

一、概念定义
1.什么是类目
类目简单来说就是商品的分类,用大家最常用的淘宝来看,就是图中圈出来的地方。

为什么会有类目,也是其功能决定的,类目目前已经作为电商网站导航的标配,只是不同网站的类目不同罢了。
如果我们的网站只有几十个、上百个商品,或许类目对于我们来说不重要,但是如果商品有成千上万个,甚至更多,那类目对我们来找到具有某些特点的商品就至关重要了。比如现在要找女式牛仔裤,可以通过类目 女装->牛仔裤 就能找到了;否则那就一页一页去搜索,就算我们平台商品质量再好,性价比再高,相信用户也会忍耐不住抓狂了。。
2.前后台类目
类目分为前台和后台类目。
前台类目的存在主要是面向用户,搜索导航栏,这个是易变的,季节、营销活动都会影响类目导航;
后台类目是直接和商品关联的,商品创建的时候选择好类目,那么对应的类目几乎就不会变化了,它是很稳定的。
好处:
比如现在我们平台新推出一种活动,类目就是12.12,如果没有前后台类目分离,那我们需要找到需要做活动的商品把他们类目改为12.12,但明显这个方式不妥;那重新维护一套和这些商品的关联关系,这样搞个新模块那还不如直接用类目来承载呢,这样我们把前后台类目做个映射关系就OK了。
关联关系可以根据需求任意组合。
举例:现在有批商品,分别有后台类目A、B、C,我们要对A、B类目的商品做活动导航,则做个映射关系,12.12->(A、B),将前台类目12.12和后台A、B做关联,这样就可以通过导航12.12找到所有A、B类目下的商品了。
此外,前台类目易变而且不和商品直接关联还有个好处,它可以扩展成很多种方式。比如新增活动频道,通过URL的方式直接跳转;通过关键词的方式定义,比如类目T恤就是通过关键词T恤进行商品搜索的功能。
一般来说,不管是前台类目还是后台类目都会分为几级,所以最终都会形成一棵类目树。
3.属性和属性值
每个类目都有属性,属性作为该类目下商品都共有的特征,比如颜色、大小等等。
属性值则是该属性具体的值,比如颜色可以有红色、白色、黑色。
正常来说,前台类目有关联后台类目,则前台类目的属性都是从后台类目的属性集合中选择的。
比如12.12->(A、B)这个关系中,对应属性A(a1,a2),B(b1,b2),则12.12的属性应该属于(a1,a2,b1,b2)集合。
属性也可分为几类,我们使用到的大致为:导航属性、销售属性、普通属性。
导航属性:作为根据类目进入筛选页的属性选项。

销售属性:商品详情页可供选择的sku规格属性,不同属性价格可能会不同。
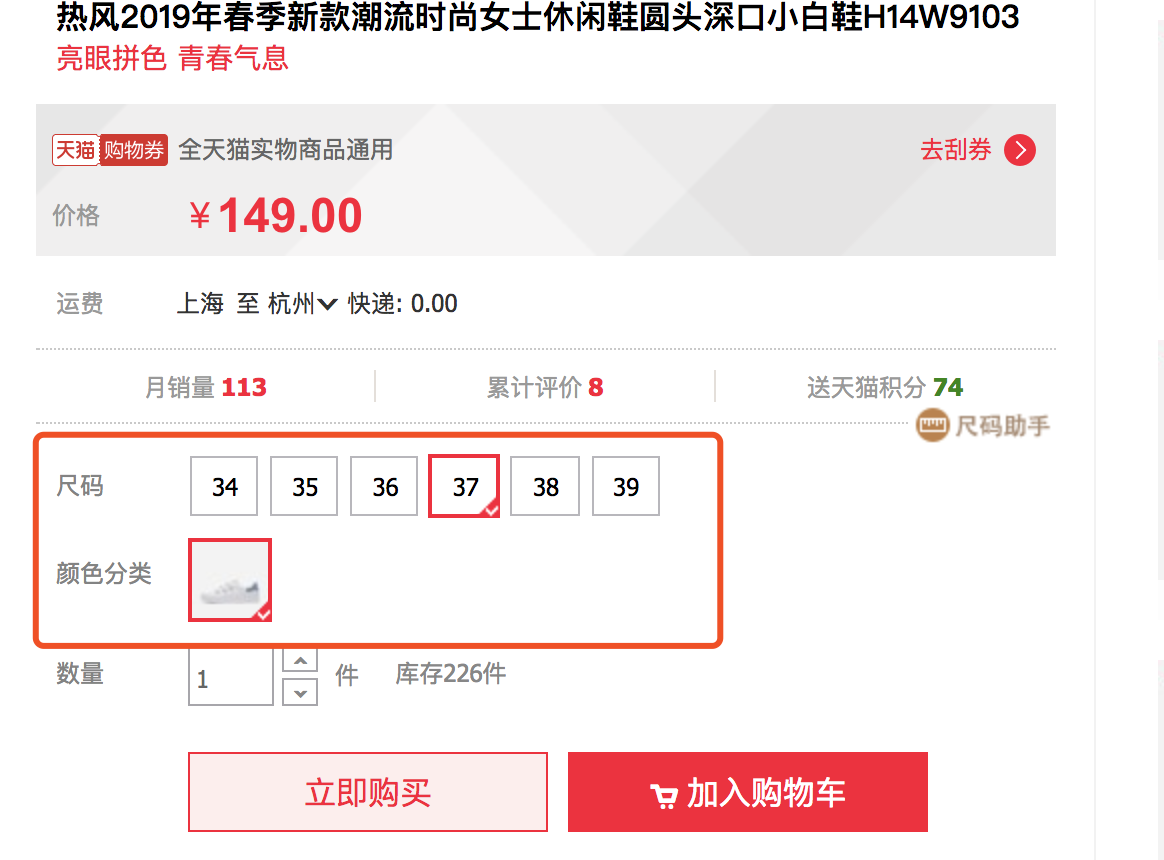
普通属性:商品的其他属性。
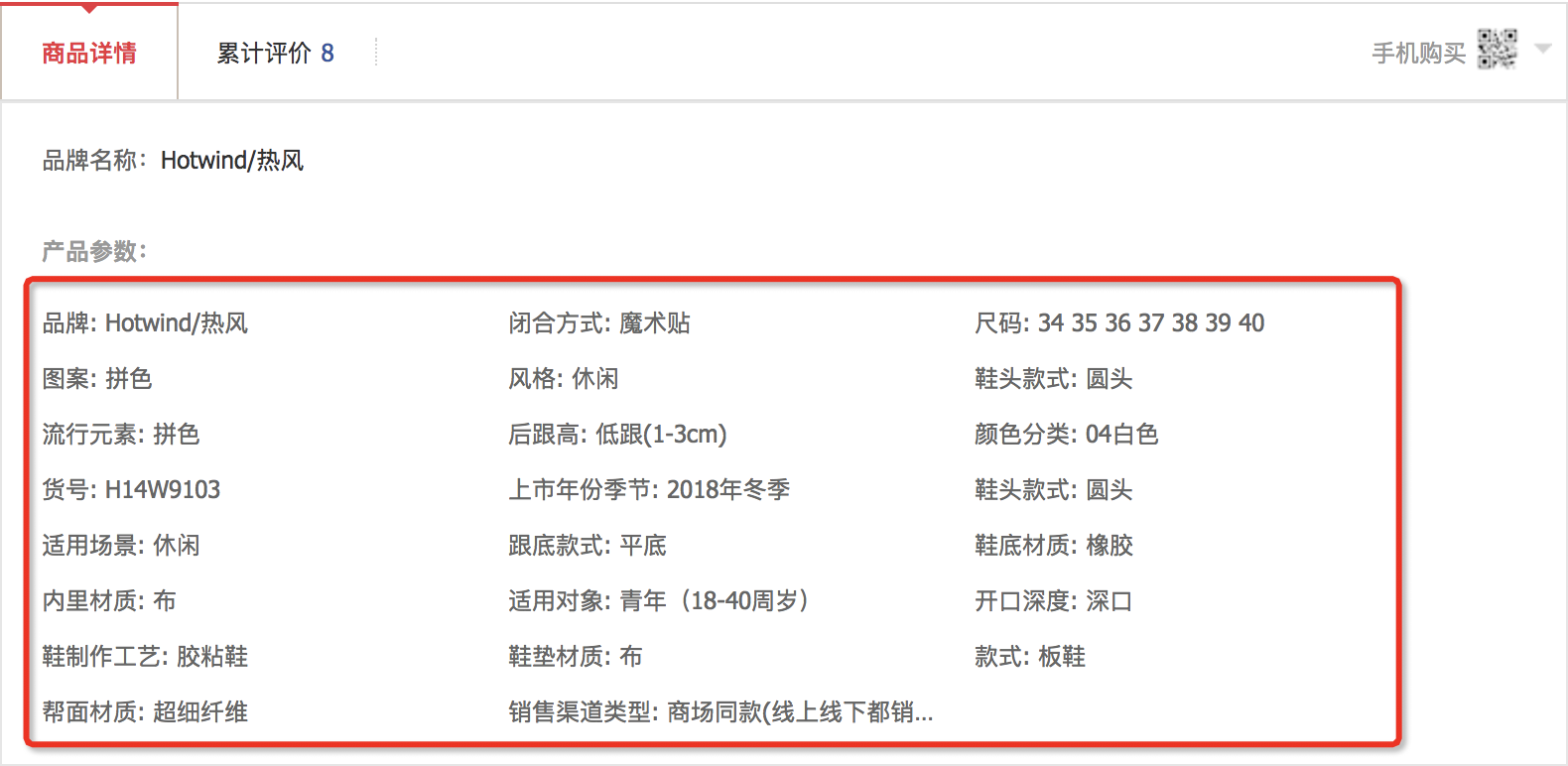
创建商品的时候需要选择类目,然后根据该类目的属性来填充商品的属性值,保存在商品上就类似于key-value的格式。这样就可以根据属性值来筛选商品。
4.子属性和子属性值
这个关系一般用不上,设计不了这么细致,不过可以预留着。
子属性是挂在某个属性值下面的。子属性值就是该子属性的取值。例如手机类目下,有个属性为品牌,存在一个属性值为iPhone的品牌,则再往下划分可划分出iPhone的子属性型号,对应的子属性值可以为iPhone8、iPhone X等。
所以这里就存在一个关系:类目(手机)->属性(品牌)->属性值(iPhone)->子属性(型号)->iPhone8(子属性值)
子属性也用属性模型来承载,只是设计的时候要建立好属性值和子属性的关联关系。
二、技术设计
1.关系图
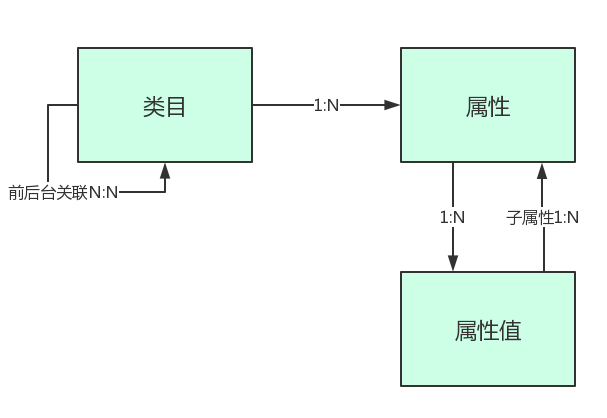
其中包含的对应关系有:
前台类目:后台类目(多对多);
类目:属性(1对多);
属性:属性值(1对多);
属性值:子属性(1对多);
2.类目属性树形结构图
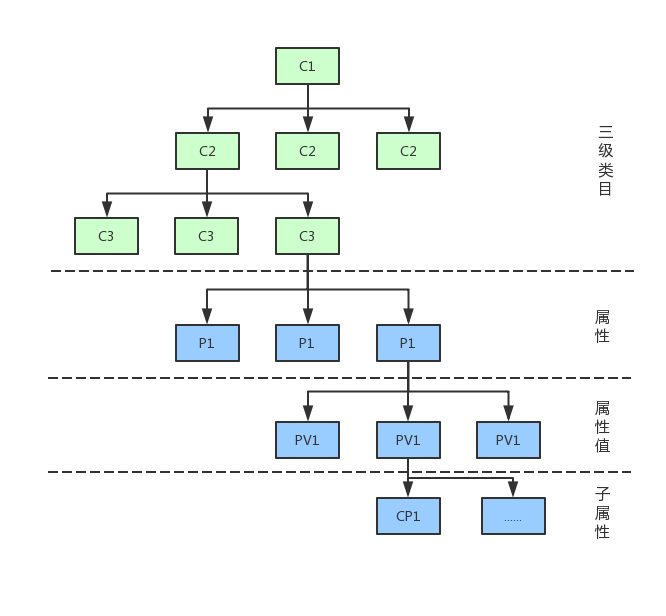
类目和属性的层级深度根据业务而定,因为是树形结构,所以本身可扩展。
属性挂在后台叶子类目下。
3.类目表
`cate_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`gmt_create` datetime NOT NULL COMMENT '创建时间',
`gmt_modified` datetime NOT NULL COMMENT '修改时间',
`pid` bigint(20) DEFAULT NULL COMMENT '父id',
`leaf` tinyint(4) NOT NULL COMMENT '是否叶子节点 1:是0:不是',
`level` tinyint(4) NOT NULL COMMENT '层级',
`title` varchar(64) NOT NULL COMMENT 'title',
`cate_type` tinyint(4) NOT NULL COMMENT '前台后台类目 1:前台 2:后台',
`back_categories` varchar(255) DEFAULT NULL COMMENT '后台类目id集合 适用于前台 英文逗号分隔',
`root_cate_id` bigint(20) DEFAULT NULL COMMENT '根类目id',
`order_seq` int(11) NOT NULL COMMENT '排序序列',
`picture_url` varchar(255) DEFAULT NULL COMMENT '图片url',
`need_audit` tinyint(4) NOT NULL COMMENT '是否需要审核 1:是0:不是',
`is_delete` tinyint(4) NOT NULL COMMENT '状态0:正常 1:删除',
`biz_type` varchar(64) NOT NULL COMMENT '平台类型',
`language` varchar(64) DEFAULT 'zh' COMMENT '语言',
`country` varchar(64) DEFAULT 'CN' COMMENT '国家',
`extension` mediumtext COMMENT '扩展字段',
`version` int(11) NOT NULL DEFAULT '0' COMMENT ‘版本',其中pid存储上级类目ID
level表示该类目处于第几级
4.缓存
由于类目作为电商系统的基础数据,很多模块都会依赖它,随着电商系统规模的扩大,类目查询请求、并发量会不断增加,所以一开始我们就采用缓存的方式。
采用类目做缓存的几点考量:
- 类目作为基础数据,查询请求巨大;
- 类目数据相比其他基础数据来说内存占用不高;
- 类目是共享数据;
- 类目变更实时性要求不高,没有严格的数据一致性要求;
缓存的两种方式:分布式缓存和分布式本地缓存
4.1分布式缓存:
使用Redis来存储类目数据结构。
优点:所有client共享一份数据,没有数据不一致的问题
缺点:当系统规模很大,qps将不断增加,缓存中心压力变大。
整体流程如下图:
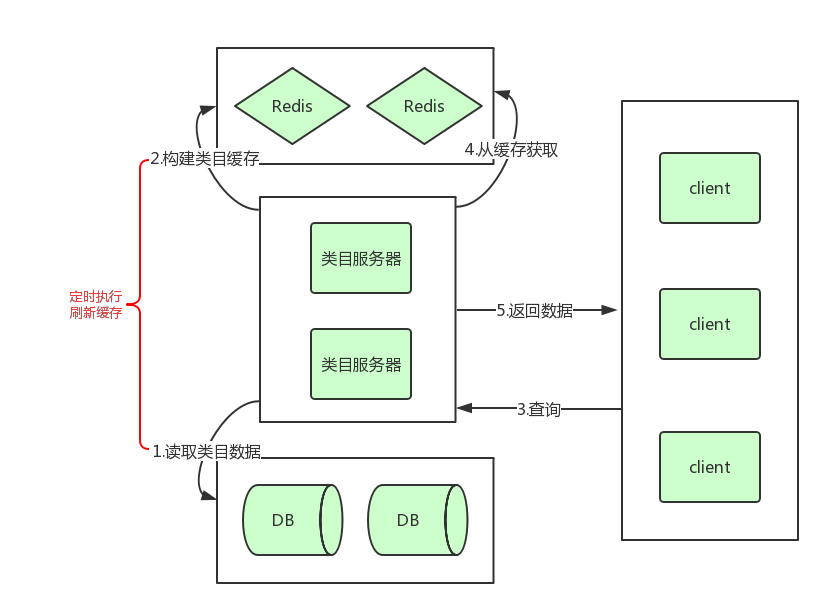
- 从DB查询类目数据
- 构建需要保存的数据结构,并推到缓存
- 接收client查询请求
- 从构建好的缓存中查询
- 返回数据
刷新策略:定时更新,1.2两步通过定时任务执行、执行频率可根据具体业务可接受程度而定。
该方法的好处是无需在类目更改的所有方法路径加入缓存失效、推送的逻辑。所有逻辑都统一在定时任务里面处理。
4.2分布式本地缓存:
优点:所有client本地内存有一份副本,直接从内存读取,速度快。
缺点:所有client需要与server数据同步,关键问题是数据不一致很难保证;
需要封装单独的client jar包以供使用,当jar包升级时需要同步所有依赖方升级,维护成本大;
整体流程图如下:
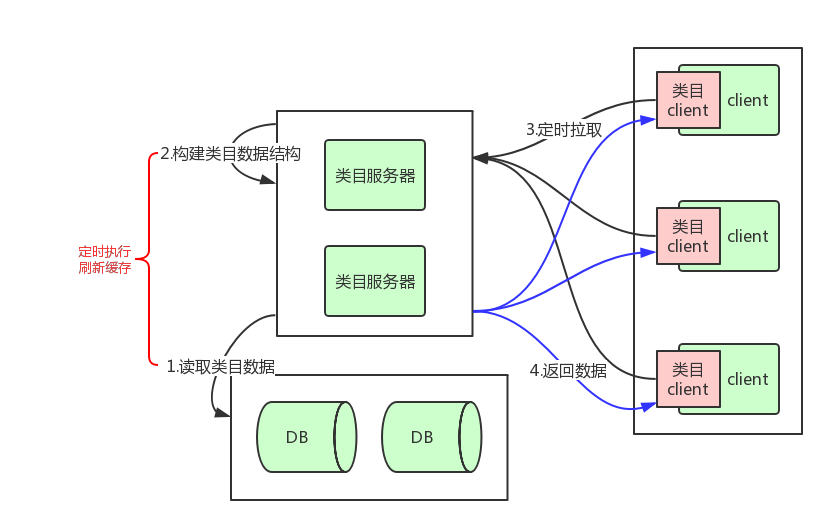
- 1.从DB读取类目数据
- 2.构建需要缓存的类目数据结构。
- 3.通过开发的类目client jar包向服务器拉取数据。
- 4.返回构建好的数据结构。
这里有几点需要注意:
1.可以通过很多种方式来达到client的数据刷新:
- 将构建好的数据包存放在DB,client统一从DB刷新;
- 服务器通过发消息广播的方式,client监听刷新本地缓存;
- 通过jar包实现封装定时拉取的方式,定时刷新本地缓存。
由于我们系统中对类目的更新实时性要求不高、没有严格一致性要求。所以设计时可采用定时刷新的方式。jar包的方式对于依赖方是最易用的方式。也正是实时性、一致性要求不高,所以才可使用本地缓存。如果系统因为本地缓存数据不一致而将导致很严重的后果,那还是慎用。
2.类目client是开发后打包给需要使用类目服务的应用引用。该包里面已封装好了关于类目的所有操作,包括定时拉取、解析服务器构建的数据结构、数据校验、本地缓存刷新等功能,对应用提供的就是类目的基本操作,比如根据ID获取类目、获取类目树等等。
3.服务器每次构建类目数据结构应维护版本号,这样client可判断是否是最新数据,重新拉取等等。通过先判断版本号,再拉取是一种不错的选择。这样可减少数据未更新而产生的不必要网络传输。
4.为什么通过类目client主动从服务器拉取的方式,因为如果服务器主动推送,首先得维护client列表,其次还要维护所有client的推送状态。如果把这个放在client维护,那就大大减少了复杂性。
通过比较分布式缓存和本地缓存两种方式,总结出分布式缓存实现简单,数据一致性易保证。本地缓存需要自己实现client包,会出现短暂的不一致,在高并发下优势更加明显,但强一致业务慎用。最终我们使用分布式缓存即能满足要求。
结构设计:
类目面向电商前台页面,用的最多的就是类目树的获取,所以可以这样来设计。
- rootCategoryIds:保存根类目ID列表索引
- subCategoryIds + 类目ID:保存该类目下级类目ID列表索引
- category + 类目ID:保存该类目具体数据data
通过根类目ID列表和子类目ID列表就能够索引到类目树中所有的类目ID,通过ID就能拿到所有数据。
该结构其实可适用于分布式缓存和本地缓存的数据结构。通过构建该数据结构就能快速拿到类目树中的任一节点。
三、总结
虽然类目结构不复杂,但因为其使用非常频繁,所有在电商系统中需要好好设计类目的存取。介绍了一些分布式缓存和本地缓存,但不详细,详细的缓存知识可参考网上其他资料。上面讲到的本地缓存的实现方式也是借鉴了淘宝的类目体系,如果非要使用本地缓存也可以参考一下。
更多文章欢迎访问 http://www.apexyun.com/
联系邮箱:public@space-explore.com
(未经同意,请勿转载)
