

本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。期待加入IOT时代最具战斗力的团队。QQ邮箱地址:1120746959@qq.com,如有任何学术交流,可随时联系。
概要
- 性能
- 吞吐量:broker或者clients应用程序每秒能处理多少字节(或消息)
- 延时:通常指Producer发送到broker端持久化保存消息之间的时间间隔。
- 可用性:系统和组件正常运行的概率或时间比率,业界一般N个9来量化可用性,比如年度4个9表示53分钟(365* 24 * 60 * 0.01%=53分钟)
- 持久性:已提交的消息需要被持久化到Broker端底层的文件系统的物理日志而不能丢失。
1 kafka 基础设施优化
-
磁盘容量:首先考虑的是所需保存的消息所占用的总磁盘容量和每个broker所能提供的磁盘空间。如果Kafka集群需要保留 10TB数据,单个broker能存储 2TB,那么我们需要的最小Kafka集群大小5 个broker。此外,如果启用副本参数,则对应的存储空间需至少增加一倍(取决于副本参数)。这意味着对应的Kafka集群至少需要 10 个broker。
-
文件系统在文件被访问、创建、修改等的时候会记录文件的一些时间戳,比如:文件创建时间(ctime)、最近一次修改时间(mtime)和最近一次访问时间(atime)。默认情况下,atime的更新会有一次读操作,这会产生大量的磁盘读写,然而atime对Kafka完全没用。
mount -o noatime -
绝大多数运行在Linux上的软件都是基于EXT4构建和测试的,因此兼容性上EXT4要优于其他文件系统。
-
作为高性能的64位日志文件系统(journaling file system),XFS表现出高性能,高伸缩性,特别适应于生产服务器,特别是大文件(30+GB)操作。很多存储类的应用都适合选择XFS作为底层文件系统。
-
计算机的内存分为虚拟内存和物理内存。物理内存是真实的内存,虚拟内存是用磁盘来代替内存。 并通过swap机制实现磁盘到物理内存的加载和替换,这里面用到的磁盘我们称为swap磁盘。在写文件的时候,Linux首先将数据写入没有被使用的内存中,这些内存被叫做内存页(page cache)。然后读的时候,Linux会优先从page cache中查找,如果找不到就会从硬盘中查找。 当物理内存使用达到一定的比例后,Linux就会使用进行swap,使用磁盘作为虚拟内存。 通过cat /proc/sys/vm/swappiness可以看到swap参数。这个参数表示虚拟内存中swap磁盘占了多少百分比。0表示最大限度的使用内存,100表示尽量使用swap磁盘。系统默认的参数是60,当物理内存使用率达到40%,就会频繁进行swap,影响系统性能,推荐将vm.swappiness 设置为较低的值1。 最终我设置为10,因为我们的机器的内存还是比较小的,只有40G,设置的太小,可能会影响到虚拟内存的使用吧。
临时修改:sudo sysctl vm.swappiness=N 永久修改(/etc/sysctl.conf):vm.swappiness=N
2 kafka JVM设置
-
PermGen space : 全称是Permanent Generation space,是指内存的永久保存区域,为什么会发生内存溢出?这一部分用于存放Class和Meta的信息, Class在被 Load的时候被放入PermGen space区域,它和存放Instance的Heap区域不同,所以如果你的APP会LOAD很多CLASS的话,就很可能出现PermGen space错误。
-
G1算法将堆划分为若干个区域(Region),它仍然属于分代收集器。不过,这些区域的一部分包含新生代,新生代的垃圾收集依然采用暂停所有应用线程的方式,将存活对象拷贝到老年代或者Survivor空间。老年代也分成很多区域,G1收集器通过将对象从一个区域复制到另外一个区域,完成了清理工作。这就意味着,在正常的处理过程中,G1完成了堆的压缩(至少是部分堆的压缩),这样也就不会有cms内存碎片问题的存在了。
-
在G1中,还有一种特殊的区域,叫Humongous区域。 如果一个对象占用的空间超过了分区容量50%以上,G1收集器就认为这是一个巨型对象。这些巨型对象,默认直接会被分配在年老代,但是如果它是一个短期存在的巨型对象,就会对垃圾收集器造成负面影响。为了解决这个问题,G1划分了一个Humongous区,它用来专门存放巨型对象。如果一个H区装不下一个巨型对象,那么G1会寻找连续的H分区来存储。为了能找到连续的H区,有时候不得不启动Full GC。
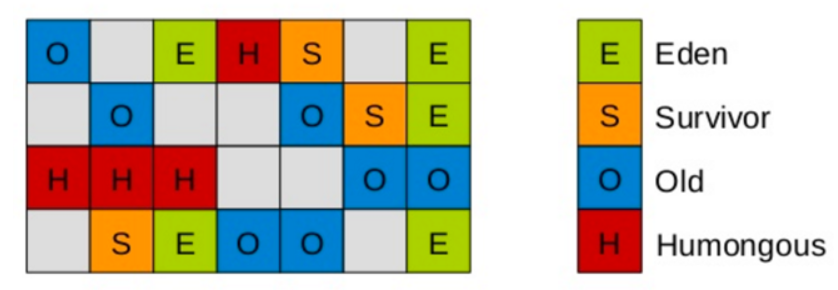
-
G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
-
G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
-
G1的收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而降低停顿。
-
堆内存中一个Region的大小可以通过-XX:G1HeapRegionSize参数指定,大小区间只能是1M、2M、4M、8M、16M和32M,总之是2的幂次方,如果G1HeapRegionSize为默认值,则在堆初始化时计算Region的实践大小,默认把堆内存按照2048份均分,最后得到一个合理的大小。
-
JVM 8 metaSpace 诞生了: 不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小: -XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集 -XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
-
XX:MaxGCPauseMillis=n : 设置最大GC停顿时间(GC pause time)指标(target). 这是一个软性指标(soft goal), JVM 会尽量去达成这个目标。
-
InitiatingHeapOccupancyPercent: 整个堆栈使用达到百分之多少的时候,启动GC周期. 基于整个堆,不仅仅是其中的某个代的占用情况,G1根据这个值来判断是否要触发GC周期, 0表示一直都在GC,默认值是45(即45%慢了,或者说占用了)
-
-XX:G1NewSizePercent 新生代最小值,默认值5%
-
-XX:G1MaxNewSizePercent 新生代最大值,默认值60%
-
MetaspaceSize: 这个JVM参数是指Metaspace扩容时触发FullGC的初始化阈值,也是最小的阈值。
# export JAVA_HOME=/usr/java/jdk1.8.0_51 # export KAFKA_HEAP_OPTS=" -Xmx6g -Xms6g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+G1HeapRegionSize=16M -XX:MinMetaspaceFreeRatio=50 " -
本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。期待加入IOT时代最具战斗力的团队。QQ邮箱地址:1120746959@qq.com,如有任何学术交流,可随时联系。
3 文件调优
-
若出现"too many files open"错误时,就需要为Broker所在的机器调优最大文件部署符上限。文件句柄个数计算方法如下:
broker上可能最大分区数*(每个分区平均数据量/平均的日志段大小+3)其中3 表示索引文件个数, 假设20个分区,分割分区总数据量为100GB,每一个日志段大小是1GB,那么这台机器最大文件部署符大小应该是: 20*(100/1+3)=2060 因此该参数一定要设置足够大。比如100000 -
若出现"java.lang.OutOfMemoryError:Map failed的严重错误,主要原因是大量创建topic将极大消耗操作系统内存,用户可以适当调整vm.max.map.count参数,具体方法如下:
/sbin/sysctl -w vm.max_map_count = N ,该参数默认值是65535,可以考虑线上环境设置更大的值。
4 吞吐量
Broker端;
- 适当增加num.replica.fetchers,但不要超过CPU核数,该值控制了broker端follower副本从leader副本处获取消息的最大线程数。默认值是1,表明follower副本只使用一个线程实时拉取leader处的最新消息。对于设置了acks=all的producer而言,主要延时可能耽误在follower与leader同步过程,所以增加该值可以缩短同步的时间,从而间接的提升Producer端的TPS。
- 调优GC避免经常性的Full GC。老版本过渡依赖Zookeeper来表征Consumer还活着,若GC时间过长,会导致Zookeeper会话过期,kafka会立即对group进行rebalance。新版本上已经弃用了对Zookeeper的依赖。
Producer端:
- 适当增加batch.size,比如100-512KB。
- 适当增加linger.ms,比如10-100毫秒 Producer端是批量发送消息的,更大的batch size可以令更多的消息封装进同一个请求,故发送给broker端的总请求数就会减少,此举可以减轻Producer的负载,也降低了broker端的CPU请求处理开销。而更大的linger.ms使producer等待更长的时间才发送消息,这样就能够缓存更多的消息填满batch,从而从整体上提升TPS。但是延时肯定增加了。
- 设置压缩类型compression.type=lz4,目前支持的压缩方式有:GZIP,Snappy,LZ4,在CPU资源丰富的情况下compression.type=lz4的效果是最好的。
- acks=0或1
- retries=0
- 若多线程共享Produer或分区数很多时,增加buffer.memory。因为每一个分区都会占用一个batch.size。
consumer端
- 采用多Consumer实例,共同消费多分区数据,这些实例共享相同的group.id。
- 增加fetch.min.bytes,比如10000,表征每次leader副本所在的broker所返回的最小数据量来间接影响TPS,通过增加该值,Kafka会为每一个FETCH请求的response填入更多的数据。
5 悖论存在(分区数越多,TPS越高)
- Kafka基本的并行单元就是分区,producer在设计时实现了能够同时向多个分区发送消息,从而这些消息最终写入到多个broker上,最终可以被多个consumer同时消费。通常来说,分区数越多,TPS越高
- 分区数越多,占用的缓冲区越多,因为缓冲区是以分区为粒度的,所以Server/clients端将占用更多的内存。
- 每一个分区在底层文件系统中都有专属目录,除了3个索引文件外还保存日志段文件,会占用大量的文件句柄。
- 每一个分区都有若干个副本保存在不同的broker上,当broker挂掉后,因为需要Controller进行处理leader变更请求,该处理线程是单线程,疯了吧,亚历山大。
- 本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。期待加入IOT时代最具战斗力的团队。QQ邮箱地址:1120746959@qq.com,如有任何学术交流,可随时联系。
7 总结
num.replica.fetchers倒是一个新颖的选手,可以好好试试,acks重点关注,其他都中规中矩。一片好文得来不易,尊重原创,谢绝转载,谢谢!
本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。期待加入IOT时代最具战斗力的团队。QQ邮箱地址:1120746959@qq.com,如有任何学术交流,可随时联系。
秦凯新 于深圳 201812032355
