

1. 前言
现在初入前端的同学们,都直接就上手webpack了,而在几年前没有node还是jquery打天下的时候,不借助node或软件让不同js文件之间互相引用、模块化开发,是件很麻烦的事。
接下来会介绍两个有名的工具AMD(require.js)和CMD(sea.js),虽然现在用的很少了,但还是需要知道模块化经历的过程,面试也可能会问到。
2. 需求的产生
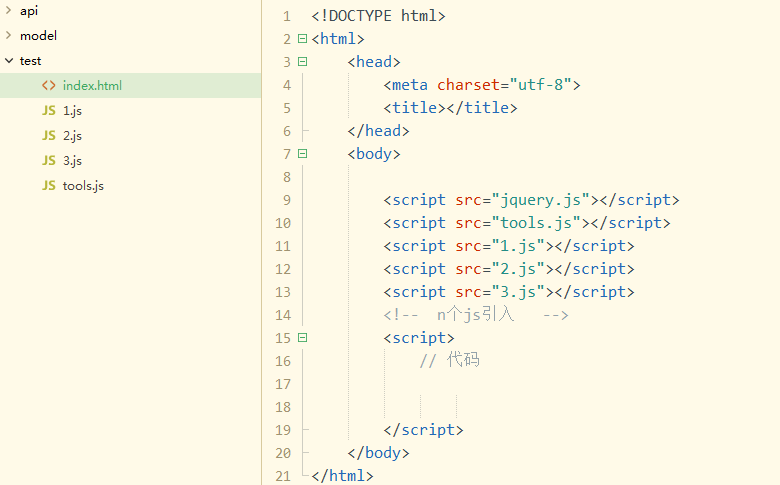
- 必须按顺序引入,如果 1.js中要用到jquery,那就将jquery.js放到1.js上方。
- 同步加载各个js,只有1.js加载并执行完,才去加载2.js。
- 各个js文件可能会有多个window全局变量的创建,污染。
- ......还有很多缺点
总之,上面的结构,在前端内容越来越多,尤其ajax的趋势、前后端分离、越来越注重前端体验,js文件越来越多且互相引用更复杂的情况下,真心乱套了,所以需要有一个新的模块化工具。
我们当然是希望像现在这样,文件之间互相 import、export 就行了,但遗憾的是,这是es6配合node的用法,需要服务端做支撑处理文件,而一开始仅通过静态文件去模块化。
3. AMD
即Asynchronous Module Definition,中文名是异步模块定义的意思。它是一个模块化开发的规范,是一种思路,是一个概念。我们不用过于纠结它到底是个啥,只需要知道它是一个规范概念,而大名鼎鼎的require.js,是它的一个具体的实现,以前很多都用这个工具开发。
require.js的用法
这里只介绍大概简单的用法,没用过的同学最好去看教程。
login.html中
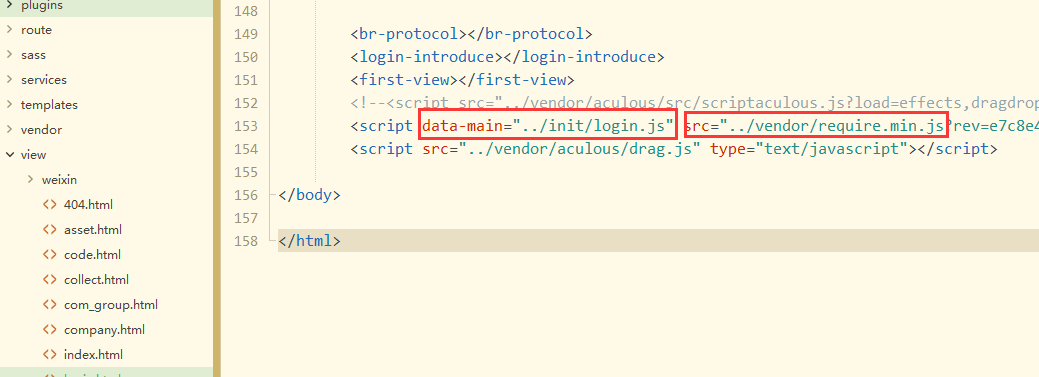
引入了require.js文件,然后指定了入口文件login.js
~~
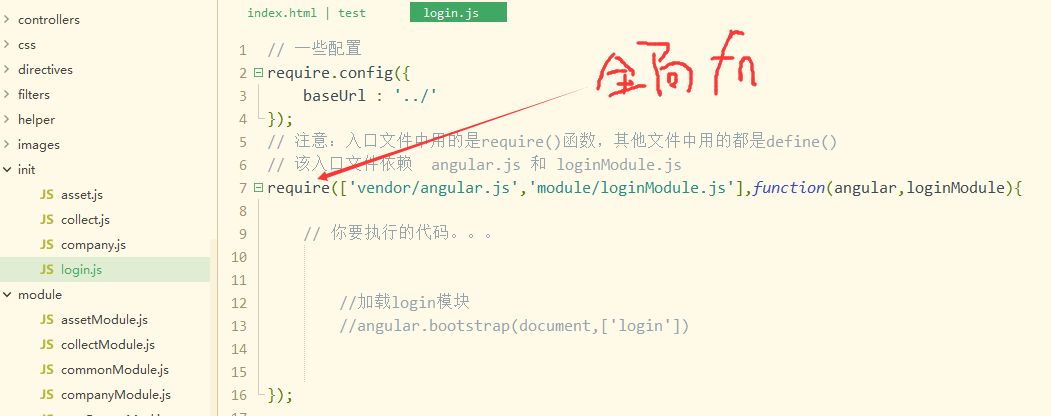
入口文件login.js中
loginModule.js中
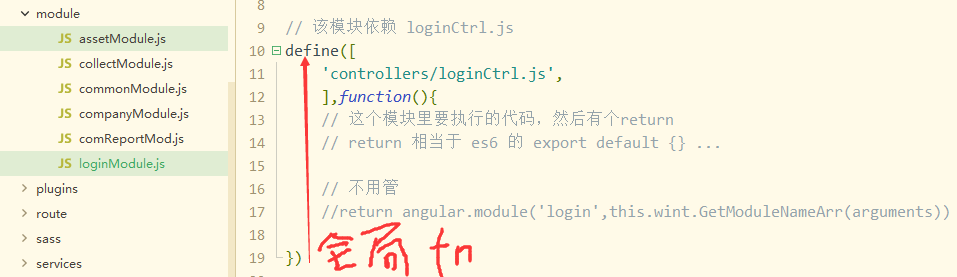
loginCtrl.js中

注意:
-
实际上就是定义了两个全局变量函数,一个require(),一个define()
-
其实这两个函数功能和原理差不多,你可以认为他俩除了名字不一样,其他都差不多。
-
define函数的第一个参数是个数组,写的是所依赖的模块;第二个参数是回调函数,回调函数里的参数对应的是依赖数组里的模块返回值,如:
es6 :
import A from 'a.js'
import B from 'b.js'
require.js:
define(['a.js', 'b.js'], function(A, B) {
})
最需要注意的是!!!:
无论是CMD还是AMD,都只是让开发者写代码时变爽了,而对于浏览器来说,可以认为没啥太大变化,该加载多少js文件,js文件的顺序,都和以前没啥区别!!!
4. require.js 原理
到这里我们大概知道了,这两个工具的意义,是让开发者不再需要写一堆 <script> 标签 引入js了,让编码更爽。。。但是对于浏览器那边,没啥大的变化。
以前:
编码:
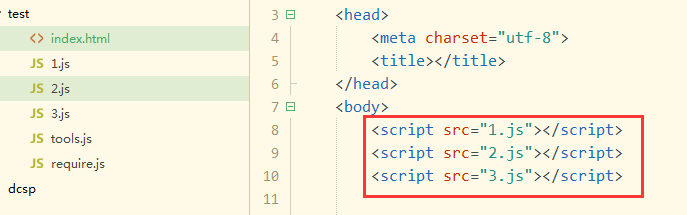
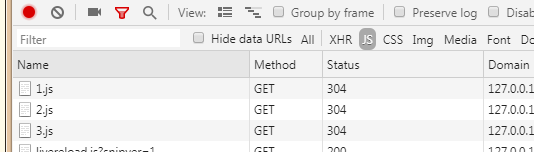
浏览器:
require.js后
编码:
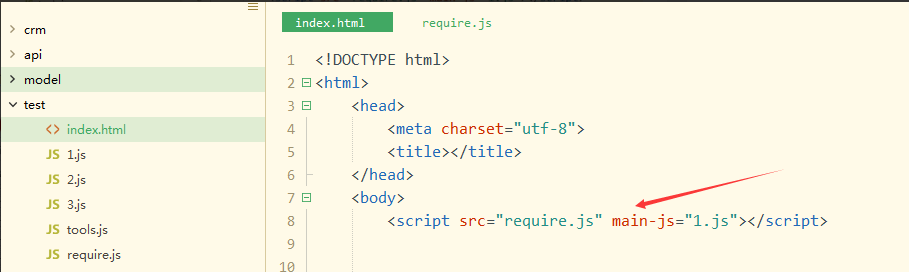
浏览器:
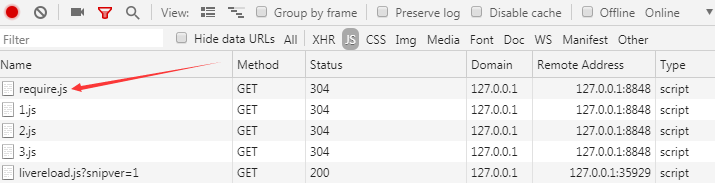
所以结论:require.js只是采取了某种“方法”,让你在写代码时只写一个<script>,运行html文档时却是多个<script>
分析实现原理:
可能1:
编码时的html文件和运行时的html文件是两个文件,即通过某些工具复制并修改了html。可惜修改文件需要服务端程序去做,而require.js只是个js文件,所以不是这个原理。这在node下webpack可以轻松的实现。
可能2:
既然可能1是不对的,那么说明了,浏览器运行的html文件和编码时的html文件是一模一样的。所以只剩下第二条路了,就是运行时由js代码去修改html文档~
工具目的:
所以我们的目的就成了,浏览器文档一开始运行时:
就只引用了一个require.js文件
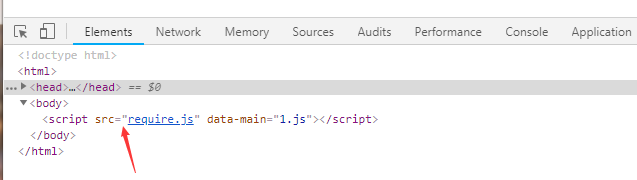
执行了require.js之后,由js在dom上添加了一堆 <script>
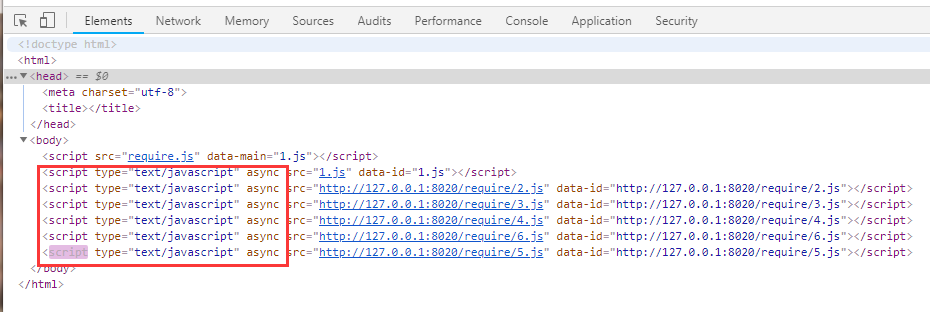
也就是说,红框里的<script>,都是require.js里的js代码手动在body元素尾部添加的!!!
还有,添加了<script src="3.js" > , 不能只是在html文档上添加了这行字符串,而是要加载并且运行 3.js !!!
!!!重要方法:
1. 插入sciprt节点,并且 加载 + 运行 其js文件
// 建一个node节点, script标签
var node = document.createElement('script')
node.type = 'text/javascript'
node.src = '3.js'
// 将script节点插入dom中
document.body.appendChild(node)
注意:
采用dom.appendChild方法插入script节点,会立即下载js文件,并且运行文件!
而采用dom.innerHTML = '<script src="3.js"></script>',则只是在dom中插入了一行字符串,就更不会管字符串里引入的js了,所以不能用这个方法插入script!!!
2. 各个js文件的加载时机(script标签插入文档的时机顺序)
文件之间有依赖关系的,所以加载js文件 (dom中插入script节点) 是要有顺序的,比如: 1.js 依赖 2.js,2.js 依赖 3.js
那么,实际的加载顺序是为 1.js,2.js,3.js
有同学可能会问,按理说加载顺序应该是反过来 3.js,2.js,1.js啊。。。那是因为,只有 1.js 加载并且运行之后,才知道1.js依赖啥啊。。。仔细想想,你在 1.js 里面写得define([2.js]),那是不是得 先加载运行 1.js 后才能从define函数的参数中拿到依赖 2.js ?
注意: 而实际模块运行的顺序,才是 3.js,2.js,1.js。。。所以,文件的加载、加载后文件的运行、模块的运行,这是 3 个东西啊,别混了先,下一部分再细说。
继续这里,那么就需要判断,1.js什么时候加载完呢?
<script src="1.js" onload="alert()"></script>
关键就在于,onload 这个函数,其作用是,1.js 加载完并且执行完之后,执行onload里的 alert
所以要实现 1.js 加载完后再加载 2.js ,则只需这样:
var node = document.createElement('script')
node.type = 'text/javascript'
node.src = '1.js'
// 给该节点添加onload事件,标签上onload,这里是load,见事件那里的知识点
// 1.js 加载完后onload的事件
node.addEventListener('load', function(evt) {
// 开始加载 2.js
var node2 = document.createElement('script')
node2.type = 'text/javascript'
node2.src = '2.js'
// 插入 2.js script 节点
document.body.appendChild(node2)
})
// 插入 1.js script 节点
document.body.appendChild(node)
所以,处理依赖的核心就是利用 onload 事件,不断的递归嵌套的加载依赖文件。事实上,最麻烦的也是这里处理依赖文件,尤其是一个文件可能被多个文件所依赖,的情况。
3. 文件模块的执行时机
这一点一定要理解,这也是require.js和sea.js的区别之一。
刚才说了3个东西,文件的加载、加载后文件的运行、模块的运行,这里千万别蒙圈,举例:
// 1.js 中的代码
require([], functionA() {
// 主要逻辑代码
})
js文件加载后就会瞬间执行文件,那么
-
文件的加载:将<script src='1.js' > 节点插入dom中,之后,下载 1.js 文件
-
加载后文件的运行:1.js 文件加载完后,执行 1.js 中的代码,即执行 require() 函数!!!
-
模块的运行: require回调函数,上方的,主要逻辑代码,所在的函数,functionA,的运行!!!
所以我们以后所说的 运行,都指的是 模块的运行 ,而文件的运行默认和加载一起了就,不需考虑。。。而且我们每个页面的逻辑代码都要是写在require/define 的回调函数,functionA中的啊。。。
!!!一定要要仔细想清楚,模块加载顺序和模块运行的顺序?
就像 es6 你 1.js 中 import '2.js',不得 2.js 先执行并且返给你个值?即:
1.js 依赖 2.js 时,那么是 1.js 先加载, 但是 2.js 模块先运行(还是要注意:是模块的运行,不是文件的运行!!!)
总结顺序:
-
文件加载/文件运行 顺序: 1.js , 2.js , 3.js
-
模块运行 顺序:3.js , 2.js , 1.js
5. require.js 简单代码实现
用法例子
// 1.js 中(入口用require,其他用define)
require(['2.js'], function(A) {
// A得到的就是2.js模块的返回值
// 主要的执行代码
// 2.js 3.js都加载完,才执行1.js的这回调函数!!!!!!!!!!!!!!!
})
// 2.js 中
define(['3.js', 'xxxx.js'], functionA(B, C) {
// B得到的就是3.js模块的返回值,C是xxxx.js的
return aaaaa // 2.js 模块的返回值
})
// 3.js 中
define([], functionA() {
retrun {} // 3.js 模块的返回值
})
require.js 简单源码原理
利用递归去加载层层的嵌套依赖,代码的难点就在于,怎样判断递归结束?即怎样判断所有的依赖都加载完了?
var modules = {}, // 存放所有文件模块的信息,每个js文件模块的信息
loadings = []; // 存放所有已经加载了的文件模块的id,一旦该id的所有依赖都
加载完后,该id将会在数组中移除
// 上面说了,每个文件模块都要有个id,这个函数是返回当前运行的js文件的文件名,拿文件名作为文件对象的id
// 比如,当前加载 3.js 后运行 3.js ,那么该函数返回的就是 '3.js'
function getCurrentJs() {
return document.currentScript.src
}
// 创建节点
function createNode() {
var node = document.createElement('script')
node.type = 'text/javascript'
node.async = true;
return node
}
// 开始运行
function init() {
// 加载 1.js
loadJs('1.js')
}
// 加载文件(插入dom中),如果传了回调函数,则在onload后执行回调函数
function loadJs(url, callback) {
var node = createNode()
node.src = url;
node.setAttribute('data-id', url)
node.addEventListener('load', function(evt) {
var e = evt.target
setTimeout(() => { // 这里延迟一秒,只是让在浏览器上直观的看到每1秒加载出一个文件
callback && callback(e)
}, 1000)
}, false)
document.body.appendChild(node)
}
// 此时,loadJs(1.js)后,并没有传回调函数,所以1.js加载成功后只是自动运行1.js代码
// 而1.js代码中,是require( ['2.js', 'xxx.js'], functionA(B, C){} ),则执行的是require函数, 在下面是require的定义
window.require = function(deps, callback) {
// deps 就是对应的 ['2.js', 'xxx.js']
// callback 就是对应的 functionA
// 在这里,是不会运行callback的(即模块的运行!),得等到所有依赖都加载完的啊
// 所以得有个地方,把一个文件的所有信息都先存起来啊,尤其是deps和callback
var id = getCurrentJs();// 当前运行的是1.js,所以id就是'1.js'
if(!modules.id) {
modules[id] = { // 该模块对象信息
id: id,
deps: deps,
callback: callback,
exports: null, // 该模块的返回值return ,
就是functionA(B, C)运行后的返回值,仔细想想?在后面的getExports中详细讲
status: 1,
}
loadings.unshift(id); // 加入这个id,之后会循环loadings数组,递归判断id所有依赖
}
loadDepsJs(id); // 加载这个文件的所有依赖,即去加载[2.js]
}
function loadDepsJs(id) {
var module = modules[id]; // 获取到这个文件模块对象
// deps是['2.js']
module.deps.map(item => { // item 其实是依赖的Id,即 '2.js'
if(!modules[i]) { // 如果这个文件没被加载过(注:加载过的肯定在modules中有)
(1) loadJs(item, function() { // 加载 2.js,并且传了个回调,准备要递归了
// 2.js加载完后,执行了这个回调函数
loadings.unshift(item); // 此时里面有两个了, 1.js 和 2.js
// 递归。。。要去搞3.js了
loadDepsJs(item)// item传的2.js,递归再进来时,就去modules中取2.js的deps了
// 每次检查一下,是否都加载完了
checkDeps(); // 循环loadings,配合递归嵌套和modules信息,判断是否都加载完了
})
}
})
}
// 上面(1)那里,加载了2.js后马上会运行2.js的,而2.js里面是
define(['js'], fn)
// 所以相当于执行了 define函数
window.define = function(deps,callback) {
var id = getCurrentJs()
if(!modules.id) {
modules[id] = {
id: id,
deps: getDepsIds(deps),
callback: callback,
exports: null,
status: 1,
}
}
}
// 注意,define运行的结果,只是在modules中添加了该模块的信息
// 因为其实在上面的loadDepsJs中已经事先做了loadings和递归deps的操作,
而且是一直不断的循环往复的进行探查,所以define里面就不需要再像require中写一次loadDeps了
// 循环loadings,查看loadings里面的id,其所依赖的所有层层嵌套的依赖模块是否都加载完了
function checkDeps() {
for(var i = 0, id; i < loadings.length ; i++) {
id = loadings[i]
if(!modules[id]) continue
var obj = modules[id],
deps = obj.deps
// 下面那行为什么要执行checkCycle函数呢,checkDeps是循环loadings数组的模块id,而checkCycle是去判断该id模块所依赖的**层级**的模块是否加载完
// 即checkDeps是**广度**的循环已经加载(但依赖没完全加载完的)的id
// checkCycle是**深度**的探查所关联的依赖
// 还是举例吧。。。假如除了1.js, 2.js, 3.js, 还有个4.js,依赖5.js,那么
// loadings 可能 是 ['1.js', '4.js']
// 所以checkDeps --> 1.js, 4.js
// checkCycle深入内部 1.js --> 2.js --> 3.js ;;; 4.js --> 5.js
// 一旦比如说1.js的所有依赖2.js、3.js都加载完了,那么1.js 就会在loadings中移出
var flag = checkCycle(deps)
if(flag) {
console.log(i, loadings[i] ,'全部依赖已经loaded');
loadings.splice(i,1);
// !!!运行模块,然后同时得到该模块的返回值!!!
getExport(obj.id)
// 不断的循环探查啊~~~~
checkDeps()
}
}
}
// 深层次的递归的去判断,层级依赖是否都加在完了
// 进入1.js的依赖2.js,再进入2.js的依赖3.js ......
function checkCycle(deps) {
var flag = true
function cycle(deps) {
deps.forEach(item => {
if(!modules[item] || modules[item].status == 1) {
flag = false
} else if(modules[item].deps.length) {
// console.log('inner deps', modules[item].deps);
cycle(modules[item].deps)
}
})
}
cycle(deps)
return flag
}
/*
运行该id的模块,同时得到模块返回值,modules[id].export
*/
function getExport(id) {
/*
先想一下,例如模块2.js, 这时 id == 2.js
define(['3.js', 'xxxx.js'], functionA(B, C) {
// B得到的就是3.js模块的返回值,C是xxxx.js的
return aaaaa // 2.js 模块的返回值
})
所以:
1. 运行模块,就是运行 functionA (模块的callback)
2. 得到模块的返回值,就是functionA运行后的返回值 aaaaa
问题:
1. 运行functionA(B, C) B, C是什么?怎么来的?
2. 有B, C 了,怎么运行functionA ?
*/
// 解决问题1
// B, C 就是该模块依赖 deps [3.js, xxxx.js]对应的返回值啊
// 那么循环deps 得到 依赖模块Id, 取模块的export。。。
var params = [];
var deps = modules[id].deps
for(var i = 0; i < deps.length; i++) {
// 取依赖模块的exports即模块返回值,注意不要害怕取不到,因为你这个模块
都进来打算运行了,那么你的所有依赖的模块早都进来过运行完了(还记得模块运行顺序不?)
let depId = deps[i]
params.push( modules[ depId ].exports )
}
// 到这里,params就是依赖模块的返回值的数组,也就是B,C对应的实参
// 也就是 params == [3.js的返回值,xxxx.js的返回值]
if(!modules[id].exports) {
// 解决问题2: callback(functionA)的执行,用.apply,这也是为什么params是个数组了
// 这一行代码,既运行了该模块,同时也得到了该模块的返回值export
modules[id].exports = modules[id].callback.apply(global, params)
}
}
代码的难点就在于checkDeps以及对loadings进行递归那里,很难去讲清楚,需要自己去写去实践,这里也很难全都描述清楚。。。
结尾会给一个简单的能运行的例子
不要想着花一两个小时就搞定所有了,刚开始确实会看的烦,多回来几次,隔段时间再研究一下,每次都会加深一点
6. CMD
CMD 即Common Module Definition通用模块定义,sea.js是它的实现
sea.js是阿里的大神写得,和require.js很像,先看一下用法的区别
// 只有define,没有require
// 和AMD那个例子一样,还是1依赖2, 2依赖3
1.js中
define(function() {
var a = require('2.js')
console.log(33333)
var b = require('4.js')
})
2.js 中
define(function() {
var b = require('3.js')
})
3.js 中
define(function() {
// xxx
})
看着是比require.js要好一点。。。
AMD和CMD的区别
对依赖模块的执行时机不同,注意:不是加载的时机,模块加载的时机是一样的!!!
文件加载顺序: 都是先加载1.js,再加载2.js,最后加载3.js
模块运行顺序:
AMD: 3.js,2.js,1.js,,,即如果模块以及该模块的依赖都加载完了,那么就执行。。。 比如 3.js 加载完后,发现自己也没有依赖啊,那么直接执行3.js的回调了,,,2.js加载完后探查到依赖的3.js也加载完了,那么2.js就执行自己的回调了。。。。 主模块一定在最后执行
CMD: 1.js,2.js,3.js,,,即先执行主模块1.js,碰到require('2.js')就执行2.js,2.js中碰到require('3.js')就执行3.js
会不会又不理解,怎么能控制执行哪个文件模块呢?啥时执行呢?
还记得不,之前说过,执行模块,是指的执行那个functionA回调函数,callback,,,那么这个callback函数其实在一开始执行define()中,就已经通过参数,赋到了modules上了啊,所以无论CMD还是AMD,执行模块,都是执行modules[id].callback()

所以,sea.js里,你用的var a = require('2.js'),中的执行的require函数,源码中就是简单的执行了模块的callback
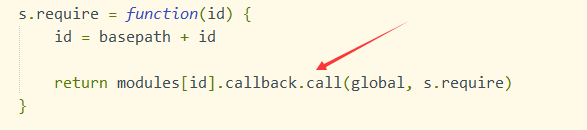
7. sea.js源码
源码,大部分和require.js都很像,上面说的执行时机不同,也很简单,就是控制一下啥时执行modules[id].callback呗。
之前又说了,加载模块差不多,那么sea.js是怎么通过require(3.js),require(2.js)去控制3.js和2.js的加载呢???上面说require函数已经就是执行callback了,那么require函数就不能承担起加载模块的功能了啊,再来看
CMD的define
用法
define(function() {
var a = require('2.js')
})
define源码的定义
window.define = function(callback) {
var id = getCurrentJs()
var depsInit = s.parseDependencies(callback.toString())
var a = depsInit.map(item => basepath + item)
// 和require.js的define相比,就多了上面的2行代码
// 1. 把传进来的函数给转换成字符串,'function (){var a = require("2.js")}'
// 2. 利用一个正则函数,取出字符串中require中的2.js,最后拼成一个数组['2.js']返回来。
// 3. 之后就和require.js差不多了啊。。。
// 下面的都差不多
if(!modules[id]) {
modules[id] = {
id: id,
status: 1,
callback: callback,
deps: a,
exports: null
}
}
s.loadDepsJs(id)
}
所以sea.js,是写了一个正则的函数,去查询define中传入的fn的字符串,然后得到的依赖数组。。。 而require.js的依赖数组,是咱们自己写并且传入的:define(['2.js'])。。。
这个正则方法,大家不用去探究,练习时直接用就行了
8. 最后
简单源码地址:
这个文章内容写得确实有点多有点罗嗦,还是希望能够讲的通俗易懂一点。之后会不断的完善文章,也欢迎大家留言提问,不对的地方也欢迎指正~~~希望对大家能有帮助
转载请注明出处,谢谢~~
