

本节我们将全面了解一下 LevelDB 的各种特性。LevelDB 的开发语言是 C++,考虑到会使用 C++ 语言的同学不是很多,在本节我们将使用 Java 语言来描述 LevelDB 的特性。其它语言栈的同学也不必担心,因为不同语言操纵 LevelDB 的接口 API 都是一样的,使用起来大同小异。
打开和关闭
LevelDB 的数据存储在一个特定的目录中,里面有很多数据文件、日志文件等。使用 LevelDB API 来打开这个目录,就得到了 db 的引用。后续我们就使用这个 db 引用来执行读写操作。下面的代码是 Java 语言描述的伪代码。
class LevelDB {
public static LevelDB open(String dbDir, Options options);
void close(); // 关闭数据库
}
打开数据库有很多选项可以配置,比如设置块缓存大小、压缩等
基础 API
LevelDB 用起来就像 HashMap,但是比 HashMap 要稍微弱一些,因为 put 方法不能返回旧值,delete 操作也不知道对应的 key 是否真的存在。
class LevelDB {
byte[] get(byte[] key)
void put(byte[] key, byte[] value)
void delete(byte[] key)
...
}
原子批处理
对于多个连续的写操作如果因为宕机有可能导致这多个连续的写操作只完成了一部分。为此 LevelDB 提供了批处理功能,批处理操作就好比事务,LevelDB 确保这一些列写操作的原子性执行,要么全部生效要么完全不生效。
class WriteBatch {
void put(byte[] key, byte[] value);
void delete(byte[] key);
}
class LevelDB {
...
void write(WriteBatch wb);
}
日志文件
当我们调用 LevelDB 的 put 方法往库里写数据时,它会先将数据记录到内存中,延后再通过某种特殊的策略持久化到磁盘。这就存在一个问题,如果突发宕机,这些来不及写到磁盘的数据就丢失了。所以 LevelDB 也采用了和 Redis AOF 日志类似的策略,先讲修改操作的日志写到磁盘文件中,再进行实际的写操作流程处理。
如此即使宕机发生了,数据库启动时还可以通过日志文件来恢复。
安全写(同步写)
了解 Redis 的同学都知道它的 AOF 写策略有多种配置,取决于日志文件同步磁盘的频率。频率越高,遇到宕机时丢失的数据就越少。操作系统要将内核中文件的脏数据同步到磁盘需要进行磁盘 IO,这会影响访问性能,所以通常都不会同步的太频繁。
LevelDB 也是类似的,如果使用前面的非安全写,虽然 API 调用成功了,但是遇到宕机问题,有可能对应的操作日志会丢失。所以它提供了安全写操作,代价就是性能会变差。
class LevelDB {
...
void putSync(byte[] key, byte[] value);
void deleteSync(byte[] key);
void writeSync(WriteBatch wb);
}
在安全和性能之间往往需要折中,所以通常我们会定时若干毫秒或者每隔若干写操作使用一次同步写。这样可以在兼顾写性能的同时尽量少丢失数据。
并发
LevelDB 的磁盘文件会放在一个文件目录中,里面有很多相关的数据和日志文件。它不支持多进程同时打开这个目录来使用 LevelDB API 进行读写访问。但是对于同一个进程 LevelDB API 是支持多线程安全读写的。LevelDB 内部会使用特殊的锁来控制并发操作。
遍历
LevelDB 中的 Key 都是有序的,按照字典序从小到大整齐排列。LevelDB 提供了遍历 API 可以逐个顺序访问所有的键值对,可以指定从中间开始遍历。
class LevelDB {
...
Iterator<KV> scan(byte[] startKey, byte[] endKey, int limit);
}
快照隔离
LevelDB 支持多线程并发读写,这意味着连续的两个同样 key 的读操作读到的数据可能不一样,因为两个读操作中间数据可能被其它线程修改了。这在数据库理论中称为「重复读」。LevelDB 提供了快照隔离机制,在同一个快照范围内保证连续的读写操作不受其它线程修改操作的影响。
class Snapshot {
byte[] get(byte[] key)
void put(byte[] key, byte[] value)
void delete(byte[] key)
void write(WriteBatch wb);
...
void close(); // 关闭快照
}
class LevelDB {
...
Snapshot getSnapshot();
}
快照虽然很神奇,但是实际上它的原理非常简单,这个我们后文再深入讲解。
自定义 Key 比较器
LevelDB 的 key 默认使用字典序,不过它也提供了自定义排序规则。你可以自定义一个排序函数注册进去,比如按数字排序。必须尽可能确保排序规则在整个数据库生命周期内保持不变,因为排序会影响到磁盘键值对的存储顺序,磁盘存储顺序是无法动态改变的。
Options options = new Options();
options.comparator = new CustomComparator();
db = LevelDB.open("/tmp/ldb", options);
自定义比较器很危险,谨慎使用。比较算法设置不当,会严重影响到存储效率。如果确实必须要改变排序规则,那就需要提前规划,这里会有一个特别的小技巧,理解它需要了解磁盘存储的细节,所以我们后续再仔细探讨。
数据块
LevelDB 的磁盘数据是以数据库块的形式存储的,默认的块大小是 4k。适当提升块大小将有益于批量大规模遍历操作的效率,如果随机读比较频繁,这时候块小点性能又会稍好,这就要求我们自己去折中选择。
Options options = new Options();
options.blockSize = 8092;
db = LevelDB.open("/tmp/ldb", options);
块不宜过小低于 1k,也不宜过大设置成了好几 M,这样过激的设置并不会给性能带来多大的提升,反而会大幅增加数据库在不同的读写场合的性能波动。我们要选择中庸之道,在默认块大小周边浮动。块大小一经初始化就不可再次更改。
压缩
LevelDB 的磁盘存储默认是开启压缩的,是业界常用的 Snappy 算法,压缩效率非常高,所以无需担心性能损耗问题。如果你不想使用压缩,也可以动态关闭。关闭压缩开关通常不会带来明显的性能提升,所以我们尽可能不要去动它。
Options options = new Options();
options.compression = CompressionType.kSnappyCompression;
// options.compression = CompressionType.kNoCompression; // 关闭压缩
db = LevelDB.open("/tmp/ldb", options);
块缓存
LevelDB 的内存中存储了一笔最近读写的热数据,如果请求的数据在热数据中查不到就需要去磁盘文件中去查找,效率就会大幅降低。LevelDB 为了降低磁盘文件的搜寻次数,增加了块缓存,缓存了近期频繁使用的数据块解压缩之后的内容。
Options options = new Options();
options.blockCache = LevelDB.NewLRUCache(100 * 1024 * 1024); // 100M
db = LevelDB.open("/tmp/ldb", options);
默认块缓存不开启,打开数据库时可以手动设置选项。块缓存会占据一部分内存,不过这通常不需要设置太大,100M 左右就差不多了,再大一些效率提升的也不明显了。
还需要注意遍历操作对缓存的影响,为了避免遍历操作将很多冷门数据刷到块缓存中,可以在遍历的时候设置一个选项 fill_cache,它用来控制磁盘遍历的数据块是否需要同步到缓存。
布隆过滤器
内存读 miss 导致磁盘搜寻是一个比较耗时的操作,LevelDB 为了进一步减少磁盘读的次数,在每个磁盘文件上又加了一层布隆过滤器,它需要消耗一定的磁盘空间,但是在效果上可以直接将磁盘读次数大幅减少。布隆过滤器的数据存储在磁盘文件中数据块的后面。
LevelDB 的磁盘文件是分层存储的,它会先去 Level 0 查找,如果找不到继续去 Level 1 去找,一直递归到最底层。所以如果你去找一个不存在的 key,就需要很多次磁盘文件读操作,会非常耗费时间。而布隆过滤器可以帮你省去95%以上的磁盘文件搜寻的时间。
布隆过滤器类似于一个内存 Set 结构,它里面存储了指定磁盘文件一定范围内所有 Key 的指纹信息。当它发现某个 key 的指纹在 Set 集合里找不到,它就可以断定这个 key 肯定不存在。
如果对应的指纹可以在集合里找到,这并不能确定它就一定存在。因为不同的 Key 可能会生成同样的指纹,这就是布隆过滤器的误判率。误判率越低需要的 Key 指纹信息越多,对应消耗的内存空间也就越大。
如果布隆过滤器能准确知道某个 Key 是否存在,那就不存在误判了,这时候也就不会存在白白浪费的磁盘读操作。这样的极限形式的布隆过滤器就是 HashSet —— 内存里存储了所有的 Key,当然内存空间自然是无法接受的。
Options options = new Options();
// 每个 key 的指纹大小是 10bit
options.filterPolicy = LevelDB.NewBloomFilterPolicy(10);
db = LevelDB.open("/tmp/ldb", options);
在使用布隆过滤器时,我们需要在内存消耗和性能之间做一个折中选择。如果你想深入理解布隆过滤器的原理,可以去看《Redis 深度历险》,里面有一个单独的章节专门讲解布隆过滤器的内部原理。
默认布隆过滤器没有打开,需要在打开数据库的时候设置 filter_policy 参数才可以生效。布隆过滤器是减少磁盘读操作的最后一层堡垒。布隆过滤器内部的位图数据会存储在磁盘文件中,但是使用是会缓存在内存里面。
数据校验
LevelDB 有严格的数据校验机制,它将校验的单位精确到了 4K 字节的数据块。校验和会浪费一点存储空间和计算时间,但是在遇到数据块损坏时可以较为精确地恢复健康的数据。
class LevelDB {
...
public void static repairDB(String dbDir, Options options);
}
打开数据库时默认没有开启强制校验选项,如果开启了,在遇到校验错误时就会报错。如果数据真的出现了问题,LevelDB 还提供了修复数据的方法 repairDB() 可以帮我们恢复尽可能多的数据。
小结
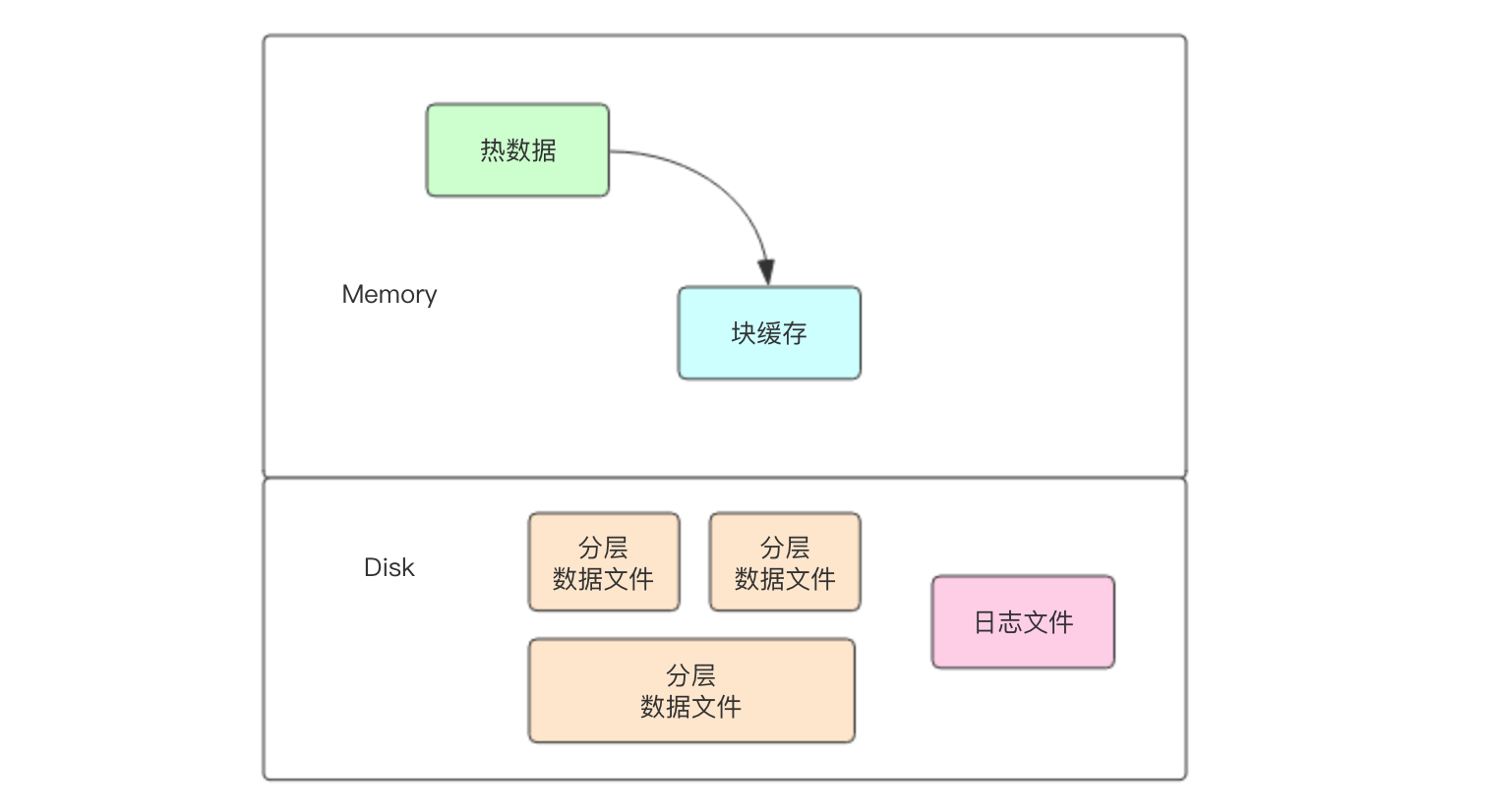
经过了这一节的学习,同学们应该可以在脑海中形成下面这样一张概念图。图中的「热数据」是指最近被修改的键值对,这里面的键值对读取速度是最为快速的。如果热数据中读取不到,就会去块缓存中读取。如果还读不到,就分两种情况,一种是真的不存在,另一个种是存在于磁盘上。如果存在于磁盘上,经过有限层次读取就读取到了,通常越冷的数据越在底层。如果真的不存在就要经过布隆过滤器来大幅减少磁盘搜寻 IO,布隆过滤器的数据和键值对数据共同放在分层的数据文件中。
下一节我们使用真实的代码来亲自实践一下 LevelDB。

