

写在前面
日本电视动画《BORUTO -火影新世代》(中国大陆译名《博人传:火影忍者新时代》)改编自岸本齐史原作并监修、池本干雄编绘、小太刀右京编剧的同名漫画,是《火影忍者》系列的续篇,讲述原作故事完结后漩涡鸣人之子漩涡博人的冒险故事。动画的后续剧情将对岸本齐史负责脚本的剧场版《火影忍者剧场版:博人传》作出补充 。
动画与前作《火影忍者》《火影忍者疾风传》一样由Studio Pierrot(小丑社)负责制作。
时间是:2017年4月5日起每周三16:55在东京电视台系列首播

以上内容,是我从百度百科抄袭过来的~哈哈哈哈,咱主要做的是数据分析,数据的爬取,去我的爬虫系列的博客里面去看吧,里面有相关的教程。
数据分析
作为评论的数据,咱保存了这些数据留着备用
author # 作者
content # 评论内容
ctime = # 评论时间
disliked # 不喜欢人数
liked # 喜欢
likes # 奇怪???
score # 打分
user_season # 在第几集打的分数
1.清洗数据
最核心的步骤来了,在分析数据以前,我们需要对数据做一些处理,空值判断,时间格式修改等内容,这部分可能会根据实际的需求发生一些变化。
import numpy as np
import pandas as pd
import datetime
# 数据读取
def read_csv():
file = pd.read_csv("./bore.csv",header=None,names=["author","content","ctime","disliked","liked","likes","score","user_season"])
return file
# 数据清洗
def clear_data():
df = read_csv()
#print(any(df.duplicated())) # 判断数据是否有重复
#print(df.head())
#print(df.isnull().any()) # 判断是否有空列
#print(df[df.isnull().values==True]) # 检测空值
data = df.fillna(0) # 空值填充
# 时间处理
def get_localtime(data):
time = datetime.datetime.fromtimestamp(data['ctime']).strftime("%Y-%m-%d")
return pd.to_datetime(time)
df["ctime"]=df.apply(get_localtime,axis = 1) # apply 的使用
return df
# 数据分析1
def analsis1(data):
print(data["author"].describe())
if __name__ == '__main__':
df = clear_data()
analsis1(df)
2.评论最多的人?
看一下谁是这部动漫评论最多的人,这个代码非常简单,参考下面代码即可。.describe() 函数
def analsis1(data):
print(data["author"].describe())
count 18535 # author总数
unique 18535 # 去除重复之后的总数
top 你的盛世
freq 1
Name: author, dtype: object
很神奇,竟然没有人评论次数超过2 这个结论只能表示,B站允许视频评论一次?!机制的我想去测试一下,啪啪啪,打脸回来了,我竟然没有权限。

3.评论最多的人?
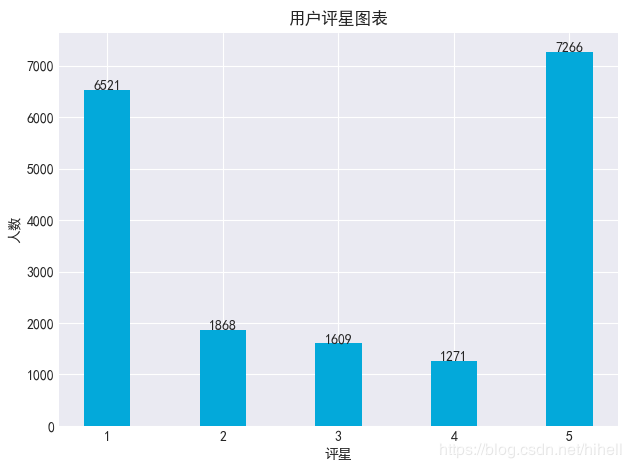
数据中,有分数的排布,那么我们看一下打分的柱状图吧!数据显示的1星和5星的比较多,两级分化比较严重。
为了确保中文显示正常,需要首先配置一下默认字体并且设置一下 matplotlib的样式
import numpy as np
import pandas as pd
import datetime
import matplotlib.pyplot as plt
import matplotlib.style as psl
psl.use('seaborn-darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False
- 分组统计
score打分,使用groupby(by="字段名称").size() # 获取数量 - reset_index(drop=True) # 重置索引
- plt.bar #用来生成柱状图
- plt.text() # 生成文字
def analsis2(data):
# 文章打分的柱状图
score = data["score"].groupby(data["score"]).size()
score = score.reset_index(drop=True)
x_index = np.arange(1,6).tolist()
plt.bar(x_index,score.values,0.4,color="#03a9da")
# 绘制文字
for xx,yy in zip(x_index,score.values):
plt.text(xx,yy+0.2,str(yy),ha="center",fontsize = 10)
plt.title("用户评星图表") # 设置标题
plt.xlabel("评星") # 设置x轴标识
plt.ylabel("人数") # 设置y轴标识
plt.show()
如果编写如下代码
plt.barh(x_index, score.values, 0.4, color="#03a9da")
就会得到一个横向的条形柱状图。
4. 评论时间分布
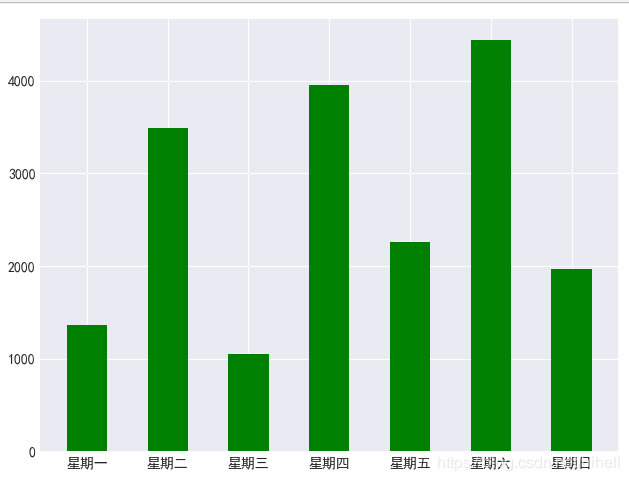
从数据看星期二、四、六评论次数增多,很有意思的数据。
# 通过星期判断评论次数
def analysis3(data):
data.set_index(data["ctime"],inplace=True)
weeks = ["星期日","星期一","星期二","星期三","星期四","星期五","星期六"]
def get_weekday(data):
return weeks[data["ctime"].weekday()]
data["week"] = data.apply(get_weekday,axis=1)
week_data = data.groupby(by="week")["author"].size()
plt.bar(weeks,week_data.values,0.5,color="green")
plt.show()
5. 评论月份暴漏的部分关系
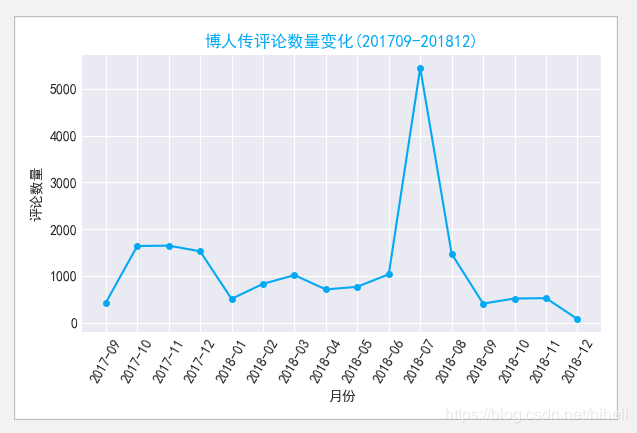
我们看到在2018年7月份数据忽然升高,这背后到底有啥隐藏的秘密呢?我们继续往下看。!
def analysis4(data):
data.set_index(data["ctime"], inplace=True)
data = data.resample("M").count()["author"] # 按照月份汇总数据
data = data.to_period("M") # 显示数据
x = np.arange(0,len(data),1)
fig = plt.figure(figsize=(6, 4))
ax = fig.add_subplot(111)
'''
fig = plt.figure()
ax2 = fig.add_subplot(212)
'''
ax.plot(x,data.values,"#03a9f4",marker="o",markersize=4)
ax.set_xticks(x) # 设置x轴标签为自然数序列
ax.set_xticklabels(data.index) # 更改x轴标签值为年份
plt.xticks(rotation=60) # 旋转90度,不至太拥挤
plt.title('博人传评论数量变化(201709-201812)', color="#03a9f4", fontsize=12)
plt.xlabel("月份")
plt.ylabel('评论数量')
plt.tight_layout() # 自动控制空白边缘
plt.show()
过滤2018年7月份的数据出来,发现在2018年7月20日的时候,出现了一个评论峰值,在进行细致的分析,咱看一下数据。
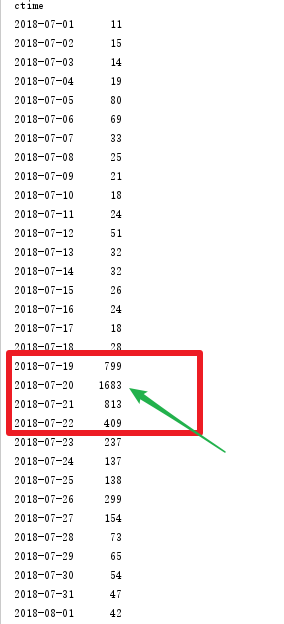
看到这个数据之后,虽然我没看博人传,但是,我知道了 65集肯定好看,而且很有可能在7月20日更新的就是这1集,好奇心起来的你,或者你是一个火影迷,你可以去看看这一集~! 我翻到评论,引用了一个置顶评论
本集是值得国人观众特别期待的一集,因为这一话(第65集)是由国人原画师黄成希全权负责的,
他一个人包揽了本集的分镜/演出/作画导演等主要工作。
换而言之,黄成希作为中国画师获得了本集的作监资格。这在火影忍者开播16年以来是史无前例的。
十几年前,黄成希在火影忍者刚刚开播时,也和多数人一样仅仅只是屏幕前的看客,
但是这部作品对学生时代的他施加了巨大的影响,最终促使黄成希走上了成为动画画师的道路。
在2012年加入日本动画行业后,他如愿以偿成为了火影忍者的主力原画之一,并参与作画监督的工作。
除此之外他还先后加入过包括黑子的篮球、妖怪手表和刀剑神域剧场版等多部作品的制作,
实力得到了业内的认可,因此才最终获得了独自扛下重要打斗回的资格,如此说来也算是圆梦成功。
由于本集几乎是黄成希的个人秀,再加上这一话中大筒木桃式使用了漫画版而不是剧场版中的新形象,
因此黄成希在作画上自由发挥的空间就变得很大,这就有余地在打斗中融入太极和咏春等中国传统武术了。
所以大伙看到一连串的“中国功夫”也别觉得奇怪哈~
说起来,大筒木一族本身就有一股浓厚的道家派头,他们不仅历史悠久,文明程度远远超越这个世界的人,
而且全族都在种灵根,吃仙桃,修金丹,求长生不老。现在再配合一整套中国武学架子,
简直给人一种徐福手下三千童男童女入蓬莱求仙药的即视感...将来出一个徐福式的修仙族长也是极好的!(大误)
黄成希在博人传中的几段作画(可能有遗漏):
博人vs木叶丸
博人vs花火
博人vs鵺
小樱vs信
巳月vs尸澄真


def analysis5(data):
data = data.set_index('ctime') # 将时间作为索引
data = data["2018-07-01":"2018-08-01"]
child_data = data.resample("D").count()["content"]
print(child_data.to_period("D"))
data = data['2018-07-20':"2018-07-20"]
print(data["content"])
6. 评论最多的集数
其实有上面的分析,我们已经知道了,65集肯定是评论最多的了,但是我们还是要用数据看一下
def analysis6(data):
data = data.groupby(by="user_season").size()
data = data.sort_values(ascending=False)
print(data.head())
没问题,65集必看
| 集数 | 评论数量 |
|---|---|
| 65 | 4338 |
| 40 | 985 |
| 39 | 658 |
| 66 | 502 |
| 68 | 494 |
最后打算在弄一个文字图的,后来想想下次再说,《博人传》数据和源码已经给大家写完整啦~
一星给情怀,一星给65集

