

本文将通过如下简单的代码来分析HashMap的内部数据结构的变化过程。
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
for (int i = 0; i < 50; i++) {
map.put("key" + i, "value" + i);
}
}
1 数据结构说明
HashMap中本文需要用到的几个字段如下:
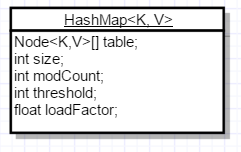
下面说明一下几个字段的含义
1)table
// HashMap内部使用这个数组存储所有键值对
transient Node<K,V>[] table;
Node的结构如下:
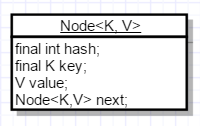
2)size
记录了HashMap中键值对的数量
3)modCount
记录了HashMap在结构上更改的次数,包括可以更改键值对数量的操作,例如put、remove,还有可以修改内部结构的操作,例如rehash。
4)threshold
记录一个临界值,当已存储键值对的个数大于这个临界值时,需要扩容。
5)loadFactor
负载因子,通常用于计算threshold,threshold=总容量*loadFactor。
2.new HashMap
new HashMap的源码如下:
/**
* The load factor used when none specified in constructor.
* 负载因子,当 已使用容量 > 总容量 * 负载因子 时,需要扩容
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
此时,HashMap只初始化了负载因子(使用默认值0.75),并没有初始化table数组。 其实HashMap使用的是延迟初始化策略,当第一次put的时候,才初始化table(此时table是null)。
3.table数组的初始化
当第一次put的时候,HashMap会判断当前table是否为空,如果是空,会调用resize方法进行初始化。 resize方法会初始化一个容量大小为16 的数组,并赋值给table。 并计算threshold=16*0.75=12。 此时table数组的状态如下:

4.put过程
map.put("key0", "value0");
首先计算key的hash值,hash("key0") = 3288451 计算这次put要存入数组位置的索引值:index=(数组大小 - 1) & hash = 3 判断 if (table[index] == null) 就new一个Node放到这里,此时为null,所以直接new Node放到3上,此时table如下:

继续put。。。
map.put("key1", "value1");

map.put("key1", "value1");
map.put("key2", "value2");
map.put("key3", "value3");
map.put("key4", "value4");
map.put("key5", "value5");
map.put("key6", "value6");
map.put("key8", "value7");
map.put("key9", "value9");
map.put("key10", "value10");
map.put("key11", "value11");

map.put("key12", "value12");
计算Key的hash值,hash("key12")=101945043,计算要存入table位置的索引值 = (总大小 - 1) & hash = (16 - 1) & 101945043 = 3 从目前的table状态可知,table[3] != null,但此时要put的key与table[3].key不相等,我们必须要把他存进去,此时就产生了哈希冲突(哈希碰撞)。
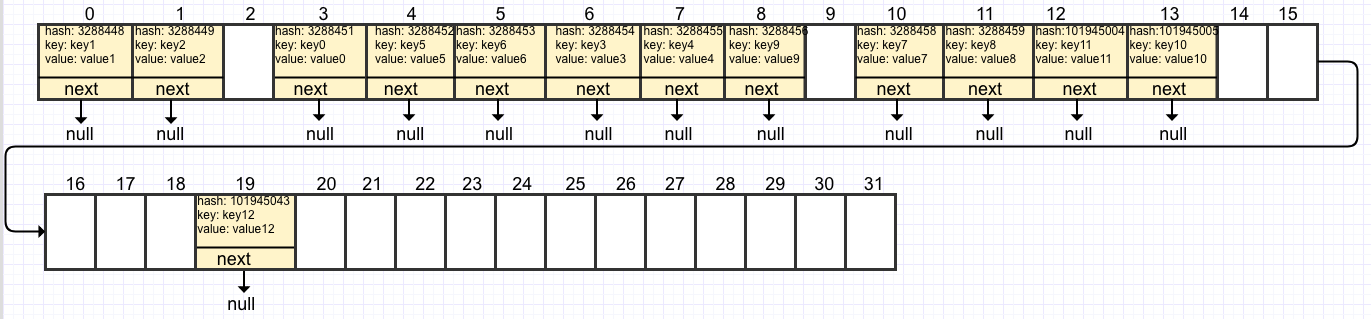
这时链表就派上用场了,HashMap就是通过链表解决哈希冲突的。 HashMap会创建一个新的Node,并放到table[3]链表的最后面。 此时table状态如下:

5.resize扩容
此时table中一共有13个元素,已经超过了threshold(12),需要对table调用resize方法扩容。 HashMap会创建一个容量为之前两倍(162=32)的table,并将旧的Node复制到新的table中,新的临界值(threshold)为24(320.75)。
下面主要介绍一下复制的过程(并不是原封不动的复制,Node的位置可能发生变化)
先来看源码:
for (int j = 0; j < oldCap; ++j) { // oldCap:旧table的大小 =16
Node<K,V> e;
if ((e = oldTab[j]) != null) { // oldTab:旧table的备份
oldTab[j] = null;
// 如果数组中的元素没有后继节点,直接计算新的索引值,并将Node放到新数组中
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 忽略这个else if。其实,如果链表的长度超过8,HashMap会把这个链表变成一个树结构,树结构中的元素是TreeNode
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// 有后继节点的情况
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
// 【说明1】
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
//【说明2】
newTab[j + oldCap] = hiHead;
}
}
}
}
【说明1】遍历链表,计算链表每一个节点在新table中的位置。
计算位置的方式如下:
1)如果节点的 (hash & oldCap) == 0,那么该节点还在原来的位置上,为什么呢?
因为oldCap=16,二进制的表现形式为0001 0000,任何数&16,如果等于0,那么这个数的第五个二进制位必然为0。
以当前状态来说,新的容量是32,那么table的最大index是31,31的二进制表现形式是00011111。 计算index的方式是 hash & (容量 - 1),也就是说,新index的计算方式为 hash & (32 - 1) 假设Node的hash = 01101011,那么
01101011
& 00011111
----------
00001011 = 11
2)下面再对比(hash & oldCap) != 0的情况
如果节点的(hash & oldCap) != 0,那么该节点的位置=旧index + 旧容量大小
假设Node的hash = 01111011,那么
01111011
& 00011111
----------
00011011 = 27
上一个例子的hash值01101011跟这个例子的hash值01111011只是在第5位二进制上不同,可以发现,这两个值在旧的table中,是在同一个index中的,如下:
01101011
& 00001111
----------
00001011 = 11
01111011
& 00001111
----------
00001011 = 11
由于扩容总是以2倍的方式进行,也就是:旧容量 << 1,这也就解释了【说明2】,当(hash & oldCap) != 0时,这个Node的新index = 旧index + 旧容量大小。
扩容后,table状态如下所示:
欢迎关注我的微信公众号

