

我是一个前端,机缘巧合加入了一家AI创业公司,一年多过去了,所幸公司没倒,我得到了一些参与AI模型开发的机会,我发现所谓的“AI”虽然很复杂,但并不神奇,是可以被理解、学习的。趁着最近有空,计划写些文章分享见闻吧。
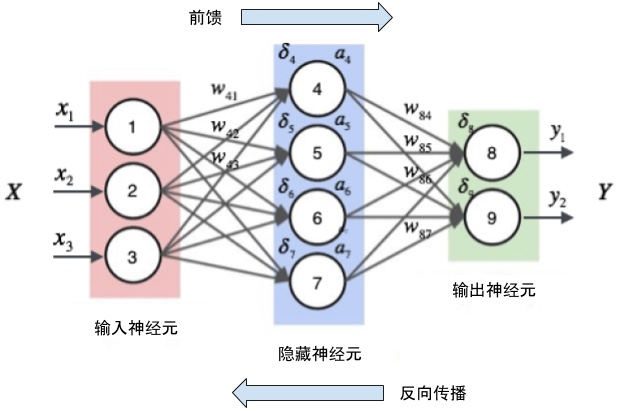
神经网络是一种机器学习算法,算是当前最火的人工智能技术了。“网络”由许多“层”组成,每层是一个处理单元,作用是将输入值按该层逻辑转换为输出值。 如果说特征抽取是一个复杂的大任务,那么“层”就是将大任务拆解后形成的一个一个独立的、单一职责的小任务,比如有些层是将图像文件转换为RGB矩阵;有些层用于抽取图像的颜色特征;有些层专门用于降维,将输入压缩为特定大小的矩阵。每层都能在不同层面描述或者处理图像的某个片面信息,将这些层按 适当的规则 连接在一起后,就构成一个能描述图像完整信息的“网”。模型开发的主要任务就在于如何设计层,以及如何将层连接在一起上。原理就是这样,但实际的开发非常非常复杂。
神经网络包含前向传播与反向传播两个过程,前向是将输入,比如一张图片,从网络输入层开始经过各层迭代处理,输出特征值;反向则是将输出的特征值与样本预期特征值之间的误差反向传回各层,各层根据误差调整权重。“模型训练”就是将大量样本输入到网络,网络在不断前向、反向的过程中慢慢调整各层权重,使得最终结果能“大概率”满足样本需求的状态。这个状态我们可以理解为一大堆参数,参数与网络模型共同组成我们日常所说的“模型”。
什么是训练样本
所谓的训练数据,就是经过预处理(一般是人工标注)后,有相对稳妥、精确的特征描述的数据集,以“样本”形式参与模型开发工作。那么,对训练数据集一般会有这样一些要求:
- 尽量准确,但不排除也很难排除有异常噪音的情况。毕竟是人工标注的,很难说数据一定正确,一个优秀的算法工程师应该具备一定的噪音处理能力
- 样本足够大。样本越大,得到准确结果的概率也就越大,小量样本容易出现 过拟合 的情况
- 能代表需求领域。比如,我现在要训练一个家具分类的模型,训练数据却是一堆衣服,这明显是不合理的。一般,样本数据应该是应用领域的抽样,应该能在统计意义上“代表”应用域。
- 适当的特征信息,比如,如果训练的是一个detect模型,那特征就应该图片进行分割后对局部的描述,也就是各种各样的box;如果样本是对整张图片的分类描述,那明显是不符合需求的。另外如果算法只能处理“矩形”,特征却是“不规则多边形”,那对算法来说也是一个不小的挑战,不过这一点一般可以通过工程手段做调整。
训练样本说白了就是一个大的数据集,要筹集这个数据大致需要做两步工作,以图像为例,一是收集大量的图片;而是处理图片,标识出图片包含的特征信息。
收集图片
如果出于学习目的,我们可以从各种开放数据源下载图片作为训练数据,好处是几乎没有成本,坏处是针对性很低。举几个例子:
- image-net,良好标注的数据集,每张图都会边框、边框分类
- Open Images Dataset,谷歌出品的数据集
- caffe、pytorch 等深度学习框架也都提供了很多训练用例
更多开放数据源,可以参考 数据集大全:25个深度学习的开放数据集。开放数据源一般都经过业界长期的试炼,有着比较完整、完善、正确的数据集,能够快速获取,作为学习素材是非常合适的。 但一般针对性不高,很多情况下并不符合需求,比如我要训练一个识别饮料的模型,就很难找到针对“饮料”这一类别,有足够sku样本的开放数据源。因此,很多模型开发还是需要自行筹备数据集,这里面门门道道就多了去了,不过方法也就那么几类:
- 通过爬虫收集网络图片,比如针对商品搜索场景,会写个爬虫爬爬某东某宝。这也是很多AI公司会配备爬虫工程师的原因
- 购买,现在已经有不少公司专门售卖各种数据集,如何数据集合适,这种方式会比自己做快捷很多。
- 由合作方提供,比如现在要为一个五金企业训练分类模型,那从他们手上很方便就能拿到各种产品图;又或者要训练一个癌细胞识别模型,这些X光片是非常敏感的隐私数据,全网基本上很难找到适合的,那由合作意愿提供也是非常合情合理的。
- 线下采集,有些模型针对性比较高,应用场景有限,而又找不到合适的数据集时,可能就需要有针对性的采集图片。国内也已经有很多外包采集公司,比如 京东众智、百度众包
经过上述方法收集来的图片,还需要经过一系列的预处理,比如把剔除无效样本、补充缺失样本;比如太大的图片做个压缩;比如给每张图添加一些原信息。这些步骤可能很复杂,可能很简单,变动太大,随机应变即可。真正的重点是后续的步骤:图像标注。
图像标注
标注就是以各种技术手段将图像信息以数字化、计算机可理解的方式表达出来,比如以边框、类别结构标注图像中的物体。 标注不是一个必选项,有些模型仅仅关注图像的视觉信息,不对内容做任何语义解读,不需要分割,不需要分类,比如常见的各种通用图像搜索。 取决于样本数据量,标注过程往往需要大量人力投入,标注的规则也会应模型需求的变化而变化。不过常见的标注需求还是比较容易总结的,包括:
- 标注图像中物体的边框、类别或文字信息
- 标注同类图像集,常见的有商品同款标注
- 图像分类,针对整图信息的分类
- 图像相似度标注,一般用于评价样品图与候选图集之间的相似性,特别适用于评价搜索服务质量
- 关键点标注
对标注的管理往往是对人以及信息的管理。前面说过,训练数据的正确性对模型质量有非常非常大的影响,依靠人力的标注很难百分比保证正确性,但还是有必要保证大的正确率。需要通过各种工程手段、管理方法,从立项、准备数据到确定标注群体、确定工期、确定标注规则、标注、质量审核、数据过滤、算法验收等等,确保每个步骤尽量不要出现纰漏。当然,在保质保量、按时完成的前提下,一个好的管理者,往往还要考虑成本。跟人打交道,每个步骤都可能出幺蛾子,都有一些讲究,比如说:
1. 确定标注群体
也就是确定由谁来标注。笔者接触过的大部分标注任务,都比较简单,标个人脸;标个商品,基本没有门槛,这就适合由学历不高,但价格低廉的人来做。这种情况下往往可以通过众包、外包方式,将标注工作分发到二三线,甚至农村地区。现在已经有一些很成熟的众包标注网站,比如 京东众智、百度众包、龙猫,blabla。
也有一些对专业知识要求很高的任务,比如对癌细胞X光片的标注,这还真就必须得由经验老到的专业医生做。这种垂直领域的人才目前非常难找到合适的群体,数量少,成本低,周期长,一般也就大厂能搞搞。
2. 确定标注规则
商用模型都有特定需求,解决特定问题,模型所需要的训练数据也就需要根据应用需求的变化而变化。训练数据的标注规则,可能很简单,比如,一个只用于识别可口可乐的模型,那就只需要标志出图片中可口可乐包装的位置、sku信息;也可能会非常非常复杂,比如上文提到的癌细胞标注,对癌细胞的识别需要高度专业知识,形状又千奇百怪;也可能会非常抽象,比如一个通用物体搜索模型,判断结果的好坏(DCG)非常依赖标注者主观意识,很难也不能定义统一规则。
标注规则对数据样本好坏有决定作用,必须慎之又慎,需要各种干系人介入反复讨论,这方面与需求工程倒是有几分相似之处。
3. 标注
有人有规则,那就可以开干了。标注过程可能需要面向大规模的人力,大批量的图像,耗费相当长一段时间,除了上述准备的充足外,如何提高信息传递率、如何尽早发现问题及时修正、如何优化工具降低标注成本、如何结算薪酬、如何协同调度多个标注任务。。。等等,太多问题需要考量,这方面就需要很强的开发、协调、质检、成本控制、资源调度等能力。
很多人把数据比喻成人工智能的煤炭能源,但这能源的生产行业目前很混乱原始,问题很大,行业很新,人才很少,我个人认为未来这方面的专业人才会越来越吃香。
作为一个开发,我更多关注于“标注工具”。标注工具可能很复杂,对功能、体验、性能、健壮性等等的要求,一点不比 TO C 产品低。我们的标注平台,由最初的单机单实例单数据库,发展到现在已经变成两台服务器、两个应用实例、两个MongoDB、两个mysql服务,代码上拆解成五个微服务、一个http服务(BFF);标注功能上,最复杂的一次是开发了一个图像分割工具,支持图像分割(基于 magic-wand-js)、多边形边框、剪切、复制、撤销、滤镜、导入、导出等等,严格来说已经算是一个不错的编辑器了,下次开一个专题聊聊。
后记
林林总总,聊了很多。2018的人工智能已经有些退烧,但涌入的资本并不见少,也依然有许多人才加入,至少近几年内,人工智能行业还是一个不错的选择。
