

What
koa-mock-swich是一个前端mock数据、并可以管理返回数据的server。
Why
为什么需要koa-mock-switch。
目前开发过程中的mock数据方式,主流来说分为:
1.后端mock数据
即,局域环境有一个专门模拟数据用的数据库,然后,后端开发完接口以后,和线上一样地进行增删改查,最后返回给前端数据。
缺点:
时间上,前端在需要数据接口的时候,不得不等后端开发完接口以后,才能进行下一步开发。 职责上,即使前端开发页面的效率很高,但是因为最后完成的时间肯定是在后端之后的,如果一个项目进度耽误了,前端的锅是背定了。
2.前端搭建mock数据服务
我们前端,一般都会自己用express或者koa搭建自己的本地前端mock数据服务,市面上也有很多现成的npm可以使用。
优点:
前后端并行开发。前后端只需要在开发之前,一起定义好接口规范即可。之后前端按照api文档模拟mock数据,自己可以躲在小黑屋独自开发,直到最后的联调。
通过对比,我们发现前端搭建mock数据服务的方式无疑是前端开发的首选。 但是,对于传统的前端mock服务,我们做的仅仅只有,前端页面发起请求,mock服务接收请求,根据请求路径寻找对应的mock文件,最后返回给前端。 相信大多公司也是这么干的。
那它有什么不足呢?
考虑一下以下场景:
如果我们想要返回不同的mock数据,开发者不得不手动的修改mock数据源文件,每次注释,解注释。
状态少还可以,比如一个接口,成功或失败,在界面的显示需要不同,因此,我们就需要写完两组模拟数据,并注释一组比如失败,等到需要用失败的时候,解注释失败,注释成功。
如果状态多呢?比如一个用户信息接口,用户分为企业用户和个人用户,然后,企业用户有四种状态:未实名、实名中、已实名、实名失败。默认模拟数据为企业用户->已实名,这个时候,我们想要测测所有的情况,那就得做7次注释加解注释的操作。
版本迭代了,已实名还有分:初级会员、中级会员、高级会员、超级会员。我们以后每次改相关代码,为了避免出bug被测试看不起,就不得不所有的情况全都再测一遍。

如果状态更多呢?
有同学说,我三年的注释解注释工作经验,怕这百把十个操作?我就喜欢每次改完代码就一顿注释解注释操作,让老板看到,我工作是有多么饱和。

我相信有些很有毅力的同学,会觉得这都不是事儿。但是,这么做的话,我们能保证我们不会漏掉任何一个有多个状态的接口吗?
又有同学说:恩,这个不难,在每个有多个状态的mock文件中加个标记,比如本王宇宙最牛逼这行注释,然后全局搜索,就能知道哪些mock文件会有多状态了。
那我们能保证我们不会把状态拼接错乱吗?比如,明明是个人用户,却不小心解注释了企业用户的某些状态。 有同学说:小意思,写注释就好,想要多少写多少,下次一行行看注释就好了,吐了算我输。 恩~~~对于这样的杠精,我只能说:

回归正题,为了解决这些问题,koa-mock-switch诞生了。
How
那么,怎么设计koa-mock-switch这个server呢?
首先,先说一下我们的期望,我们期望:
1、有一个涉及多状态mock数据的管理页面,方便查看
2、通过UI界面的操作就可以控制返回对应状态的mock数据
其实这个方案并不是我首创的,最开始接触这个方案,是从我们部门同事那,原始版叫做mock-middleware。我先解释一下他的实现原理。
前端项目browser -> node 算法:
其实就是在express或者koa的node服务中,维护一个全局变量,我们叫$config,数据类型为对象,key为api的地址,value为返回的模拟数据。如果node端接收到浏览器的请求的话,先在$config中查找,看看是否存在当前api,有的话直接返回,没有的话,就寻找对应的mock文件,返回数据。同时,将api作为key,返回数据作为value存入$config。
mock管理界面browser -> node 算法:
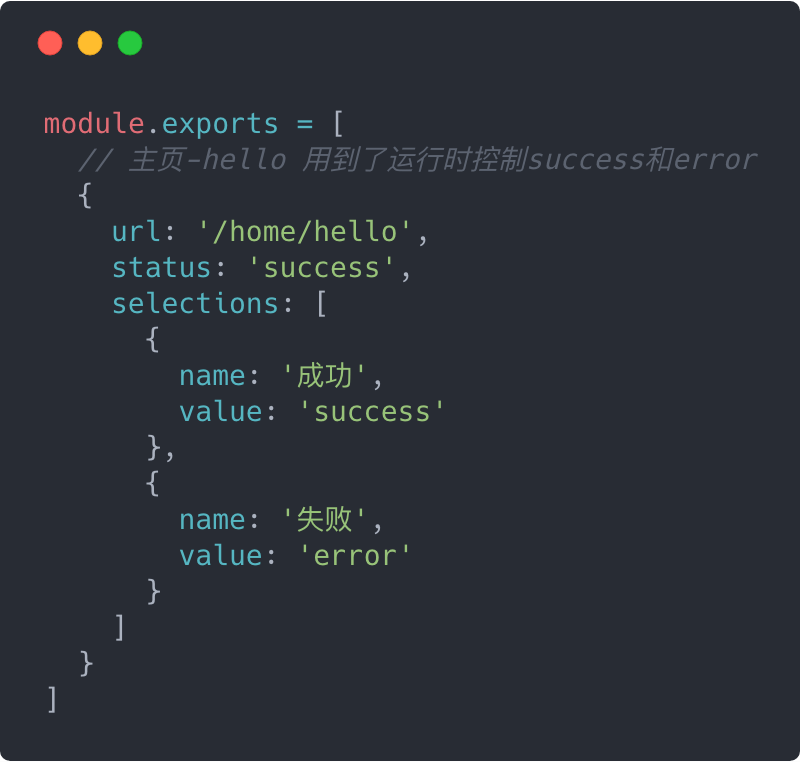
为了达到通过UI界面的操作就可以控制返回对应状态的mock数据的效果,会有一个和项目无关的,专门用来管理mock返回数据的页面,我们就叫做mock-management-page吧,如图:
 这个页面的列表渲染,依赖与事先创建的mockSwitchMap。
这个页面的列表渲染,依赖与事先创建的mockSwitchMap。
渲染完以后,只要切换状态,就会想node服务发起ajax请求,参数为api的地址以及对应的status(如成功或失败)。node端接收到后,读取该api的mock文件,根据需要的状态,更新$config。
如此一来,我们就可以通过mock-management-page,在开发的时候,简单的点击一下按钮,就达到了切换返回数据的目的。
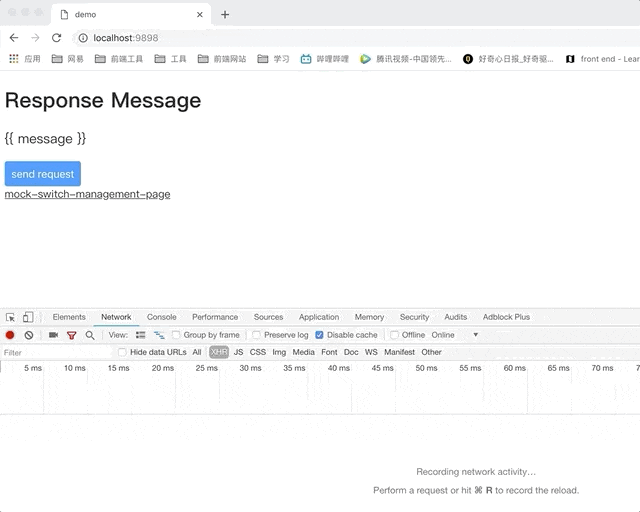
然而,还是会遇到问题,从算法可以看出,mock-management-page可以发起ajax对应的status是单一的,会遇到什么问题呢?
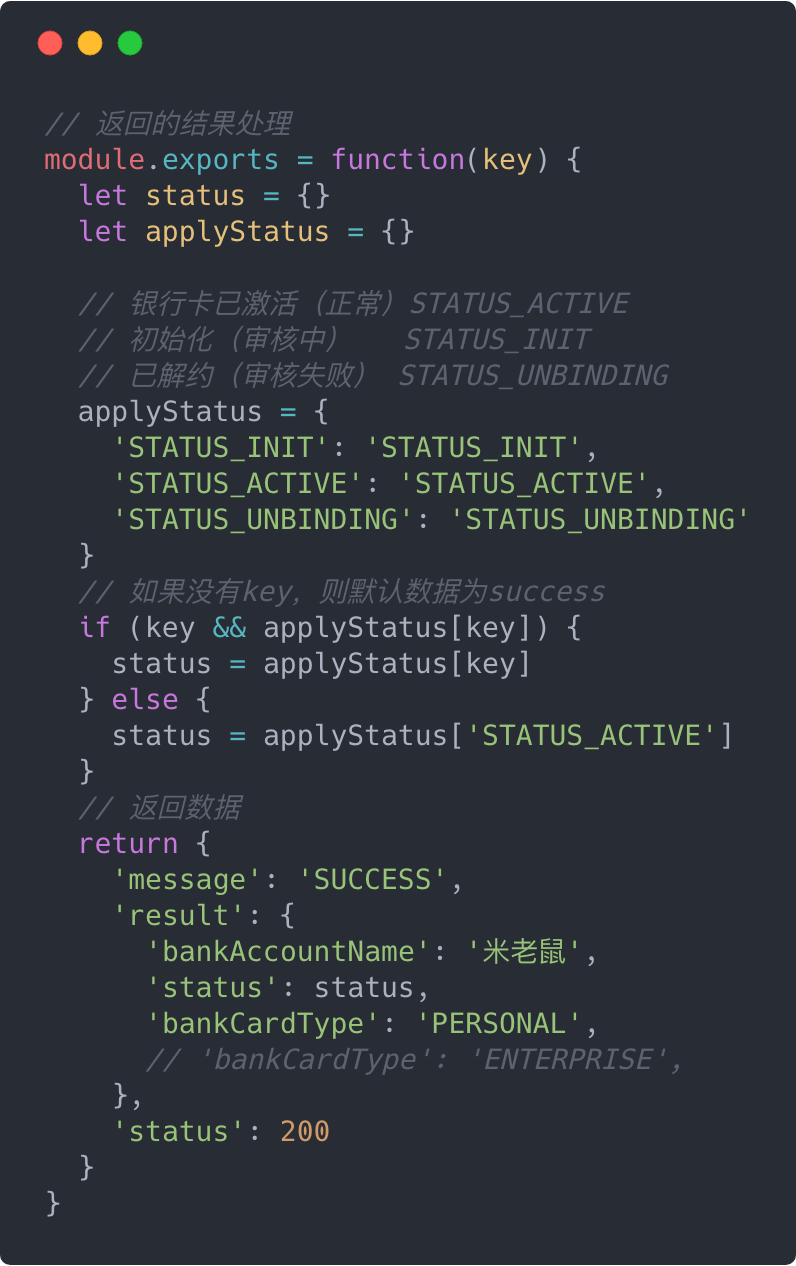
缺点很明显:
1、不得在每次的返回函数中,根据key(即之前说的各种状态)进行人工处理。
2、我们看到有段注释// 'bankCardType': 'ENTERPRISE',,我们依然用了传统的注释,解注释方式来切换返回数据。因为,我们之前说过mock-management-page可以发起ajax对应的status是单一的。如果我们一定要把它变为可切换方式,我们不得不这么写:
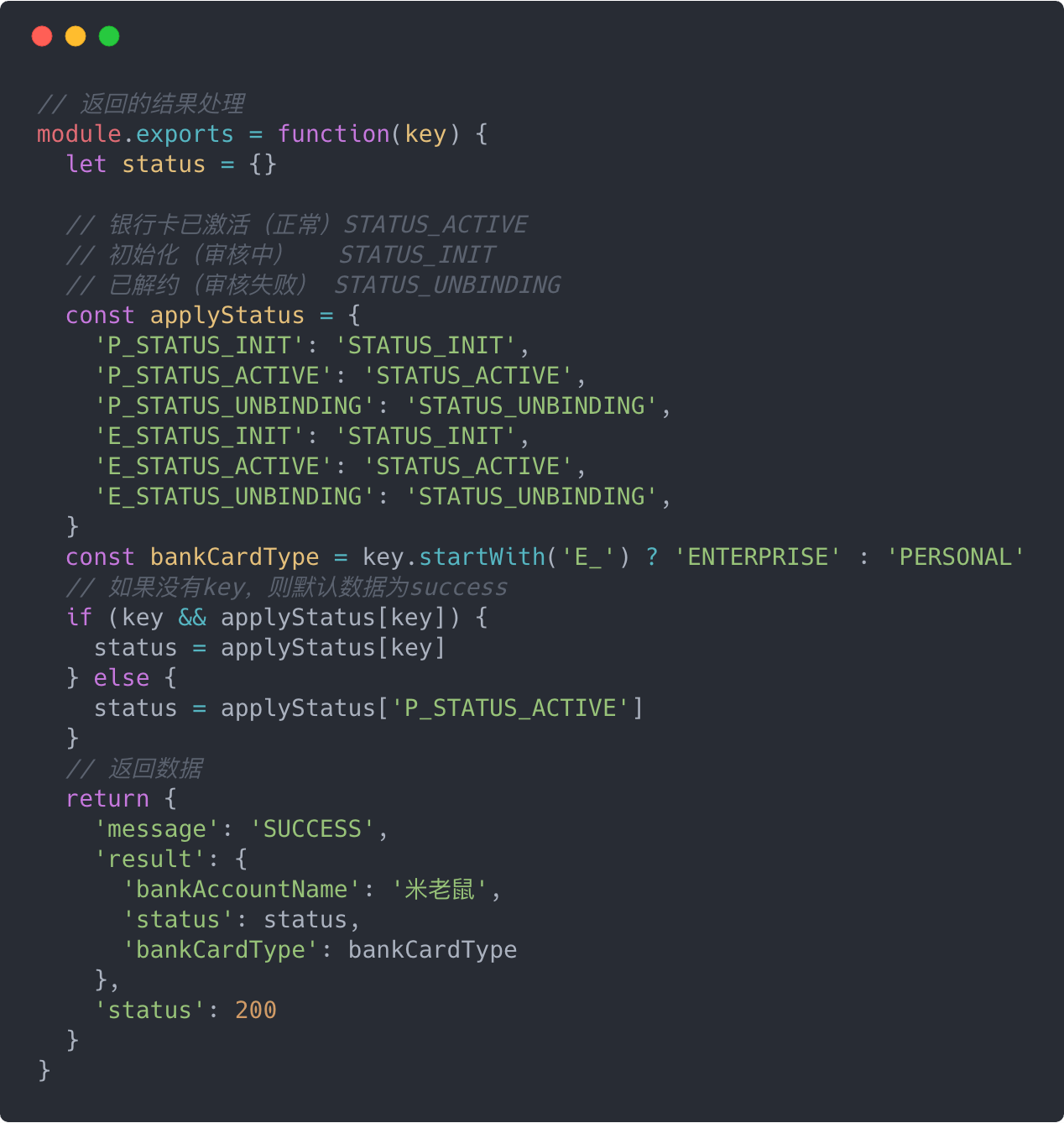
我们发现,处理状态的过程又多了,最终导致该接口状态越多,处理逻辑约繁重,想想都觉得好心疼,做了这么多,回报却不是很大。
但是,细心的同学可以发现,我们根据key(即之前说的各种状态)的名字规定,可以做些不同的处理,所以是不是存在某种方式,可以通过一个通用的数据处理方法,自动地根据key(即之前说的各种状态)的规则,处理后得到最终理想的数据呢?
当然可以!最后,我们的任务就是:制定key规则;编写一个通用数据处理函数。
Rule
我们通过事先约定来规定mockSwitchMap的value,为了便于理解,我们回到Hello Kitty的例子,我们重新构造mockSwitchMap的value:
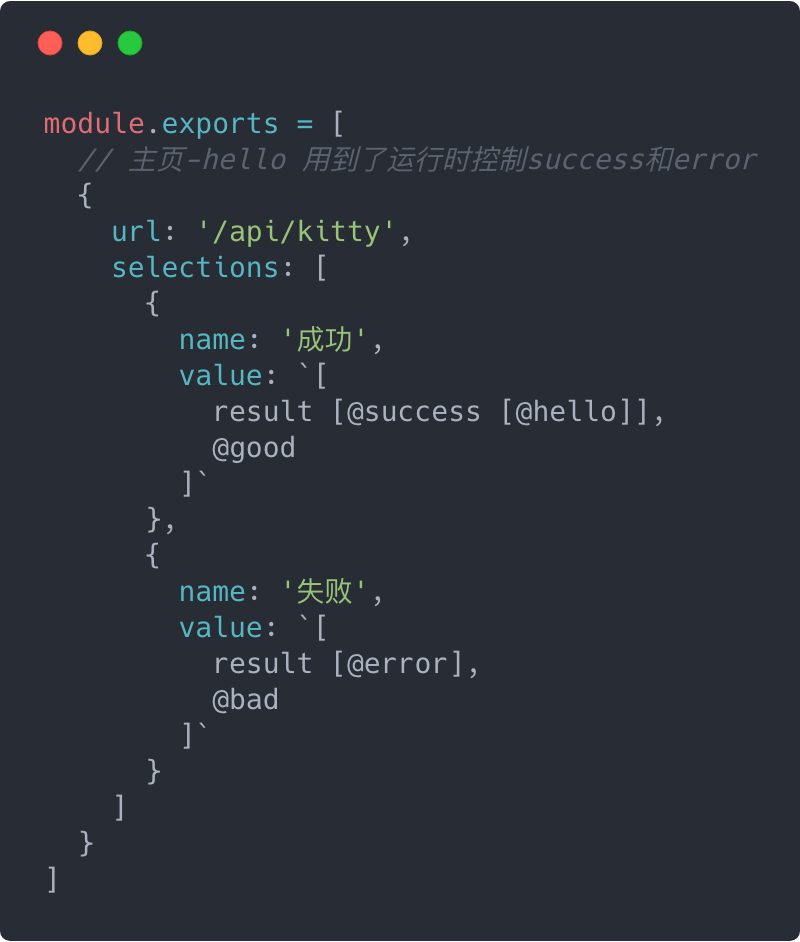
我们[]代表数据的层级,用@代表状态,@作为状态选项,经过处理以后,会向上提升一层。
/api/kitty的mock数据文件:
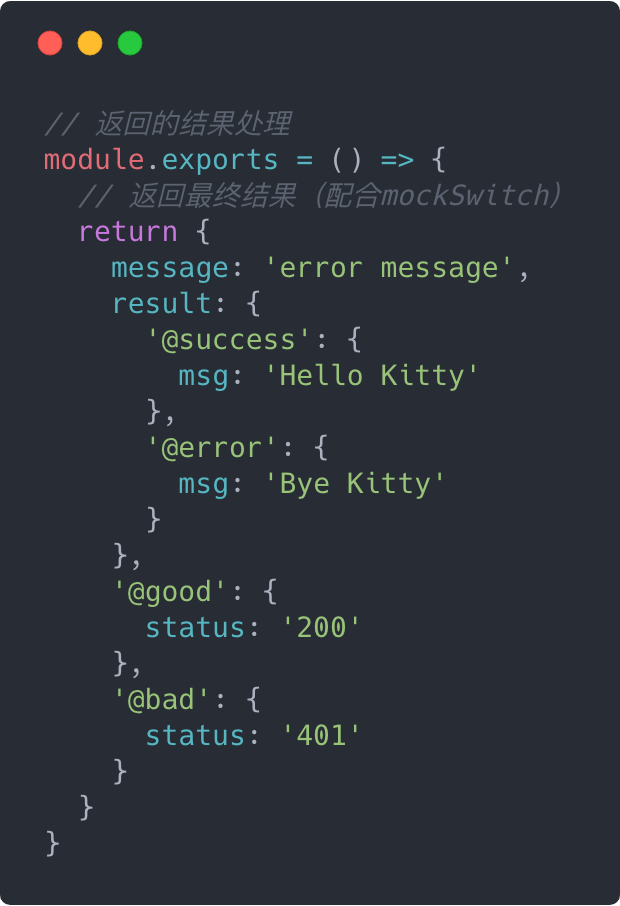
如此,我们就可以非常灵活地管理我们想要返回的mock数据,并且,对于哪些mock接口具有多种状态一目了然。此外,如果不需要多状态的mock数据和传统mock文件一样,不需要做任何额外的处理,比如Tom的mock文件:

npm安装
npm install -D koa-mock-switch
node端使用方法
const path = require('path')
// mock文件的根目录
const mockRoot = path.join(__dirname, './mock')
// require koa-mock-switch
const KoaMockSwitch = require('koa-mock-switch')
// mock管理列表
const mockSwitchMap = require('./mockSwitchMap.js')
/**
* KoaMockSwitch(mockRoot, mockSwitchMap, apiSuffix)
* @param mockRoot mock文件的根目录
* @param mockSwitchMap mock管理列表
* @param apiSuffix 客户端请求api的后缀,比如'/api/kitty.json',apiSuffix就是'.json'
*/
const mock = new KoaMockSwitch(mockRoot, mockSwitchMap, '.htm')
// 启动mock服务
mock.start(7878)
还是对使用方法疑惑的同学,可以参考demo。
项目地址demo
项目中有demo演示,同学们可以自己clone后体验下。 地址:koa-mock-switch
demo启动
安装
npm install
第一个窗口shell
npm run mock
第二个窗口shell
npm run demo
