

本文由云+社区发表
SQLite 在移动端开发中广泛使用,其使用质量直接影响到产品的体验。
常见的 SQLite 质量监控一般都是依赖上线后反馈的机制,比如耗时监控或者用户反馈。这种方式问题是:
- 事后发现,负面影响已经发生。
- 关注的只是没这么差。eg. 监控阈值为 500ms ,那么一条可优化为 20ms 而平均耗时只有 490ms 的 sql 就被忽略了。
能否在上线前就进行SQLite使用质量的监控?于是我们尝试开发了一个工具: SQLiteLint 。虽然名带 “lint ” ,但并不是代码的静态检查,而是在 APP 运行时对 sql 语句、执行序列、表信息等进行分析检测。而和 “lint” 有点类似的是:在开发阶段就介入,并运用一些最佳实践的规则来检测,从而发现潜在的、可疑的 SQLite 使用问题。
本文会介绍 SQLiteLint 的思路,也算是 SQLite 使用经验的分享,希望对大家有所帮助。
简述
SQLiteLint 在 APP 运行时进行检测,而且大部分检测算法与数据量无关即不依赖线上的数据状态。只要你触发了某条 sql 语句的执行,SQLiteLint 就会帮助你 review 这条语句是否写得有问题。而这在开发、测试或者灰度阶段就可以进行。
检测流程十分简单:
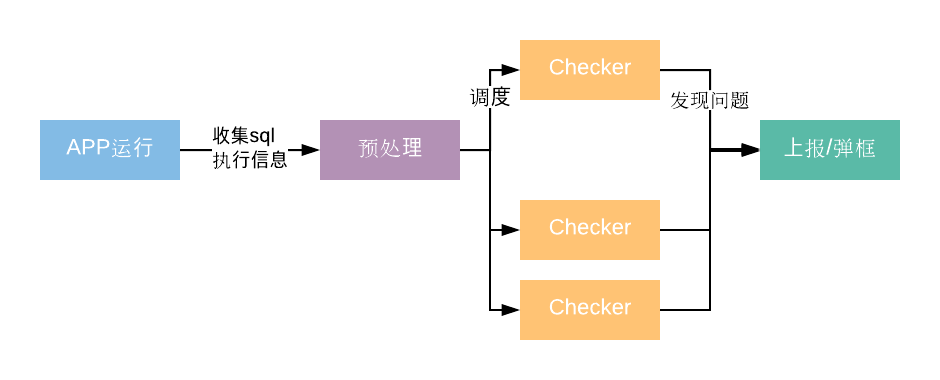
\1. 收集 APP 运行时的 sql 执行信息 包括执行语句、创建的表信息等。其中表相关信息可以通过 pragma 命令得到。对于执行语句,有两种情况: a)DB 框架提供了回调接口。比如微信使用的是 WCDB ,很容易就可以通过MMDataBase.setSQLiteTrace 注册回调拿到这些信息。 b) 若使用 Android 默认的 DB 框架,SQLiteLint 提供了一种无侵入的获取到执行的sql语句及耗时等信息的方式。通过hook的技巧,向 SQLite3 C 层的 api sqlite3_profile 方法注册回调,也能拿到分析所需的信息,从而无需开发者额外的打点统计代码。
\2. 预处理 包括生成对应的 sql 语法树,生成不带实参的 sql ,判断是否 select* 语句等,为后面的分析做准备。预处理和后面的算法调度都在一个单独的处理线程。
\3. 调度具体检测算法执行 checker 就是各种检测算法,也支持扩展。并且检测算法都是以 C++ 实现,方便支持多平台。而调度的时机包括:最近未分析 sql 语句调度,抽样调度,初始化调度,每条 sql 语句调度。
\4. 发布问题 上报问题或者弹框提示。
可以看到重点在第 3 步,下面具体讨论下 SQLiteLint 目前所关注的质量问题检测。
检测问题简介
一、检测索引使用问题
索引的使用问题是数据库最常见的问题,也是最直接影响性能的问题。SQLiteLint 的分析主要基于 SQLite3 的 "explain query plan" ,即 sql 的查询计划。先简单说下查询计划的最常见的几个关键字:
SCAN TABLE: 全表扫描,遍历数据表查找结果集,复杂度 O(n) SEARCH TABLE: 利用索引查找,一般除了 without rowid 表或覆盖索引等,会对索引树先一次 Binary Search 找到 rowid ,然后根据得到 rowid 去数据表做一次 Binary Search 得到目标结果集,复杂度为 O(logn) USE TEMP B-TREE: 对结果集临时建树排序,额外需要空间和时间。比如有 Order By 关键字,就有可能出现这样查询计划
通过分析查询计划,SQLiteLint 目前主要检查以下几个索引问题:
1. 未建索引导致的全表扫描(对应查询计划的 SCAN TABLE... )
虽然建立索引是最基本优化技巧,但实际开发中,很多同学因为意识不够或者需求太紧急,而疏漏了建立合适的索引,SQLiteLint 帮助提醒这种疏漏。问题虽小,解决也简单,但最普遍存在。 这里也顺带讨论下一般不适合建立索引的情况:写多读少以及表行数很小。但对于客户端而言,写多读少的表应该不常见。而表行数很小的情况,建索引是有可能导致查询更慢的(因为索引的载入需要的时间可能大过全表扫描了),但是这个差别是微乎其微的。所以这里认为一般情况下,客户端的查询还是尽量使用索引优化,如果确定预估表数量很小或者写多读少,也可以将这个表加到不检测的白名单。
解决这类问题,当然是建立对应的索引。
2. 索引未生效导致的全表扫描(对应查询计划的 SCAN TABLE... )
有些情况即便建立了索引,但依然可能不生效,而这种情况有时候是可以通过优化 sql 语句去用上索引的。举个例子:
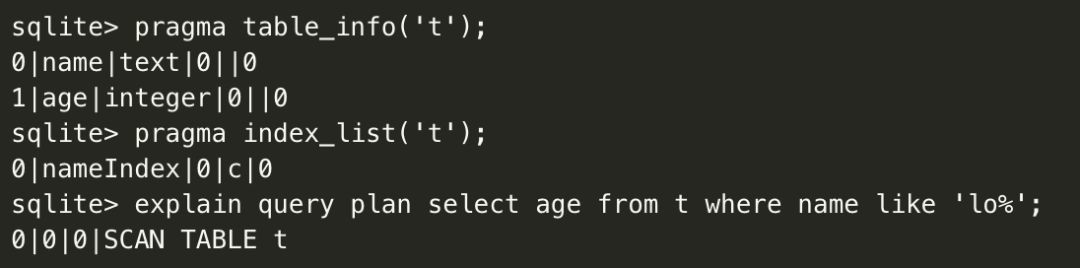
以上看到,即便已建立了索引,但实际没有使用索引来查询。 如对于这个 case ,可以把 like 变成不等式的比较:

这里看到已经是使用索引来 SEARCH TABLE ,避免了全表扫描。但值得注意的是并不是所有 like 的情况都可以这样优化,如 like '%lo' 或 like '%lo%' ,不等式就做不到了。
再看个位操作导致索引不生效的例子:
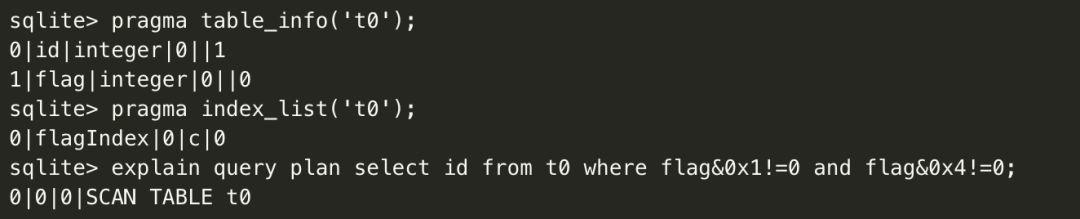
位操作是最常见的导致索引不生效的语句之一。但有些时候也是有些技巧的利用上索引的,假如这个 case 里 flag 的业务取值只有 0x1,0x2,0x4,0x8 ,那么这条语句就可以通过穷举值的方式等效:

以上看到,把位操作转成 in 穷举就能利用索引了。
解决这类索引未生效导致的全表扫描 的问题,需要结合实际业务好好优化sql语句,甚至使用一些比较trick的技巧。也有可能没办法优化,这时需要添加到白名单。
3. 不必要的临时建树排序(对应查询计划的 USE TEMP B-TREE... )。
比如sql语句中 order by 、distinct 、group by 等就有可能引起对结果集临时额外建树排序,当然很多情况都是可以通过建立恰当的索引去优化的。举个例子:
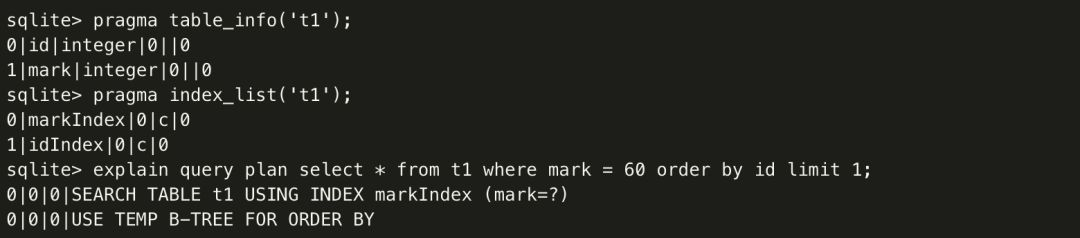
以上看到,即便id和mark都分别建立了索引,即便只需要一行结果,依然会引起重新建树排序( USE TEMP B-TREE FOR ORDER BY )。当然这个case非常简单,不过如果对 SQLite 的索引不熟悉或者开发时松懈了,确实很容易发生这样的问题。同样这个问题也很容易优化:

这样就避免了重新建树排序,这对于数据量大的表查询,优化效果是立竿见影的好。
解决这类问题,一般就是建立合适的索引。
4. 不足够的索引组合
这个主要指已经建立了索引,但索引组合的列并没有覆盖足够 where 子句的条件式中的列。SQLiteLint 检测出这种问题,建议先关注该 sql 语句是否有性能问题,再决定是否建立一个更长的索引。举个例子:
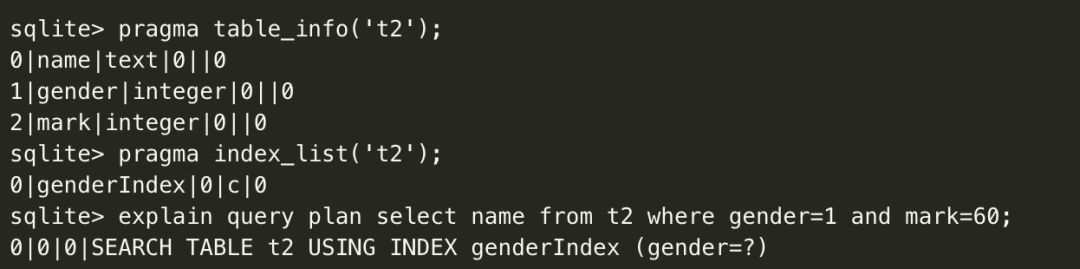
以上看到,确实是利用了索引 genderIndex 来查询,但看到where子句里还有一个 mark=60 的条件,所以还有一次遍历判断操作才能得到最终需要的结果集。尤其对于这个 case,gender 也就是性别,那么最多 3 种情况,这个时候单独的 gender 索引的优化效果的已经不明显了。而同样,优化也是很容易的:

解决这类问题,一般就是建立一个更大的组合索引。
5. 怎么降低误报
现在看到 SQLiteLint 主要根据查询计划的某些关键字去发现这些问题,但SQLite支持的查询语法是非常复杂的,而对应的查询计划也是无穷变化的。所以对查询计划自动且正确的分析,不是一件容易的事。SQLiteLint 很大的功夫也在这件事情上
所以对查询计划自动且正确的分析,不是一件容易的事。SQLiteLint 很大的功夫也在这件事情上。SQLiteLint 这里主要对输出的查询计划重新构建了一棵有一定的特点的分析树,并结合sql语句的语法树,依据一定的算法及规则进行分析检测。建分析树的过程会使用到每条查询计划前面如 "0|1|0" 的数字,这里不具体展开了。 举个例子:是不是所有带有 "SCAN TABLE" 前缀的查询计划,都认为是需要优化的呢?明显不是。具体看个 case :

这是一个联表查询,在 SQLite 的实现里一般就是嵌套循环。在这个语句中里, t3.id 列建了索引,并且在第二层循环中用上了,但第一层循环的 SCAN TABLE是无法优化的。比如尝试给t4的id列也建立索引:

可以看出,依然无法避免 SCAN TABLE 。对于这种 SCAN TABLE 无法优化的情况,SQLiteLint 不应该误报。前面提到,会对查询计划组织成树的结构。比如对于这个 case ,最后构建的查询计划分析树为:
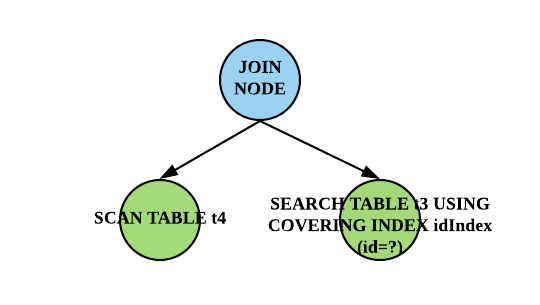
分析树,有个主要的特点:叶子节点有兄弟节点的是联表查询,其循环顺序对应从左往右,而无兄弟节点是单表查询。而最后的分析会落地到叶子节点的分析。遍历叶子节点时,有一条规则(不完整描述)是:
叶子节点有兄弟节点的,且是最左节点即第一层循环,且 where 子句中不含有相关常量条件表达式时,SCAN TABLE 不认为是质量问题。
这里有两个条件必须同时满足,SCAN TABLE 才不报问题:第一层循环 & 无相关常量表达式。第一层循环前面已经描述,这里再解释下后面一个条件。

由上看到,当select子句中出现常量条件表达式 “t4.id=666” , 若 t3.id,t4.id 都建了索引,是可以优化成没有 SCAN TABLE 。

而把 t4.id 的索引删除后,又出现了 SCAN TABLE 。而这种 SCAN TABLE 的情况,不满足规则里的的第二个条件,SQLiteLint 就会报出可以使用索引优化了。
这里介绍了一个较简单语句的查询计划的分析,当然还有更复杂的语句,还有子查询、组合等等,这里不展开讨论了。巨大的复杂性,无疑对准确率有很大的挑战,需要对分析规则不断地迭代完善。当前 SQLiteLint 的分析算法依然不足够严谨,还有很大的优化空间。 这里还有另一个思路去应对准确性的问题:对所有上报的问题,结合耗时、是否主线程、问题等级等信息,进行优先级排序。这个“曲线救国”来降低误报的策略也适用本文介绍的所有检测问题。
二、检测冗余索引问题
SQLiteLint 会在应用启动后对所有的表检测一次是否存在冗余索引,并建议保留最大那个索引组合。
先定义什么是冗余索引:如对于某个表,如果索引组合 index1,index2 是另一个索引组合 index3 的前缀,那么一般情况下 index3 可以替代掉 index1 和 index2 的作用,所以 index1,index2 就冗余了。而多余的索引就会有多余的插入消耗和空间消耗,一般就建议只保留索引 index3 。 看个例子:
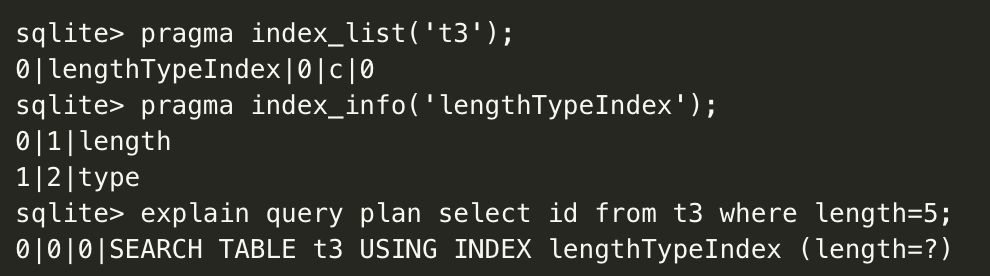
以上看到,如果已经有一个 length 和 type 的组合索引,就已经满足了单 length 列条件式的查询,没必要再为 length 再建一个索引。
三、检测 select * 问题
SQLiteLint这里通过扫描 sql 语法树,若发现 select * 子句,就会报问题,建议尽量避免使用 select * ,而是按需 select 对应的列。
select * 是SQLite最常用的语句之一,也非常方便,为什么还认为是问题的呢?这里有必要辩驳一下:
- 对于 select * ,SQLite 底层依然存在一步把 * 展开成表的全部列。
- select * 也减少了可以使用覆盖索引的机会。覆盖索引指索引包含的列已经覆盖了 select 所需要的列,而使用上覆盖索引就可以减少一次数据表的查询。
- 对于 Android 平台而言,select * 就会投射所有的列,那么每行结果占据的内存就会相对更大,那么 CursorWindow(缓冲区)的容纳条数就变少,那么 SQLiteQuery.fillWindow 的次数就可能变多,这也有一定的性能影响。
基于以上原因,出于 SQLiteLint 目标最佳实践的原则,这里依然报问题。
四、检测 Autoincrement 问题
SQLiteLint 在应用启动后会检测一次所有表的创建语句,发现 AUTOINCREMENT 关键字,就会报问题,建议避免使用 Autoincrement 。
这里看下为什么要检测这个问题,下面引用 SQLite 的官方文档:
The AUTOINCREMENT keyword imposes extra CPU, memory, disk space, and disk I/O overhead and should be avoided if not strictly needed. It is usually not needed.
可以看出 Auto Increment 确实不是个好东西。 ps. 我这里补充说明一下 strictly needed 是什么是意思,也就是为什么它不必要。通常 AUTOINCREMENT 用于修饰 INTEGER PRIMARY KEY 列,后简称IPK 列。而 IPK 列等同于 rowid 别名,本身也具有自增属性,但会复用删除的 rowid 号。比如当前有 4 行,最大的rowid是 4,这时把第 4 行删掉,再插入一行,新插入行的 rowid 取值是比当前最大的 rowid 加 1,也就 3+1=4 ,所以复用了 rowid 号 4 。而如果加以 AUTOINCREMENT 修饰就是阻止了复用,在这个情况,rowid 号是 5 。也就是说,AUTOINCREMENT 可以保证了历史自增的唯一性,但对于客户端应用有多少这样的场景呢?
五、检测建议使用 prepared statement
SQLiteLint 会以抽样的时机去检测这个问题,比如每 50 条执行语句,分析一次执行序列,如果发现连续执行次数超过一定阈值的相同的(当然实参可以不同)而未使用 prepared statement 的 sql 语句,就报问题,建议使用 prepared statement 优化。 如阈值是 3 ,那么连续执行下面的语句,就会报问题:

使用 prepared statement 优化的好处有两个:
- 对于相同(实参不同)的 sql 语句多次执行,会有性能提升
- 如果参数是不可信或不可控输入,还防止了注入问题
六、检测建议使用 without rowid 特性
SQLiteLint 会在应用启动后检测一次所有表的创建语句,发现未使用 without rowid 技巧且根据表信息判断适合使用 without rowid 优化的表,就报问题,建议使用 without rowid 优化。 这是 SQLiteLint 的另一个思路,就是发现是否可以应用上一些 SQLite 的高级特性。
without rowid 在某些情况下可以同时带来空间以及时间上将近一半的优化。简单说下原理,如:

对于这个含有 rowid 的表( rowid 是自动生成的),这时这里涉及到两次查询,一次在 name 的索引树上找到对应的 rowid ,一次是用这个 rowid 在数据树上查询到 mark 列。 而使用 without rowid 来建表:

数据树构建是以 name 为 key ,mark 为 data 的,并且是以普通 B-tree 的方式存储。这样对于刚刚同样的查询,就需要只有一次数据树的查询就得到了 mark 列,所以算法复杂度上已经省了一个 O(logn)。另外又少维护了一个 name 的索引树,插入消耗和空间上也有了节省。
当然 withou rowid 不是处处适用的,不然肯定是默认属性了。SQLiteLint 判断如果同时满足以下两个条件,就建议使用 without rowid :
- 表含有 non-integer or composite (multi-column) PRIMARY KEY
- 表每行数据大小不大,一个比较好的标准是行数据大小小于二十分之一的page size 。ps.默认 page size SQLite 版本3.12.0以后(对应 Android O 以上)是 4096 bytes ,以前是 1024 。而由于行数据大小业务相关,为了降低误报,SQLiteLint 使用更严格的判定标准:表不含有 BLOB 列且不含有非 PRIMARY KEY TEXT 列。
简单说下原因: 对于1,假如没有 PRIMARY KEY ,无法使用 without rowid 特性;假如有 INTEGER PRIMARY KEY ,前面也说过,这时也已经等同于 rowid 。 对于 2,小于 20 分之一 pagesize 是官方给出的建议。 这里说下我理解的原因。page 是 SQLite 一般的读写单位(实际上磁盘的读写 block 更关键,而磁盘的消耗更多在定位上,更多的page就有可能需要更多的定位)。without rowid 的表是以普通 B-Tree 存储的,而这时数据也存储在所有树结点上,那么假如数据比较大,一个 page 存储的结点变少,那么查找的过程就需要读更多的 page ,从而查找的消耗更大。当然这是相对 rowid 表 B*-Tree 的存储来说的,因为这时数据都在叶子结点,搜索路径上的结点只有 KEY ,那么一个page能存的结点就多了很多,查找磁盘消耗变小。这里注意的是,不要以纯内存的算法复杂度去考量这个问题。以上是推论不一定正确,欢迎指教。
引申一下,这也就是为什么 SQLite 的索引树以 B-Tree 组织,而 rowid 表树以 B*-Tree 组织,因为索引树每个结点的存主要是索引列和 rowid ,往往没这么大,相对 B*-Tree 优势就在于不用一直查找到叶子结点就能结束查找。与 without rowid 同样的限制,不建议用大 String 作为索引列,这当然也可以加入到 SQLiteLint 的检测。
小结
这里介绍了一个在开发、测试或者灰度阶段进行 SQLite 使用质量检测的工具,这个思路的好处是:
- 上线前发现问题
- 关注最佳实践
本文的较大篇幅其实是对 SQLite 最佳实践的讨论,因为 SQLiteLint 的思路就是对最佳实践的自动化检测。当然检查可以覆盖更广的范围,准确性也是挑战,这里还有很大的空间。
此文已由作者授权腾讯云+社区发布
