

OpenVPN是和网络结合的非常紧密的一款VPN,事实上,每一个VPN框架都和IP网络结合的很紧密,因此在此首先劝一下那些想搞VPN的朋友们,一定要先彻底精通TCP/IP网络协议栈,特别是IP路由,防火墙原理之后再去啃OpenVPN或者其它的VPN,否则会事倍功半的,仅仅看懂源代码和灵活配置,灵活运用,灵活定制之间的差距和很远,精通VPN远远不是会写C代码会使用哈希表就能应付得了的。
OpenVPN中内置了包过滤机制。这个机制一般由ENABLE_PF这个宏括起来。一般而言,很少有人去用这个功能,更别提去修改定制了,这是因为,对于可以将数据包打入虚拟网卡从而进入系统网络协议栈的VPN框架,很多的过滤功能都可以用操作系统的包过滤来完成,对于Linux而言,首选的就是iptables了。本文简要介绍OpenVPN的内部包过滤机制以及简单的定制。
1. OpenVPN包过滤的设计
作为一个用户态的VPN框架,OpenVPN支持多种配置模式,它要么是一台虚拟的交换机,要么是一台虚拟的路由器。既然OpenVPN可以虚拟出这样的设备来,那么这些设备的功能OpenVPN要能简要模拟。对于路由功能,OpenVPN支持了内部路由,而对于包过滤功能,OpenVPN支持了内部packet filter。
2. 运行起来以及原理
要使用OpenVPN的包过滤,其实还真的不是那么简单,首先你要了解包过滤配置文件的格式。
2.1. 包过滤配置文件格式
OpenVPN的包过滤策略由配置文件或者buffer来指定,本文只介绍配置文件的基于IP子网的过滤方式(不考虑基于证书CN项的过滤)。格式如下:
[SUBNETS DROP|ACCEPT]
+|-IP地址/掩码位
…
[END]
其中[SUBNETS …]指示了段的开始,而[END]指示了其结束。SUBNETS后面跟上默认的策略,ACCEPT或者DROP,以下就是正文,正文的开头必须由+号或者-号标示,后面跟上标准的IP地址/掩码的格式,+号表示可以通过,-号表示不可以通过,就这么简单。具体可以看一下OpenVPN源码目录下的management/management-notes.txt文件中的相关介绍,令我不解的是,为何将统一的包过滤功能置于management这个管理接口相关的目录下。
2.2. 配置tmp目录/定义plugin
以上2.1节说的配置文件需要放置在一个特定的临时目录下,说它临时是因为里面的文件是OpenVPN自己动态创建的,等OpenVPN退出之后,里面的文件会被删除。这么说来上述2.1节中的文件也是OpenVPN动态创建的了?是的,正是这样。OpenVPN动态创建了这个文件,然后你可以编辑这个文件,添加进去一些策略规则,OpenVPN定时监控这个文件是否被修改,若被修改则重新根据文件内容加载包过滤策略规则。至于说这些在OpenVPN中是怎么实现的,看代码就好了,很简单的
因此,你只需要配置--tmp-dir dir即可,其中dir是你的临时目录路径。另外一件需要做的事就是编写一个plugin,有了它就可以在plugin中建立包过滤配置文件和外部程序的关联从而动态为包过滤配置文件添加策略规则了,否则的话,你手工修改这个包过滤配置文件也可以,当然这只能达到实验的目的,现实中使用时都是基于plugin来做的。我们可以看看下面的代码:
void pf_init_context (struct context *c) {
struct gc_arena gc = gc_new ();
if (plugin_defined (c->plugins, OPENVPN_PLUGIN_ENABLE_PF)) {
//创建临时文件
const char *pf_file = create_temp_file (c->options.tmp_dir, "pf", &gc);
if( pf_file ) {
setenv_str (c->c2.es, "pf_file", pf_file);
if (plugin_call (c->plugins, OPENVPN_PLUGIN_ENABLE_PF,
NULL, NULL, c->c2.es) == OPENVPN_PLUGIN_FUNC_SUCCESS) {
//初始化定时器,此后定时监控文件变化
event_timeout_init (&c->c2.pf.reload, 1, now);
c->c2.pf.filename = string_alloc (pf_file, NULL);
c->c2.pf.enabled = true;
}
…
}
因此,我们需要写一个plugin,侦听OPENVPN_PLUGIN_ENABLE_PF事件,然后在其func函数中创建包过滤配置文件和外部程序的关联,本文只是实验,因此什么都没有做,全部手工修改添加策略规则。
2.3. 理解在哪里执行包过滤
一般而言,我们使用server模式,因此肯定是multi.c里面执行了,而且是在multi.c中的 multi_process_incoming_link函数中执行:
if (c->c2.to_tun.len && !pf_addr_test (c, &edest, "tap_dest_addr")) {
msg (D_PF_DROPPED, "PF: client -> addr[%s] packet dropped by TAP packet filter",
mroute_addr_print_ex (&edest, MAPF_SHOW_ARP, &gc));
c->c2.to_tun.len = 0;
}
主要由pf_addr_test来执行基于IP子网的包过滤。其实现在pf.c文件中。注意,哪怕是TAP模式的VPN,在开启包过滤宏的情况下,也要解析出载荷的目标IP地址用于包过滤。
pf_addr_test的实现非常之简单,就是一下的循环:
while (se) {
if ((addr & se->rule.netmask) == se->rule.network) {
// exclude由+号或者-号决定
return !se->rule.exclude;
}
se = se->next;
}
…
//由[…]里面的ACCEPT或者DROP决定
return pfs->sns.default_allow;
一切就是这么简单!
2.4. 具体效果
理解了原理,看效果就简单了,配置了tmp-dir为/var/vpn/tmp,然后以172.16.0.0/16为虚拟子网启动OpenVPN服务器,在/var/vpn/tmp下面有个文件: openvpn_pf_3758e76a5d04078a35c900e32aa25d08.tmp 注意,乱七八糟的名字是故意这么生成的,使用了随机数的原理。我手工编辑了这个文件加入:
[SUBNETS DROP]
+172.16.0.0/16
[END]
之后只有访问这个虚拟子网内的主机才可以,其它的全部丢弃。…
2.5. 定制细粒度的包过滤
OpenVPN原生实现的包过滤只是粗粒度的基于IP子网的过滤,但是我们知道,任何操作系统的哪怕最原始的防火墙都是根据起码第四层的协议数据进行过滤,比如TCP或者UDP的端口,比如禁止ICMP等等,要怎样才能实现这样呢?事实上当我们理解了OpenVPN的包过滤原理之后,实现这个一点难度都没有。关键是在实现之前要先定义好接口,这个也不难,只是在+a.b.c.d/e之后再加上协议和端口信息即可,我的垃圾实现是:+a.b.c.d/e:协议号|目的端口号,紧接着在解析包过滤配置文件的时候增加对协议和端口的解析,并且在ipv4_subnet结构体中增加协议和端口的字段。最后在pf_addr_test中这么实现:
if (pfs && !pfs->kill) {
const in_addr_t addr = in_addr_t_from_mroute_addr (dest);
const struct pf_subnet *se = pfs->sns.list;
const struct openvpn_iphdr *pip;
int ipoff = (tunnel_type == DEV_TYPE_TAP)?sizeof(struct openvpn_ethhdr):0;
//不考虑变长的IP协议头
int tloff = ipoff + sizeof(struct openvpn_iphdr);
verify_align_4 (buf);
pip = (struct openvpn_iphdr *)(BPTR (buf)+ipoff);
const uint8_t proto = pip->protocol;
uint16_t dport;
if (proto == OPENVPN_IPPROTO_TCP) {
struct openvpn_tcphdr *ptcp = (struct openvpn_tcphdr*)(BPTR(buf)+tloff);
//对于TCP的后续数据,直接通过,因为没有syn的通过,就不会有后续的数据
if (!(ptcp->flags & OPENVPN_TCPH_SYN_MASK))
return true;
dport = ntohs(ptcp->dest);
} else if (proto == OPENVPN_IPPROTO_UDP) {
}
…
while (se) {
if (((addr & se->rule.netmask) == se->rule.network) &&
se->rule.proto == proto && se->rule.dport == dport) {
…
}
}
…
return pfs->sns.default_allow;
这样就可以实现和iptables一样的策略规则了,虽然还不支持其它的match,而且配置文件显得很是奇怪,然而这已经足够了。
OpenVPN的包过滤机制对性能是有些影响,使本来性能就不是很好的OpenVPN更是雪上加霜,然而功能的实现总是要付出些性能代价的,就连Cisco如此凶猛的家伙都是这样。
2.6. 基于用户的包过滤
所谓的internal packet filter和internal route是一样的,就是工作在OpenVPN内部的一个过滤机制,它的主要作用在于限制client-to-client之间的通信,因为client-to-client之间的通信完全是在内部被路由的,外部的系统路由在这里起不到作用的。client-to-client之间的通信过滤完全是OpenVPN内部进行的。
关于OpenVPN内部包过滤机制的文档真的特别少,少之又少,好不容易才在网上找了一篇,加上我自己的这篇,基本够操作了。因此我把那篇文章(《OpenVPN’s built-in packet filter》)大致意思总结了一下: OpenVPN提供了一种内部的包过滤机制来限制client-to-client之间的通信。总的来讲,每一个client都会有一个过滤规则集,限制该client允许或者不允许访问的其它用户以及IP网段。那篇文章给出一个场景,一共四个人,分别是john,nick,bob,max,这四个人接入在同一个使能client-to-client的OpenVPN服务器上,然而需求是他们之间的互相访问是被严格控制的。下面的表格显示了他们之间相互访问的规则,yes代表可以访问,no代表不可以访问:
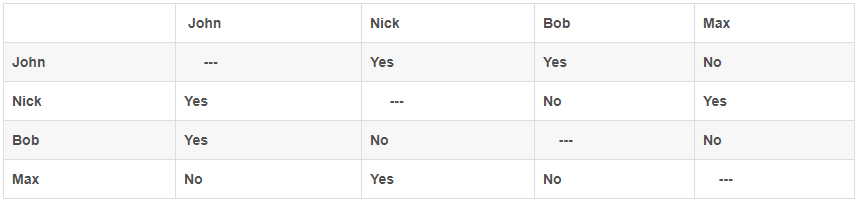
根据前面个小节的分析,看懂下面的配置文件应该不成问题,只是将IP网段换成了client证书的CN项,注意为了避免混乱,请在启动OpenVPN服务器时不要使用duplicate-cn选项。下面是各个用户的配置文件,看完配置文件后,我们再看看这些配置文件中的规则是怎么样配置到各个用户的:
$ cat /etc/openvpn/john.pf
[CLIENTS DROP]
+nick
+bob
[SUBNETS ACCEPT]
[END]
$ cat /etc/openvpn/nick.pf
[CLIENTS DROP]
+john
+max
[SUBNETS ACCEPT]
[END]
$ cat /etc/openvpn/bob.pf
[CLIENTS DROP]
+john
[SUBNETS ACCEPT]
[END]
$ cat /etc/openvpn/max.pf
[CLIENTS DROP]
+nick
[SUBNETS ACCEPT]
[END]
那么这些配置文件如何和具体用户关联呢?实际上在每个用户接入到VPN服务器的时候都会调用pf_init_context函数,该函数和pf相关的大体如下:
void
pf_init_context (struct context *c)
{
struct gc_arena gc = gc_new ();
if (plugin_defined (c->plugins, OPENVPN_PLUGIN_ENABLE_PF)) {
const char *pf_file = create_temp_file …
if( pf_file ) {
//将临时文件名称设置成环境变量很关键
setenv_str (c->c2.es, "pf_file", pf_file);
if (plugin_call (c->plugins, …) {
…
} else {
//disable packet filter
}
}
…
}
这样,每一个用户就都有了一个值为pf临时文件名的环境变量,当调用client-connect脚本或者plugin的时候,这个环境变量就大大的有用了,请看下面的client-connect脚本:
#!/bin/sh
# /etc/openvpn/client-connect.sh: sample client-connect script using pf rule files
# rules template file
template="/etc/openvpn/${common_name}.pf"
# create the file OpenVPN wants with the rules for this client
if [ -f "$template" ] && [ ! -z "$pf_file" ]; then
cp -- "$template" "$pf_file"
else
# if anything is not as expected, fail
exit 1
fi
这个脚本就是为这些环境变量指示的pf策略规则集文件填值的,填什么值呢?填上述的配置文件啊。到此为止,功能就实现了。
那么那个plugin仅仅是为了传输那个配置文件么?其实不应该是那样的啊,以下是我昨晚写的一个plugin,那时我还没有看到这篇《OpenVPN’s built-in packet filter》:
struct plugin_context {
char name[1];
};
OPENVPN_EXPORT openvpn_plugin_handle_t
openvpn_plugin_open_v1 (unsigned int *type_mask, const char *argv[], const char *envp[])
{
struct plugin_context *context;
context = (struct plugin_context *) calloc (1, sizeof (struct plugin_context));
*type_mask =OPENVPN_PLUGIN_MASK(OPENVPN_PLUGIN_ENABLE_PF);
return (openvpn_plugin_handle_t) context;
}
OPENVPN_EXPORT int
openvpn_plugin_func_v1 (openvpn_plugin_handle_t handle, const int type, const char *argv[], const char *envp[])
{
struct plugin_context *context = (struct plugin_context *) handle;
return OPENVPN_PLUGIN_FUNC_SUCCESS;
}
OPENVPN_EXPORT void
openvpn_plugin_close_v1 (openvpn_plugin_handle_t handle)
{
struct plugin_context *context = (struct plugin_context *) handle;
free (context);
}
虽然什么也没有做,然而这是必须的。实际上应该在这个plugin里面做更多事的,比如通知外部程序,比如设置和外部程序的联动等等。而且我也知道,如果不返回FUNC_SUCCESS,那么将禁用该用户的packet filter,很显然在plugin中应该判断是否针对这个用户进行filter,然而调用plugin的时候,此用户的instance刚刚建立,证书还没有提交呢,什么信息都没有,这就导致没什么事情可做。今天看了这篇文章后,那哥们也写了一个plugin,如下:
/* dummy context, as we need no state */
struct plugin_context {
int dummy;
};
/* Initialization function */
OPENVPN_EXPORT openvpn_plugin_handle_t openvpn_plugin_open_v1 ( unsigned int *type_mask,
const char *argv[],
const char *envp[])
{
struct plugin_context *context;
/* Allocate our context */
context = (struct plugin_context *)
calloc (1, sizeof (struct plugin_context)); /* Which callbacks to intercept. */
*type_mask = OPENVPN_PLUGIN_MASK (OPENVPN_PLUGIN_ENABLE_PF); return (openvpn_plugin_handle_t) context;
}
/* Worker function */
OPENVPN_EXPORT int openvpn_plugin_func_v2 (
openvpn_plugin_handle_t handle,
const int type,
const char *argv[],
const char *envp[],
void *per_client_context,
struct openvpn_plugin_string_list **return_list) {
if (type == OPENVPN_PLUGIN_ENABLE_PF) {
return OPENVPN_PLUGIN_FUNC_SUCCESS;
} else { /* should not happen! */
return OPENVPN_PLUGIN_FUNC_ERROR;
}
}
/* Cleanup function */
OPENVPN_EXPORT void openvpn_plugin_close_v1 (
openvpn_plugin_handle_t handle)
{
struct plugin_context *context = (struct plugin_context *) handle;
free (context);
}
除了代码比我的更规范,多了注释之外,没有什么不同的。而且作者说:The fact that the worker function is invoked at client connection and then is re-invoked periodically makes it possible to dynamically change or disable the filtering policy for a client (OpenVPN will re-read the rule file if it changes); in our example we just return success always.
我没有看出OpenVPN在对这个plugin re-invoked periodically了。实际上真的应该周期调用它的,正如作者所说。
看了这篇《OpenVPN’s built-in packet filter》我发现自己遇到了知音,行文的风格我们太像了,我也自恋一把,跟人家套套近乎…不管怎么说,OpenVPN的packet filter机制是基于每用户,这种灵活性真的太有用了,只是是不是在client-connect这个HOOK点创建这个pf临时文件更好些呢?此时可以得到用户的所有信息,可以在plugin中决定是否对这个用户开启pf,而且还可直接将针对用户的规则集填入到那个pf临时文件中。我实在想不通OpenVPN的开发者为何用现有的方式来实现这么有用的机制…
3. 总结
总的来讲,OpenVPN的包过滤机制实现的很是恰到好处,使得OpenVPN作为一个用户态的VPN框架能够和系统的路由以及包过滤独立开来。然而美中不足的是,它的配置有些奇怪,甚至有些复杂。
