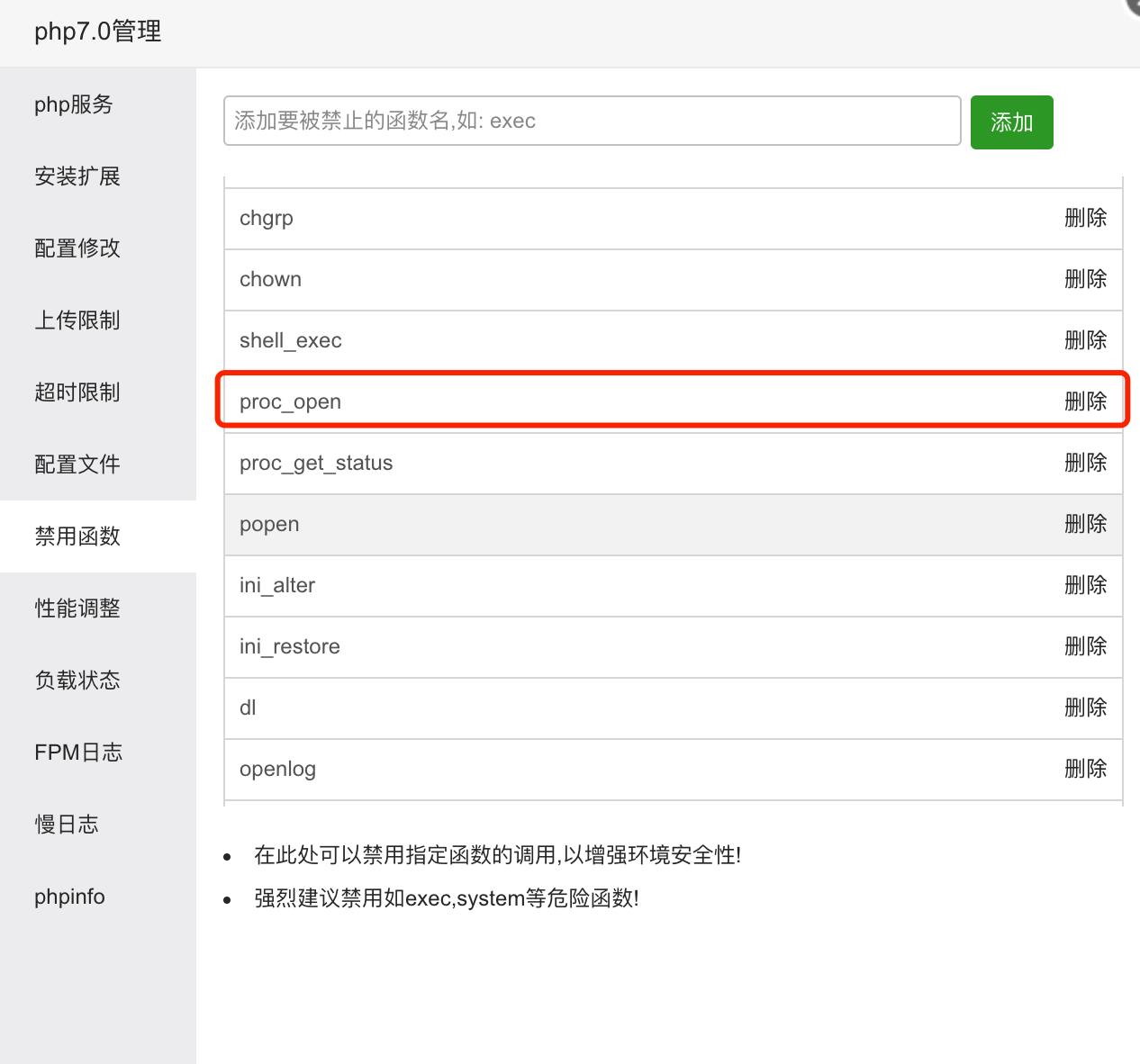
上代码
$client = Client::getInstance();
$client->getEngine()->setPath(ROOT_PATH . 'public' . DS . 'phantomjs'); //设置phantomjs位置
$client->getEngine()->addOption('--load-images=false');
$client->getEngine()->addOption('--ignore-ssl-errors=true');
$url = 'https://juejin.cn/post/6844903728646979597';
$request = $client->getMessageFactory()->createRequest($url, 'GET');
$timeout = 10000; //设置超时
$request->setTimeout($timeout);
$response = $client->getMessageFactory()->createResponse();
$client->send($request, $response);
$str = $response->getContent();
$num1 = strpos($str, '<article');
$num2 = strpos($str, '</article>');
$re_data = substr($str, $num1, $num2 - $num1);
$re_data .= '</article>';
$re_data = str_replace("data-src","src",$re_data);
// file_put_contents('3.html', $re_data);
return $re_data;
看效果
总结
这个爬虫比较简陋还没有做成全自动的、分布式、多线程的,PHP是世界上最好的编程语言。晚上想写一篇关于编程语言的文章。
