

11 月 23 日,由七牛云主办的主题为「AI 产业技术的渗透与融合」的 NIUDAY 小牛汇共享日在北京举行。会上,七牛云技术总监陈超为大家带来了题为《数据智能时代的智慧工厂实践》的内容分享。
以下是演讲内容的实录整理。

今天要介绍的是智慧工厂的相关内容。本次 NIUDAY 的主题跟 AI 有关,我们这边其实是结合了大数据跟 AI 的技术去帮助大家解决了一些问题。首先我想介绍下我们的产品主要是用来服务哪些场景的。
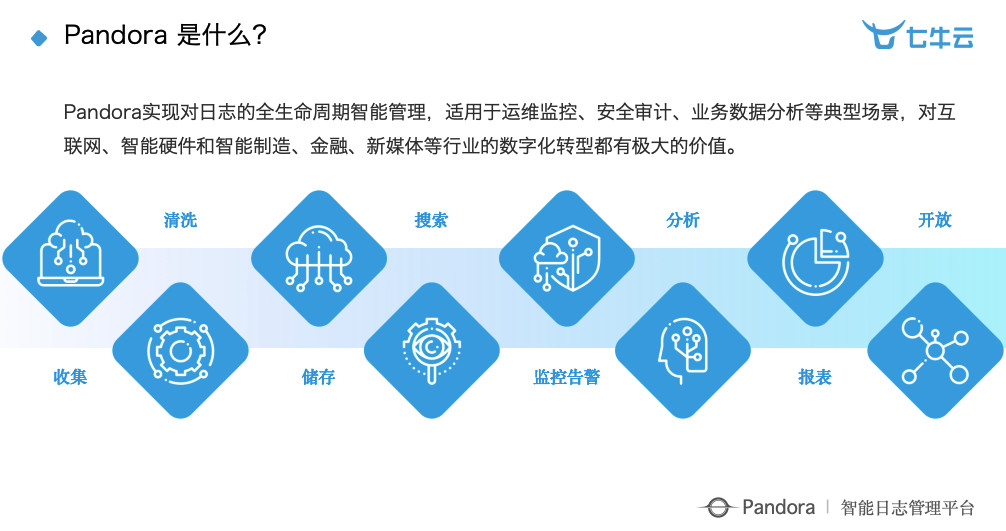
Pandora 是一个以大数据技术为基础的日志平台,这张图可以非常清晰快速的看到整个产品的全貌。
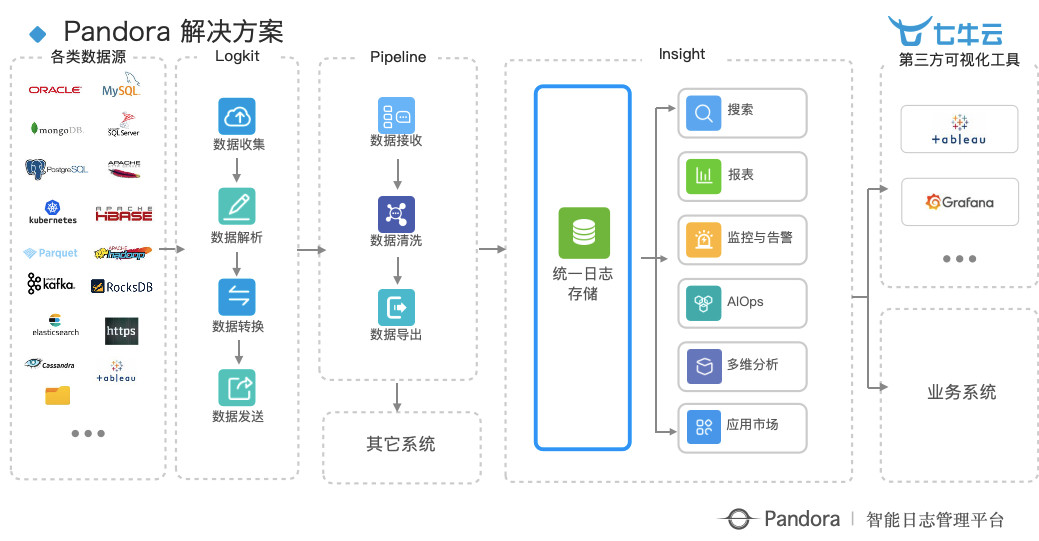
最前面是收集、清洗等繁杂的工作,后面落地到统一的日志存储,再到搜索、报表、监控告警、AIOps、多维分析、应用市场等等,我们目前有如下几个重点场景:
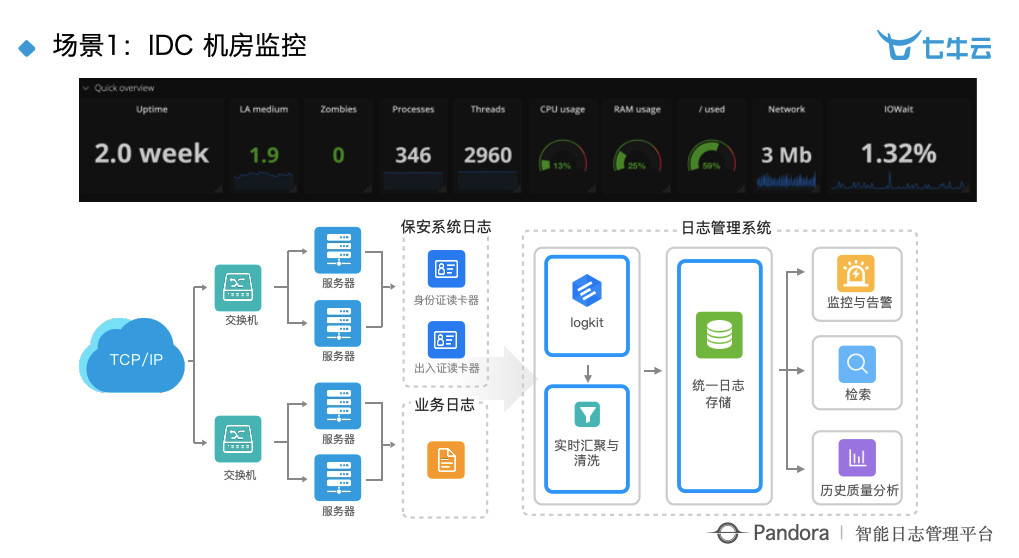
场景 1: IDC 机房监控。现在整个 IT 行业,尤其是传统企业的变革是非常大的。国内不少的银行、基金公司、运营商等都是在用我们这套东西,帮他们做一个统一的、精细化的分析与管理。以前运维就是运维,用一些非常简单的运维软件收集他们的数据,但是现在的新趋势是:把运维当做运营来做,并且做的非常精细。
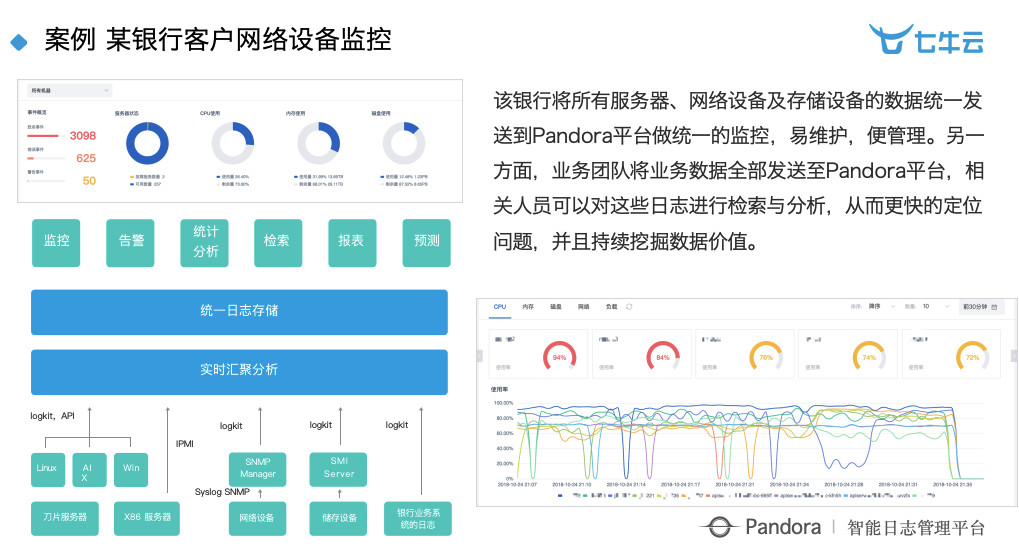
上图是一个银行客户的网络设备监控,但实际上大家会看到,所呈现的不是一个监控告警的东西,而是帮他做了很多报表,做了很多智能分析、预测。这是非常有用的,我们接下来的做法是把一些智能技术快速融入到一些非常传统的场景里面,去帮他解决实际问题。
场景 2:应用质量的管理。目前有很多客户都在用我们应用质量的监控。具体主要是监控告警+检索+全链路分析+趋势预测。

这也是一家银行的具体案例,他们采用的是 Tomcat + Spring + MyBatis 这种架构。当时给我们的要求是,他要做到业务代码全链路的端到端的监控,并且要求快速检索所有的日志。我们帮他们解决的问题在于端到端的全链路的监控,每一步的调用、耗时、出的问题都可以直接展示出来。对方得到的价值在于,几乎不用改代码就能知道整个交易系统里面的底层执行情况。
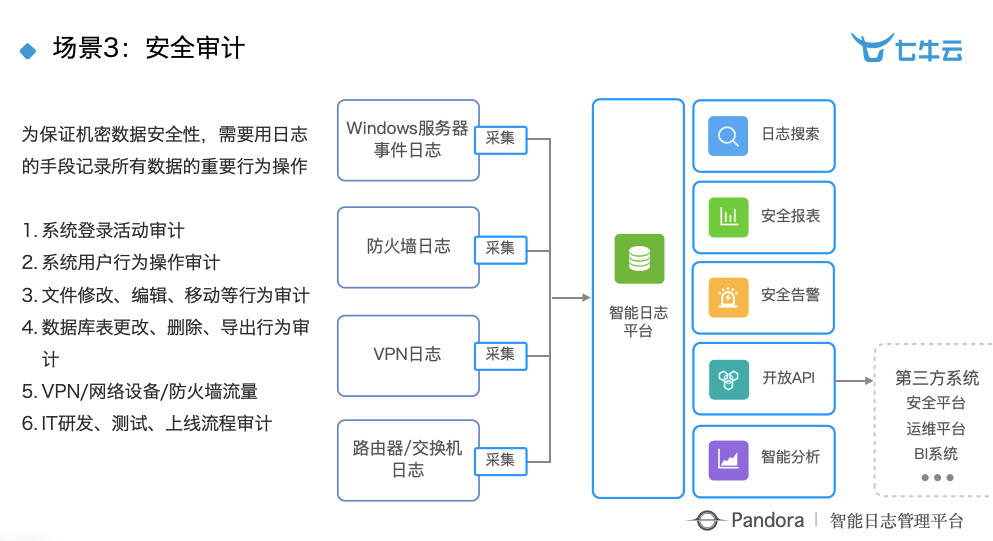
场景 3:安全审计。所有企业无论是互联网企业还是传统企业,他们对安全越来越重视,所以大家看到 Windows 服务器事件、防火墙日志、VPN 日志等等全部要采集起来做分析。之前的做法其实是和硬件厂商合作,他们的规则非常死,也没有办法做特别复杂的分析,尤其没办法做关联分析,因为各家硬件厂商只顾自己的数据,而我们相当于把全部都串起来了,并且非常灵活。
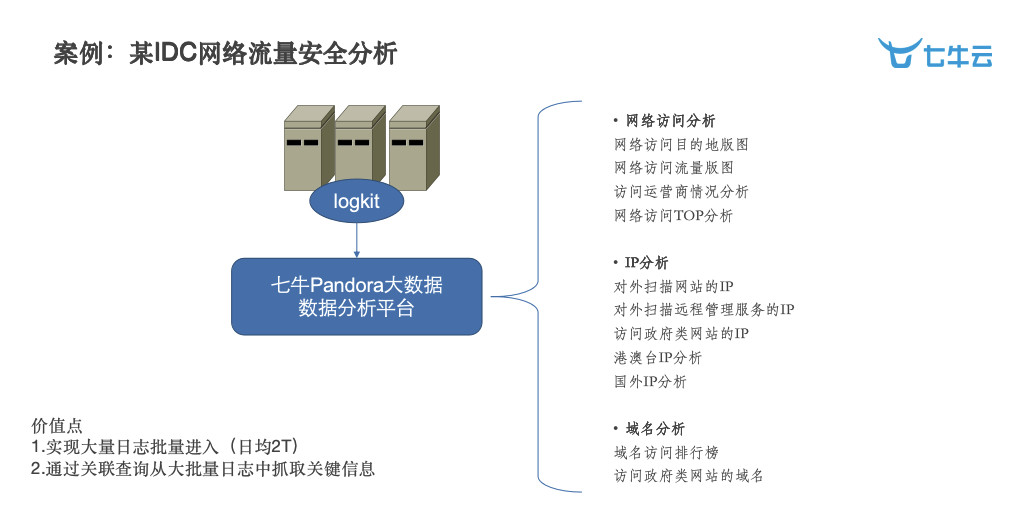
这是一个非常典型的例子,在国内也是一个非常大的 IDC 的提供商,他利用平台做了各种各样网络访问的分析,包括 IP 分析、域名分析等等。这样给他带来的价值在于:现在 IDC 的压力很大,只要出现一些不法的网站在你那里运行着,你可能就要背锅;另外,有些外部的黑客对于 IDC 的攻击越来越厉害,并且呈现了一定的规律,怎么帮他更好的分析,我们这边也做了很多的工作。
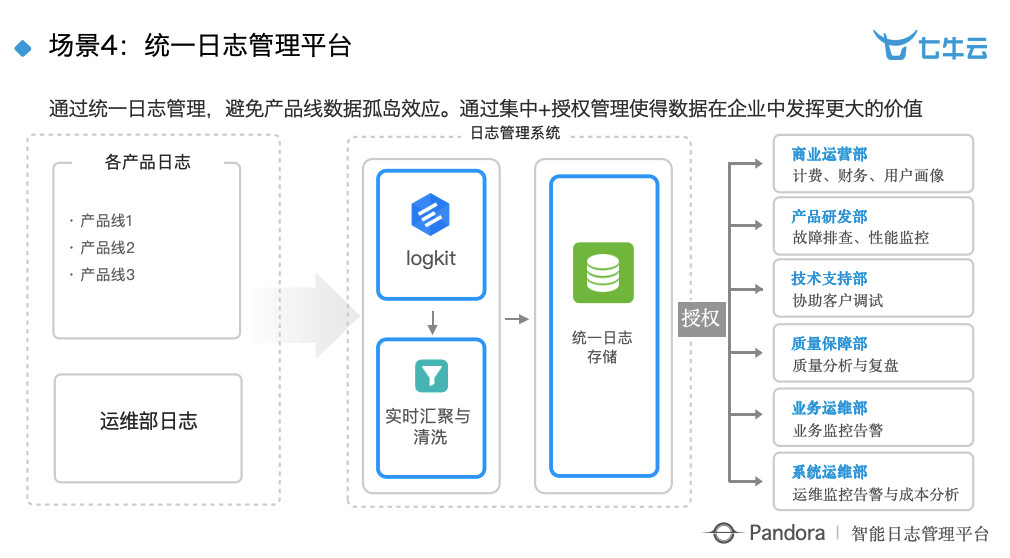
场景 4:统一的日志管理平台。实际上七牛云自己就在使用这套东西,每天往这里面灌入数据。在会前,我刚刚看了一下,昨天公司内部往里面灌的裸数据应该是 200 多个 T,包括运维数据、线上的一些审计日志的数据等等,每天裸数据是 200T,非常庞大。这些数据其实是统一采集、统计,汇聚到统一的日志里面做存储。
大家可以看到,图上右边每一个部门其实都在用这些数据来做具体的事情。可以看到以前很多部门跟数据其实没有关系,例如质量保障部、业务运维部等等,现在他们运用数据做大量的数据,尤其是运维部现在对整个公司的资产。因为七牛云服务器特别多,需要做非常精细化的管理。比如以前一个部门说服务器不够了,需要增加几百台,可能很容易就批了,但现在如果没有把资源用好,就不会批了。
此外目前有不少银行也在采用我们这一套产品作为统一的日志分析平台。
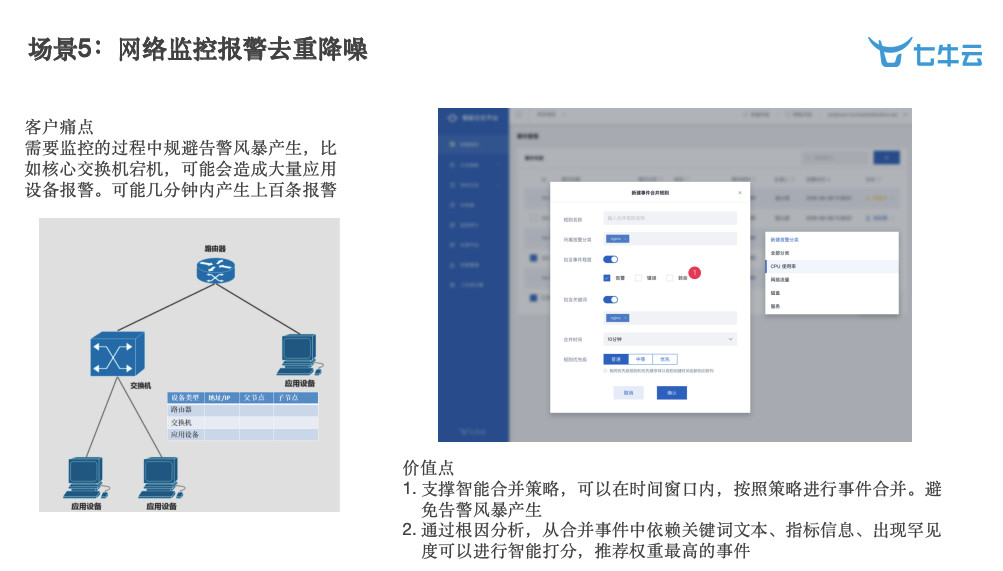
场景 5:网络监控报警去重降噪。报警太多了,告警风暴出来,也不能给出一些建议,也不知道是在什么地方出了问题。我们帮助解决了一些告警的合并策略,包括根因分析等等,甚至可以给出告警的报表。我们已经在公有云上线了全新的告警云平台,非常的强大和人性化,欢迎大家体验使用。
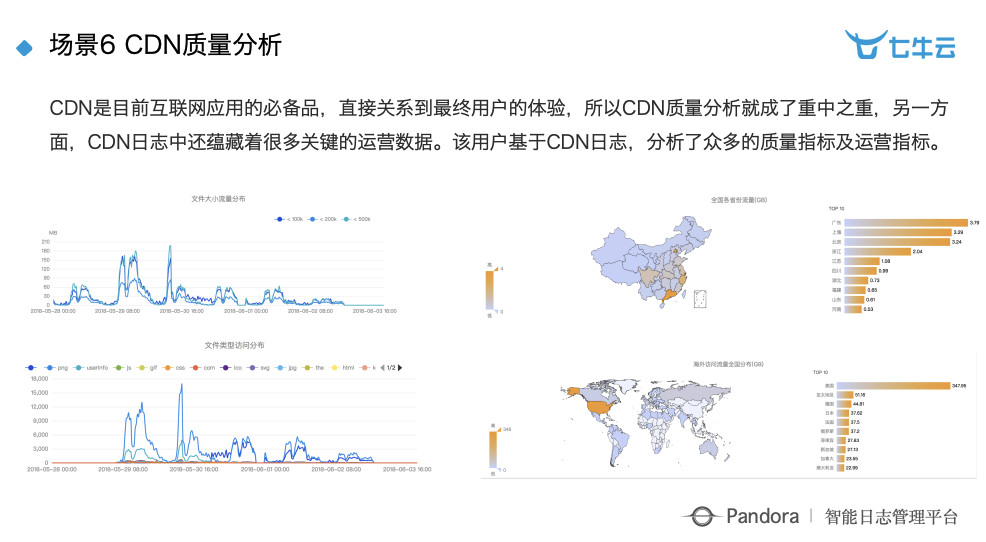
场景 6:CDN 质量分析。这个很多互联网公司都在用。我们的特点在于,之前的 CDN 公司,很难做到每一条访问日志的都可以被快速检索,而我们这边可以精细化到每一条访问日志,任意一个人在任意一个运营商,任意一个地点去点一个东西都能追踪到,但缺点就是成本相对高一些,所以这方面我们也在做大量的优化。
下面简单介绍 Pandora 平台的产品模块:
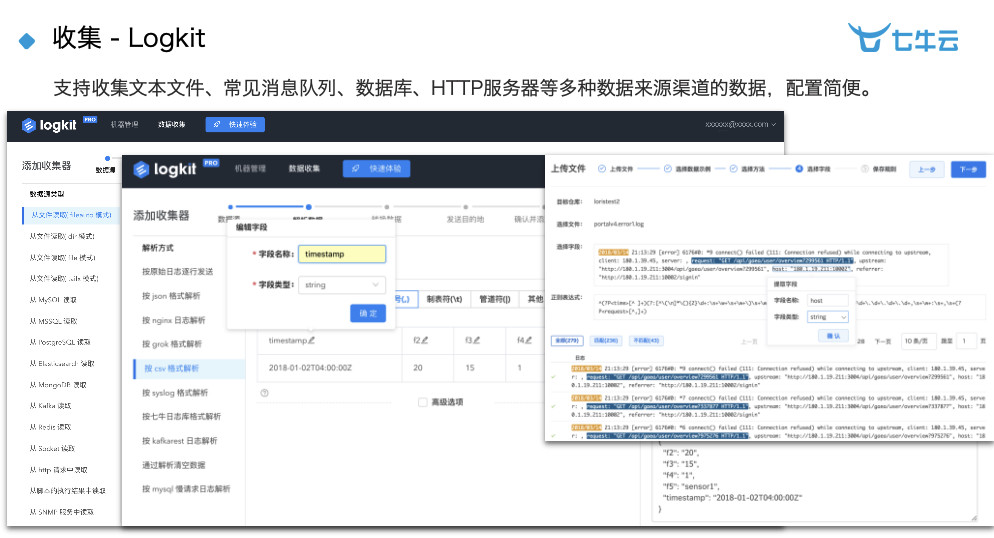
收集界面可以完全可视化的收集,几乎可以看到所有的数据源。
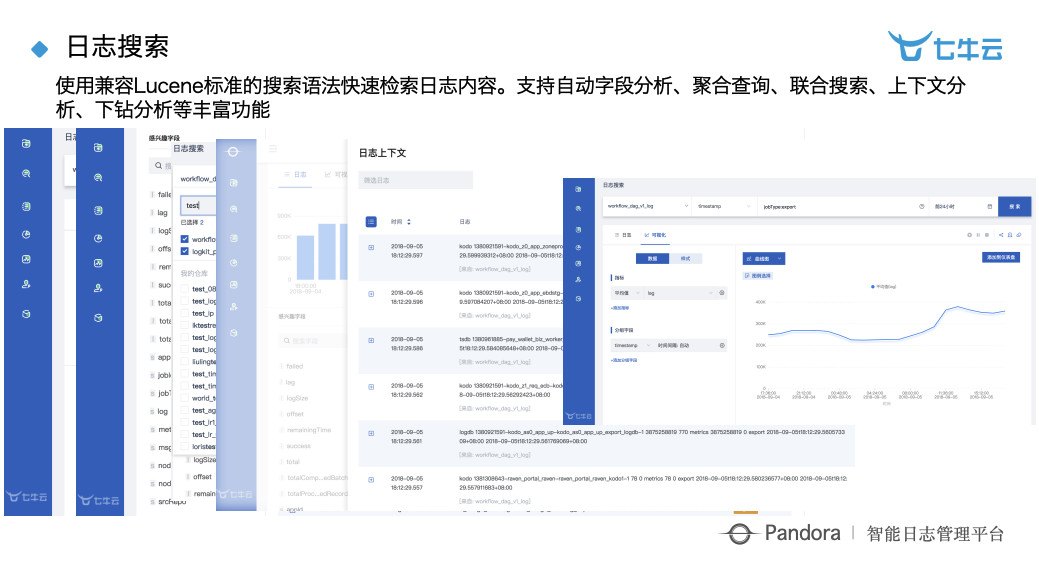
日志搜索。用过 ES 的都可以发现,我们这个其实是比 ES 功能更强大,可以帮你原生的做出很多报表来,并且可以按照时间、字段进行关联分析等等。我们也支持上下文的检索,检索完一个日志以后想看看上面发生了什么,下面发生了什么都是原生支持的。这个现在叫做搜索即报表,搜索以后直接通过报表的形式呈现,非常方便。
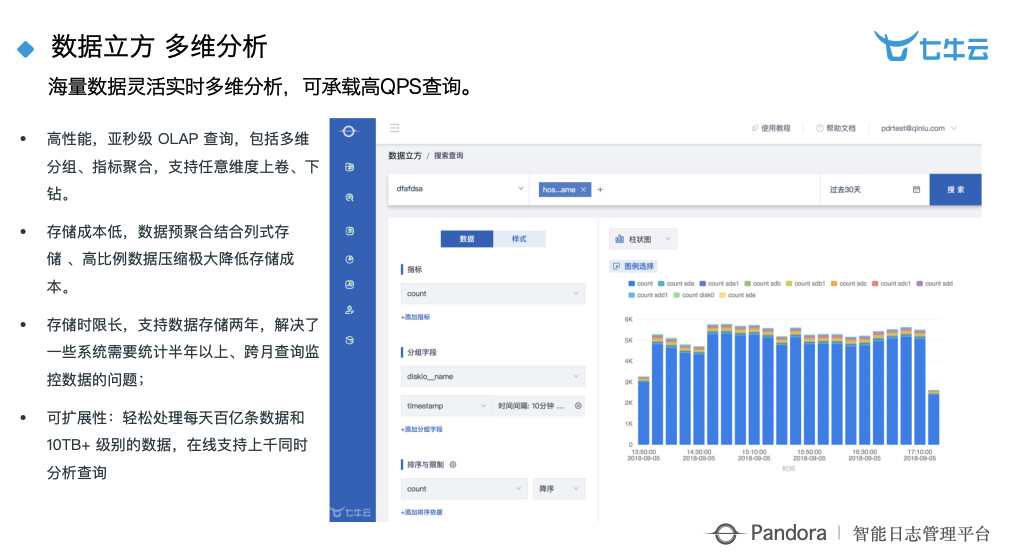
数据立方是为了弥补之前搜索场景的一些弊端。当我的数据表特别宽的时候,效率基本上就没法提升,所以数据立方本质上解决的是一个多维度的实时的分析。七牛云现在内部所有的类似于 Nginx 的分析全部都迁移到这上面来了,之前查询是 15 秒左右,现在我们查询是 200 毫秒左右,特别快。
数据立方目前应用较多的场景是广告点击,然后就是流量实时监控和安全事件的分析。我们每天进入数据立方分析的数据大概在 50 个 T 左右,50 个 T 进去分析完,落地基本只有 50 个 G 或者 100 个 G 左右,所以是一个低成本、高效率的分析引擎。
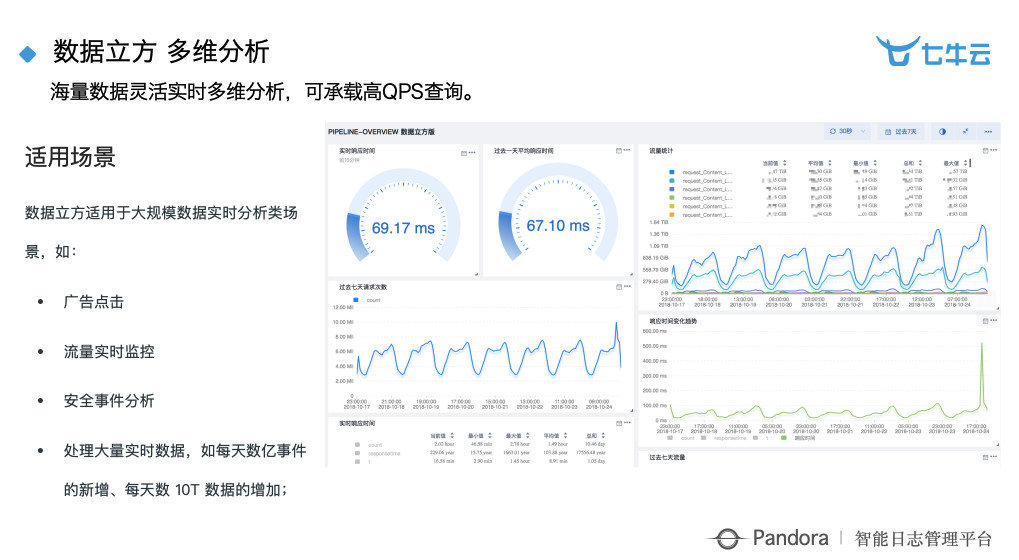
右边的图是我们一个线上的图,可以看到实时响应的时间是 69 毫秒,过去一天平均响应时间是 67 毫秒,过去七天的时间甚至一个月的时间,实际上拉长时间宽度,监控报表的响应时间也不会变长。
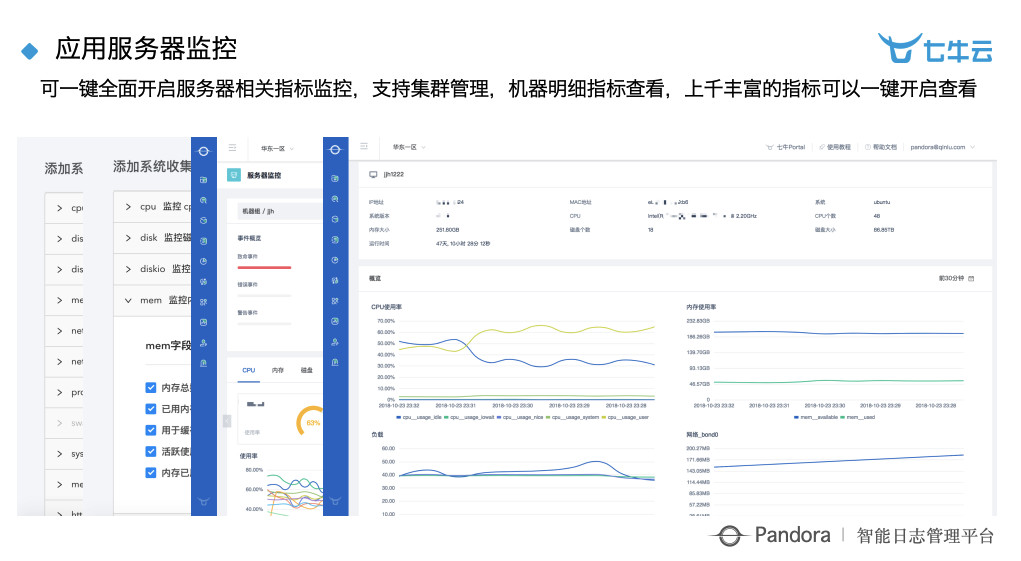
应用服务器监控。有一些应用市场在里面完全不需要配置,把我们的东西装好这些内容就自动有了。
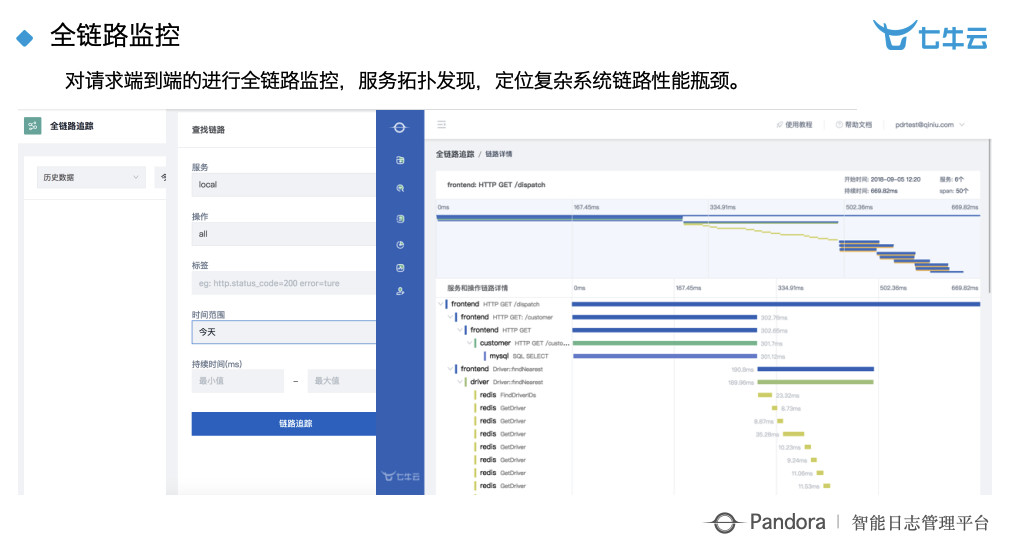
全链路监控也是在应用市场里面的,现在应用市场里面有三块内容:服务器监控、全链路监控、CDN 分析。我们全链路的监控可以看出服务拓扑、定位性能瓶颈等等,看到访问时间落到什么时间段内,有时候一到高峰期,可能时间就开始变慢了。全链路监控能给你从端到端的分析,从前端开始发送数据,到下面每一次调用都可以很强大的把具体的内容显示出来。七牛云内部这一块基本上全部覆盖了,也就是说大家每次访问七牛云存储的图片,就有这个东西在背后做支撑。
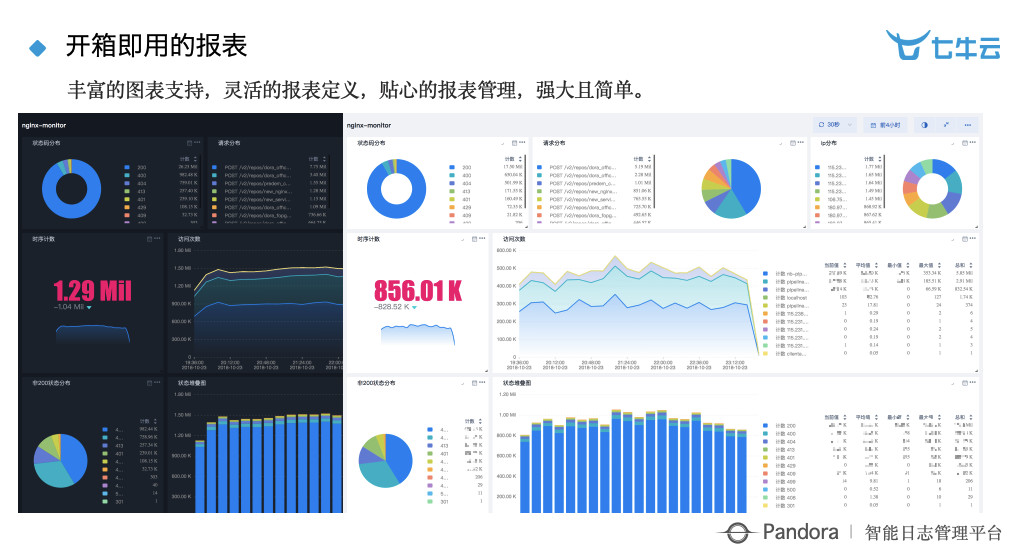
报表在这里不细讲,我们在这方面做的目前已经相当不错,客户反映也非常好。
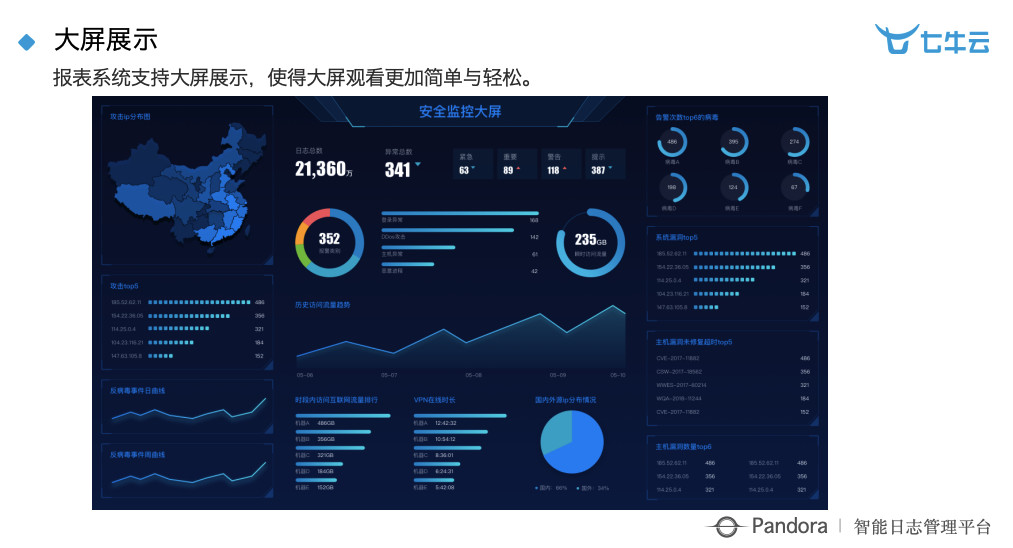
这个是帮杭州一家公司做的安全的监控大屏,也是比较酷的一个屏幕,让他们放在运维的大屏幕上。
接下来重点介绍机器学习。
机器学习会有一个特点,我们是做异常检测的,也就是现在比较流行的 time series 分析。做这个事情如果还要暴露算法的话就对用户太残忍了,所以我们花了特别大的功夫在背后大概做了十几种算法,然后做自动的融合,算法对用户完全屏蔽。用户只要选择一下他的数据源是什么,就可以帮他做实时分析和预测。
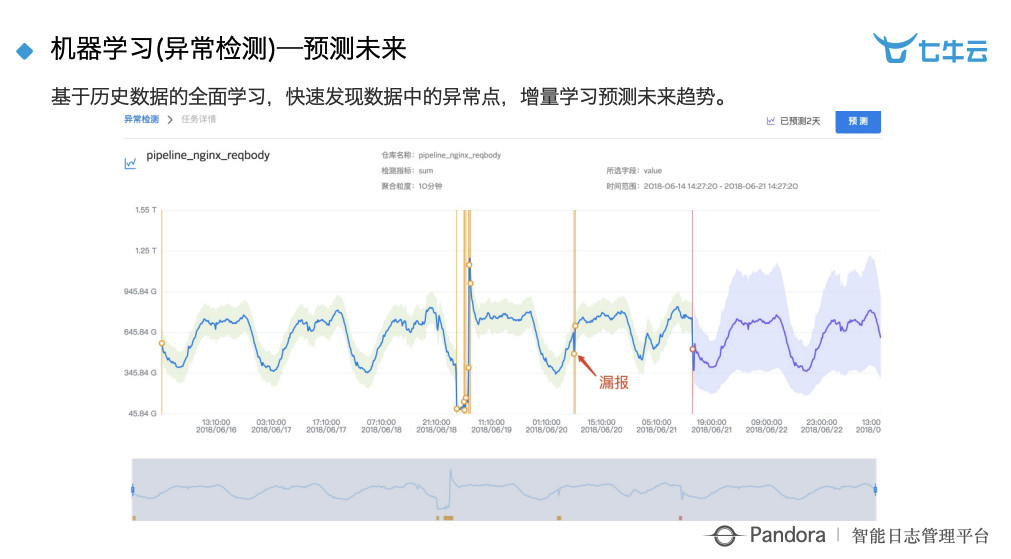
在平台上要如何使用这个东西?首先,你要对这个数据源做异常检测,它就会出来一个图,告诉你我要预测;我要预测多久,说预测一天,右边紫色的部分就会把预测时间给打出来。所有异常点会在下面展示出来,七牛云现在整个容量规划包括一些高峰期的预测全跑在上面,效果是非常好的。
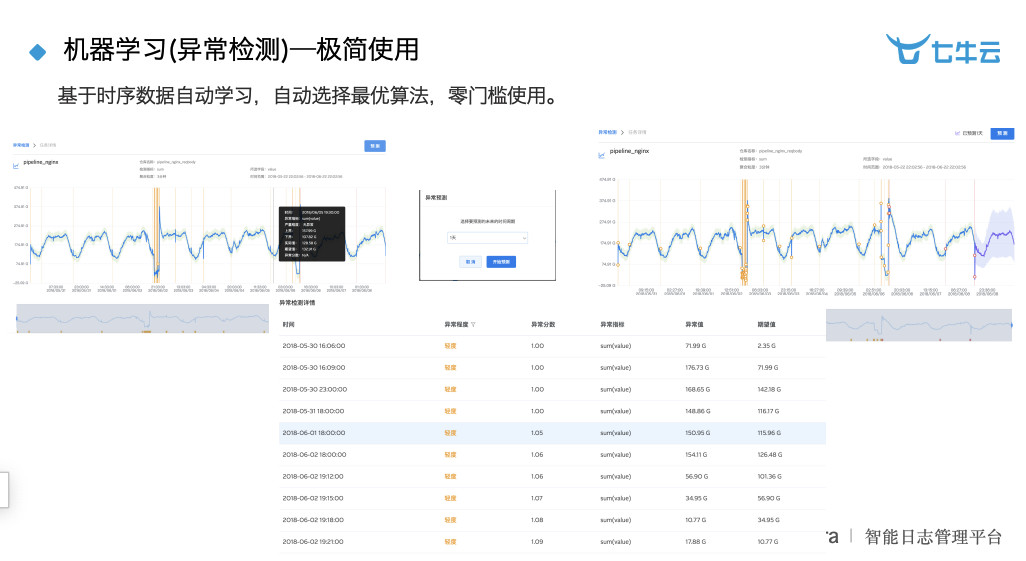
其实这个事情真正的引发了我们跟工厂合作的一个契机,今天展示出来的是一个老版本,我们有一个新版本还没有发布,是一个完全更自动化的一个 AI 产品。将日志往里面打,打完以后机器会自动判断是否有异常情况,不需要定义异常,机器算法就会帮你发现异常。
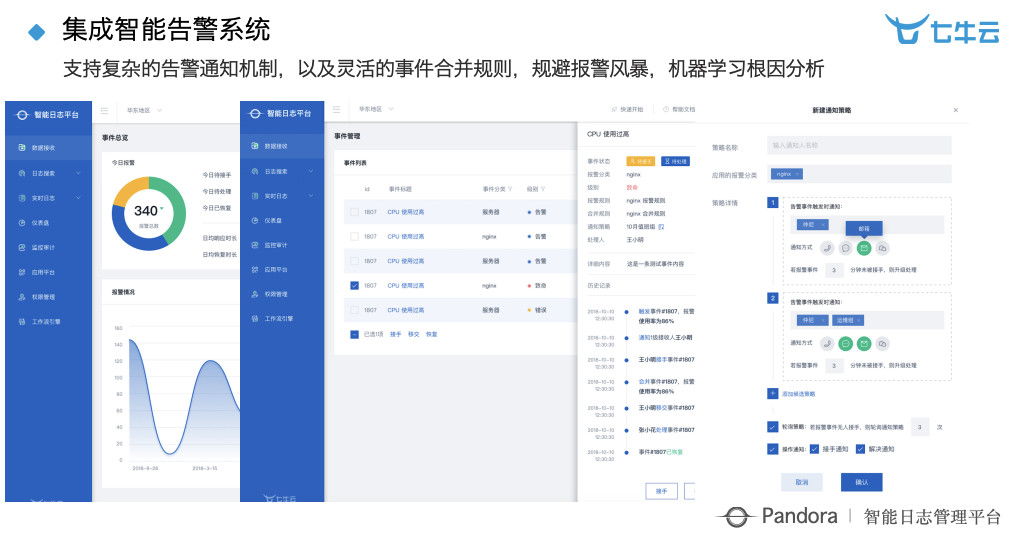
这是集成智能告警系统,可以看到整个系统完整性还是比较好的。

这是平台目前的一些数据,300 多个企业,每天 400T 数据,总数据量 60 个 P,吞吐量 1000 万条/秒。
智慧工厂实践案例
智慧工厂的实践,我们目前跟几个单位有深度合作,而目跟我们合作最紧密的是晶盛机电(www.jsjd.cc/ )。
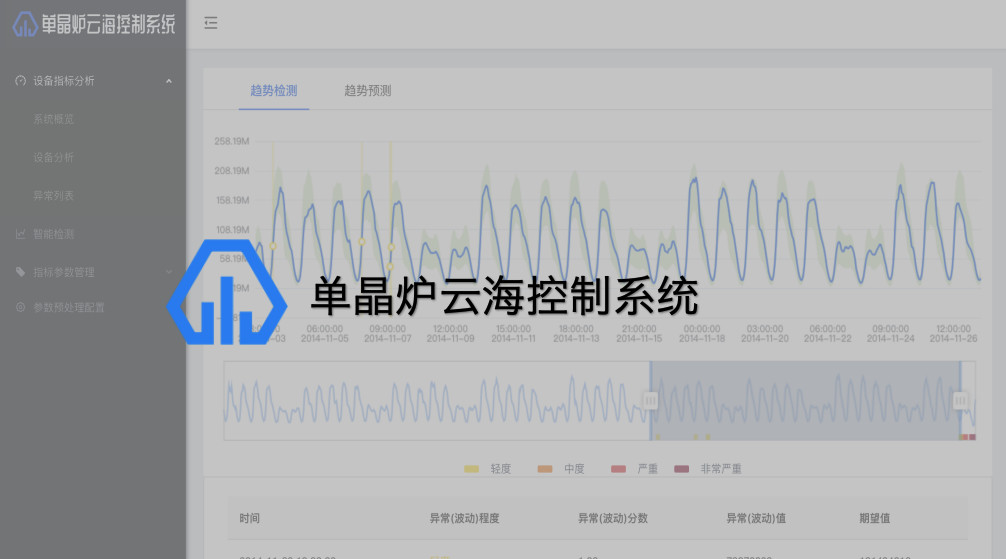
晶盛机电目前是光伏产业链装备最齐全、技术最强的装备龙头企业,相继开发出具有完全自主知识产权的全自动单晶炉、多晶铸锭炉、区熔硅单晶炉、蓝宝石炉,成功开发并销售多种光伏智能化装备。而我们目前的合作,主要是针对单晶炉。
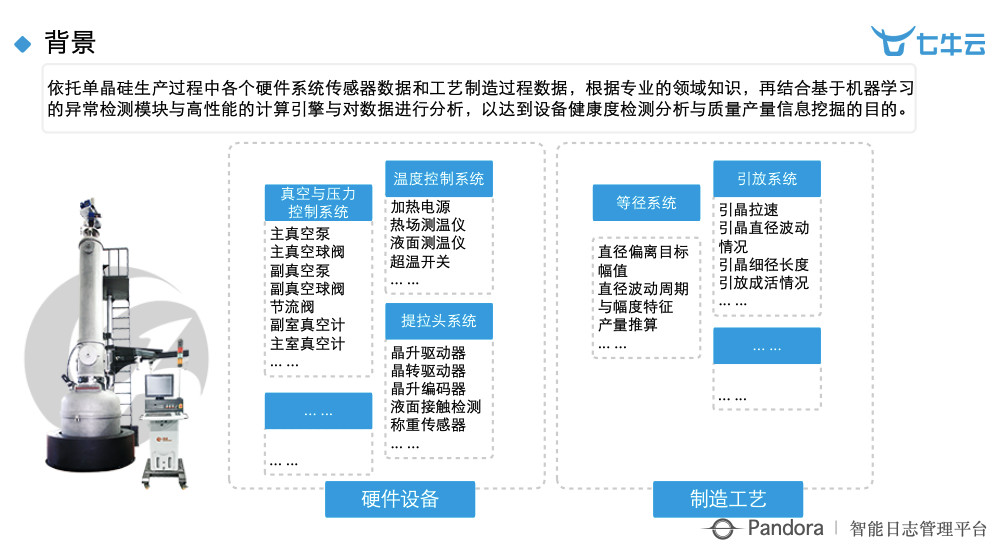
上图可以看到,在单晶硅的生产过程当中,左边是他们的炉子,有很多传感器装在这个上面,之前是每 5 分钟或者 15 分钟甚至一小时才会采集一个点出来,因为数据实在太多,很难高效紧凑的存下来并做进一步分析, 但是这些数据里面的信息又非常重要。所以我们需要有个更加强大的方式,来做采集、传输、存储、分析及挖掘。
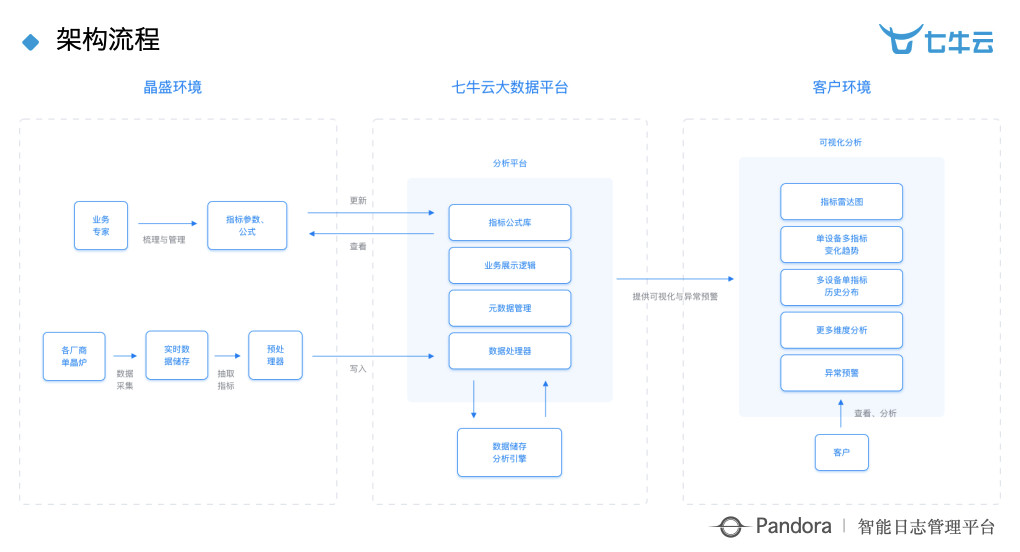
我们做的事情就在这张图上可以整体显示出来,从端到端一直跟他们一起合作。在晶盛环境里,他们做了各厂商数据采集和指标的抽取,抽取之后我们的业务专家会帮他们来初步的提取指标参数跟公式,因为一开始不知道什么好坏,很难客观评价。像我们这样的互联网公司要做智慧工厂,不了解他们的业务,只靠所谓的 AI 算法,是根本不可能的。所以,我认为「有多少人工就有多少智能」这句话有时候是对的,人工智能这个东西应该是一半一半来看,在前期真的是有多少人工就有多少智能,来跟业务专家一起来观察。
到一定阶段之后,会由量变产生质变。进入七牛云平台,把指标公式库、业务逻辑、元数据、数据处理等全部放进去,基于数据存储引擎去帮他做一个完整的分析,目前我们主要用到了若干个个传统的机器学习方法和两个深度学习的方法。但是在又遇到一个挑战,包括前面讲的异常检测一样,在这个公司里面做深度学习是不能用 GPU 的,他现场没有 GPU,所以只能做 CPU,我们对 CPU 算法做了很多优化。
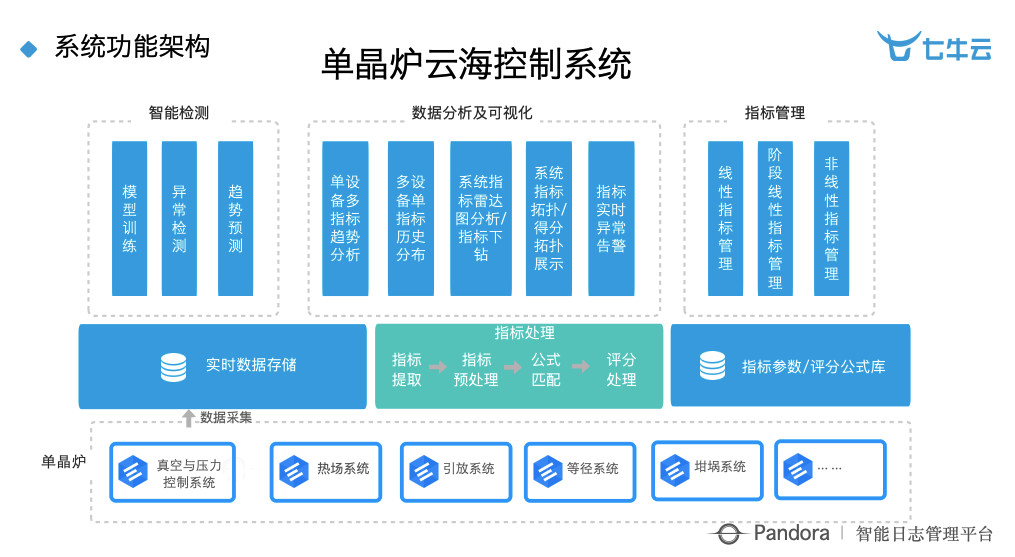
这是我们做的东西,我觉得这个事情有一定的普试性。智能检测部分,我们做模型训练、异常检测、趋势分析,数据分析那边做了这个单晶炉的体检系统,体检系统指得是我这个炉子出问题需要要检修了,就不往里面倒原料来进行单晶提取了。如果原料进入出问题的炉子就要废掉,光这些原料的钱就要好几十万。目前的阶段,我们花的最大的力气是在智能检测这一端,之前是在数据分析和可视化。
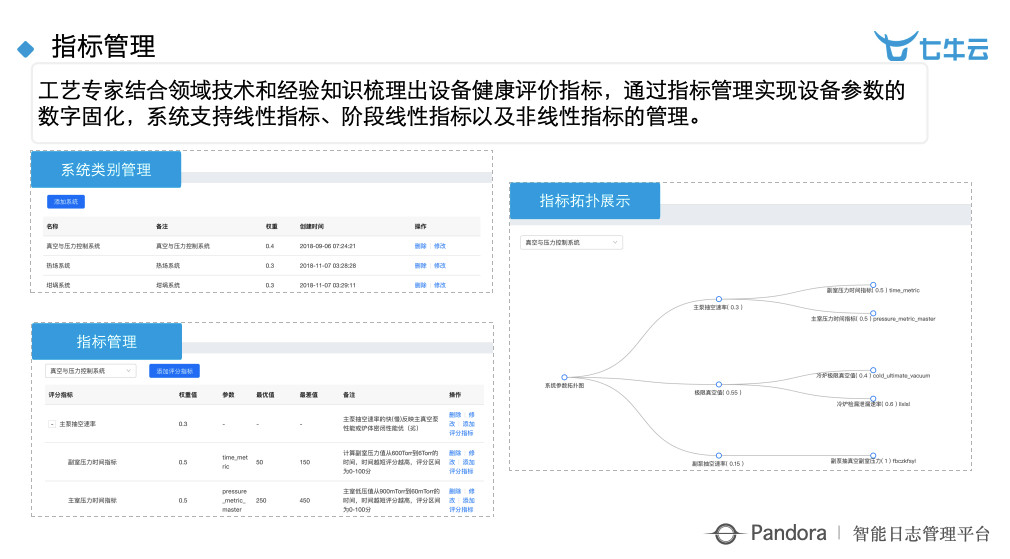
这个是我们给他们看的一个界面,可以看到要跟工艺专家一起来搞出一些评价指标等,再把这个评价指标通过机器学习的方式来进行分解。如果有一个东西不好了,要判断它是什么原因引起的,然后再判断这个原因又是因为什么原因引起的,层层往下。这个过程像极了传统运维根因分析的需求,我们要找到造成这个问题的根本原因,用这个理念来帮他做这个事。
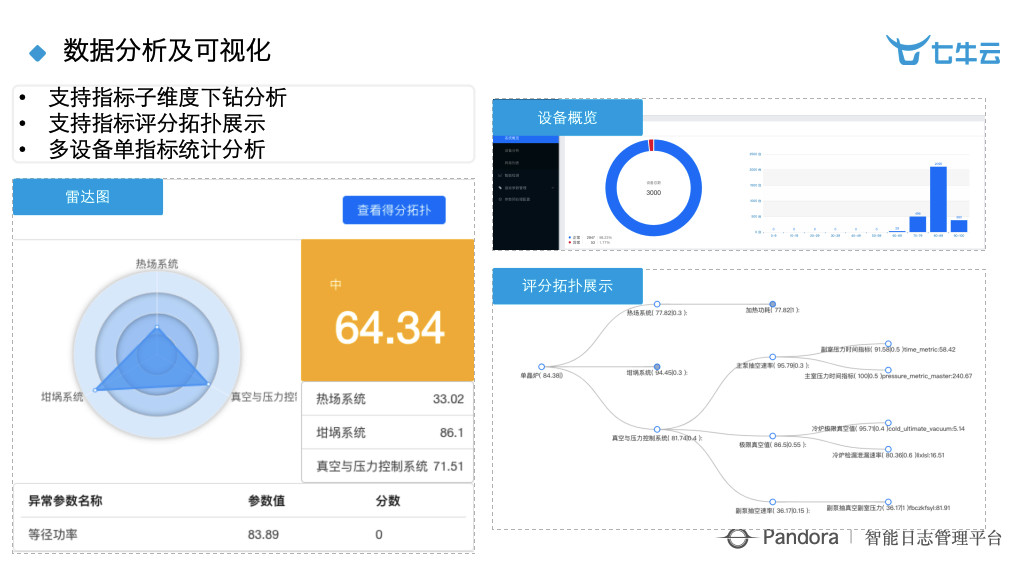
可视化就是,一开机就可以体检炉子是几分,如果是 60 分以下这个炉子今天就不要生产了。

智能检测就是利用里面的一些数据进行检测,但现在我们觉得,最有价值的地方不是在于明显的异常点,而是在于一些不是那么突出的异常点,但是它的趋势又特别突出,比如突升突降,这种以前是发现不了的。以前的做法就像运维一样,都是低于这个数或者高于这个数就是异常,但是有些时候,趋势也可以成为一种异常。
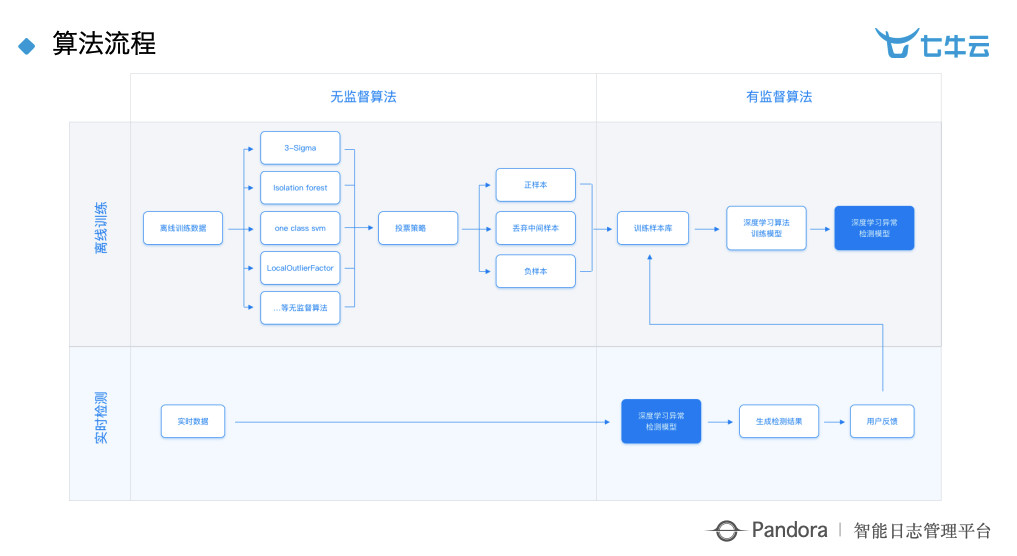
我们把离线训练跟实时训练分开来做,离线训练我们做了一些离线数据集。之前单晶炉的历史数据进行一系列的无监督算法,来进行一个打标的过程。打标之后会有一个投票策略,保留正样本和负样本,丢弃中间样本。
然后从无监督算法出来以后,带有一个 label 的一套数据集,这样真正进入我们给他使用的数据集里面,就是深度学习算法。当数据进来以后会跟下面的实时数据直接做融合,相当于最终给用户看的数据全部是由深度学习的算法来做的。传统的机器学习在这边主要是用来做打标的过程。我们其实做了一些尝试,就是在不改变逻辑的情况下,移植到另外一个工厂的设备当中发现它完全可用,但是只发现有结果,没有办法从业务上以及从他们真正的场景上解释,因为不懂业务,所以做这些事情需要真正懂业务的人 + 技术专家一起做。
目前我们双方仍然还在一起努力完善这套系统,我相信在不久的将来,这套系统一定会大放异彩。
以上是我的分享内容,谢谢大家!
