

APP开发中,卡顿绝对优化的大头,Google为了帮助开发者更好的定位问题,提供了不少工具,如Systrace、GPU呈现模式分析工具、Android Studio自带的CPU Profiler等,主要是辅助定位哪段代码、哪块逻辑比较耗时,影响UI渲染,导致了卡顿。拿Profile GPU Rendering工具而言,它用一种很直观的方式呈现可能超时的节点,该工具及其原理也是本文的重点:
CPU Profiler也会提供相似的图表,本文主要围绕着GPU呈现模式分析工具展开,简析各个阶段耗时统计的原理,同时总结下在使用及分析过程中也遇到的一些问题,可能算工具自身的BUG,这给分析带来了不少困惑。比如如下几点:
- GPU呈现模式分析工具跟Google官方文档上似乎对应不起来(各个颜色代表的阶段)
- CPU Profiler的函数调用似乎有些调用被合并了,并非独立的调用栈(影响分析哪块耗时)
- Skip Frame掉帧可能跟我们预想的不同,而且掉帧的统计也可能不准(主要是Vsync的延时部分,有些耗时操作导致卡顿了,但是可能没有统计出掉帧)
GPU呈现模式分析工具简介
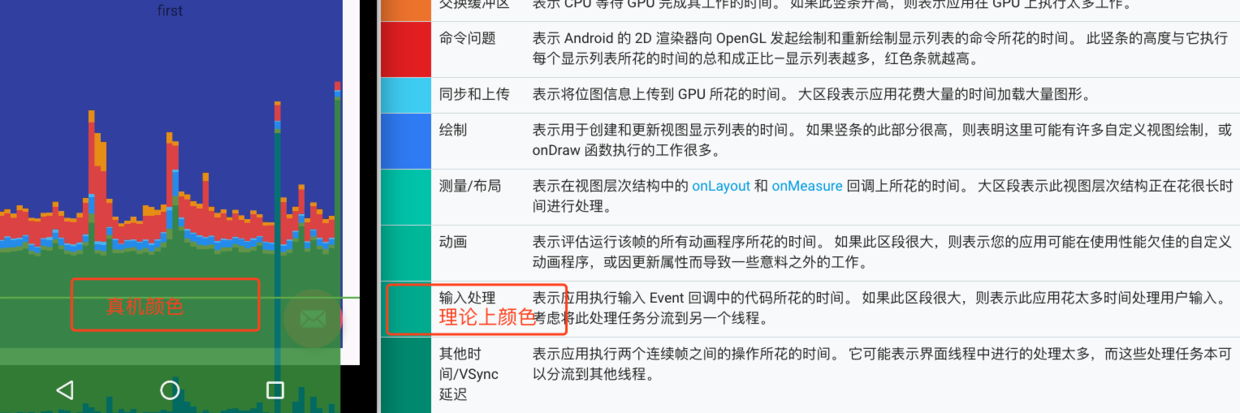
Profile GPU Rendering工具的使用很简单,就是直观上看一帧的耗时有多长,绿线是16ms的阈值,超过了,可能会导致掉帧,这个跟VSYNC垂直同步信号有关系,当然,这个图表并不是绝对严谨的(后文会说原因)。每个颜色的方块代表不同的处理阶段,先看下官方文档给的映射表:

想要完全理解各个阶段,要对硬件加速及GPU渲染有一定的了解,不过,有一点,必须先记心里:虽名为 Profile GPU Rendering,但图标中所有阶段都发生在CPU中,不是GPU 。最终CPU将命令提交到 GPU 后触发GPU异步渲染屏幕,之后CPU会处理下一帧,而GPU并行处理渲染,两者硬件上算是并行。 不过,有些时候,GPU可能过于繁忙,不能跟上CPU的步伐,这个时候,CPU必须等待,也就是最终的swapbuffer部分,主要是最后的红色及黄色部分(同步上传的部分不会有问题,个人认为是因为在Android GPU与CPU是共享内存区域的),在等待时,将看到橙色条和红色条中出现峰值,且命令提交将被阻止,直到 GPU 命令队列腾出更多空间。
在使用Profile GPU Rendering工具时,我面临第一个问题是:官方文档的使用指导好像不太对。
Profile GPU Rendering工具颜色问题
真正使用该工具的时候,条形图的颜色跟文档好像对不上,为了测试,这里先用一个小段代码模拟场景,鉴别出各个阶段,最后再分析源码。从下往上,先忽略VSYNC部分,先看输入事件,在一个自定义布局中,为触摸事件添加延时,并触发重绘。
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
}
mTextView.setText("" + System.currentTimeMillis());
requestLayout();
super.dispatchTouchEvent(ev);
return true;
}
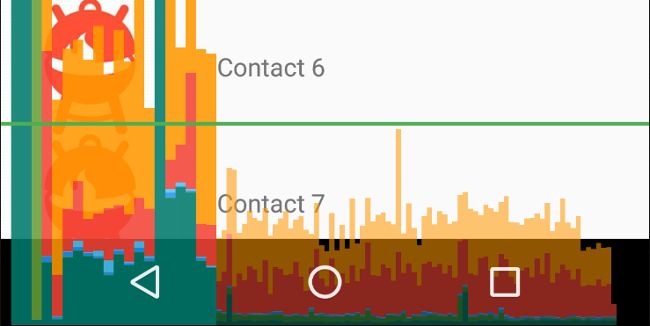
这个时候看到的超时部分主要是输入事件引起的,进而确定下输入事件的颜色:
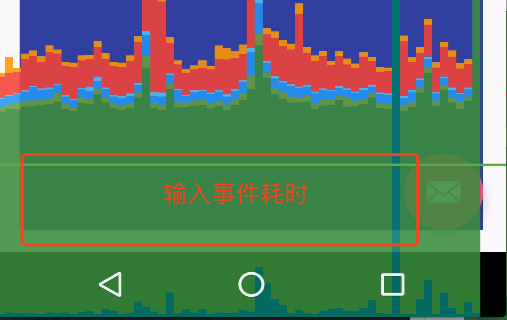
输入事件加个20ms延后,上图红色方块部分正好映射到输入事件耗时,这里就能看到,输入事件的颜色跟官方文档的颜色对不上,如下图
同样,测量布局的耗时也跟文档对不上。为布局测量加个耗时,即可验证:
@Override
protected void onMeasure(int widthMeasureSpec, int heightMeasureSpec) {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
}
super.onMeasure(widthMeasureSpec, heightMeasureSpec);
}
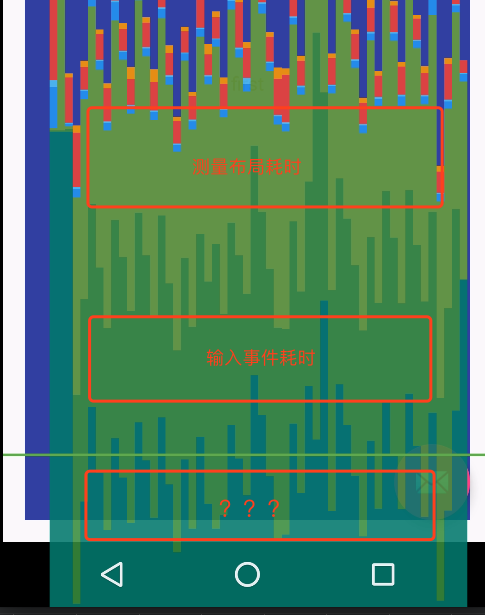
可以看到,上图中测量布局的耗时跟官方文档的颜色也对不上。除此之外,似乎多出了第三部分耗时,这部分其实是VSYNC同步耗时,这部分耗时怎么来的,真的存在耗时吗?官方解释似乎是连个连续帧之间的耗时,但是后面分析会发现,可能这个解释同源码对应不起来。
Miscellaneous
In addition to the time it takes the rendering system to perform its work, there’s an additional set of work that occurs on the main thread and has nothing to do with rendering. Time that this work consumes is reported as misc time. Misc time generally represents work that might be occurring on the UI thread between two consecutive frames of rendering.
其次,为什么几乎每个条形图都有一个测量布局耗时跟输入事件耗时呢?为什么是一一对应,而不是有多个?测量布局是在Touch事件之后立即执行呢,还是等待下一个VSYNC信号到来再执行呢?这部主要牵扯到的内容:VSYNC垂直同步信号、ViewRootImpl、Choreographer、Touch事件处理机制,后面会逐步说明,先来看一下以上三个事件的耗时是怎么统计的。
Miscellaneous--VSYNC延时
Profile GPU Rendering工具统计的入口在Choreographer类中,时机是VSYNC信号Message被执行,注意这里是信号消息被执行,而不是信号到来,因为信号到来并不意味着立即被执行,因为VSYNC信号的申请是异步的,信号申请后线程继续执行当前消息,SurfaceFlinger在下一次分发VSYNC的时候直接往APP UI线程的MessageQueue插入一条VSYNC到来的消息,而消息被插入后,并不会立即被执行,而是要等待之前的消息执行完毕后才会执行,而VSYNC延时其实就是VSYNC消息到来到被执行之间的延时。
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
...
long intendedFrameTimeNanos = frameTimeNanos;
<!--关键点1 设置vsync开始,并记录起始时间 -->
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
try {
// 开始处理输入事件,并记录起始时间
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
// 开始处理动画,并记录起始时间
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
// 开始处理测量布局,并记录起始时间
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
} finally {
}
这里的 VSYNC延时其实是 mFrameInfo.markInputHandlingStart - frameTimeNanos,而frameTimeNanos是VSYNC信号到达的时间戳,如下
private final class FrameDisplayEventReceiver extends DisplayEventReceiver
implements Runnable {
private boolean mHavePendingVsync;
private long mTimestampNanos;
private int mFrame;
public FrameDisplayEventReceiver(Looper looper) {
super(looper);
}
@Override
public void onVsync(long timestampNanos, int builtInDisplayId, int frame) {
...
<!--存下时间戳,并往UI的MessageQueue发送一个消息-->
mTimestampNanos = timestampNanos;
mFrame = frame;
Message msg = Message.obtain(mHandler, this);
msg.setAsynchronous(true);
mHandler.sendMessageAtTime(msg, timestampNanos / TimeUtils.NANOS_PER_MS);
}
@Override
public void run() {
<!--将之前的时间戳作为参数传递给doFrame-->
mHavePendingVsync = false;
doFrame(mTimestampNanos, mFrame);
}
}
onVsync是VSYNC信号到达的时候在Native层回调Java层的方法,其实是MessegeQueue的native消息队列那一套,并且VSYNC要一个执行完,下一个才会生效,否则下一个VSYNC只能在队列中等待,所以之前说的???第三部分延时就是VSYNC延时,但是这部分不应该被算到渲染中去,另外根据写法,VSYNC延时可能也有很大出入。看doFrame中有一部分是统计掉帧的,个人理解也许这部分统计并不是特别靠谱,下面看下掉帧的部分。
掉帧Skiped Frame同Vsync延时耗时的关系
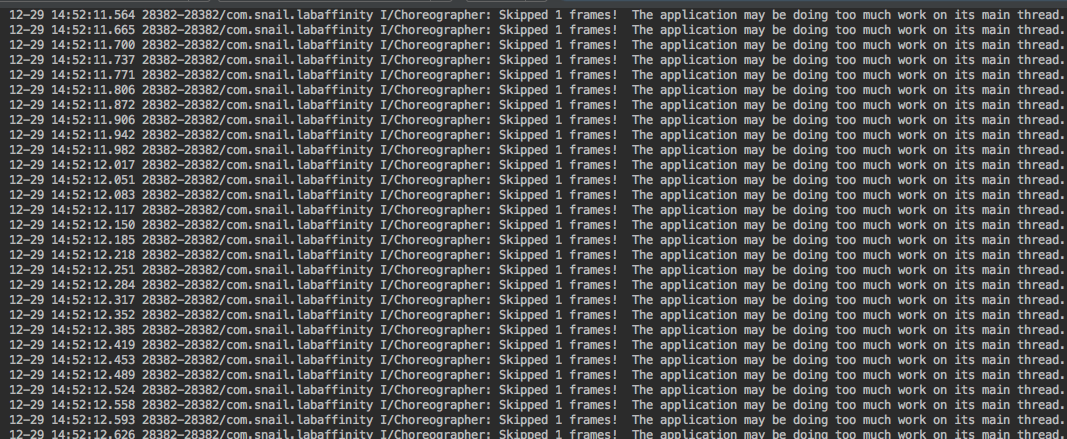
有些APM检测工具通过将Choreographer的SKIPPED_FRAME_WARNING_LIMIT设置为1,来达到掉帧检测的目的,即如下设置:
try {
Field field = Choreographer.class.getDeclaredField("SKIPPED_FRAME_WARNING_LIMIT");
field.setAccessible(true);
field.set(Choreographer.class, 0);
} catch (Throwable e) {
}
如果出现卡顿,在log日志中就能看到如下信息
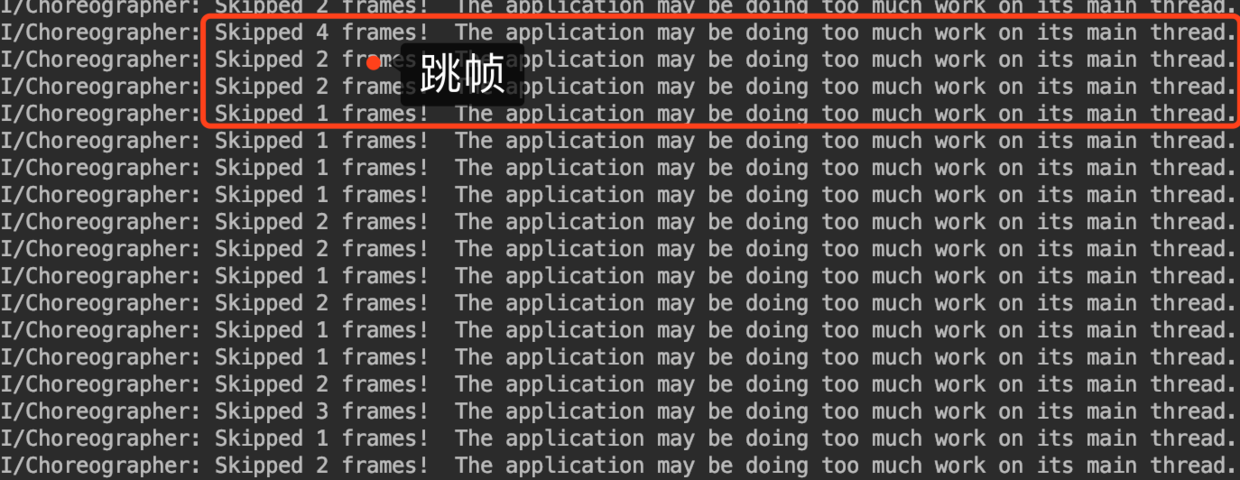
感觉这里并不是太严谨,看源码如下:
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
return; // no work to do
}
long intendedFrameTimeNanos = frameTimeNanos;
<!--skip frame关键点 -->
startNanos = System.nanoTime();
final long jitterNanos = startNanos - frameTimeNanos;
if (jitterNanos >= mFrameIntervalNanos) {
final long skippedFrames = jitterNanos / mFrameIntervalNanos;
if (skippedFrames >= SKIPPED_FRAME_WARNING_LIMIT) {
Log.i(TAG, "Skipped " + skippedFrames + " frames! "
+ "The application may be doing too much work on its main thread.");
}
...
}
可以看到跳帧检测的算法就是:Vsync信号延时/16ms,有多少个,就算跳几帧。Vsync信号到了后,重绘并不一定会立刻执行,因为UI线程可能被阻塞再某个地方,比如在Touch事件中,触发了重绘,之后继续执行了一个耗时操作,这个时候,必然会导致Vsync信号被延时执行,跳帧日志就会被打印,如下
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
super.dispatchTouchEvent(ev);
scrollTo(0,new Random().nextInt(15));
try {
Thread.sleep(40);
} catch (InterruptedException e) {
}
return true;
}
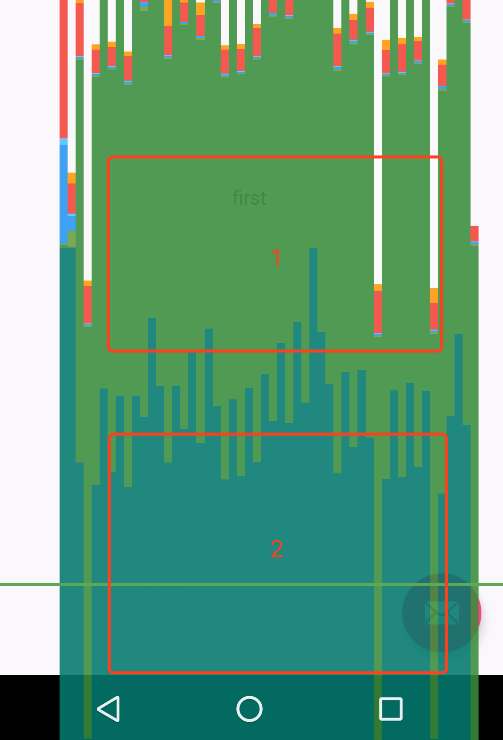
可以看到,颜色2的部分就是Vsync信信号延时,这个时候会有掉帧日志。
但是如果将触发UI重绘的消息放到延时操作后面呢?毫无疑问,卡顿依然有,但这时会发生一个有趣的现象,跳帧没了,系统认为没有帧丢失,代码如下:
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
super.dispatchTouchEvent(ev);
try {
Thread.sleep(40);
} catch (InterruptedException e) {
}
scrollTo(0,new Random().nextInt(15));
return true;
}
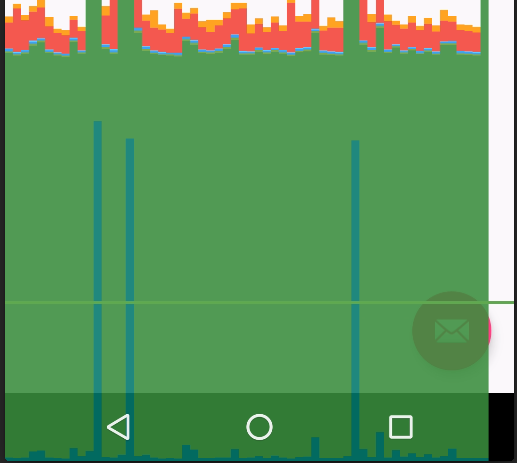
可以看到,图中几乎没有Vsync信信号延时,这是为什么?因为下一个VSYNC信号的申请是由scrollTo触发,触发后并没有什么延时操作,直到VSYNC信号到来后,立即执行doFrame,这个之间的延时很少,系统就认为没有掉帧,但是其实卡顿依旧。因为整体来看,一段时间内的帧率是相同的,整体示意如下:
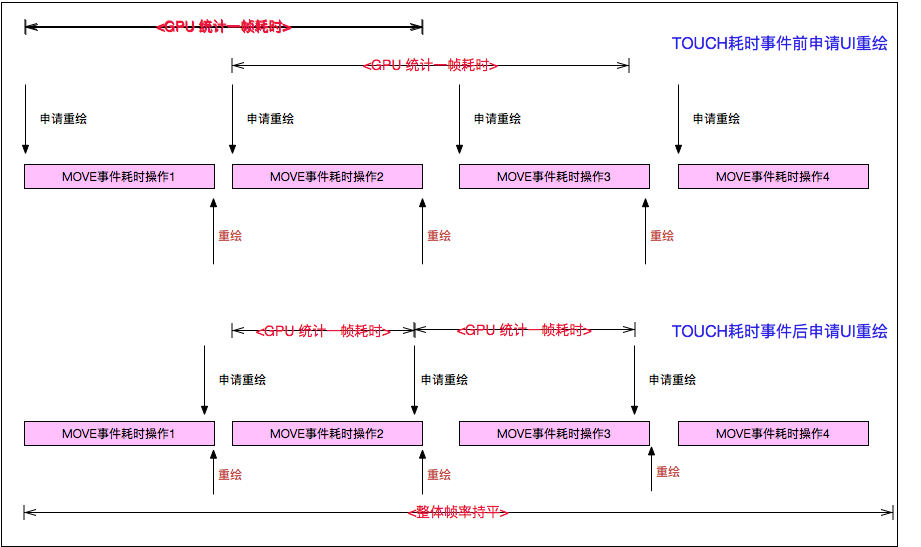
以上就是scrollTo在延时前后的区别,两种其实都是掉帧的,但是日志统计的跳帧却出现了问题,而且,每一帧真正的耗也并不是我们看到的样子,个人觉得这可能算是工具的一个BUG,不能很精确的反应卡顿问题,依靠这个做FPS侦测,应该也都有问题。比如滚动时候,处理耗时操作后,再更新UI,这种方式是检测不出跳帧的,当然不排除有其他更好的方案。下面看一下Input时间耗时,之前,针对Touch事件的耗时都是直接用了,并未分析为何一帧里面会有且只有一个Touch事件耗时?是否所有的Touch事件都被统计了呢?Touch事件如何影响GPU 统计工具呢?
输入事件耗时分析
输入事件处理机制:InputManagerService捕获用户输入,通过Socket将事件传递给APP端(往UI线程的消息队列里插入消息)。对于不同的触摸事件有不同的处理机制:对于Down、UP事件,APP端需要立即处理,对于Move事件,要结合重绘事件一并处理,其实就是要等到下一次VSYNC到来,分批处理。可以认为只有MOVE事件才被GPU柱状图统计到里面,UP、DOWN事件被立即执行,不会等待VSYNC跟UI重绘一起执行。。这里不妨先看一个各个阶段耗时统计的依据,GPU 呈现工具图表的绘制是在native层完成的,其各个阶段统计示意如下:
FrameInfoVisualizer.cpp
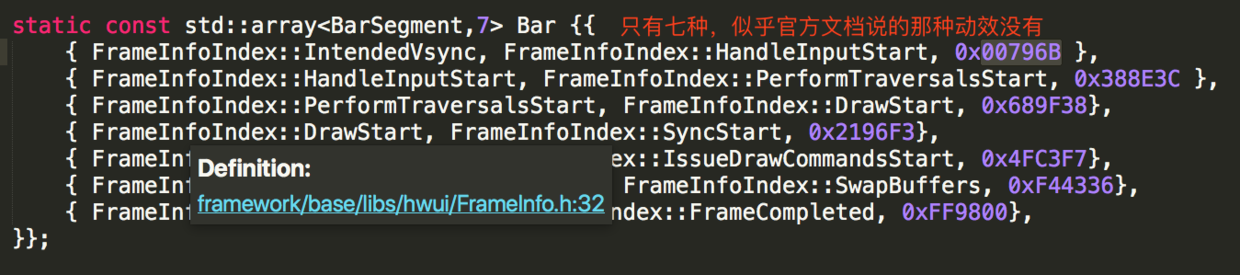
前文分析的VSYNC延时其实就是 FrameInfoIndex::HandleInputStart -FrameInfoIndex::IntendedVsync 颜色是0x00796B,输入事件耗时其实就是FrameInfoIndex::PerformTraversalsStart -FrameInfoIndex::HandleInputStart,不过这里只有7种,跟文档的8中对应不上。在doFrame可以得到验证:
void doFrame(long frameTimeNanos, int frame) {
final long startNanos;
synchronized (mLock) {
if (!mFrameScheduled) {
...
// 设置vsync开始,并记录起始时间
<!--关键点1 -->
mFrameInfo.setVsync(intendedFrameTimeNanos, frameTimeNanos);
mFrameScheduled = false;
mLastFrameTimeNanos = frameTimeNanos;
}
try {
// 开始处理输入事件,并记录起始时间
mFrameInfo.markInputHandlingStart();
doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos);
// 开始处理动画,并记录起始时间
mFrameInfo.markAnimationsStart();
doCallbacks(Choreographer.CALLBACK_ANIMATION, frameTimeNanos);
// 开始处理测量布局,并记录起始时间
mFrameInfo.markPerformTraversalsStart();
doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos);
} finally {
}
如上代码很简单,但是在利用CPU Profiler看函数调用栈的时候,却发现很多问题。为Touch事件处理加入延时后,CPU Profiler看到的调用栈如下:
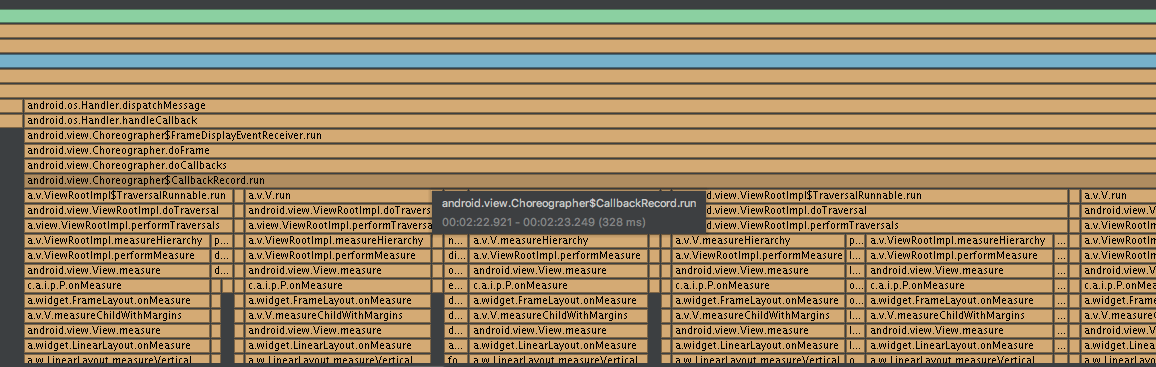
这个栈是怎么回事?不是说好的,一次VSYNC信号调用一次doFrame,而一次doFrame会依次执行不同类型的CallBack,但是看以上的调用栈,怎么是穿插着来啊?这就尴尬了,莫非是BUG,事实证明,确实真可能是CPU Profiler的BUG。 证据就是doFrame的调用次数跟CPU Profiler 中统计的次数的压根对应不起来,doFrame的次数明显要很多。
也就是说CPU Profiler应该将一些类似的函数调用给整合分组了,所以看起来好像一个Vsync执行了一次doFrame,但是却执行了很多CallBack,实际上,默认情况下,每种类型的CallBack在一次VSYNC期间,一般最多执行一次。**垂直同步信号机制下,在下一个垂直同步信号到来之前,Android系统最多只能处理一个MOVE的Patch、一个绘制请求、一次动画更新。**先看看Touch时间处理机制,上文的dispatchTouchEvent如何被执行的呢?
@Override
public boolean dispatchTouchEvent(MotionEvent ev) {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
}
mTextView.setText("" + System.currentTimeMillis());
requestLayout();
super.dispatchTouchEvent(ev);
return true;
}
InputManagerService收到Touch事件后,通过Socket传递给APP端,APP端的UI Loop会将事件读取出来,在native预处理下,将事件发送给Java层,
public abstract class InputEventReceiver {
...
public final boolean consumeBatchedInputEvents(long frameTimeNanos) {
if (mReceiverPtr == 0) {
Log.w(TAG, "Attempted to consume batched input events but the input event "
+ "receiver has already been disposed.");
} else {
return nativeConsumeBatchedInputEvents(mReceiverPtr, frameTimeNanos);
}
return false;
}
// Called from native code.
@SuppressWarnings("unused")
private void dispatchInputEvent(int seq, InputEvent event) {
mSeqMap.put(event.getSequenceNumber(), seq);
onInputEvent(event);
}
// NativeInputEventReceiver
// Called from native code.
@SuppressWarnings("unused")
private void dispatchBatchedInputEventPending() {
onBatchedInputEventPending();
}
...
}
如果是DOWN、UP事件,调用dispatchInputEvent,如果是MOVE事件,则被封装成Batch,调用dispatchBatchedInputEventPending,对于DOWN、UP事件会调用子类的enqueueInputEvent立即执行
final class WindowInputEventReceiver extends InputEventReceiver {
public WindowInputEventReceiver(InputChannel inputChannel, Looper looper) {
super(inputChannel, looper);
}
@Override
public void onInputEvent(InputEvent event) {
<!--关键点 最后一个参数是true-->
enqueueInputEvent(event, this, 0, true);
}
void enqueueInputEvent(InputEvent event,
InputEventReceiver receiver, int flags, boolean processImmediately) {
adjustInputEventForCompatibility(event);
<!--获取输入事件-->
QueuedInputEvent q = obtainQueuedInputEvent(event, receiver, flags);
...
<!--是否立即执行-->
if (processImmediately) {
doProcessInputEvents();
} else {
scheduleProcessInputEvents();
}
}
对于DOWN UP事件会调用 doProcessInputEvents立即执行, 而对于dispatchBatchedInputEventPending则调用WindowInputEventReceiver的onBatchedInputEventPending延迟到下一个VSYNC执行:
final class WindowInputEventReceiver extends InputEventReceiver {
public WindowInputEventReceiver(InputChannel inputChannel, Looper looper) {
super(inputChannel, looper);
}
...
@Override
public void onBatchedInputEventPending() {
if (mUnbufferedInputDispatch) {
super.onBatchedInputEventPending();
} else {
scheduleConsumeBatchedInput();
}
}
mUnbufferedInputDispatch默认都是false,为了提高执行效率,发行版的源码该参数都是false,所以这里会执行scheduleConsumeBatchedInput:
void scheduleConsumeBatchedInput() {
<!--mConsumeBatchedInputScheduled保证了当前Touch事件被执行前,不会再有Batch事件被插入-->
if (!mConsumeBatchedInputScheduled) {
mConsumeBatchedInputScheduled = true;
<!--通过Choreographer暂存回调,同时请求VSYNC信号-->
mChoreographer.postCallback(Choreographer.CALLBACK_INPUT,
mConsumedBatchedInputRunnable, null);
}
}
scheduleConsumeBatchedInput中的逻辑保证了每次VSYNC间,最多只有一个Batch被处理。Choreographer.CALLBACK_INPUT类型的CallBack是输入事件耗时统计的对象,只有Batch类Touch事件(MOVE事件)会涉及到这个类型,所以个人理解GPU呈现工具统计的输入耗时只针对MOVE事件,直观上也比较好理解:**MOVE滚动或者滑动事件一般都是要伴随UI更新,这个持续的流程才是帧率关心的重点,如果不是持续更新,FPS(帧率)没有意义。**继续看Choreographer.postCallback函数
private void postCallbackDelayedInternal(int callbackType,
Object action, Object token, long delayMillis) {
synchronized (mLock) {
final long now = SystemClock.uptimeMillis();
final long dueTime = now + delayMillis;
<!--添加回调-->
mCallbackQueues[callbackType].addCallbackLocked(dueTime, action, token);
<!--ViewrootImpl过来的一般都是立即执行,直接申请Vsync信号-->
if (dueTime <= now) {
scheduleFrameLocked(now);
}
...
}
Choreographer为Touch事件添加一个CallBack,并加入到缓存队列中,同时异步申请VSYNC,等到信号到来后,才会处理该Touch事件的回调。VSYNC信号到来后,Choreographer最先执行doFrame中的doCallbacks(Choreographer.CALLBACK_INPUT, frameTimeNanos),该函数会调用ConsumeBatchedInputRunnable的run函数,最终调用doConsumeBatchedInput处理Batch事件:
void doConsumeBatchedInput(long frameTimeNanos) {
<!--标记事件被处理,新的事件才有机会被添加进来-->
if (mConsumeBatchedInputScheduled) {
mConsumeBatchedInputScheduled = false;
if (mInputEventReceiver != null) {
if (mInputEventReceiver.consumeBatchedInputEvents(frameTimeNanos)
&& frameTimeNanos != -1) {
...
}
}
<!--处理事件-->
doProcessInputEvents();
}
}
doProcessInputEvents会走事件分发机制最终回调到对应的 dispatchTouchEvent完成Touch事件的处理。这个有个很重要的点:如果在处理Batch事件的时候触发了UI重绘(非常常见),比如MOVE事件一般都伴随着列表滚动,那么这个重绘CallBack会立即被添加到Choreographer.CALLBACK_TRAVERSAL队列中,并在执行完当前Choreographer.CALLBACK_INPUT回调后,立刻执行,这就是为什么CPU Profiler中总能看到一个一个Touch事件后面跟着一个UI重绘事件。拿上文例子而言requestLayout()最终会调用ViewRootImpl的:
@Override
public void requestLayout() {
if (!mHandlingLayoutInLayoutRequest) {
checkThread();
mLayoutRequested = true;
scheduleTraversals();
}
}
从而调用scheduleTraversals,可以看到这里也用了一个标记mTraversalScheduled,保证一次VSYNC中最多一次重绘:
void scheduleTraversals() {
// 重复多次调用invalid requestLayout只会标记一次,等到下一次Vsync信号到,只会执行执行一次
if (!mTraversalScheduled) {
mTraversalScheduled = true;
<!--添加一个栅栏,阻止同步消息执行-->
mTraversalBarrier = mHandler.getLooper().getQueue().postSyncBarrier();
mChoreographer.postCallback(
Choreographer.CALLBACK_TRAVERSAL, mTraversalRunnable, null);
<!--=更新UI的时候,通常伴随MOVE事件,预先请求一次Vsync信号,不用真的等到消息到来再请求,提高吞吐率-->
// mUnbufferedInputDispatch =false 一般都是false 所以会执行scheduleConsumeBatchedInput,
if (!mUnbufferedInputDispatch) {
scheduleConsumeBatchedInput();
}
notifyRendererOfFramePending();
pokeDrawLockIfNeeded();
}
}
对于重绘事件而言,通过mChoreographer.postCallback直接添加一个CallBack,同时请求Vsync信号,一般而言scheduleTraversals中的scheduleConsumeBatchedInput请求VSYNC是无效,因为连续两次请求VSYNC的话,只有一次是有效的,scheduleConsumeBatchedInput只是为后续的Touch事件提前占个位置。刚开始执行Touch事件的时候,mCallbackQueues信息是这样的:
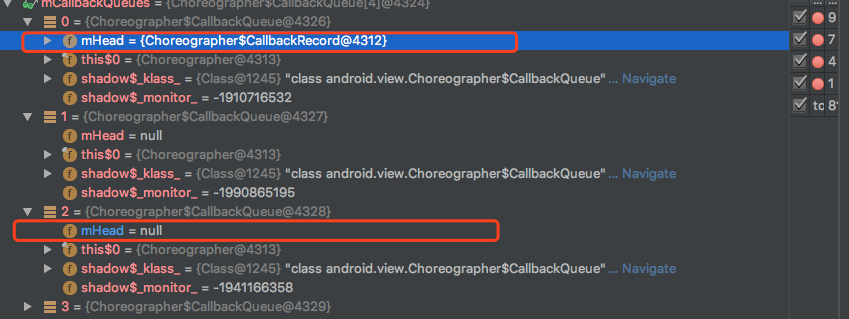
可以看到,开始并没有Choreographer.CALLBACK_TRAVERSAL类型的回调,在处理Touch事件的时候,触发了重绘,动态增加了Choreographer.CALLBACK_TRAVERSAL类CallBack,如下
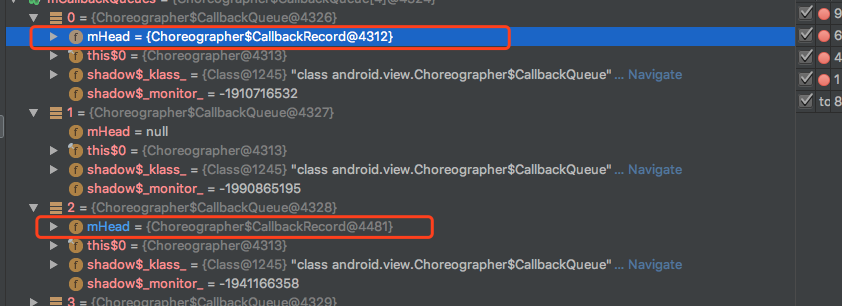
那么,在当前MOVE时间处理完毕后,doCallbacks(Choreographer.CALLBACK_TRAVERSAL, frameTimeNanos)会被执行,刚才被加入的重绘CallBack会立即执行,而不会等待到下一次Vsync信号的到来,这就是之前MOVE跟重绘一一对应,并且重绘总是在MOVE事件之后执行的原理,同时也看到Choreographer用了不少标记,保证一次VSYNC期间,最多有一个MOVE事件、重回时间被依次执行(先忽略动画)。以上两个是GPU玄学曲线中比较拧巴的地方,剩余的几个阶段其实就比较清晰了。
CALLBACK_ANIMATION类CallBack耗时 (似乎被算到Touch事件耗时中去了)
一般MOVE事件伴随Scroll,比如List,scroll的时候可能触发了所谓的动画,
public void scrollTo(int x, int y) {
if (mScrollX != x || mScrollY != y) {
int oldX = mScrollX;
int oldY = mScrollY;
mScrollX = x;
mScrollY = y;
invalidateParentCaches();
onScrollChanged(mScrollX, mScrollY, oldX, oldY);
if (!awakenScrollBars()) {
postInvalidateOnAnimation();
}
}
}
最终调用Choreogtapher的postInvalidateOnAnimation创建Choreographer.CALLBACK_ANIMATION类型回调
public void postInvalidateOnAnimation() {
final AttachInfo attachInfo = mAttachInfo;
if (attachInfo != null) {
attachInfo.mViewRootImpl.dispatchInvalidateOnAnimation(this);
}
}
final class InvalidateOnAnimationRunnable implements Runnable {
...
private void postIfNeededLocked() {
if (!mPosted) {
mChoreographer.postCallback(Choreographer.CALLBACK_ANIMATION, this, null);
mPosted = true;
}
}
只是调用View的invalidate,不怎么耗时:
final class InvalidateOnAnimationRunnable implements Runnable {
@Override
public void run() {
final int viewCount;
final int viewRectCount;
synchronized (this) {
...
for (int i = 0; i < viewCount; i++) {
mTempViews[i].invalidate();
mTempViews[i] = null;
}
当然,如果这里有自定义动画的话,就不一样了。但是,就GPU呈现模式统计耗时而言,却并非像官方文档说的那样,似乎压根没有这部分耗时,而源码中也只有七段,如下图:
重写invalidate函数验证,会发现,这部分耗时会被归到输入事件耗时里面:
@Override
public void invalidate() {
super.invalidate();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
}
}
也就是说下面的官方说明可能是错误的,因为真机上没看到这部分耗时,或者说,这部分耗时被归结到Touch事件耗时中去了,从源码中看好像也是这样。

测量、布局、绘制耗时
走到测量重绘的时候,整个流程已经清晰了,在UI线程中测量重绘耗时很直观,也很忠诚,用多少就是多少,没有Vsync那样别扭的问题,没什么分析必要,不过需要注意的是,这里的Draw仅仅是构建DisplayList数,也可以看做是帮助创建OpenGL绘制命令及预处理些数据,没有真正渲染,到这里为止,都是在UI线程中进行的,剩下三个阶段Sync/upload、Issue commands、swap buffers都是在RenderThread线程。
Sync/upload(同步和上传 )耗时
The Sync & Upload metric represents the time it takes to transfer bitmap objects from CPU memory to GPU memory during the current frame.
As different processors, the CPU and the GPU have different RAM areas dedicated to processing. When you draw a bitmap on Android, the system transfers the bitmap to GPU memory before the GPU can render it to the screen. Then, the GPU caches the bitmap so that the system doesn’t need to transfer the data again unless the texture gets evicted from the GPU texture cache.
表示将位图信息上传到 GPU 所花的时间,不过Android手机上 CPU跟GPU是共享物理内存的,这里的上传个人理解成拷贝,这样的话,CPU跟GPU所使用的数据就相互独立开来,两者并行处理的时候不会有什么同步问题,耗时大的话,说明需要上传位图信息过多,这里个人感觉主要是给纹理、材质准备的素材。
Issue commands
The Issue Commands segment represents the time it takes to issue all of the commands necessary for drawing display lists to the screen.
这部分耗时主要是CPU将绘制命令发送给GPU,之后,GPU才能根据这些OpenGL命令进行渲染。这部分主要是CPU调用OpenGL ES API来实现。
swapBuffers耗时
Once Android finishes submitting all its display list to the GPU, the system issues one final command to tell the graphics driver that it's done with the current frame. At this point, the driver can finally present the updated image to the screen.
之前的GPU命令被issue完毕后,CPU一般会发送最后一个命令给GPU,告诉GPU当前命令发送完毕,可以处理,GPU一般而言需要返回一个确认的指令,不过,这里并不代表GPU渲染完毕,仅仅是通知CPU,GPU有空开始渲染而已,并未渲染完成,但是之后的问题APP端无需关心了,CPU可以继续处理下一帧的任务了。如果GPU比较忙,来不及回复通知,则CPU需要阻塞等待,直到收到通知,才会唤起当前阻塞的Render线程,继续处理下一条消息,这个阶段是在swapBuffers中完成的。可进一步参考Android硬件加速(二)-RenderThread与OpenGL GPU渲染。
OpenGL GPU Profiler源码 (非真机,软件模拟的OpenGL库libagl)
GPU Profiler绘制主要是通过FrameInfoVisualizer的draw函数实现:
void FrameInfoVisualizer::draw(OpenGLRenderer* canvas) {
RETURN_IF_DISABLED();
...
// 绘制一条条,dubug模式中可以开启
if (mType == ProfileType::Bars) {
// Patch up the current frame to pretend we ended here. CanvasContext
// will overwrite these values with the real ones after we return.
// This is a bit nicer looking than the vague green bar, as we have
// valid data for almost all the stages and a very good idea of what
// the issue stage will look like, too
FrameInfo& info = mFrameSource.back();
info.markSwapBuffers();
info.markFrameCompleted();
<!--计算宽度及高度-->
initializeRects(canvas->getViewportHeight(), canvas->getViewportWidth());
drawGraph(canvas);
drawThreshold(canvas);
}
}
这里用的色值及用的就是之前说的7种,这部分代码提前markSwapBuffers跟markFrameCompleted,看注释,CanvasContext后面用real耗时进行校准:
void FrameInfoVisualizer::drawGraph(OpenGLRenderer* canvas) {
SkPaint paint;
for (size_t i = 0; i < Bar.size(); i++) {
nextBarSegment(Bar[i].start, Bar[i].end);
paint.setColor(Bar[i].color | BAR_FAST_ALPHA);
canvas->drawRects(mFastRects.get(), mNumFastRects * 4, &paint);
paint.setColor(Bar[i].color | BAR_JANKY_ALPHA);
canvas->drawRects(mJankyRects.get(), mNumJankyRects * 4, &paint);
}
}
之前简析过Java层四种耗时,现在看看最后三种耗时的统计点:
<!--同步开始-->
void CanvasContext::prepareTree(TreeInfo& info, int64_t* uiFrameInfo, int64_t syncQueued) {
mRenderThread.removeFrameCallback(this);
<!--将Java层拷贝-->
mCurrentFrameInfo->importUiThreadInfo(uiFrameInfo);
mCurrentFrameInfo->set(FrameInfoIndex::SyncQueued) = syncQueued;
// 这里表示开始同步上传位图
mCurrentFrameInfo->markSyncStart();
...
mRootRenderNode->prepareTree(info);
...
}
markSyncStart标记着上传位图开始,通过prepareTree将Texture相关位图拷贝给GPU可用内存区域后,CanvasContext::draw进一步issue GPU命令到GPU缓冲区:
void CanvasContext::draw() {
...
<!--Issue的开始-->
mCurrentFrameInfo->markIssueDrawCommandsStart();
...
<!--GPU呈现模式的图表绘制-->
profiler().draw(mCanvas);
<!--像GPU发送命令,可能是对应的GPU驱动,缓存等-->
mCanvas->drawRenderNode(mRootRenderNode.get(), outBounds);
<!--命令发送完毕-->
mCurrentFrameInfo->markSwapBuffers();
if (drew) {
swapBuffers(dirty, width, height);
}
// TODO: Use a fence for real completion?
<!--这里只有用GPU fence才能获取真正的耗时,不然还是无效的,看每个手机厂家的实现了-->
mCurrentFrameInfo->markFrameCompleted();
mJankTracker.addFrame(*mCurrentFrameInfo);
mRenderThread.jankTracker().addFrame(*mCurrentFrameInfo);
}
markIssueDrawCommandsStart 标记着issue命令开始,而mCanvas->drawRenderNode负责真正issue命令到缓冲区,issue结束后,通知GPU绘制,同时将图层移交SurfaceFlinger,这部分是通过swapBuffers来实现的,在真机上需要借助Fence机制来同步GPU跟CPU,参考Android硬件加速(二)-RenderThread与OpenGL GPU渲染。由于后三部分可控性比较小,不再分析,有兴趣可以自己查查OpenGL及GPU相关知识。
总结
- GPU Profiler的色值跟官方文档对不起来
- 动画耗时并没有单独的色块,而是被归并到Touch事件耗时中
- Studio自带的CPU Profiler有问题,存在合并操作的BUG
- 源码中关于跳帧的统计可能不准,他统计的不是跳帧,而是VSYNC的延时
- Chorgropher通过各种标记保证了一个VSYNC信号中最多只有一个Touch事件、一个重绘事件、一次动画更新
- GPU呈现模式的图表仅供参考,并不完全正确。
作者:看书的小蜗牛 Android GPU呈现模式原理及卡顿掉帧浅析
仅供参考,欢迎指正
