

本节信息量很大,我们要从整体上把握 LevelDB 这座大厦的结构。当我们熟悉了整体的结构,接下来就可以各个击破来细致了解它的各种微妙的细节了。
一个比喻
LevelDB 有点类似于建筑,分为地基和地面两部分,也就是磁盘和内存,而地基又好比地壳结构分了很多层级,不同层级的数据还会定期从上往下移动 —— 沉积作用。如果磁盘底层的冷数据被修改了,它又会再次进入内存,一段时间后又会被持久化刷回到磁盘文件的浅层,然后再慢慢往下移动到底层,周而复始就好比地球水循环。
内存结构
LevelDB 的内存中维护了 2 个跳跃列表,一个是只读的 rtable,一个是可修改的 wtable。跳跃列表在我的另一本书《Redis 深度历险》中有详细讲解,这里就不再细致重复说明。简单理解,跳跃列表就是一个 Key 有序的 Set 集合,排序规则由全局的「比较器」决定,默认是字典序。跳跃列表的查找和更新操作时间复杂度都是 Log(n)。
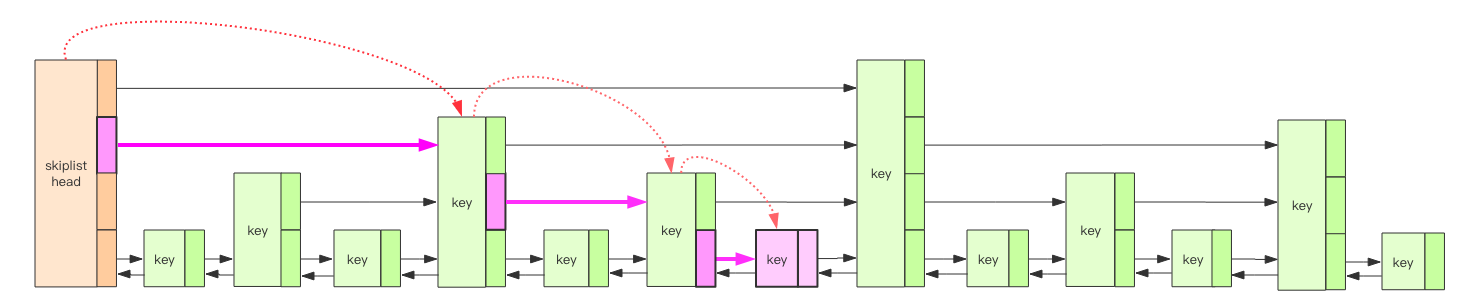
跳跃列表是由多个层次的链表构成,其中最底层的链表存储了所有的 Key,它们是有序的。普通链表并不支持快速二分查找,但是跳跃链表的特殊结构可以让最底层的链表以近似二分查找算法的效率定位到指定节点。简单理解就是跳跃列表同时具备了有序数组的快速定位能力和链表的高效增删能力。但是它会付出一定的代价,在实现上有一定的复杂度。
如果跳跃列表只存 Key,那 Value 存哪里呢?答案是 Value 也存在跳跃列表的 Key 中。跳跃列表中存储的 Key 比较特殊,它是一个复合结构字符串,它同时包含了键值对的 Key 和 Value。
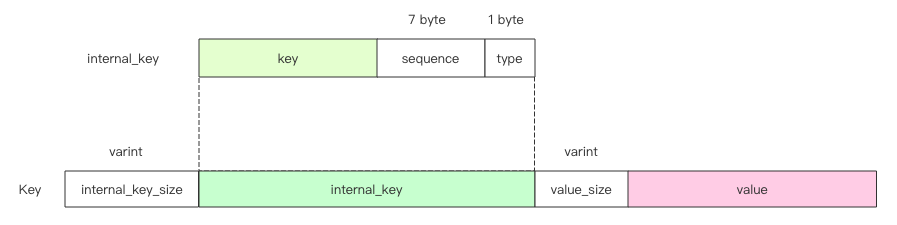
type 为数据类型,标记是 Put 还是 Delete 操作,只有两个取值,0 表示 Delete,1 表示 Put。
internal_key = key + sequence + type
Key = internal_key_size + internal_key + value_size + value
如果是删除操作,后面的 value_size 字段值 为 0,value 字段值是空的。我们要将 Delete 操作等价看成 Put 操作。同时为了节省存储空间,internal_key_size 和 value_size 都要采用 varint 整数编码。
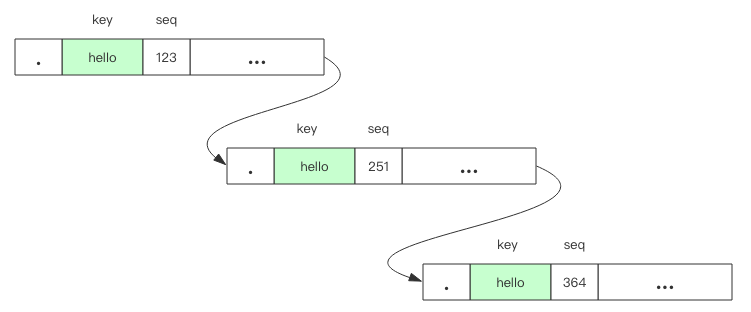
待 Put 和 Delete 操作日志写到日志文件后,其键值对合并成「复合 Key」插入到 wtable 的指定位置中。
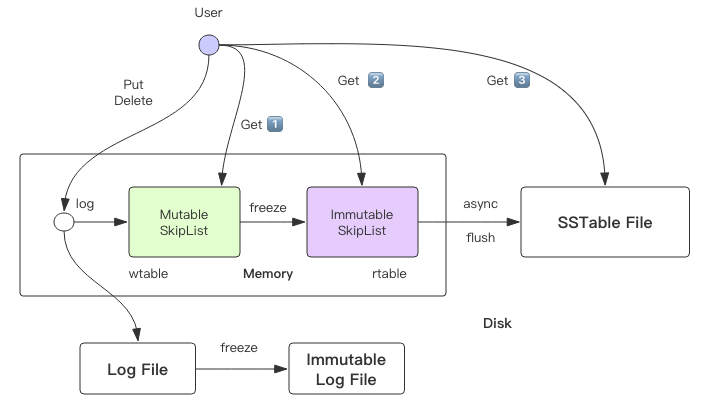
因为 wtable 要支持多线程读写,所以访问它是需要加锁控制。而 rtable 是只读的,它就不需要,但是它的存在时间很短,rtable 一旦生成,很快就会被异步线程序列化到磁盘上,然后就会被置空。但是异步线程序列化也需要耗费一定的时间,如果 wtable 增长过快,很快就被写满了,这时候 rtable 还没有完成序列化,而wtable 急需变身怎么办?这时写线程就会阻塞等待异步线程序列化完成,这是 LevelDB 的卡顿点之一,也是未来 RocksDB 的优化点。
图中还有个日志文件,记录了近期的写操作日志。如果 LevelDB 遇到突发停机事故,没有持久化的 wtable 和 rtable 数据就会丢失。这时就必须通过重放日志文件中的指令数据来恢复丢失的数据。注意到日志文件也是有两份的,它和内存的跳跃列表正好对应起来。当 wtable 要变身时,日志文件也会跟着变身。待 rtable 落盘成功之后,只读日志文件就可以被删除了。
磁盘结构
LevelDB 在磁盘上存储了很多 sst 文件,sst 表示 Sorted String Table,文件里所有的 Key 都会有序的。每个文件都会对应一个层级,每个层级都会有多个文件。底层的文件内容来源于上一层,最终它们都会来源于 0 层文件,而 0 层的文件又来源于内存里的 rtable 序列化。一个 rtable 会被序列化为一个完整的 0 层文件。这就是我们前面所说的「下沉作用」。
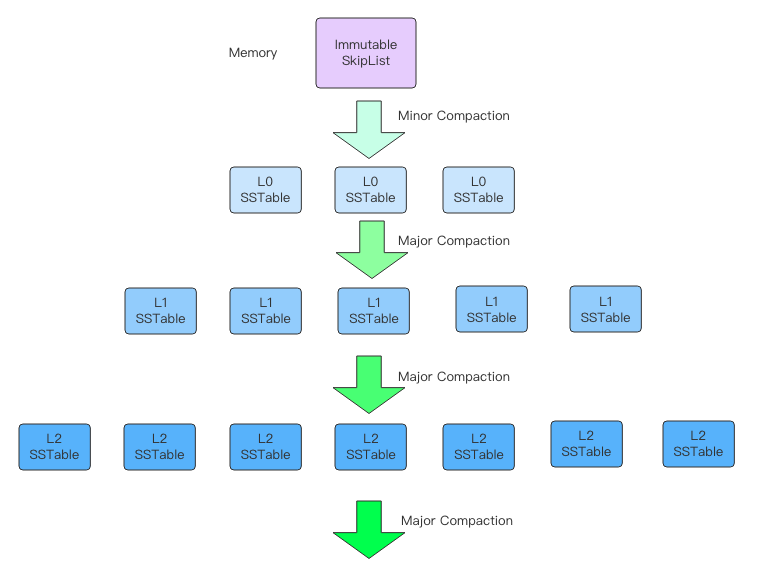
从内存的 rtable 序列化成 0 层 sst 文件称之为「Minor Compaction」,从 n 层 sst 文件下沉到 n+1 层 sst 文件称之为「Major Compaction」。之所以这样区分是因为 Minor 速度很快耗费资源少,将 rtable 完整地序列化为一个 sst 文件就完事了。而 Major 会涉及到多个文件之间的合并操作,耗费资源多,速度慢。层级越深的文件总容量越大,在 LevelDB 源码里有一个层级容量公式,容量和层级呈指数级关系。而通常每个 sst 文件的大小都差不多,区别就成了每一层的文件数量不一样。
capacity = level > 0 && 10^(level+1) M
每个文件里面的 Key 都是有序的,也就是说它内部的 Key 取值会有一个确定的范围。0 层文件和其它层文件有一个明显的区别那就是其它层内部的文件之间范围不会重叠,它们按照 Key 的顺序严格做了切分。而 0 层文件的内容是直接从内存 dump 下来的,所以 0 层的多个文件的 Key 取值范围会有重叠。
当内存出现读 miss 要去磁盘搜寻时,会首先从 0 层搜寻,如果搜不到再去更深层次搜寻。
如果是其它层级,搜寻速度会很快,因为可以根据 Key 的范围快速确定它可能会位于哪个文件中。但是对于 0 层,因为文件 Key 范围会重叠,所以它可能存在于多个文件中,那就需要对这多个文件进行搜寻。正因如此,LevelDB 限制了 0 层文件的数量,如果数量超出了默认的 4 个,就需要「下沉」到 1 层,这个「下沉」操作就是 Major Compaction。
所有文件的 Key 取值范围、层级和其它元信息会存储在数据库目录里面的 MANIFEST 文件中。数据库打开时,读取一下这个文件就知道了所有文件的层级和 Key 取值范围。
MANIFEST 文件也有版本号,它的版本号体现在文件名上如 MANIFEST-000361。每一次重新打开数据库,都会生成一个新的 MANIFEST 文件,具有不同的版本号,然后还需要将老的 MANIFEST 文件删除。
数据库目录中还有另外一个文件 CURRENT,它里面的内容很简单,就是当前 MANIFEST 的文件名。LevelDB 首先读取 CURRENT 文件才知道哪个 MANIFEST 文件是有效文件。在遇到断电时,会存在一个小概率中间状态,新旧 MANIFEST 文件共存于数据库目录中。
我们知道 LevelDB 的数据库目录不允许多进程同时访问,那它是如何防止其它进程意外对这个目录文件进行读写操作呢?仔细观察数据库目录,你还会发现一个名称为 LOCK 的文件,它就是控制多进程访问数据库的关键。当一个进程打开了数据库时,会在这个文件上加上互斥文件锁,进程结束时,锁就会自动释放。
还有最后一个不那么重要的操作日志文件 LOG,它记录了数据库的一系列关键性操作日志,例如每一次 Minor 和 Major Compaction 的相关信息。

多路归并
Compaction 是比较耗费资源的操作,为了不影响线上的读写操作,LevelDB 将 Compaction 工作交给一个单一的异步线程来完成。如果工作量巨大,这个单一的异步线程也会有点吃不消。当异步线程吃不消的时候,线上内存的读写操作也会收到影响。因为只有 rtable 沉到磁盘里了,wtable 才可以变身。只有 wtable 变身了,才会有新的 wtable 被创建来容纳后续更多的键值对。总之就是一环套一环,环环相扣。
下面我们来研究一下 Compaction 。Minor Compaction 很好理解,就是内容空间有限,所以需要将 rtable 中的数据 dump 到磁盘 0 层文件。那为什么需要从 0 层文件 Compact 下沉到 1 层文件呢?因为 0 层文件如果过多,就会影响查找效率。前面我们提到 0 层文件之间的 Key 范围会有重叠,所以单个 Key 可能存在于多个文件中,IO 读次数将会被文件的数量放大。通过 Major Compaction 可以减少 0 层文件的数量,提升读效率。那是不是只需要下沉到 1 层文件就可以了呢?那 LevelDB 究竟是什么原因需要这么多层级呢?
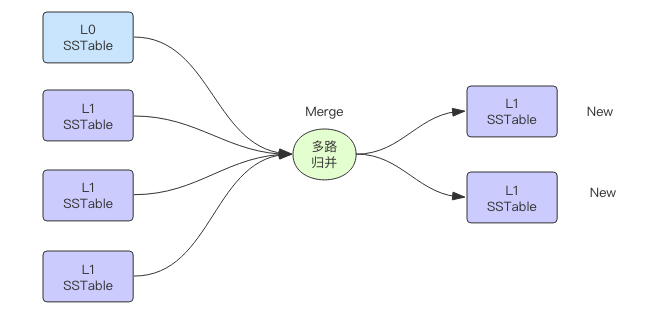
那 LevelDB 究竟是怎么做的呢?它采用多路归并算法,将相关的 0 层文件和 1 层 sst 文件作为输入,进行多路归并,生成多个新的 1 层 sst 文件,再将老的 sst 文件干掉,同时还会生成新的 MANIFEST 文件。对于每个 0 层文件,它会根据 Key 的取值范围搜寻 1 层文件中和它的范围有重叠部分的 sst 文件。如果 1 层文件数量过多,每次多路归并涉及到的文件数量太多,归并算法就会非常耗费资源。所以 LevelDB 同样也需要控制 1 层文件的数量,当 1 层容量满时,就会继续下沉到 2 层、3 层、4 层等。
非 0 层的多路归并资源消耗要少一些,因为单个文件的 Key 取值范围有限,能覆盖到下一层的文件数量有限,参与多路归并的输入文件就少了很多。但是这个逻辑有个漏洞,那就是上下层的文件数量有 10 倍的差距,按照平均范围间隔来算,意味着上层平均一个文件的取值范围会覆盖到下一层的 10 个文件。所以说非 0 层的多路归并资源消耗其实也不低,Major Compaction 就是一个比较消耗资源的操作。
下一节我们将深入磁盘文件内部结构,看看每一个 sstable 内部究竟长什么样

