

HashMap的原理及实现
- 个人对
HashMap的总结,有错误请留言. - 本文是纯文字介绍的,如果有朋友喜欢结合代码的话也可以直接点击文末链接。
- 感谢阅读.
概述
HashMap是在JDK1.2中引入的一种K/V对形式的集合类.- 在底层,
HashMap通过数组和单链表组合的结构形式来存储数据,数组在这作为一个外部结构,数组中的每个节点被称做Bucket(桶),而桶是由在单链表构成,JDK1.8之后为了解决长链表下,查询和插入效率低下的情况,又引入了红黑树的作为桶的实现方式, - 桶中的各节点是由
HashMap定义的Node内部类生成的,是普通的链表节点类.
- 注意:
HashMap是线程不安全的,在JDK1.8之前多线程情况下甚至可能会出现环路(后面会讲),所以多线程状态下还是要使用ConcurrentHashMap的.
重点参数
HashMap的参数不多,除去当做默认属性的静态常量和底层数组对象,就只有以下五个
transient Node<K,V>[] table;
transient int size
transient int modCount;
int threshold;
final float loadFactor;
-
table就是整个HashMap的底层数组,table的初始化并不在构造函数中完成,而是在resize()方法中完成.table的初始化可能有点绕,构造函数中最多指定了阈值threshold和负载因子loadFactor并没有容量相关,但是在resize()方法中会根据旧容量和旧阈值判断新容量是等于默认容量,旧阈值或者两倍旧容量,最后根据新容量创建新数组
-
loadFactor就是所谓的负载因子,默认为0.75,是控制扩容时机的关键属性,因为扩容发生在当前元素个数超过阈值时,而阈值等于当前容量乘以负载因子. -
modCount为修改计数,是fast-fail机制的关键参数.在对Map中的元素做新增/删除操作时会自增,但修改不会(putVal()方法中覆盖原值)
新增逻辑
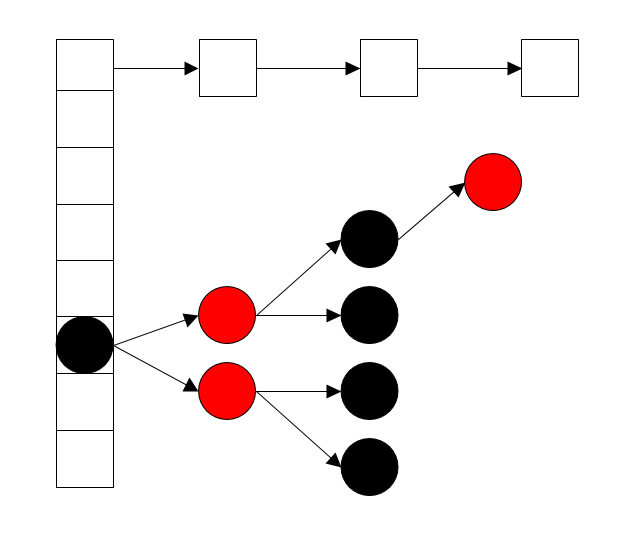
HashMap的新增过程重点主要还是定位,如何确定元素在数组中的位置,HashMap采用的就是Hash算法- 首先
HashMap会根据Key的hash值,按照表达式(n - 1) & hash计算出桶的下标 - 如果此时桶为空,会创建一个新的
Node,作为链表的第一个元素,直接存放在数组中.(以前还听说过什么链表首节点为空的情况,是假的.) - 如果节点存在又会区分树节点(TreeNode)和普通节点(Node)两种情况.
- 普通节点会直接从首节点往下遍历找到尾节点,并将带插入节点添加到末尾
- 树节点会调用,
TreeNode的方法插入到树中.
- 首先
- 另外新增前会判断底层数组
table是否初始化,新增后会判断该桶大小是否超过的8,超过则转化为红黑树,再判断整个数组是否需要扩容. Hash同时也叫散列,可以把任意长度的输入通过算法,换算成固定长度的输出,不同元素通过Hash算法获得的下标一致可以被称之为冲突或者碰撞,Hash算法的要求就是使元素尽量少的发生碰撞,从而均匀的散布在数组中.而发生碰撞时,像HashMap这种以一个列表下挂的方式可以被称为拉链法.
查找逻辑
- 此处的查找逻辑是指调用
get()方法,通过key值查找的情况,如果自己遍历的另说.- 同样是根据表达式
(n - 1) & hash计算出桶的下标(可以说是相当重要了),若得到的桶为空,直接返回null - 不为空时则会遍历整个桶,并根据
key.equals(k)判断是否相等 - 遍历的方法也会根据节点类型的不同而不同,但是区分节点前直接存放在数组中的头结点是要先进行判断的.感觉上性能影响不大吧
- 同样是根据表达式
- 从查找的过程可以看出,确定桶下标的计算不存在随机性,时间复杂度就为O(1),具体的性能体现在遍历这一块,链表查询的时间复杂度为O(n),所以链表越长遍历时间也就越长,插入和查找的效率也就越低.所以在
JDK1.8之后引入的红黑树作为桶的另一种实现方法.当链表长度大于8时,桶的实现会转化为红黑树. HashMap的性能很大一部分取决于Hash算法..
RESIZE逻辑
-
通过插入和查找我们可以知道,在数组大小不变的情况下,链表越长或者说树的高度越高都会导致操作性能降低,所以此时很有必要通过扩容数组的方式,重新排列桶中元素,降低链表长度,减少树的高度.
-
首先,触发扩容的情况是
size > threshold即元素个数大于阈值.整个扩容过程可以简单的拆分为以下几步:- 对数组进行扩充,一般情况下是数组容量和阈值都变为原来的两倍,此间会有上限判断,容量最大为
1 << 30也就是2^30. - 遍历旧数组,重新判断元素的位置并散布到新数组.
- 对数组进行扩充,一般情况下是数组容量和阈值都变为原来的两倍,此间会有上限判断,容量最大为
-
resize()方法中重新散布元素的方法还是很有意思的(除去单元素链表和红黑树(桶的容量在1~7之间)- 首先将新数组分为两部分
lo和hi(源码是loHead和hiHead,我猜是low和high,怎么缩写这么随意),lo表示0到旧容量大小部分,hi表示余下算是新加入的部分,并以此创建两个链表的节点 - 根据表达式
e.hash & oldCap判断元素是否分布在lo部分,是就挂到lo链表下面,否就挂到hi链表下面. lo链表挂到和旧数组相同位置的桶,而hi则挂到下标为原下标 + 旧数组容量的桶.- 此处的依据就是
e.hash & (oldCap - 1) + oldCap == e.hash & (oldCap << 1) -1
- 首先将新数组分为两部分
-
可以看出
resize()方法会调整全部的元素散列情况,因此过于频繁的resize会降低HashMap的性能,因此如果一开始可以大概知道所需要存放的元素个数时,尽量直接指定容量大小. -
JDK1.7之前的resize()方法在并发条件下可能会发生闭环问题,但在JDK1.8之后不会在出现,但并不代表HashMap可以在并发条件下使用了,小部分情况还是会出现数据丢失等问题. -
介绍
JDK1.8之前的闭环问题详情的文章 -
HashMap的懒加载问题
- 查看
HashMap的源码,你会发现底层数组table的创建其实并不是在构造函数中完成的,而是resize()方法中,这就是所谓的懒加载,数组对象并非是在一开始就创建的,而是在第一次插入操作之前完成的。
- 查看
关于HashMap一些问题
扰动函数
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
扰动函数的逻辑很简单就是将hashCode的高16位和低16位异或.
扰动函数的作用就是增加散列的随机性,使元素能够更均匀的分布在数组中,减少冲突从而捎带提高性能.
至于为什么,可以看hash(*)用到的地方,hash(*)被用来计算元素的下标.而下标的计算公式如下
tab[i = (n - 1) & hash] // n表示数组的长度
因为HashMap的容量一定会是2的次幂,所以减1之后转化为二进制会变为一串0加一串1的,例如长度为4时,减去1,就会变为000…00011(前面30个0),再结合&可以发现他只使用了hashCode的末尾几位,高位是全部没用.
而经过扰动函数,将高16位和低16位异或之后相当于高低位都用到了,其散列的随机性也就增加了.
HashMap的容量为什么一定要是2的次幂
- 容量为2次幂有两个优点
- 在下标运算的时候使用
(length - 1) & hash)代替hash % length,相对来说位运算性能更佳,速度更快。 - 而在采用
(length - 1) & hash的方式计算下标之后,如果不是二次幂的容量,出现碰撞的几率将会大大增加,例如我们取17作为容量((17 -1) => 0001000),经过&与运算,可以想象会有一大批的元素直接挂在0号桶。
- 在下标运算的时候使用
- 可以说这是一整套的策略,如果使用
hash & length的话,也不用要求容量一定是二次幂,但各方面的性能总是会差一点的。
HashMap和HashTable的区别
HashTable都没用过了,但以前还稍微看过
- 最大的区别就是
HashTable是线程安全的,暴力的加方法级synchronized.而HashMap是线程不安全的,并发情况下可能会出现数据丢失等情况. HashTable不允许null值,而HashMap允许null值.(包括key和value)HashCode的使用不同,HashTable是直接调用hashCode,而HashMap会经过扰动函数.而且HashMap中用&代替了%HashTable数组默认是11,且增长为2n+1,而HashMap默认为16,增长为2n,且硬性要求长度为2的次幂.HashTable并不是和HashMap一样继承自AbstractMap的,它继承自一个独立的父类AbstractDictionary- 还有就是遍历方法的不同.了解不深先不说话.
- 最后附上完整的源码阅读,蛮久之前写的,不过被朋友吐槽说大段的代码混着注释实在看不下去,所以写了这篇总结性的
