

版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何技术交流,可随时联系。
网上的Hbase调优资料参差不齐,实在是不忍卒读,有些都是拼凑且版本过时的东西,我这里决定综合所有优质资源进行整合,写一份最全,最有深度,不过时的技术博客。辛苦成文,各自珍惜,谢谢!版权声明:禁止转载,欢迎学习,侵权必究!
1 HBase 数据块编码Key优化

数据块编码主要是针对 Key/Value 中的 Key 进行编码,减少 Key 存储所占用的空间,因为很多 Key 的前缀都是重复的。举例如下:
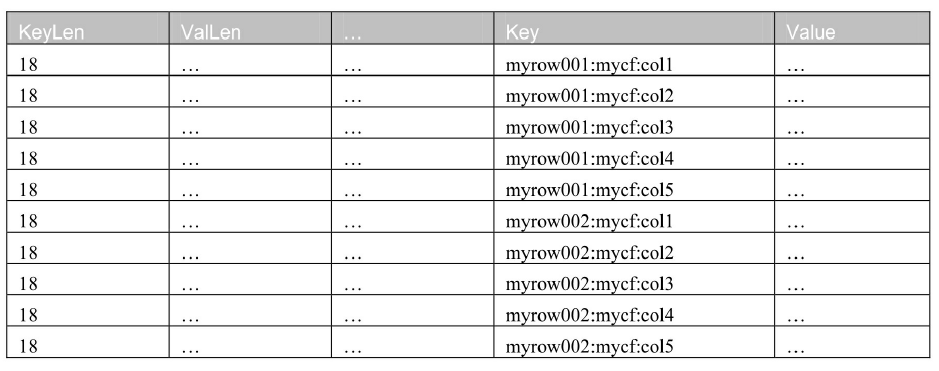
1.1 前缀编码(Prefix)
如果使用前缀编码作为数据块编码方式,那么它只会存储第一个 Key 的完整字符串,后面的 key 只存储跟第一个 key 的差异字符,重新编码过的数据如下所示。如下例所示:
最上面的key值为:
myrow001:mycf:col1
针对于key而言,后续的可以之存储差异值:
myrow001:mycf:col2就变为2
myrow001:mycf:col3就变为3
myrow002:mycf:col3就变为 2:mycf:col1 (变为最上面)
myrow003:mycf:col3就变为 3
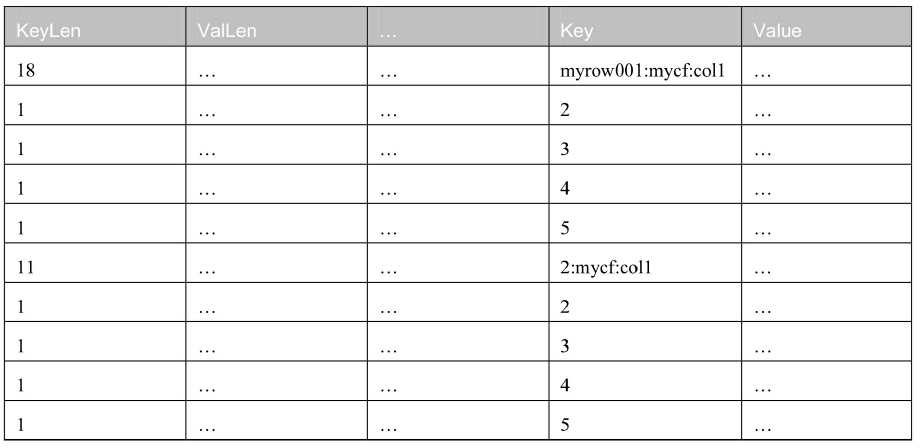
1.2 差异编码(Diff)
差异编码方式默认是不启用的。为什么?因为太慢了,每条数据都要这样计算一下,获取数据的速度很慢。除非你要追求极致的压缩比,但是不考虑读取性能的时候可以使用它,比如你想要把这部分数据当作归档数据的时候,可以考虑使用差异编码。
差异编码(Diff)比前缀编码更进一步,差异编码甚至把以下字段也一起进行了差异化的编码。
键长度(KeyLen);
值长度(ValueLen);
时间戳(Timestamp),也即是Version;
类型(Type),也即是键类型。
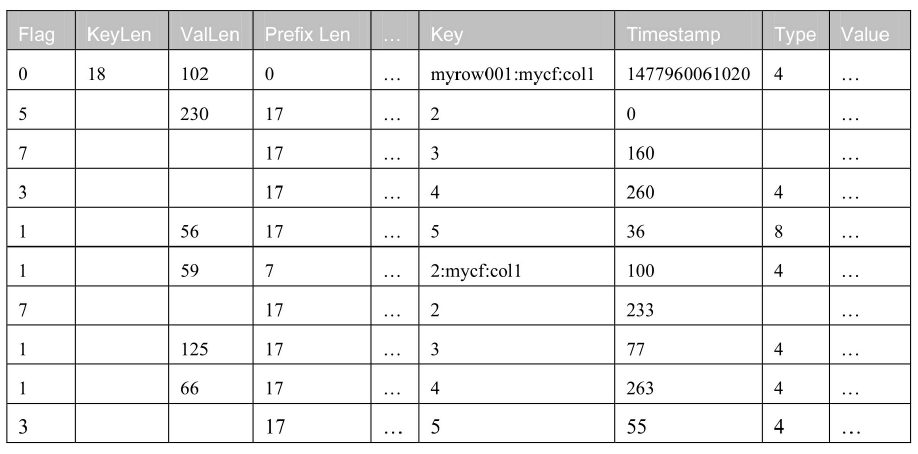
采用了差异编码后的 KeyValue 结构为:
1 byte:标志位;
1-5 bytes:Key 长度(KeyLen);
1-5 bytes:Value 长度(ValLen);
1-5 bytes:前缀长度(Prefix Len);
... bytes:剩余的部分;
... bytes:真正的 Key 或者只是有差异的 key 后缀部分;
1-8 bytes:时间戳(timestamp)或者时间戳的差异部分;
1 byte:Key 类型(type);
... bytes:值(value)。
版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何技术交流,可随时联系。
1.3 快速差异编码(Fast Diff)
快速差异编码(Fast Diff)借鉴了 Diff 编码的思路,也考虑到了差异编码速度慢的致命缺陷。快速差异编码的 KeyValue 结构跟差异编码一模一样,只有 Flag 的存储规则不一样,并且优化了 Timestamp 的计算。Fast Diff 的实现比 Diff 更快,也是比较推荐的算法
不过这个“快速”只是相对本来的差异算法而言的,由于还是有很多计算过程存在,所以快速差异算法的速度依然属于比较慢的。
1.4 前缀树编码(Prefix Tree)
前缀树编码(Prefix Tree)是前缀算法的变体,它是 0.96 版本之后才加入的特性。前缀树编码最大的作用就是提高了随机读的能力,但是其复杂的算法相对地降低了写入的速度,消耗了更多的 CPU 资源,使用时需要在资源的消耗和随机读的性能之间进行取舍。
2 基于Value的压缩器启用
压缩器的作用是可以把 HBase 的数据按压缩的格式存储,这样可以更节省磁盘空间。当然这完全是可选的,不过推荐大家还是安装 Snappy 压缩器,这是 HBase 官方目前排名比较高的压缩器。
hbase> alter 'mytable',{NAME =>'mycf',COMPRESSION=>'snappy'}
Snappy 是 Google 开发的压缩器,有以下特点:
快速:压缩速度达到 250MB/s;
稳定:已经用于 Google 多个产品长达数年;
健壮:Snappy 的解压器可以保证在数据被损坏的时候也不会太糟;
免费开源。
3 客户端API 新版本最佳实践
3.1 Connection 连接实例出世
推荐将 Configuration 做为单例;Connection 随建随用,用完及时关闭。
public static void main(String[] args) throws URISyntaxException, IOException {
//获取配置文件
Configuration config = HBaseConfiguration.create();
config.addResource(new Path(ClassLoader.getSystemResource("hbase-site.xml").toURI()));
config.addResource(new Path(ClassLoader.getSystemResource("core-site.xml").toURI()));
//创建连接
try (Connection connection = ConnectionFactory.createConnection(config); Admin admin = connection.getAdmin()) {
//定义表名
TableName tableName = TableName.valueOf("tb1");
//定义列族
ColumnFamilyDescriptor myCf = ColumnFamilyDescriptorBuilder.of("cf1");
//定义表
TableDescriptor table = TableDescriptorBuilder.newBuilder(tableName).setColumnFamily(myCf).build();
//执行创建表动作
admin.createTable(table);
} catch (Exception ex) {
ex.printStackTrace();
}
}
3.2 new HTable已废弃,新用法
// 已废弃,不推荐使用
// HTable table = new HTable(config, "mytable");
// 官方推荐
try (Connection connection = ConnectionFactory.createConnection(config)) {
connection.getTable(TableName.valueOf("tb1"));
}
3.3 checkAndPut(数据一致性)方法
Put put =new Put(Bytes.toBytes("qinkaixinRowkeys"))
put.addColumn(Bytes.toBytes("mycf"),Bytes.toBytes("name"),Bytes.toBytes("ted"));
boolean result = table.checkAndput(
Bytes.toBytes("row3"),
Bytes.toBytes("mycf"),
Bytes.toBytes("name"),
Bytes.toBytes("ted"),
put)
3.4 increment方法
保证原子性的情况下,把数据库中的某个列的数字进行数学运算
Table table = connection.getTable(TableName.valueOf("tb1"));
Increment inc = new Increment(Bytes.toBytes("row1"));
inc.addColumn(Bytes.toBytes("cf1"), Bytes.toBytes("age"), 1L);
table.increment(inc);
3.5 Mutation 方法
把添加一列的时候同时删除另一列的操作放在同一个原子操作中
Delete delete =new Delete(Bytes.toBytes("qinkaixinRowkeys"))
delete.addColumn(Bytes.toBytes("mycf"),Bytes.toBytes("name"),Bytes.toBytes("ted"));
Put put =new Put(Bytes.toBytes("qinkaixinRowkeys"))
put.addColumn(Bytes.toBytes("mycf"),Bytes.toBytes("name"),Bytes.toBytes("ted"));
RowMutations rowMutations =new RowMutations(Bytes.toBytes("ted"));
rowMutations.add(delete);
rowMutations.add(put);
table.mutateRow(rowMutations);
3.6 BufferedMutator批量操作(batch)()
客户端写缓冲区就是一个在客户端 JVM 里面的缓存机制,可以把多个 Put 操作攒到一起通过单个 RPC 请求发送给客户端,目的是节省网络握手带来的 IO 消耗。这个缓冲区可以通过调用 HTable.setAutoFlush(false) 来开启。 最新版的 API 中 setAutoFlush 被废弃了,每个表自带的 writeBuffer 也被废弃了,但是客户端写缓冲区还是存在的,只是转而使用 BufferedMutator 对象。
最好不要把针对同一个单元格的 Put 和 Delete 放到同一个 actions 列表里面,因为 HBase 不一定是顺序地执行这些操作的,你可能会得到意想不到的结果。
connection.getTable(TableName.valueOf("tb1")
Table table = connection.getBufferedMutator(TableName.valueOf("mytable"));
bm.mutate(put);
bm.flush();
bm.close();
3.7 批量 put 操作
HBase 提供了专门针对批量 put 的操作方法:void put(List puts);其实内部也是用 batch 来实现的。需要注意的是,当一部分数据插入成功,但是另一部分数据插入失败,比如某个 RegionServer 服务器出现了问题,这时会返回一个 IOException,操作会被放弃,不过插入成功的数据不会被回滚。
对于插入失败的数据,服务器会尝试着再次去插入或者换一个 RegionServer,当尝试的次数大于定义的最大次数会抛出 RetriesExhaustedWithDetailsException 异常,该异常包含了很多错误信息,包括有多少操作失败了,失败的原因以及服务器名和重试的次数。
3.8、Scan 缓存优化
现在的 HBase 在扫描的时候已经默认开启了缓存。
每一次的 next() 操作都会产生一次完整的 RPC 请求,而这次 RPC 请求可以获取多少数据是通过 hbase-site.xml 中的 hbase.client.scanner.caching 参数配置的。比如你如果配置该项为 1,那么当你遍历了 10 个结果就会发送 10 次请求,显而易见这是比较消耗性能的,尤其是当单条的数据量较小的时候。
hbase-site.xml参数调优:
<property>
<name>hbase.client.scanner.caching</name>
<value>100</value>
</property>
4 总结
本文解决了连个问题包括HBase数据块编码压缩机制调优以及客户端API 新版本最佳实践
版权声明:本套技术专栏是作者(秦凯新)平时工作的总结和升华,通过从真实商业环境抽取案例进行总结和分享,并给出商业应用的调优建议和集群环境容量规划等内容,请持续关注本套博客。QQ邮箱地址:1120746959@qq.com,如有任何技术交流,可随时联系。
参考文档及连接:Hbase不睡觉书 及官方文档资料
秦凯新 于深圳 201801102252
