

首先,ts 的 github 地址:github.com/Microsoft/T…
。各位可先行下载。其编译部分位于 src/compiler 目录下。
其中分为以下几个关键部分,
- Scanner 扫描器(
scanner.ts) - Parser 解析器(
parser.ts) - Binder 绑定器(
binder.ts) - Checker 检查器(
checker.ts) - Emitter 发射器(
emitter.ts)
每个部分在源文件中均有独立文件,稍后会解释这些部分在编译过程中所起到的左右。
概览
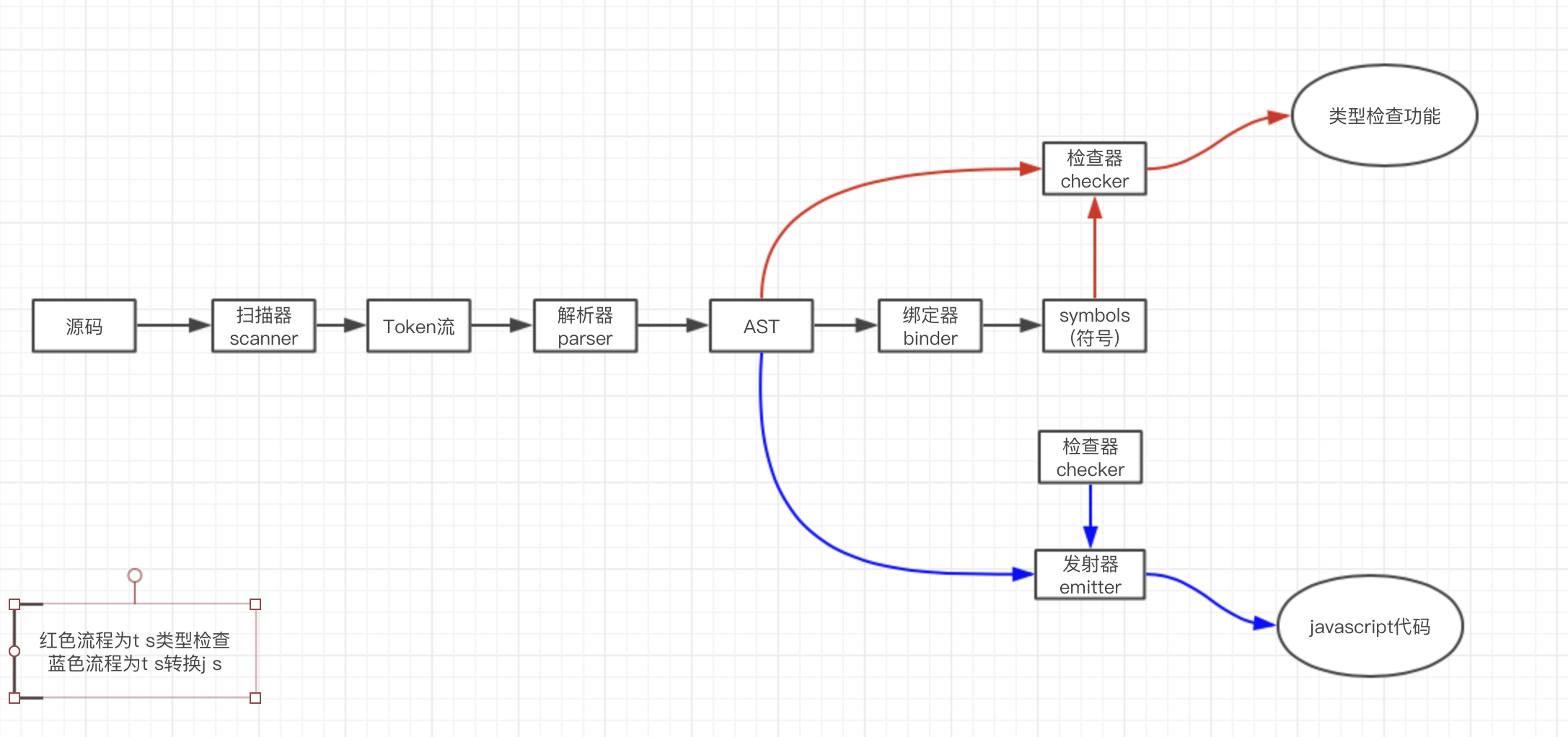
上图简单说明 TypeScript 编译器如何将上述几个关键部分组合在一起:
- 源码 ~ scanner(扫描器) ~ token数据流 ~ parser(解析器) -> AST(抽象语法树)
- AST(抽象语法树) ~ binder(绑定器) -> symbols(符号)
- AST(抽象语法树) + symbols ~ checker(检查器) -> 类型检查功能
- AST(抽象语法树) + checker(检查器) ~ emitter(发射器) -> js代码
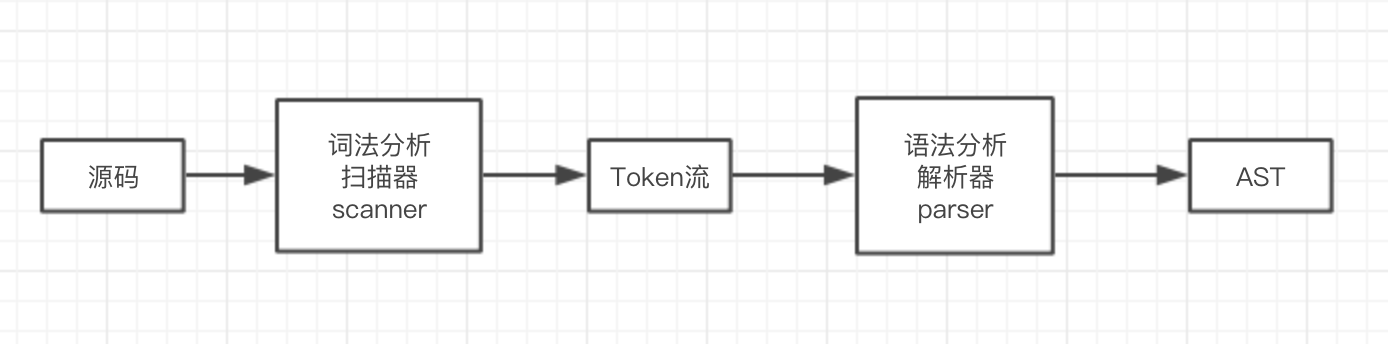
流程 1: 源码 => AST
源码 ~ scanner(扫描器) ~ token数据流 ~ parser(解析器) -> AST(抽象语法树)
typescript的扫描器位于scanner.ts,解析器位于parser.ts,在内部,由
parser解析器控制scanner扫描器将源码转化为抽象语法树(AST)。流程如下:

若以常见的AST生成过程类比,可简单类比上述的
扫描器阶段
可对应为
词法分析过程,解析器阶段可对应为语法分析过程。
有关AST抽象语法树 可参考 AST抽象语法树。
Parser 解析器对 Scanner 扫描器的使用
通过 parseSourceFile 设置初始状态并将工作交给 parseSourceFileWorker 函数。
parseSourceFile
export function parseSourceFile(fileName: string, sourceText: string, languageVersion: ScriptTarget, syntaxCursor: IncrementalParser.SyntaxCursor | undefined, setParentNodes = false, scriptKind?: ScriptKind): SourceFile {
scriptKind = ensureScriptKind(fileName, scriptKind);
//初始化状态
if (scriptKind === ScriptKind.JSON) {
const result = parseJsonText(fileName, sourceText, languageVersion, syntaxCursor, setParentNodes);
convertToObjectWorker(result, result.parseDiagnostics, /*returnValue*/ false, /*knownRootOptions*/ undefined, /*jsonConversionNotifier*/ undefined);
result.referencedFiles = emptyArray;
result.typeReferenceDirectives = emptyArray;
result.libReferenceDirectives = emptyArray;
result.amdDependencies = emptyArray;
result.hasNoDefaultLib = false;
result.pragmas = emptyMap;
return result;
}
//专备好扫描器状态
initializeState(sourceText, languageVersion, syntaxCursor, scriptKind);
//将工作交给 parseSourceFileWorker
const result = parseSourceFileWorker(fileName, languageVersion, setParentNodes, scriptKind);
clearState();
return result;
}
parseSourceFileWorker
该函数先创建一个 SourceFile AST 节点,然后从 parseStatement 函数开始解析源代码。一旦返回结果,就用额外信息(例如 nodeCount, identifierCount等) 完善 SourceFile 节点。
function parseSourceFileWorker(fileName: string, languageVersion: ScriptTarget, setParentNodes: boolean, scriptKind: ScriptKind): SourceFile {
const isDeclarationFile = isDeclarationFileName(fileName);
if (isDeclarationFile) {
contextFlags |= NodeFlags.Ambient;
}
// 先创造一个 SourceFile AST 节点
sourceFile = createSourceFile(fileName, languageVersion, scriptKind, isDeclarationFile);
sourceFile.flags = contextFlags;
// Prime the scanner.
nextToken();
// A member of ReadonlyArray<T> isn't assignable to a member of T[] (and prevents a direct cast) - but this is where we set up those members so they can be readonly in the future
processCommentPragmas(sourceFile as {} as PragmaContext, sourceText);
processPragmasIntoFields(sourceFile as {} as PragmaContext, reportPragmaDiagnostic);
// 调用 parseStatement 函数解析源码
sourceFile.statements = parseList(ParsingContext.SourceElements, parseStatement);
Debug.assert(token() === SyntaxKind.EndOfFileToken);
// 至871行 均为完善 sourcefile AST 节点
sourceFile.endOfFileToken = addJSDocComment(parseTokenNode());
setExternalModuleIndicator(sourceFile);
sourceFile.nodeCount = nodeCount;
sourceFile.identifierCount = identifierCount;
sourceFile.identifiers = identifiers;
sourceFile.parseDiagnostics = parseDiagnostics;
if (setParentNodes) {
fixupParentReferences(sourceFile);
}
return sourceFile;
function reportPragmaDiagnostic(pos: number, end: number, diagnostic: DiagnosticMessage) {
parseDiagnostics.push(createFileDiagnostic(sourceFile, pos, end, diagnostic));
}
}
节点创建:parseStatement/parseXXXX等
其中parseStatement函数,它根据扫描器返回的当前 token 来切换(调用相应的 parseXXX 函数),生成AST节点。
function parseStatement(): Statement {
// 此处 token 为 scanner扫描器 返回的 当前token流, SyntaxKind为AST的常量枚举类型,根据不同的类型创建不同的节点
switch (token()) {
// 类型为 SemicolonToken,调用parseEmptyStatement
case SyntaxKind.SemicolonToken:
return parseEmptyStatement();
case SyntaxKind.OpenBraceToken:
return parseBlock(/*ignoreMissingOpenBrace*/ false);
case SyntaxKind.VarKeyword:
return parseVariableStatement(<VariableStatement>createNodeWithJSDoc(SyntaxKind.VariableDeclaration));
case SyntaxKind.LetKeyword:
if (isLetDeclaration()) {
return parseVariableStatement(<VariableStatement>createNodeWithJSDoc(SyntaxKind.VariableDeclaration));
}
break;
case SyntaxKind.FunctionKeyword:
return parseFunctionDeclaration(<FunctionDeclaration>createNodeWithJSDoc(SyntaxKind.FunctionDeclaration));
case SyntaxKind.ClassKeyword:
return parseClassDeclaration(<ClassDeclaration>createNodeWithJSDoc(SyntaxKind.ClassDeclaration));
case SyntaxKind.IfKeyword:
return parseIfStatement();
case SyntaxKind.DoKeyword:
return parseDoStatement();
case SyntaxKind.WhileKeyword:
return parseWhileStatement();
case SyntaxKind.ForKeyword:
return parseForOrForInOrForOfStatement();
case SyntaxKind.ContinueKeyword:
return parseBreakOrContinueStatement(SyntaxKind.ContinueStatement);
case SyntaxKind.BreakKeyword:
return parseBreakOrContinueStatement(SyntaxKind.BreakStatement);
case SyntaxKind.ReturnKeyword:
return parseReturnStatement();
case SyntaxKind.WithKeyword:
return parseWithStatement();
case SyntaxKind.SwitchKeyword:
return parseSwitchStatement();
case SyntaxKind.ThrowKeyword:
return parseThrowStatement();
case SyntaxKind.TryKeyword:
// Include 'catch' and 'finally' for error recovery.
case SyntaxKind.CatchKeyword:
case SyntaxKind.FinallyKeyword:
return parseTryStatement();
case SyntaxKind.DebuggerKeyword:
return parseDebuggerStatement();
case SyntaxKind.AtToken:
return parseDeclaration();
case SyntaxKind.AsyncKeyword:
case SyntaxKind.InterfaceKeyword:
case SyntaxKind.TypeKeyword:
case SyntaxKind.ModuleKeyword:
case SyntaxKind.NamespaceKeyword:
case SyntaxKind.DeclareKeyword:
case SyntaxKind.ConstKeyword:
case SyntaxKind.EnumKeyword:
case SyntaxKind.ExportKeyword:
case SyntaxKind.ImportKeyword:
case SyntaxKind.PrivateKeyword:
case SyntaxKind.ProtectedKeyword:
case SyntaxKind.PublicKeyword:
case SyntaxKind.AbstractKeyword:
case SyntaxKind.StaticKeyword:
case SyntaxKind.ReadonlyKeyword:
case SyntaxKind.GlobalKeyword:
if (isStartOfDeclaration()) {
return parseDeclaration();
}
break;
}
return parseExpressionOrLabeledStatement();
}
例如:如果当前 token 是一个 SemicolonToken(分号标记),就会调用 paserEmptyStatement 为空语句创建一个 AST 节点。
paserEmptyStatement/parseIfStatement等等
function parseEmptyStatement(): Statement {
const node = <Statement>createNode(SyntaxKind.EmptyStatement);
parseExpected(SyntaxKind.SemicolonToken);
return finishNode(node);
}
function parseIfStatement(): IfStatement {
const node = <IfStatement>createNode(SyntaxKind.IfStatement);
parseExpected(SyntaxKind.IfKeyword);
parseExpected(SyntaxKind.OpenParenToken);
node.expression = allowInAnd(parseExpression);
parseExpected(SyntaxKind.CloseParenToken);
node.thenStatement = parseStatement();
node.elseStatement = parseOptional(SyntaxKind.ElseKeyword) ? parseStatement() : undefined;
return finishNode(node);
}
观察上述parseXXXX等,会发现其中存在三个关键函数createNode,parseExpected,finishNode
createNode
function createNode(kind: SyntaxKind, pos?: number): Node {
nodeCount++;
// 获取初始位置(可调用扫描器scanner的startPos,'Start position of whitespace before current token')
const p = pos! >= 0 ? pos! : scanner.getStartPos();
// 返回节点类型
return isNodeKind(kind) || kind === SyntaxKind.Unknown ? new NodeConstructor(kind, p, p) :
kind === SyntaxKind.Identifier ? new IdentifierConstructor(kind, p, p) :
new TokenConstructor(kind, p, p);
}
parseExpected
function parseExpected(kind: SyntaxKind, diagnosticMessage?: DiagnosticMessage, shouldAdvance = true): boolean {
// 检查当前token是否与当前传入的kind是否一致
if (token() === kind) {
if (shouldAdvance) {
nextToken();
}
return true;
}
// 如token与kind不一致,则根据是否传入diagnosticMessage(诊断信息),回传错误
if (diagnosticMessage) {
parseErrorAtCurrentToken(diagnosticMessage);
}
else {
parseErrorAtCurrentToken(Diagnostics._0_expected, tokenToString(kind));
}
return false;
}
finishNode
function finishNode<T extends Node>(node: T, end?: number): T {
// 获取结束位置
node.end = end === undefined ? scanner.getStartPos() : end;
// 添加标记
if (contextFlags) {
node.flags |= contextFlags;
}
//判断是否出现错误,若出现错误就不会标记任何后续节点。
if (parseErrorBeforeNextFinishedNode) {
parseErrorBeforeNextFinishedNode = false;
node.flags |= NodeFlags.ThisNodeHasError;
}
return node;
}
至此, AST构建完成。
未完待续。。。
