

- 原文地址:Keep it Simple with the Strategy Design Pattern
- 原文作者:Chidume Nnamdi
- 译文出自:阿里云翻译小组
- 译文链接:github.com/dawn-plex/t…
- 译者:灵沼
- 校对者:也树,照天
使用策略设计模式来简化代码
面向对象编程是一种编程范式,这种范式围绕使用对象和类声明的方式来为我们的程序提供简单且可重用的设计。
根据维基百科:
“面向对象编程(OOP)是一种基于“对象”概念的编程范式,对象可能包含字段形式的数据,通常称为属性;还有程序形式的代码,通常称为方法。”
但 OOP 概念本身不是重点,如何构建你的类以及它们之间的关系才是重点所在。像大脑、城市、蚂蚁窝、建筑这种复杂的系统都充满了各种模式。为了实现稳定持久的状态,它们采用了结构良好的架构。软件开发也不例外。
设计一个大型应用需要对象和数据之间错综复杂的联系和协作。
OOP 为我们提供了这样做的设计,但是正如我之前所说,我们需要一个模式来达到一个持久稳定的状态。否则在我们的 OOP 设计应用里可能会出现问题导致代码腐烂。
因此,这些问题已经被记录归类,并且经验丰富的早期软件开发者已经描述了每类问题的优雅解决方案。这些方案就被称为设计模式。
迄今为止,已经有 24 种设计模式,如书中所描述的,设计模式:可复用面向对象软件的基础。这里每一种模式都为一个特定问题提供了一组解决方案。
在这篇文章里,我们将走进策略模式,去理解它怎样工作,在软件开发中,何时去应用它,如何去应用它。
提示:在 Bit 上可以更快地构建 JavaScript 应用。在这里可以轻松地共享项目和应用中的组件、与您的团队协作,并且使用它们就像使用Lego一样。这是一个改善模块化和大规模保持代码 DRY 的好方法。
策略模式:基本概念
策略模式是一种行为型设计模式,它封装了一系列算法,在运行时,从算法池中选择一个使用。算法是可交换的,这意味着它们可以互相替代。
策略模式是一种行为型模式,它可以在运行时选择算法 ——维基百科
关键的想法是创建代表各种策略的对象。这些对象会形成一个策略池,上下文对象可以根据策略进行选择来改变它的行为。这些对象(策略)功能相同、职责单一,并且共同组成策略模式的接口。
以我们已有的排序算法为例。排序算法有一组彼此特别的规则,来有效地对数字类型的数组进行排序。我们有一下的排序算法:
- 冒泡排序
- 顺序查找
- 堆排序
- 归并排序
- 选择排序
仅举几例。
然后,在我们的计划中,我们在执行期间同时需要几种不同的排序算法。使用策略模式允许我们队这些算法进行分组,并且在需要的时候可以从算法池中进行选择。
这更像一个插件,比如 Windows 中的 PlugnPlay 或者设备驱动程序。所有插件都必须遵循一种签名或规则。
举个例子,一个设备驱动程序可以是任何东西,电池驱动程序,磁盘驱动程序,键盘驱动程序......
它们必须实现:
NTSTATUS DriverEntry (_In_ PDRIVER_OBJECT ob, _In_ PUNICODE_STRING pstr) {
//...
}
VOID DriverUnload(PDRIVER_OBJECT DriverObject)
{
RtlFreeUnicodeString(&servkey);
}
NTSTATUS AddDevice(PDRIVER_OBJECT DriverObject, PDEVICE_OBJECT pdo)
{
return STATUS_SOMETHING; // e.g., STATUS_SUCCESS
}
每一个驱动程序必须实现上面的函数,操作系统使用 DriverEntry加载驱动程序,从内存中删除驱动程序时使用DriverUnload,AddDriver 用于将驱动程序添加到驱动程序列表中。
操作系统不需要知道你的驱动程序做了什么,它所知道的就是由于你称它为驱动程序,它会假设这些所有都存在,并在需要的时候调用它们。
如果我们把排序算法都集中在一个类中,我们会发现我们自己在编写条件语句来选择其中一个算法。
最重要的是,所有的策略必须有相同的签名。如果你使用面向对象语言,必须保证所有的策略都继承自一个通用接口,如果不是使用面向对象语言,比如 JavaScript,请保证所有的策略都有一个上下文环境可以调用的公共方法。
// In an OOP Language -
// TypeScript
// interface all sorting algorithms must implement
interface SortingStrategy {
sort(array);
}
// heap sort algorithm implementing the `SortingStrategy` interface, it implements its algorithm in the `sort` method
class HeapSort implements SortingStrategy {
sort() {
log("HeapSort algorithm")
// implementation here
}
}
// linear search sorting algorithm implementing the `SortingStrategy` interface, it implements its algorithm in the `sort` method
class LinearSearch implements SortingStrategy {
sort(array) {
log("LinearSearch algorithm")
// implementation here
}
}
class SortingProgram {
private sortingStrategy: SortingStrategy
constructor(array: Array<Number>) {
}
runSort(sortingStrategy: SortingStrategy) {
return this.sortingStrategy.sort(this.array)
}
}
// instantiate the `SortingProgram` with an array of numbers
const sortProgram = new SortingProgram([9,2,5,3,8,4,1,8,0,3])
// sort using heap sort
sortProgram.runSort(new HeapSort())
// sort using linear search
sortProgram.runSort(new LinearSearch())
SortingProgram 在它的 runSort 方法中,使用 SortingStrategy 作为参数,并调用了 sort 方法。SortingStrategy 的任何具体实现都必须实现 sort 方法。
您可以看到,SP 支持了 SOLID principles,并强制我们遵循它。SOLID 中的 D 表示我们必须依赖抽象,而不是具体实现。这就是 runSort 方法中发生的事情。还有 O,它表示实体应该是开放的,而不是扩展的。
如果我们采用了子类化作为排序算法的替代方案,会得到难以理解和维护的代码,因为我们会得到许多相关类,它们的差距只在于它们所拥有的算法。SOLID 中的 I,表示对于要实现的具体策略,我们有一个特定的接口。
这不是针对某一个特定工作虚构的,因为每一个排序算法都需要运用排序来排序:)。SOLID 中的 S,表示了实现该策略的所有类都只有一个排序工作。L 则表示了某一个策略的所有子类对于他们的父类都是可替换的。
架构
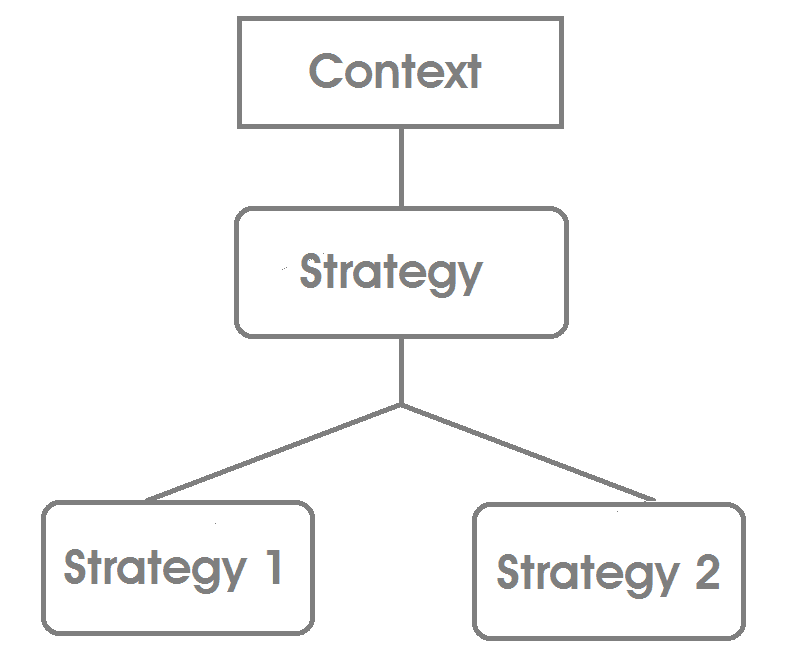
如上图所示,Context 类依赖于 Strategy。在执行或运行期间,Strategy 类型不同的策略被传递给 Context 类。Strategy 提供了策略必须实现的模板。
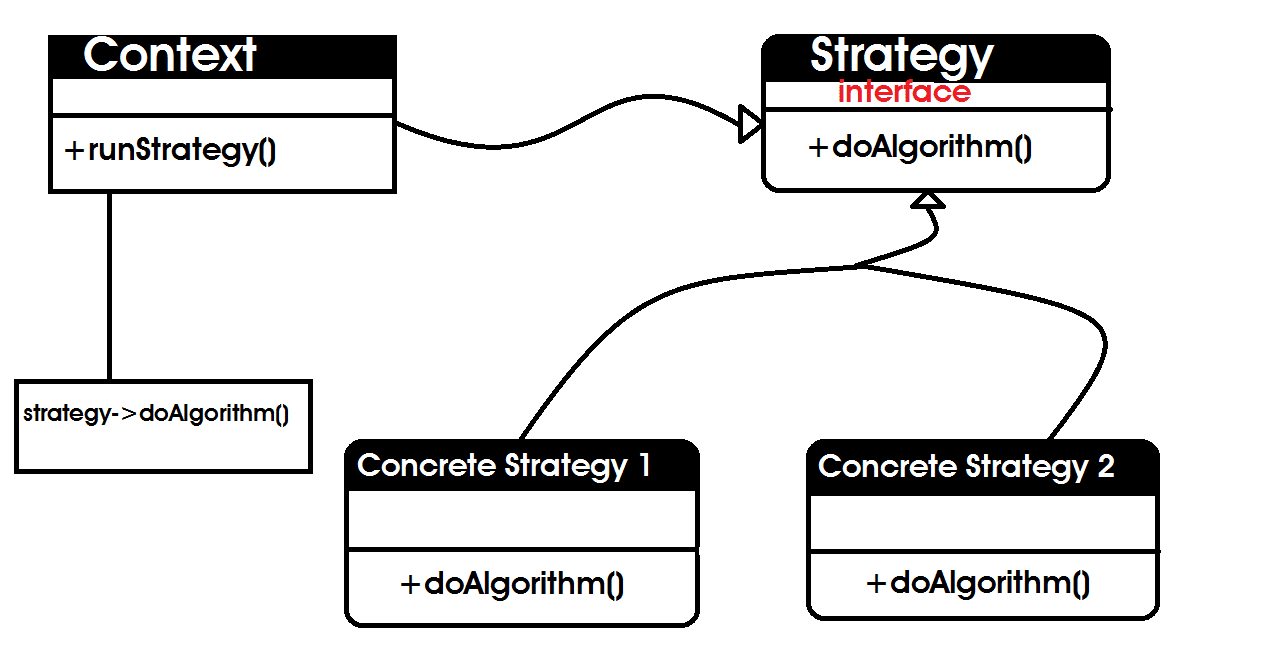
在上面的 UML 类图中,Concrete 类依赖于抽象,Strategy 接口。它没有直接实现算法。Context 从 runStrategy 方法中调用了 Strategy 传递来的 doAlgorithm。Context 类独立于 doAlgorithm 方法,它不知道也没必要知道 doAlgorithm 是如何实现的。根据 Design by Contract,实现 Strategy 接口的类必须实现 doAlgorithm 方法。
在策略设计模式中,这里有三个实体:Context、Strategy 和 ConcreteStrategy。
Context 是组成具体策略的主体,策略在这里发挥着它们各自的作用。
Strategy 是定义如何配置所有策略的模板。
ConcreteStrategy 是策略模板(接口)的实现。
示例
使用 Steve Fenton 的示例 Car Wash program,你知道洗车分不同的清洗等级,这取决于车主支付的金额,付的钱越多,清洗等级越高。让我们看一下提供的洗车服务:
- 基础车轮车身清洗
- 高档车轮车身清洗
基础车轮车身清洗仅仅是常规的清洗和冲洗和刷刷车身。
高档清洗就不仅仅是这些,他们会为车身和车轮上蜡,让整个车看起来光彩照人并提供擦干服务。清洗等级取决于车主支付的金额。一级清洗只给你提供基础清洗车身和车轮:
interface BodyCleaning {
clean(): void;
}
interface WheelCleaning {
clean(): void;
}
class BasicBodyCleaningFactory implements BodyCleaning {
clean() {
log("Soap Car")
log("Rinse Car")
}
}
class ExecutiveBodyCleaningFactory implements BodyCleaning {
clean() {
log("Wax Car")
log("Blow-Dry Car")
}
}
class BasicWheelCleaningFactory implements BodyCleaning {
clean() {
log("Soap Wheel")
log("Rinse wheel")
}
}
class ExecutiveWheelCleaningFactory implements BodyCleaning {
clean() {
log("Brush Wheel")
log("Dry Wheel")
}
}
class CarWash {
washCar(washLevel: Number) {
switch(washLevel) {
case 1:
new BasicBodyCleaningFactory().clean()
new BasicWheelCleaningFactory().clean()
break;
case 2:
new BasicBodyCleaningFactory().clean()
new ExecutiveWheelCleaningFactory().clean()
break;
case 3:
new ExecutiveBodyCleaningFactory().clean()
new ExecutiveWheelCleaningFactory().clean()
break;
}
}
}
现在你看到了,一些模式出现了。我们在许多不同的条件下重复使用相同的类,这些类都相关但是在行为上不同。此外,我们的代码变得杂乱且繁重。
更重要的是,我们的程序违反了 S.O.L.I.D 的开闭原则,开闭原则指出模块应该对 extension 开放而不是 modification。
对于每一个新的清洗等级,就会新增另一个条件,这就是 modification。
使用策略模式,我们必须解除洗车程序与清洗等级的耦合关系。
要做到这一点,我们必须分离清洗操作。首先,我们创建一个接口,所有的操作都必须实现它:
interface ValetFaactory {
getWheelCleaning();
getBodyCleaning();
}
所有的清洗策略:
class BronzeWashFactory implements ValetFactory {
getWheelCleaning() {
return new BasicWheelCleaning();
}
getBodyCleaning() {
return new BasicBodyCleaning();
}
}
class SilverWashFactory implements ValetFactory {
getWheelCleaning() {
return new BasicWheelCleaning();
}
getBodyCleaning() {
return new ExecutiveBodyCleaning();
}
}
class GoldWashFactory implements ValetFactory {
getWheelCleaning() {
return new ExecutiveWheelCleaning();
}
getBodyCleaning() {
return new ExecutiveBodyCleaning();
}
}
接下来,我们开始改造 CarWashProgram:
// ...
class CarWashProgram {
constructor(private cleaningFactory: ValetFactory) {
}
runWash() {
const wheelWash = this.cleaningFactory.getWheelCleaning();
wheelWash.cleanWheels();
const bodyWash = this.cleaningFactory.getBodyCleaning();
bodyWash.cleanBody();
}
}
现在,我们把所有所需的清洗策略传递给 CarWashProgram 中,
// ...
const carWash = new CarWashProgram(new GoldWashFactory())
carWash.runWash()
const carWash = new CarWashProgram(new BronzeWashFactory())
carWash.runWash()
另一个示例:认证策略
假设我们有一个软件,我们为了安全想为它添加一个身份认证。我们有不同的身份验证方案和策略:
- Basic
- Digest
- OpenID
- OAuth
我们也许会试着像下面一样实现:
class BasicAuth {}
class DigestAuth {}
class OpenIDAuth {}
class OAuth {}
class AuthProgram {
runProgram(authStrategy:any, ...) {
this.authenticate(authStrategy)
// ...
}
authenticate(authStrategy:any) {
switch(authStrategy) {
if(authStrategy == "basic")
useBasic()
if(authStrategy == "digest")
useDigest()
if(authStrategy == "openid")
useOpenID()
if(authStrategy == "oauth")
useOAuth()
}
}
}
同样的,又是一长串的条件。此外,如果我们想认证。对于我们程序中特定的路由,我们会发现我们面对相同的情况。
class AuthProgram {
route(path:string, authStyle: any) {
this.authenticate(authStyle)
// ...
}
}
如果我们在这里应用策略设计模式,我们将创建一个所有认证策略都必须实现的接口:
interface AuthStrategy {
auth(): void;
}
class Auth0 implements AuthStrategy {
auth() {
log('Authenticating using Auth0 Strategy')
}
}
class Basic implements AuthStrategy {
auth() {
log('Authenticating using Basic Strategy')
}
}
class OpenID implements AuthStrategy {
auth() {
log('Authenticating using OpenID Strategy')
}
}
AuthStrategy 定义所有策略都必须构建于之上的模板。任何具体认证策略都必须实现这个认证方法,来为我们提供身份认证的方式。我们有 Auth0、Basic 和 OpenID 这几个具体策略。
接下来,我们需要对 AuthProgram 类进行改造:
// ...
class AuthProgram {
private _strategy: AuthStrategy
use(strategy: AuthStrategy) {
this._strategy = strategy
return this
}
authenticate() {
if(this._strategy == null) {
log("No Authentication Strategy set.")
}
this._strategy.auth()
}
route(path: string, strategy: AuthStrategy) {
this._strategy = strategy
this.authenticate()
return this
}
}
现在可以看到,authenticate 方法不再包含一长串的 switch case 语句。use 方法设置要使用的身份验证策略,authenticate 只需要调用 auth 方法。它不关心 AuthStrategy 如何实现的身份认证。
log(new AuthProgram().use(new OpenID()).authenticate())
// Authenticating using OpenID Strategy
策略模式:解决了什么问题
策略模式可以防止将所有算法都硬编码到程序中。硬编码的方式使得我们的程序复杂且难以维护和理解。
反过来,硬编码的方式进而让我们的程序包含一些从来不用的算法。
假设我们有一个 Printer 类,可以打印不同的风格和特色。如果我们在 Printer 类中包含所有的风格和特色:
class Document {...}
class Printer {
print(doc: Document, printStyle: Number) {
if(printStyle == 0 /* color printing*/) {
// ...
}
if(printStyle == 1 /* black and white printing*/) {
// ...
}
if(printStyle == 2 /* sepia color printing*/) {
// ...
}
if(printStyle == 3 /* hue color printing*/) {
// ...
}
if(printStyle == 4 /* oil printing*/) {
// ...
}
// ...
}
}
或者
class Document {...}
class Printer {
print(doc: Document, printStyle: Number) {
switch(printStyle) {
case 0 /* color priniting strategy*/:
ColorPrinting()
break;
case 0 /* color priniting strategy*/:
InvertedColorPrinting()
break;
// ...
}
// ...
}
}
看吧,我们最后得到了一个不正宗的类,这个类有太多条件了,是不可读、不可维护的。
但是应用策略模式的话,我们将打印方式分解为不同的任务。
class Document {...}
interface PrintingStrategy {
printStrategy(d: Document): void;
}
class ColorPrintingStrategy implements PrintingStrategy {
printStrategy(doc: Document) {
log("Color Printing")
// ...
}
}
class InvertedColorPrintingStrategy implements PrintingStrategy {
printStrategy(doc: Document) {
log("Inverted Color Printing")
// ...
}
}
class Printer {
private printingStrategy: PrintingStrategy
print(doc: Document) {
this.printingStrategy.printStrategy(doc)
}
}
因此,每个条件都转移到了一个单独的策略类中,而不是一大串条件。对 Printer 类来说,它没有必要知道不同打印方式是怎么实现的。
策略模式和 SOLID 原则
在策略模式中,组合通常优于继承。它建议对抽象进行编程而不是对实体编程。你会看到策略模式与 SOLID 原则的完美结合。
例如,我们有一个 DoorProgram,它有不同的锁定机制来锁门。由于不同的锁定机制在门的子类之间可以改变。我们也许会试图像下面这样来应用门的锁定机制到 Door 类:
class Door {
open() {
log('Opening Door')
// ...
}
lock() {
log('Locking Door')
}
lockingMechanism() {
// card swipe
// thumbprint
// padlock
// bolt
// retina scanner
// password
}
}
只看起来还不错,但是每个门的行为不同。每个门都有自己的锁定和开门机制。这是不同的行为。
当我们创建不同的门:
// ...
class TimedDoor extends Door {
open() {
super.open()
}
}
并且尝试为它实现打开/锁定机制,你会发现我们在实现它自己的打开/锁定机制之前,必须调用父类的方法。
如果我们像下面一样创建了一个接口 Door:
interface Door {
open()
lock()
}
你会看到必须在每个类或模型或 Door 类型的类中声明打开/锁定的行为。
class GlassDoor implements Door {
open() {
// ...
}
lock() {
// ...
}
}
这很不错,但是随着应用程序的增长,这里会暴露许多弊端。一个 Door 模型必须有一个打开/锁定机制。一个门必须能打开/关闭吗?不是的。一扇门也许根本就不必关上。所以会发现我们的 Door 模型将会被强制设置打开/锁定机制。
接下来,接口不会对接口作为模型使用和作为打开/锁定机制使用做区分。注意:在 S in SOLID 中,一个类必须拥有一个能力。
玻璃门必须具有作为玻璃门的唯一特征,木门、金属门、陶瓷门也是同样的。另外的类应该负责打开/锁定机制。
使用策略模式,我们将我们相关的东西都分开,在这个例子中,就是将打开/锁定机制分开。进入类中,然后在运行期间,我们为 Door 模型传递它所需要使用的锁定/打开机制。Door 模型能够从锁定/打开策略池中选择一个锁定/打开装置来使用。
interface LockOpenStrategy {
open();
lock();
}
class RetinaScannerLockOpenStrategy implements LockOpenStrategy {
open() {
//...
}
lock() {
//...
}
}
class KeypadLockOpenStrategy implements LockOpenStrategy {
open() {
if(password != "nnamdi_chidume"){
log("Entry Denied")
return
}
//...
}
lock() {
//...
}
}
abstract class Door {
public lockOpenStrategy: LockOpenStrategy
}
class GlassDoor extends Door {}
class MetalDoor extends Door {}
class DoorAdapter {
openDoor(d: Door) {
d.lockOpenStrategy.open()
}
}
const glassDoor = new GlassDoor()
glassDoor.lockOpenStrategy = new RetinaScannerLockOpenStrategy();
const metalDoor = new MetalDoor()
metalDoor.lockOpenStrategy = new KeypadLockOpenStrategy();
new DoorAdapter().openDoor(glassDoor)
new DoorAdapter().openDoor(metalDoor)
每一个打开/锁定策略都在一个继承自基础接口的类中定义。策略模式支持这一点,因为面向接口编程可以实现高内聚性。
接下来,我们会有 Door 模型,每个 Door 模型都是 Door 类的一个子类。我们有一个 DoorAdapter ,它的工作就是打开传递给它的门。我们创建了一些 Door 模型的对象,并且设置了它们的锁定/打开策略。玻璃门通过视网膜扫描来进行锁定/打开,金属门有一个输入密码的键盘。
我们在这里关注的分离,是相关行为的分离。每个 Door 模型不知道也不关心一个具体锁定/打开策略的实现,这个问题由另一个实体来关注。我们按照策略模式的要求面向接口编程,因为这使得在运行期间切换策略变得很容易。
这可能不会持续很久,但是这是一种经由策略模式提供的更好的方式。
一扇门也许会有很多锁定/打开策略,并且可能会在锁定和打开运行期间使用到一个或多个策略。无论如何,你一定要在脑海中记住策略模式。
JavaScript 中的策略模式
我们的大部分示例都是基于面向对象编程语言。JavaScript 不是静态类型而是动态类型。所以在 JavaScript 中没有像 接口、多态、封装、委托这样的面向对象编程的概念。但是在策略模式中,我们可以假设他们存在,我们可以模拟它们。
让我们用我们的第一个示例来示范如何在 JavaScript 中应用策略模式。
第一个示例是基于排序算法的。现在,SortingStrategy 接口有一个 sort 方法,所有实现的策略都必须定义。SortingProgram类将SortingStrategy 作为参数传递给它的runSort方法,并且调用了sort` 方法。
我们对排序算法进行建模:
var HeapSort = function() {
this.sort(array) {
log("HeapSort algorithm")
// implementation here
}
}
// linear search sorting algorithm implementing its alogrithm in the `sort` method
var LinearSearch = function() {
this.sort(array) {
log("LinearSearch algorithm")
// implementation here
}
}
class SortingProgram {
constructor(array) {
this.array=array
}
runSort(sortingStrategy) {
return sortingStrategy.sort(this.array)
}
}
// instantiate the `SortingProgram` with an array of numbers
const sortProgram = new SortingProgram([9,2,5,3,8,4,1,8,0,3])
// sort using heap sort
sortProgram.runSort(new HeapSort())
// sort using linear search
sortProgram.runSort(new LinearSearch())
这里没有接口,但我们实现了。可能会有一个更好更健壮的方法,但是对现在来说,这已经足够了。
这里我想的是,对于我们想要实现的每一个排序策略,都必须有一个排序方法。
策略模式:使用的时机
当你开始注意到反复出现的算法,但是又互相有不同的时候,就是策略模式使用的时机了。通过这种方式,你需要将算法拆分成不同的类,并按需提供给程序。
然后就是,如果你注意到在相关算法中反复出现条件语句。
当你的大部分类都有相关的行为。是时候将它们拆分到各种类中了。
优势
- 关注点分离:相关的行为和算法会被拆分到类和策略中。
- 由于面向接口编程,在运行期间切换策略是一件很容易的事情。
- 消除不正宗的代码和受条件侵蚀的代码
- 可维护的和可重构的
- 选择要使用的算法
结论
策略模式是许多软件开发设计模式的其中一种。在本文中,我们看到了许多关于如何使用策略模式的示例,然后,我们看到了它的优势和弊端。
记住了,你不必按照描述来实现一个设计模式。你需要完全理解它并知道应用它的时机。如果你不理解它,不要担心,多次使用它以加深理解。随着时间的推移,你会掌握它的窍门,最后,你会领略到它的好处。
接下来,在我们的系列中,我们将会研究 模板方法设计模式,请继续关注:)
如果你对此有任何疑问,或者我还应该做些补充、订正、删除,请随时发表评论、邮件或 DM me。感谢阅读!👏
