

一、编译和代码优化
1、编译器优化-泛型:
1、泛型出现之前存在的问题:
所有对象的类型都继承自Object,虚拟机只有到运行时才能知道这个Object具体是什么类型,在编译期是无法检查这个Object是否强制转型成功,会将ClassCaseException的风险转移到程序运行期。
2、泛型的作用:
通过泛型,编译器可以在编译阶段发现类型不一致的问题
3、泛型擦除:
将Java代码编译成Class文件,通过反编译发现泛型都不见了,被替换为原生类型,并插入强制转型的代码。
//泛型擦除前
List<String> list = new ArrayList<>();
list.add("hello");
System.out.println(list.get(0));
//泛型擦除后
List list1 = new ArrayList();
list1.add("hello");
System.out.println((String) list1.get(0));
2、运行期优化-代码优化
1、公共子表达式消除 在程序基本块中,如果一个表达式E已经被计算过了,下次再次使用的时候,如果表达式的变量值都没发生改变,就可以直接拿表达式的结果来代替E。
int x = 1;
int y = 2;
int z = x + y;
int w1 = x + y +2;
//编译器对公共子表达式(x+y)进行消除
int w2 = z + 2;
二、方法调用
1、解析
类加载解析节点,将一部分符号引用转化为直接引用。前提是程序运行前有可确定的调用版本,并且在运行期不可变。这些编译期可知、运行期不可变的方法调用就是解析。
2、静态分派和动态分派
1、静态分派:
根据静态类型来定位方法的分派叫做静态分派,发生在编译阶段。
//父类
public class Parent {
}
//子类
public class Son extends Parent {
}
//调用
public class MyTest {
public void say(Parent parent) {
System.out.println("parent say");
}
public void say(Son son) {
System.out.println("son say");
}
public static void main(String[] args) {
MyTest myTest = new MyTest();
//实际类型为Parent
Parent parent = new Parent();
//实际类型为Son
Parent son = new Son();
myTest.say(parent);
myTest.say(son);
}
}
返回结果:

2、动态分派
public class Parent {
public void say() {
System.out.println("parent....");
}
}
public class Son extends Parent {
public void say() {
System.out.println("son....");
}
}
//调用
Parent parent = new Parent();
Parent son = new Son();
parent.say();
son.say();
结果:

基本步骤:
- 找到栈顶第一个元素所指向的对象实际类型
- 如果找到对应方法,进行访问权限验证,通过则直接引用,不通过则抛出异常。
- 否则,按照继承关系从下向上对其各个父类进行方法的搜索和验证过程。
- 如果没方法,则抛AbstractMethodError异常。
三、并发
1、处理器、缓存、内存的关系
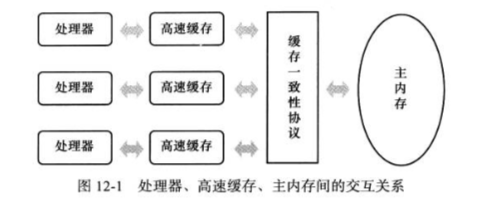
2、主内存、工作内存的关系
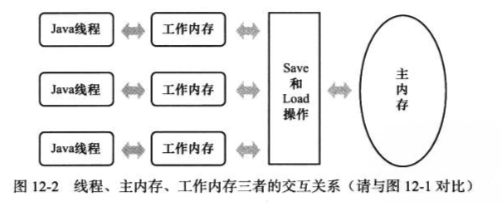
- 线程的工作内存中保存了被该线程使用的变量的主内存的拷贝副本
- 线程对变量的读取、赋值等操作是在工作内存中进行
- 不同线程之间无法直接访问对方工作内存的变量,线程间变量值传递通过主内存来完成
3、内存间的交互操作
将变量从主内存拷贝到工作内存中,将工作内存同步到主内存中。定义了8中操作,每步操作都是原子的、不可再分。
- lock(锁定):作用于主内存变量,将一个变量标识为一条线程独占的状态
- unlock(解锁):作用于主内存的变量,把一个处于锁定状态的变量释放出来,才可被其他线程锁定。
- read(读取):作用于主内存变量,把一个变量的值从主内存传输到线程的工作内存中。
- load(载入):作用于工作内存的变量,把read操作从主内存得到的变量放到工作内存的变量副本中。
- use(使用):作用于工作内存变量,当遇到需要使用变量的值得字节码指令时,会将工作内存的变量传给执行引擎。
- assign(赋值):作用于工作内存的变量,当遇到给变量赋值的字节码指令时,会把一个从执行引擎接收到的值赋给工作内存的变量。
- store(存储):作用于工作内存的变量,把工作内存的变量值传递给主内存中。
- write(写入):作用于主内存的变量,把从工作内存中得到的变量值放入主内存的变量中。
注 :
- read与load之间、store和write之前可以插入其他指令,会导致多线程操作的同步问题。
- 一个变量在同时刻只允许一个线程对其进行lock操作。
4、volatile关键字解析
1、可见性:
- 可见性:一条线程修改变量的值,新值对于其他线程是立刻得知的。
- synchronized和final也能实现可见性。
- 普通变量:如果线程A修改了普通变量的值,需要向主内存进行回写。另一条线程B在A回写完成后再从主内存进行读取操作,新变量值才能对线程B可见。
- 注意:不是所有对volatile变量的写操作都会立即反应到其他线程中。
private volatile static int x;
public static void main(String[] args) {
for (int i = 0; i < 20; i++) {
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
for (int i1 = 0; i1 < 1000; i1++) {
x++;
}
}
});
thread.start();
}
System.out.println("x="+x);
}
最终的结果不是20000,说明volatile修饰的变量也没实现正确并发的目的。
原因:
x++ 是由多条字节码指令构成的,包括取值,+1,赋值操作,volatile只能保证最后变量取到操作栈顶时该变量的同步性,但是在这之前其他线程是可以修改该变量的值。
2、volatile适用的场景:
- 运算结果不依赖变量的当前值(例如 x = x+1 不可用)
- 变量不需要与其他状态变量共同参与不变约束 (x = 1+y 不可用)
3、禁止指令重排序优化 普通变量只能保证执行过程所有依赖赋值结果的地方都能得到正确的结果,不能保证变量赋值的顺序与代码中执行顺序一致,
实现方式:在多线程访问同一内存时,相当于通过一个内存屏障,保证不能把后面的指令重排序到内存屏障之前的位置。
5、synchronized基本原理:
synchronized关键字经过编译后,会在同步块前后行程monitorenter和monitorexit两个字节码指令。在执行monitorenter指令时,如果对象没被锁定,或者当前线程拥有这个对象锁,把锁的计算器加1,执行monitorexit时,锁的计数器减1,当计数器为0时,锁会被释放。如果获取对象锁失败,当前线程会阻塞等待,直到对象锁被释放。
