

1. 背景 —— 公司物联网项目
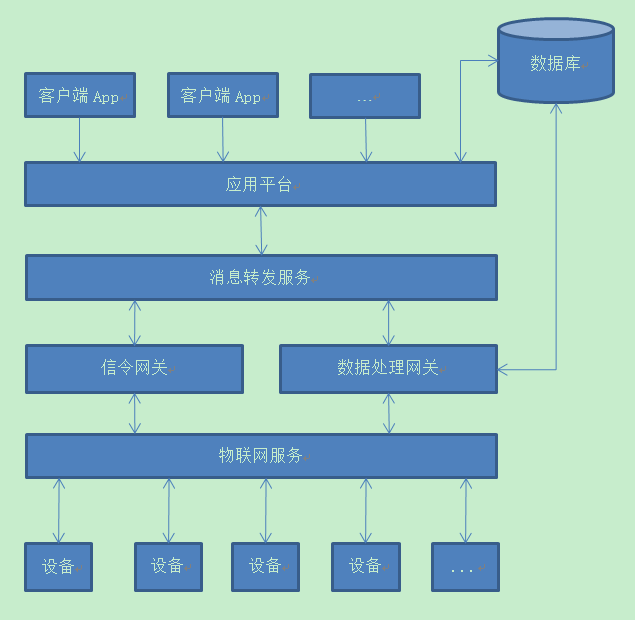
海量设备通过物联网服务接入云端,设备每30s上报一次自身数据(以下称为动态数据)。 物联网服务将设备上报的数据转发给数据处理网关,由数据入库网关执行批量入库操作插入数据库。 项目大致技术架构如下图:
2. 问题
接入的设备数量较大时,上报的动态数据数据量过大,导致单表查询过慢。
假设有1万台设备,每台设备每30秒上报一次动态数据,那每分钟就会产生2万条数据,每天会产生2880万条数据,一年将会产生100亿条以上的数据。
这么大的数据量如果进行单表查询数据库分析等操作延迟是完全无法接受的,故需要寻找一种解决方案。
3. 技术背景
3.1 分表
这里的分表指的是根据设备的序列号将一定数量的设备拆分存储在不同的表中,减少单表的数据量级。
3.2 分区
MySql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面(可以通过my.cnf中的datadir来查看)。
一张表主要对应着三个文件,一个是frm存放表结构,一个是myd存放表数据,一个是myi存表索引。如果一张表的数据量太大,mydmyi就会变的很大,查找数据就会变的很慢。
MySql的分区功能,在物理上将这一张表对应的三个文件,分割成许多个小块,这样查找一条数据时,就不用全部查找了,只要知道这条数据在哪一块,然后在那一块找就行了,这样就可以很大的提高数据查询的效率。
MySql5.1及以上版本支持分区功能。 MySql的分区方法主要有:
3.2.1 range分区:
range分区意思就是以某个字段为基准的连续分区,比如id小于3的1个分区,id小于6的一个分区,id小于100的一个分区。
3.2.2 list分区:
list分区就是以某个字段为基准,该字段从属于一个列表范围内的分区,比如id为1,3,5,7的一个分区,2,4,6,8的一个分区。
3.2.3 hash分区:
hash分区用于确保数据在预先设定数目的分区中平均分布,比如预先设置分区数量为3个,则所有数据都会被平均分布在3个分区内。
3.2.4 key分区:
按照KEY进行分区类似于按照HASH分区,除了HASH分区使用的用户定义的表达式,而KEY分区的 哈希函数是由MySQL 服务器提供。
3.2.5 子分区:
子分区是分区表中每个分区的再次分割,子分区既可以使用HASH希分区,也可以使用KEY分区。这也被称为复合分区(composite partitioning)。 子分区需遵循以下规则:
- 如果一个分区中创建了子分区,其他分区也要有子分区
- 如果创建了了分区,每个分区中的子分区数必有相同
- 同一分区内的子分区,名字不相同,不同分区内的子分区名子可以相同(5.1.50不适用)
4. 解决方案
4.1 分表设计
设计为每1000个设备一张表,表名为t_data_序号。
假设有1万台设备,则根据设备序列号将数据分散存储在t_data_1 ~ t_data_10 十张表中。
同时增加一张设备-动态数据关系表(表名t_device_table_map)来存储设备和动态数据表的关系,以便对设备数据做增删改查操作时能找到它对应的表,t_device_table_map表的结构如下:

数据处理启动时载入t_device_table_map表数据到自己的内存中,然后在将设备上报的数据入库前从自身内存读取该设备属于哪个动态数据表,再组装Sql执行入库操作。
4.2 分区设计
由于设备的数据是持续性上报的,所以考虑使用Range分区。
分区设计为以数据采集时间为基础,每周一个分区,每张表预设10年的分区。 按每个设备每30秒上报一条数据计算,每个分区大约有 10002460*2 = 2880000条数据。
建表语句如下:
CREATE TABLE `t_data_1` (
`i_id` bigint(20) NOT NULL AUTO_INCREMENT,
`i_status` bit(1) DEFAULT NULL,
`c_device_sequence` varchar(32) DEFAULT NULL COMMENT '设备序列号',
`t_collect_time` datetime NOT NULL DEFAULT '0000-00-00 00:00:00' COMMENT '数据采集时间',
...
PRIMARY KEY (`i_id`,`t_collect_time`),
KEY `index_c_device_sequence` (`c_device_sequence`,`t_collect_time`) USING BTREE
) ENGINE=MyISAM AUTO_INCREMENT=398404 DEFAULT CHARSET=utf8
/*!50500 PARTITION BY RANGE COLUMNS(t_collect_time)
(PARTITION p20171224 VALUES LESS THAN ('2017-12-24 00:00:00') ENGINE = MyISAM,
PARTITION p20171231 VALUES LESS THAN ('2017-12-31 00:00:00') ENGINE = MyISAM,
PARTITION p20180107 VALUES LESS THAN ('2018-01-07 00:00:00') ENGINE = MyISAM,
...
PARTITION p20271212 VALUES LESS THAN ('2027-12-12 00:00:00') ENGINE = MyISAM,
PARTITION p20271219 VALUES LESS THAN ('2027-12-19 00:00:00') ENGINE = MyISAM) */;
/*!40101 SET character_set_client = @saved_cs_client */;
5. 测试
以120万条数据测试,分表(10张)分区查询时间为0.1秒左右,见下图:
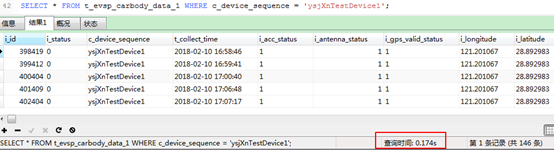
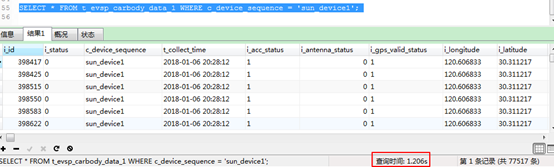
分表分区带来的性能提升是很明显的。
6. 思考
分区的数量是不是越多越好呢?肯定不是的。
因为MySQL在执行查询操作的时候首先要去检索查询范围在哪些分区内,分区太多,这部分的操作耗时就增加了。此外分区过多,可能会导致内存占用升高的问题。
怎么样分区,分多少个区才最合适,还需要长期的观察和大量数据的实验。
