

写在译前:首先介绍一下我自己,一个跨行业的、完全非科班生的文科单身狗。因为生计,走上了自学前端的荆棘之路,然后经过一路的摸爬打滚终于算是入了前端的这个门,自己也知道在前端这条道路上还有很长的路要走。平常生活中喜欢跑步,欢迎有同样爱好的大佬一起交流切磋。
这篇译文是在掘金Limin组织的2019年度开发者写作计划下开始的,旨在通过平时的学习,将自己所学的知识通过一个归纳总结,得以提高自己的前端技能水平。很感谢Limin推荐的这篇文章。
由于全文篇幅太长,无法将所有内容一次性发布完,所以计划分成上、中、下三个篇章。上篇包括( 计划和度量、制定现实的目标 和 定义环境 ),中篇包括( 资源优化、构建优化 和 交付优化 ),下篇包括( HTTP / 2、测试和监测 和 速效方案 )。
原文链接地址:Front-End Performance Checklist 2019
原文作者:Vitaly Friedman
译者:单车 runner
这是一篇有关年度前端性能优化的文章,包含了创建快速体验所需的所有知识,自2016年以来每年更新一次。
Web 性能在前端领域是一个棘手的问题,所以,知道我们在性能方面处于什么位置,以及我们的性能瓶颈究竟是什么就显得更为重要了。它是昂贵的 JavaScript 呢、 还是缓慢的 web 字体传递、 或是较大的图片在使得页面加载速度变缓? web 性能优化包括:无用代码移除 (Tree-shaking)、作用域提升(Scope hoisting)、代码分割(Code-spliting),交叉观察器(Intersection observer)、服务器推送(server push)、客户端提示(clients hints)、HTTP/2、service workers 等等这些手段。然而,最重要的是,我们该 从哪里开始提高前端性能 以及 如何建立长久的前端性能优化机制?
之前,我们习惯性在完成项目之后,再去考虑前端方面的性能优化。这样就会导致留给我们优化的时间极度有限,让我们不得不缩小优化考虑的范围。通常我们优化的内容也局限于资源优化(一些静态文件的缩小)和服务器配置文件上的一些细微调整。现在回过来看,前端发展越来越快,涉及面越来越广,性能优化光做到这些还是远远不够的。
性能不仅仅是一个技术问题:它很重要,所以当将其放入工作流中时,我们必须根据性能的影响来做设计决策。性能必须被测量、监测和不断的完善。网络日益增长的复杂性也使得前端性能指标的跟踪变得越来越难,因为性能指标会根据设备、浏览器、协议、网络类型和延迟而发生改变(CDN、ISP、缓存、代理、防火墙、负载均衡器和服务器都在性能方面发挥作用)。
因此,我们创建了一个在提高性能时必须记住的所有事情的概述:即从网站的最开始准备阶段到网站的最终发布需要注意的性能问题列表。以下是2019年的前端性能优化清单(希望没有偏见和客观)—— 更新了您可能需要考虑的问题,以确保您的网站响应时间更快,用户交互更加流畅,不会占用用户的带宽。
(您也可以仅下载 前端性能优化清单的 PDF 版本(166 kb)或者 下载 Apple Pages 版本(275 kb)或者是 .docx 文件 (151 kb)。祝愿大家,在前端性能优化这条路上走的越来越顺畅!!!)
目录
准备:计划和度量
微优化对于保持性能的正常运行非常重要,所以在我们必须把明确的目标时刻印记在脑海中。明确的目标应该是可以度量,因为他可以影响整个过程中所做的任何决策。这里有几种不同的模式,我们需要从自身的角度出发,尽早确认自己项目中性能优化的优先级别。
1. 建立性能优化意识
在很多技术团队中,前端开发人员确切地知道什么是常见的底层问题,以及应该使用什么加载模式来修复这些问题。然而,只要没有对性能优化的意见达成一致,每个部门就会按照自己的理解来定位产品,这样一个公司就会变成一盘散沙。这时候,需要让相关人员都参与进来, 然后建立一个调查问卷,调查大家所关心的速度效益指标和关键性能指标( kpi )。
如果开发/设计部与业务部之间的意见还没有达成一致,那么性能优化将无法开展。研究用户在体验产品之后的反馈,看看如何提高性能以助于解决这些常见问题。
在移动设备和桌面设备上运行性能实验并测量结果,得到的真实的数据将帮助你建立一个为公司量身定制的案例研究。此外,使用 WPO Stats 上发布的案例研究和实验数据,可以帮助提高你对性能和业务之间的潜在关系的认识,以及性能对用户体验和业务度量的影响。仅仅说明性能很重要是不够的,您还需要建立一些可度量的、可跟踪的目标来观测性能。
Allison McKnight 在她关于 构建长期性能优化 的演讲中分享了她如何帮助 Etsy 建立性能优化的全面案例研究。

2. 目标:要比你最快的竞争对手快至少 20%
根据心理学研究,如果你想让用户觉得你的网站比竞争对手的网站快,你需要至少快20%。研究你的主要竞争者,收集他们在移动端和桌面上的性能,并且设置一个你能超过他们的临界值。要获取准确的结果和目标,首先要研究你的分析结果,看看你的用户都在做什么。然后,您可以模拟第90个百分位的测试经验。
为了更好地了解竞争对手的表现,您可以使用 Chrome UX报告( CrUX,现成的 RUM 数据集,Ilya Grigorik 的 视频介绍),Speed Scorecard(也提供收入影响估算器), 真实用户体验测试比较 或 SiteSpeed CI(基于综合测试)。
注意:如果使用 Page Speed Insights(不推荐使用),则可以获取特定页面的 CrUX 性能数据,而不仅仅是聚合。此数据对于设置 目标网页 或 产品详情 等资产的效果目标非常有用。如果您使用 CI 来测试预算 以及 CrUX 设置目标,则需要确保您的测试环境与 CrUX 匹配(感谢 Patrick Meenan!)。
收集数据之后,建立一个电子表格,将数据结果减去 20% 就是你的目标(即 性能预算)。现在,你在测试之前就有了一些可度量的数据。在这个数据(性能预算)的前提下,尝试使用最少的脚本来实现最快的交互,这样子我们就算是达成了自己的目标。
启动所需要的资源:
- Addy Osmani 写了一篇关于如何开始性能预算、如何量化新特性的影响以及在超出预算时从何处开始的非常详细的文章。
- Lara Hogan 关于如何使用性能预算进行设计 的指南可以为设计师提供有用的指导。
- Jonathan Fielding 的 性能预算计算器、Brad Frost 的 性能预算构建器 和浏览器卡路里 可以帮助创建预算(感谢 Karolina Szczur 的领导)。
- 此外,通过使用报告构建大小的图表设置仪表板,可以使性能预算和当前性能可见。有许多工具可以帮助您实现这一目标:SiteSpeed.io 仪表板(开源),SpeedCurve 和 Calibre 只是其中的一部分,您可以在 perf.rocks 上找到更多工具。
准备好预算后,使用 Webpack Performance Hints 和 Bundlesize,Lightouse CI,PWMetrics 或 Sitespeed CI 将它们合并到构建过程中,以强制执行拉取请求的预算并在PR注释中提供分数历史记录。如果你需要自定义的东西,你可以使用 webpagetest-charts-api,一个端点 API 来自 WebPagetest 结果构建图表。
例如,就像 Pinterest 一样,您可以创建一个自定义的 eslint 规则,该规则禁止从已知属于依赖性的文件和目录中导入并使该捆绑包膨胀。设置可在整个团队中共享的 安全 软件包列表。
除了性能预算之外,还要考虑对您的业务最有利的关键客户任务。设置并讨论 关键操作的 可接受 时间阈值,并建立整个组织已达成一致的 UX就绪 用户时间标记。在许多情况下,用户旅程将涉及许多不同部门的工作,因此在可接受的时间安排方面的协调将有助于支持或阻止绩效讨论。确保可以看到和理解添加的资源和功能的额外成本。
此外,正如 Patrick Meenan 所建议的那样,最好在设计的过程中设置一个加载队列并且要知道这些顺序会存在哪些利弊。您需要优先处理更重要的优先级,并定义它们应该出现的顺序,那么您就可以确定哪一部分可以延迟。通常理想情况下,该队列也反映 CSS 和 JavaScript 导入的顺序,因此在构建过程中处理它们会更容易。此外,在加载页面时(例如,当尚未加载 Web 字体时),考虑视觉体验应该在 中间 状态中。
规划、计划、规划,重要的事情说三遍。如果早期进行优化那么会很容易实现目标,但是没有计划或者没有制定切合实际的、为公司量身定制的业绩目标,那么就很难保持性能。
3. 选择正确的指标
不是所有的度量都很重要。研究哪些度量对于你的应用程序最重要:通常,这与你能够以多快的速度开始渲染最重要的像素(以及它们的效果)以及如何为这些渲染像素提供输入最快的响应速度有关。 这可以帮助你为后续的工作提供最佳的优化结果。
不管怎样,不要专注于整个页面的加载时间(例如 onLoad 和 DOMContentLoaded 时间),而是要优先按照用户可以感知到的页面加载。 也就是说要关注一组稍微不同的度量。
根据 Tim Kadlec 的研究和 Marcos Iglesias 在他的 演讲 中所做的笔记,传统的度量指标可以分为几种。通常情况下,我们在全面了解性能的时候可能需要用到所有的这些方法,但是,也有可能在自己实际的项目当中,其中的某一种方法比其他方法更为重要。
这里挑出一些相对更为重要的方法:
- 基数度量标准( Quantity-based metrics )主要是用来衡量请求数量,权重和性能的得分。适用于一些提高警报或者监控随着时间的变化而改变的项目,但是对于用户体验不是很友好。
- 里程碑度量标准(M ilestone metrics )指的是项目在加载过程中,项目在某个生命周期中一个使用状态,例如:到某个生命节点所需要的时间,或者是完成某个交互所需要的时间。虽然这个度量标准不会记录两个不同生命周期之间发生的事情,但是却适合用来监控和描述用户的体验。
- 渲染度量标准( Rendering metrics )是用来预估页面内容呈现的速度。适合用于测量和调整渲染性能,但不适合用来测量重要内容在什么时间节点出现并可与之进行交互。
- 自定义度量标准( Custom metrics ) 是用来衡量项目的特定自定义事件。例如 Twitter 的 Time To First Tweet 和 Pinterest 的 PinnerWaitTime。适合用于精确的描述用户的体验,不太适合根据这个标准来和对手进行比较。
下面罗列一些最具体和相关的的度量标准:
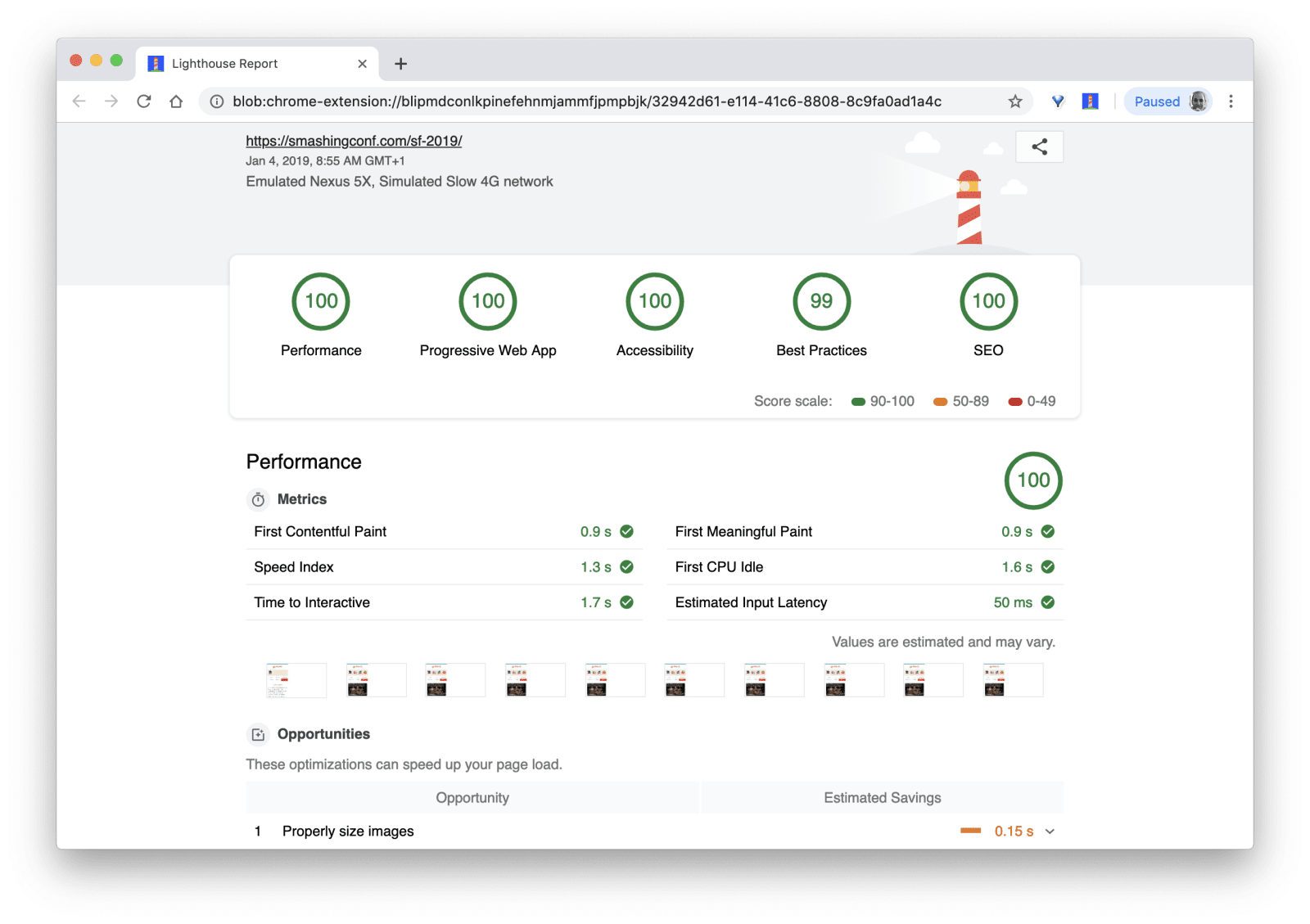
- 首次有效渲染时间 -- First Meaningful Paint ( FMP )指的是主要内容出现在页面上的时间,让您深入了解服务器输出任何数据的速度。Long FMP 大部分表示 JavaScript 阻塞了主线程,当然也可能是后端或者服务器的问题导致的。
- 交互时间 ( TTI )是指页面布局已经稳定,关键的页面字体已经可见,主进程足以去处理用户的输入 —— 用户可以在 UI 上进行点击和交互的基本时间标记。用来了解用户在没有延迟的情况下打开网站需要多长的时间。
- 输入响应 ( FID )即接口响应用户在实现交互操作所需的时间。
- 速度指数 -- Speed Index 测量页面内容在视觉上的填充速度,得分越低越好。速度指数得分是根据视觉进度的速度计算的,它只是一个计算值,对于视觉窗口大小很敏感,所以您需要定义一个与大众相匹配的测试标准(感谢,Boris!)。
- CPU时间花费 指的是 CPU 时间一个度量,指示主线程处理有效负载的繁忙程度。它显示了主线程被阻止的频率和持续时间,用于绘制,渲染,编写脚本和加载。根据 janky 的经验,高 CPU 时间即表示用户遇到他们的行动和反应之间存在明显的滞后。使用 WebPageTest,您可以 在 Chrome 选项卡上选择 Capture Dev Tools Timeline,以显示主线程使用 WebPageTest 在任何设备上运行时的详细分数。
- 广告权重影响 如果您的网站主要收入来源于广告,那么与广告业务模块的代码就要特别关注。Paddy Ganti 的 脚本 构造了两个URL(一个是正常的 URL,一个阻止广告的 URL),提示通过 WebPageTest 生成视频比较并报告增量。
- 偏差度量标准 一个仪器的测量结果的数据可以让我们知道这个仪器的可靠性,同理,我们可以通过测试的出来的数据结果分析,然后做出一个平衡。数据结果中,差异很大的标准需要重新设置,并且他还有助于我们了解某些页面是否会因为某些其他原因(例如第三方脚本)而导致更难以可靠地测量。另外,在推出新的浏览器版本时,对比新版本与旧版本在性能上的差异也是度量偏差的一个好方法。
- 自定义度量标准 即由您的业务需求和客户体验来定义。它要求您解析重要像素,关键脚本,必要的 CSS 和其他的相关资源,并预测页面展现在用户视觉下的速度。对于这个标准,您可以监视 Hero渲染时间,或使用 Performance API,为业务中很重要的事件标记一个时间戳。此外,您可以通过在测试结束时执行任意 JavaScript,然后通过结果对照 WebPagetest 确定自定义指标。
Steve Souders 详细的解释了每个度量。在许多情况下,我们测量出的数据是在特定环境下的使用程序得出的数据,但是输入响应代表的是用户的实际体验,实际当中,用户的体验要明显滞后。所以,保持持续测量和收集用户行为对于度量的制定相对来说更准确。
根据应用程序的上下文,首选度量可能会有所不同:例如,对于 Netflix TV UI:输入响应,内存使用 和 TTI 更为关键,对于维基百科,第一个/最后一个视觉更改和CPU时间花费度量更为重要。
注意:FID 和 TTI 都不考虑滚动行为; 滚动可以独立发生,因为它是非主线程,因此对于许多内容消费网站而言,这些指标可能相对于没有那么重要。
4. 从具有代表性的用户使用的设备收集数据
为了收集准确的数据,我们需要尽可能全的选择要测试的设备。最好是 Moto G4,或者一款中档的三星设备又或者是一个 Nexus 5X 这样的普通的设备。如果你手边没有设备,可以使用节流 CPU(5× 减速)来限制网速(例如,150 ms 的往返时延,1.5 Mbps 以下和0.7 Mbps 以上)实现在桌面设备上模拟移动设备的体验。最终,切换到常规的 3G,4G 和 Wi-Fi。为了使性能体验的影响更明显,你甚至可以使用 2G 或 一个节流的 3G 网络,以便进行更快的测试。

幸运的是,有很多优秀的选项可以帮助你自动收集数据,并根据这些度量衡量你的网站在一段时间内的性能。 请记住,良好的性能度量是需要被动和主动监控工具的组合:
- 被动监测工具,可以根据请求来模拟用户交互(综合测试,如Lighthouse,WebPageTest)
- **主动监测工具,**是那些不断记录和评价用户交互行为的(真正的用户监控,如 SpeedCurve,New Relic —— 这两种工具也提供综合测试)
前者在开发过程中特别有用,因为它可以在使用产品时持续跟踪。 后者在长期维护非常有用,因为它可以帮助你了解在实际访问站点时发生的性能瓶颈。
通过使用 导航定时、资源定时、绘图定时、长时间任务 等内置的 RUM API,被动和主动性能监视工具一起提供应用程序性能的完整画面。 例如,你可以使用 PWMetrics,Calibre,SpeedCurve,mPulse,Boomerang 和 Sitespeed.io,这些都是性能监测工具的绝佳选择。
注意:选择浏览器外部的网络级别的限制器总是比较安全的,例如 DevTools 由于实现的方式而存在与 HTTP/2 推送交互的问题(感谢 Yoav,Patrick!)。对于 Mac OS,我们可以使用 Network Link Conditioner,Windows 可以使用 Windows Traffic Shaper,Linux 可以使用 netem, FreeBSD 可以使用 dummynet。
5. 设置干净的用户配置文件以进行测试
在监视工具中测试时,需要关闭防病毒和后台 CPU 任务,删除后台带宽传输以及使用干净的用户配置文件。我们需要注意的是,防止使用浏览器( Firefox,Chrome )扩展而导致结果出现偏差。
有时候,研究客户经常使用的扩展程序以及使用专用的客户配置文件进行测试也是一个好办法。在实际应用当中,如果您的用户经常使用它们,您可能需要优先考虑到它,因为某些扩展可能会对您的应用程序 产生很大的性能影响。我们对于 干净 的个人资料结果过于乐观,因为在实际的用户应用场景中可能会被粉碎。
6. 与同事分享性能清单
为了避免误解,要确保你团队里的每个同事都对清单很熟悉。每个决策都对性能有影响。项目将极大地受益于前端开发人员正确地将性能价值传达给整个团队。从而使每个人都对它负责,而不仅仅是前端开发人员。根据绩效预算和清单中定义的优先顺序来设计决策。
制定现实的目标
7. 响应时间控制在 100ms,帧速控制在 60帧/秒
为了让交互感觉起来很顺畅,接口有 100ms 来响应用户的输入。任何比这更长的时间,都会让用户感觉到应用程序很慢。 RAIL,一个以用户为中心的性能模型 会为你设立一个正确的目标:要达到 < 100ms 响应时间的目标,页面必须要在小于 50ms 前最迟将控制权返回给主线程。预计输入延迟 时间告诉我们,如果我们能达到这个门槛,那么在理想情况下,它应该低于 50ms。对于像动画这样性能消耗比较大的地方,最好的做法是,在能够优化的地方,尽量优化到极致;在不能优化的地方,让性能开销降至最低。
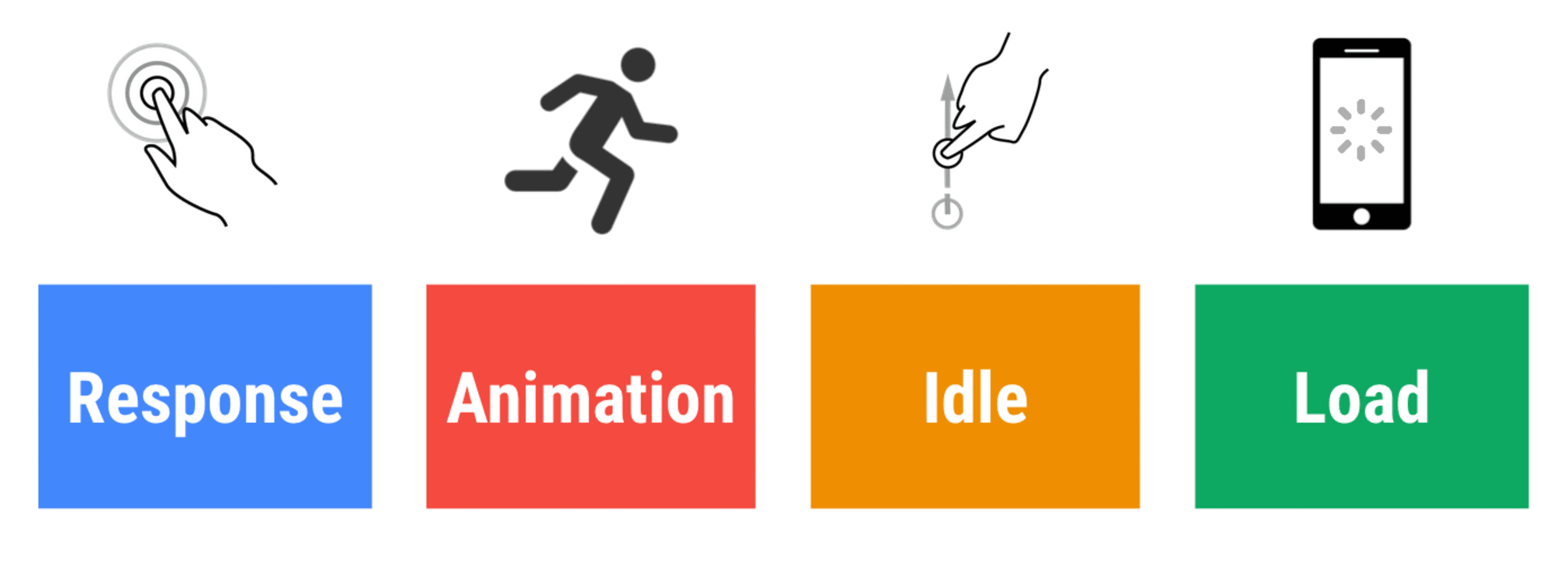
同时,每一帧动画应该要在 16 毫秒内完成,从而达到 60 帧每秒(1秒 ÷ 60 = 16.6 毫秒) —— 最好可以在 10 毫秒完成。因为浏览器需要时间将新框架绘制到屏幕上,你的代码应该在触发 16.6 毫秒以内完成。在页面设计上保持乐观 和 明智地利用空闲时间。显然,这些目标适用于运行时的性能,而不是加载性能。
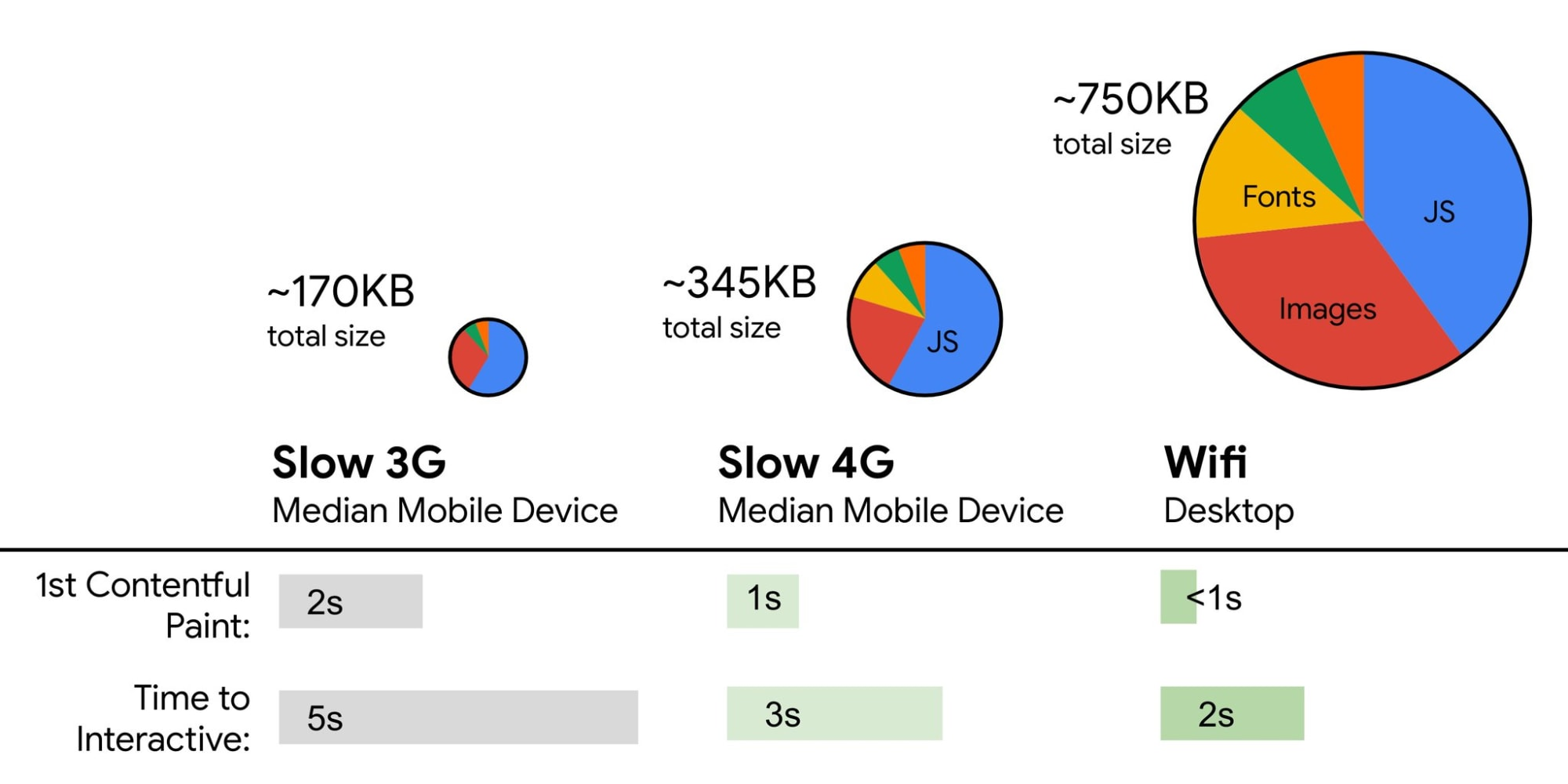
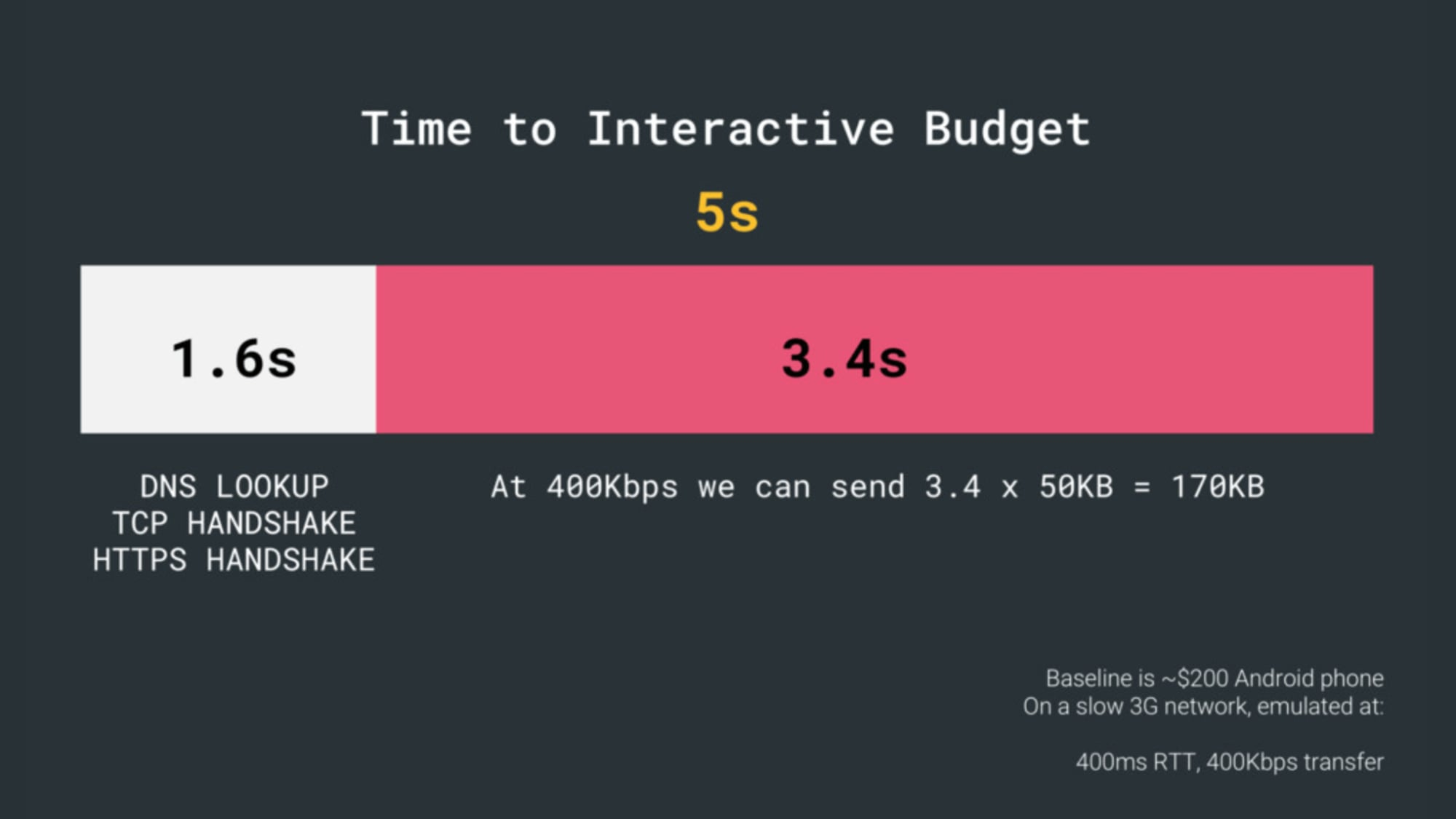
8. 速度指标(SpeedIndex) < 1250,3G上的交互时间(Interaction time)小于5s,关键文件大小预算 < 170 Kb(gzip)
虽然这可能很难实现,一个好的最终目标是首次有效渲染低于 1s 并且 SpeedIndex 的值低于 1250。因为我们是以 200 美金为基准的 Android 手机(如 Moto G4)和一个缓慢的 3G 网络上,模拟 400ms 的往返延时和 400kb 的传输速度,所以我们的目标是 可交互时间低于5s,并且再次访问的时间低于 2s。
请注意,当谈到可交互时间时,最好来 区分一下首次交互(First CPU Idle)和 连续交互(Time To Interactive) 以避免对它们之间的误解。前者是在主要内容已经渲染出来后最早出现的点(窗口至少需要 5s,页面才开始响应)。后者是期望页面可以一直进行输入响应的点。
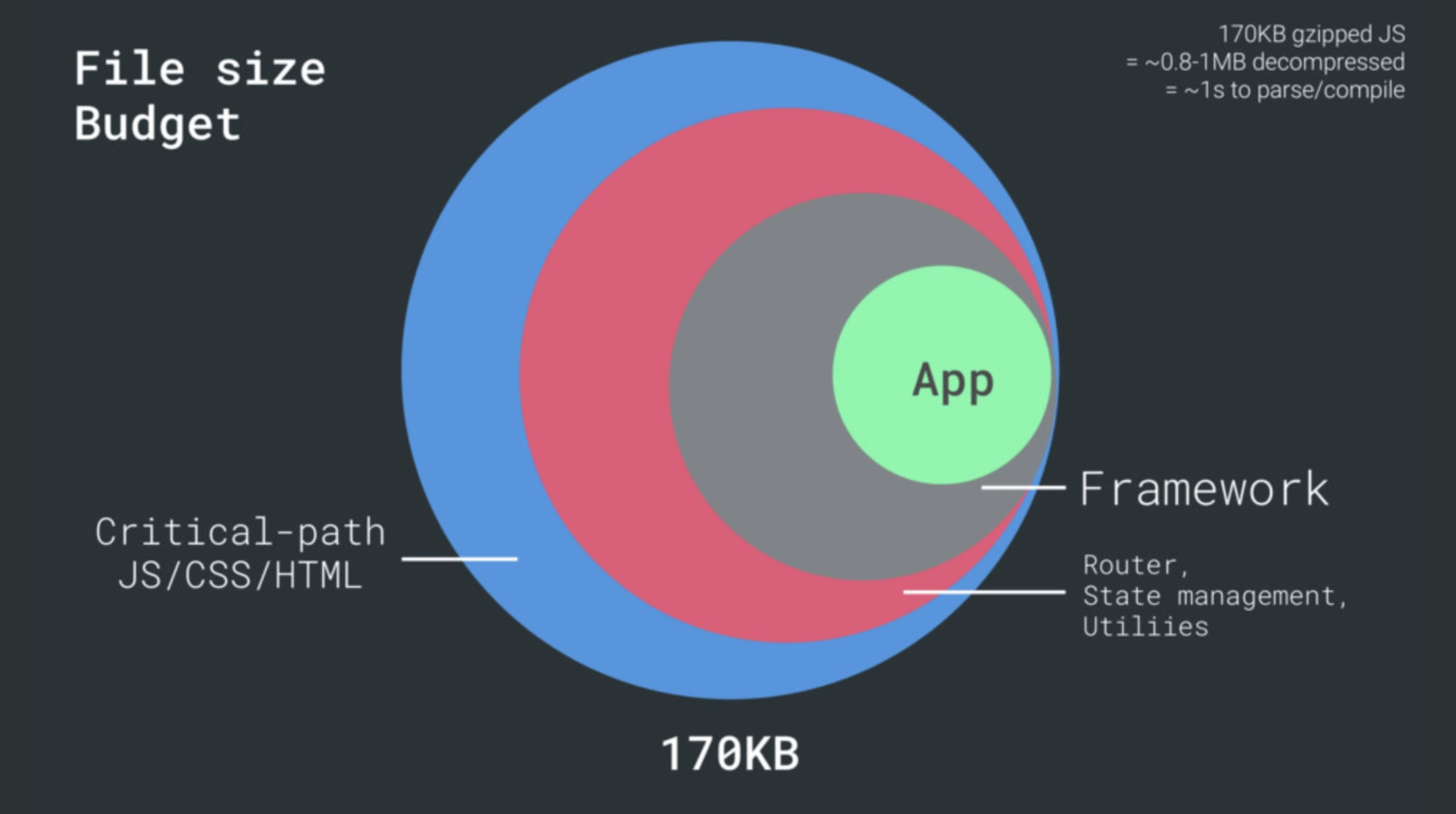
HTML 的前 14~15kb 加载是是最关键的有效载荷块—— 也是第一次往返(这是在400 ms 往返延时下 1 秒内所得到的)预算中唯一可以交付的部分。一般来说,为了实现上述目标,我们必须在关键的文件大小内进行操作。最高预算压缩之后 170 Kb(0.8-1MB解压缩),它已经占用多达 1s (取决于资源类型)来解析和编译。稍微高于这个值是可以的,但是要尽可能地降低这些值。
尽管如此,还是可以提高绑定的规模预算。例如,你可以在浏览器主线程的活动中设置性能预算,例如,在开始渲染前的绘制时间或者 跟踪前端 CPU。像 Calibre,SpeedCurve 和 Bundlesize 这些工具可以帮助你保持你的预算控制,并集成到你的构建过程。
定义环境
9. 根据实际情况选择并搭建构建工具
不要把太多的关注点放在那些看起来很酷的构建工具上。根据您的项目来构建环境,无论是 Grunt 、 Gulp 、 Webpack 、 Parcel,还是工具组合。只要这个构建工具能够让您快速的得到结果,并且保证您的构建过程没有问题,那么您就可以选择该构建工具。
在所有的构建工具中,Webpack 似乎是最成熟的一个,它有数百个插件可以用来优化构建的大小。如果你作为一位初用者,刚开始使用 Webpack 可能会很困难。所以如果你想开始使用 webpack,下面有一些很好的资源可以给您指引:
- Webpack文档 是一个很好的入手点,同样 Webpack相关的文章也可以作为很好的入门指引:Raja Rao 的 Confusing Bits 和 Andrew Welch 的 Annotated Webpack Config。
- Sean Learkin 上有一个关于 Webpack 的免费课程: Core Concepts,Jeffrey Way 也发布了一个关于 Webpack 的免费精彩视频供大家学习。它们都是深入的介绍了 Webpack。
- Webpack Fundamentals 是一个非常全面的4小时课程,由 FrontendMasters 发布在 Sean Learkin。
- 如果您对 Webpack 已经有初步的了解,Rowan Oulton 发布了一个使用 Webpack 获得 更好构建性能 的 应用场景指南,Benedikt Rotsch 对如何将Webpack绑定在一个节点上 进行了深入的研究。
- Webpack示例 包含了数百个即用型 Webpack 配置,主要按主题和用途分类。另外,还有一个 Webpack Config 配置器,可以生成一个基本配置文件。
- awesome-webpack 是一个非常有用的关于 Webpack 资源、库和工具的列表,里面包括一些介绍 Angular 、React 和未使用框架项目的文章、视频、课程、书籍和示例。
10. 默认情况下使用渐进增强
安全的选择是将渐进增强作为前端架构和项目部署的指导原则。首先设计和构建核心体验,然后通过功能强大的浏览器的高级功能增强体验,创造 弹性 体验。如果你的网站在一个网络不佳、糟糕设备、性能差的低版本浏览器上运行速度还是挺快,那么这个网站在一个网络环境好、设备和浏览器性能都比较好的环境下会运行起来会更加快。
11. 选择强大的性能基准
有这么多的未知影响加载 —— 网络、热节流、缓存回收、第三方脚本、解析器阻塞模式、磁盘的读写、 IPC jank、插件安装、CPU、硬件和内存限制、L2/L3 缓存、RTTS、图像、Web 字体加载行为的差异,其中 Javascript 脚本的代价是最大的,Web 字体阻塞默认的渲染和图片的加载使得内存消耗太大。随着性能瓶颈 从服务器端转移到客户端,作为开发人员,我们必须更仔细地考虑所有这些未知因素。
在 170kb 的预算中,已经包括了关键路径的 HTML / CSS / JavaScript、路由器、状态管理、实用程序、框架和应用程序逻辑,我们必须彻底 检查网络传输成本,解析/编译时间和运行时间来选择我们的框架。
Seb Markbage 指出,衡量框架启动成本的最好的方法就是先渲染视图,然后删除,然后再渲染,因为它可以告诉你框架是如何扩展的。第一个渲染趋向于预热一堆编译迟缓的代码,当它扩展时,更大的分支可以从中受益。第二次渲染基本上是仿效页面上的代码重用是如何随着页面复杂度的增长来影响性能特征。
12. 评估每个框架和每个依赖项
并不是每个项目都需要一个框架,也不是单页面应用程序中的每个页面都需要加载一个框架。在 Netflix 的例子中,删除 React,来自客户端的几个库和相应的应用程序代码将 JavaScript 总量减少了至少 200Kb,从而使 Netflix 注销主页的交互时间交互时间 缩短了50%以上 。然后,团队利用用户在登录页面上花费的时间,对用户可能登录的后续页面进行预取 React (详细信息请点击这里)。
事实上,某些项目可以 完全移除某些框架 并从中受益。一旦选择了一个框架,你最少会使用好几年。所以,如果你需要使用它,确保你的选择是经过 深思熟虑 的并且 对其完全了解。
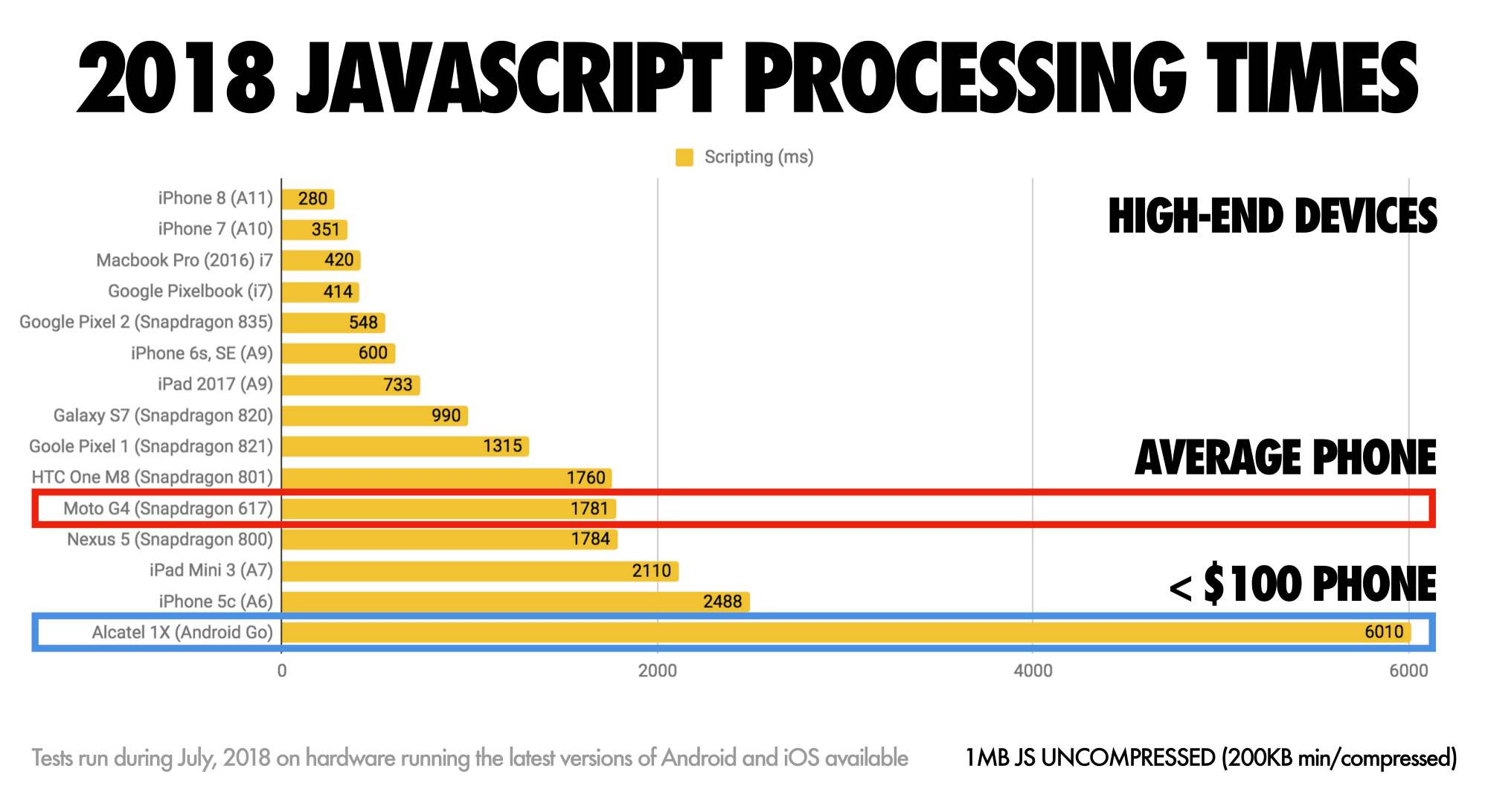
Inian Parameshwaran 测量了前50个框架的性能足迹 (针对 First Contentful Paint--从导航到浏览器从DOM渲染第一部分内容的时间)。Inian 发现,Vue 和 Preact 在桌面和移动端都是最快的,其次是 React (幻灯片)。您可以检查您的候选框架和建议的体系结构,并研究大多数解决方案的执行情况,例如服务器端呈现或客户端呈现。
基准性能成本问题。根据 Ankur Sethi的 一项 研究,**无论你对它的优化程度如何,你的 React 应用程序在印度普通手机上的加载速度绝不会超过 1.1s。你的 Angular 应用程序总是需要至少 2.7s 才能启动。您的Vue应用程序的用户需要等待至少 1s 才能开始使用它。尽管您可能不会将印度定位为主要市场,但如果一个用户在网络状况不佳的情况访问您的网站应该也会呈现出相同的体验。当然,您的项目团队可以牺牲基准性能换来可维护性和开发人员效率,但是你要确保这个决定是你经过了深思熟虑之后才做的决定。
您可以通过监测特性、可访问性、稳定性、性能、包生态系统、社区、学习曲线、文档、工具、跟踪记录、团队、兼容性、安全性等来评估 Sacha Greif 的 12分制评分系统 上的框架(或任何 JavaScript 库)。在进行选择前,至少要考虑总大小的成本 + 初始解析时间:轻量级的选项像 Preact,Inferno,Vue,Svelte 或者 Polymer 都做得很好。框架的大小基线将为你的应用程序代码定义约束条件。
一个很好的起点是为您的应用程序选择一个好的默认堆栈。Gatsby.js(React),Preact CLI 和 PWA Starter Kit 为平均移动硬件上的快速加载提供了合理的默认值。
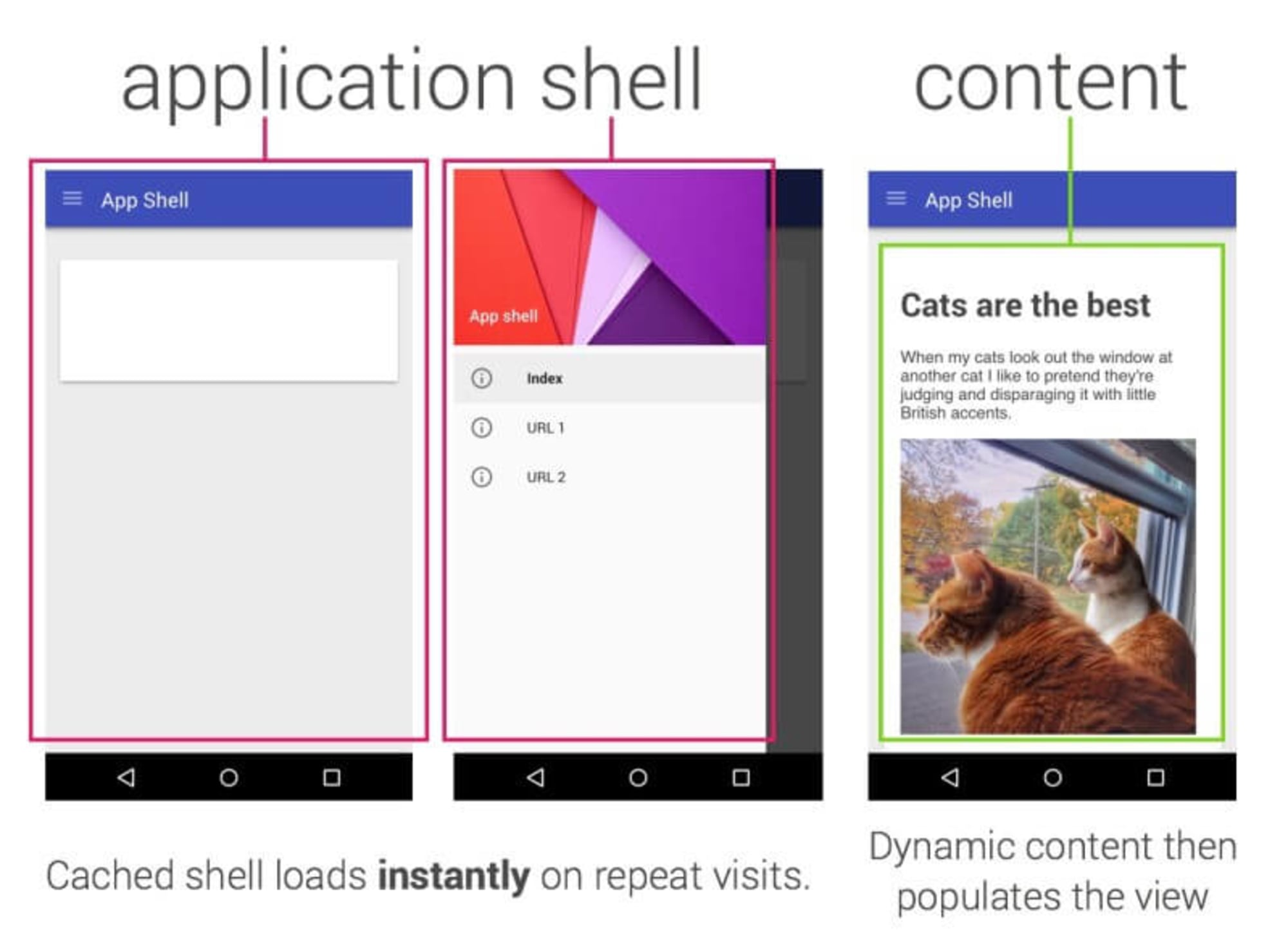
13. 考虑使用 PRPL 模式和 app shell 架构
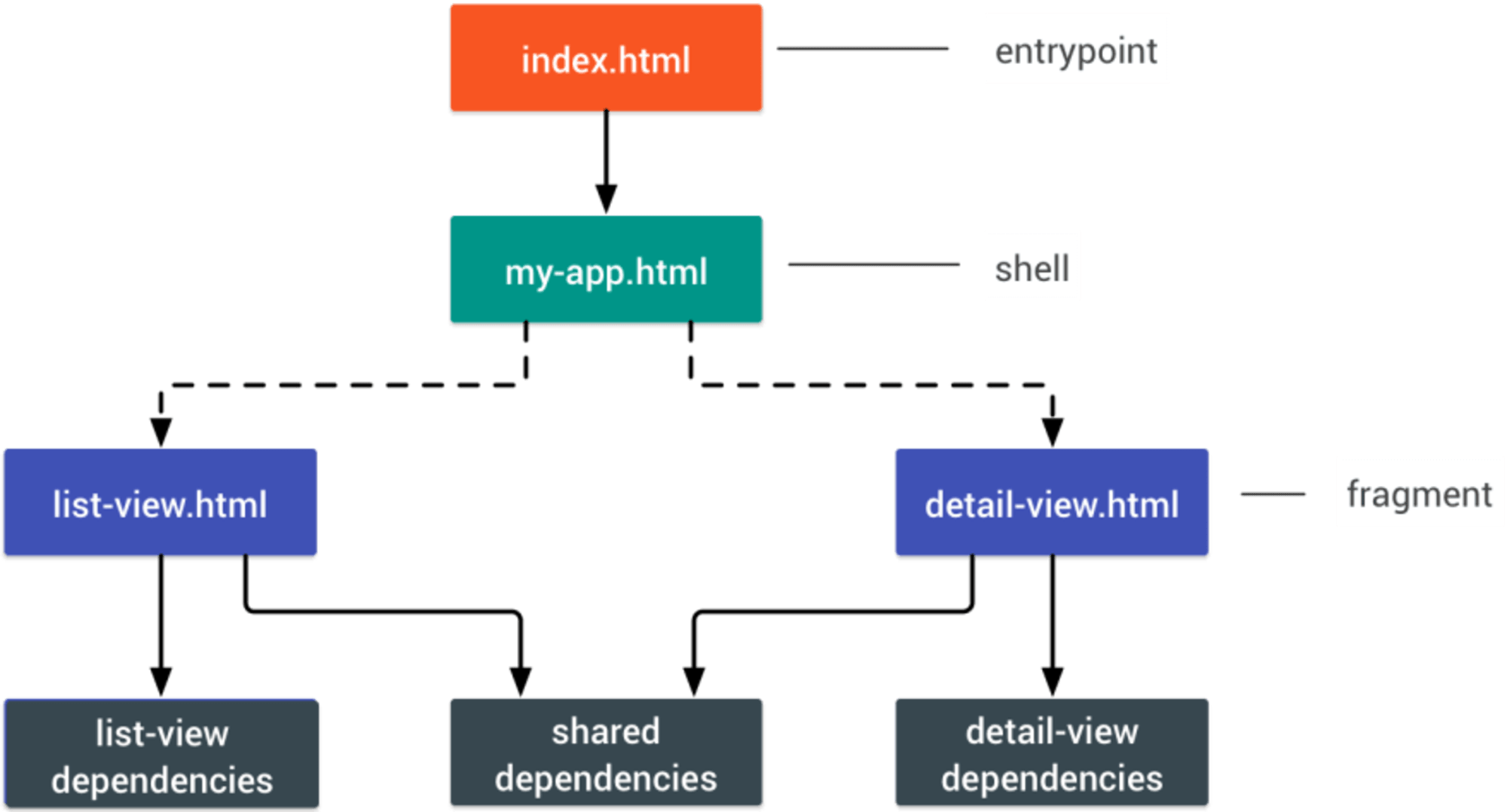
不同的框架会对性能产生不同的影响,并且需要不同的优化策略。因此,您必须清楚地了解您所依赖的框架的所有细节。在创建一个 web 应用程序时,请参考 PRPL模式 和 应用程序 shell 体系结构。这个想法很简单: 用最少的代码来将初始路由的交互快速呈现,然后使用 service worker 进行缓存和预缓存资源,然后使用懒加载异步加载所需的路由。
14. 优化 API 的性能
api是应用程序通过所谓的端点向内部和第三方应用程序来公开数据的通信通道。在 设计和构建API时,我们需要一个合理的协议来支持服务器和第三方请求之间的通信。Representational State Transfer ( REST )是一个相对完善以及合理的选择:它定义了一组约束,开发人员可以遵循这些约束以一种高性能、可靠和可伸缩的方式访问内容。符合 REST 约束的 Web 服务称为 RESTful Web 服务。
与好的 HTTP 请求一样,当从 API 检索数据时,服务器响应中的所有延迟最终都会传到最终用户,从而渲染的延迟。当资源想从 API 检索一些数据时,它需要从相应的端点请求数据。如果需要渲染来自多个资源的数据的组件(例如每篇评论中都有注释和作者照片的文章),那么可能需要多次往返服务器。此外,通过 REST 查询返回的数据量常常会超过渲染该组件所需的数据量。
如果很多资源需要 API 的数据,那么 API 可能会导致性能瓶颈。GraphQL 为这些问题提供了一个性能解决方案。GraphQL 是运行在服务端的 API 查询语言,用于为数据定义的类型系统执行查询。与 REST 不同的是, GraphQL 可以在单个请求中检索所有数据并确定所依赖的数据,而 REST 会获取过多需要的数据。
此外,由于 GraphQL 使用的是 schema (告诉如何结构化数据的元数据)。他可以将数据组织到更好的结构中。我们可以使用 GraphQL 来移除用于状态管理的 JavaScript 代码,从而在客户端生成一个更干净的应用程序代码来加快运行速度。
如果您想开始学习 GraphQL, Eric Baer 在他的 really Smashing 杂志上发表了两篇精彩的文章:GraphQL 入门教程一:为什么我们需要一种新的 API; GraphQL 入门教程二:API 设计的发展(感谢,Leonardo!)
15. 您是使用 AMP 还是 Instant Articles
根据组织的优先级和策略,您可以考虑使用谷歌的 AMP 、Facebook 的 Instant Articles 或苹果的 Apple News。如果不使用它们,你也可以实现很好的性能,但是 AMP 确实提供了一个免费的内容分发网络( CDN )的性能框架,而 Instant Articles 将提高你在 Facebook 上的可见性和性能。
对于用户而言,这些技术主要的优势是确保性能,所以有时他们更喜欢 AMP-/Apple News/Instant Pages 链接,而不是 常规 和潜在的臃肿页面。对于那些以内容为主的网站,主要处理很多第三方法内容,这些选择极大地加速渲染的时间。
除非他们不这样做。例如,根据 Tim Kadlec 的说法,AMP文档往往比同行更快,但并不一定意味着页面具有高性能;从性能角度来看,AMP并不是造成最大差异的因素。
对于站长而言,这些样式在各个平台可发现性并且 增强在搜索引擎中的可见性。你也可以重新使用 AMP 作为你的 PWA 数据源来构建 渐进式 Web AMPs。有什么缺点呢?显然,在一个有围墙的区域里,开发者可以创造并维持与内容分离的单独版本,防止 Instant Articles 和 Apple News 没有实际的URLs。(谢谢,Addy,Jeremy)
16. 合理使用 CDN
根据您拥有的动态数据量,您可以将部分内容 外包 给 静态站点生成工具,将其推送到 CDN 并从中提供静态版本,从而避免数据库请求。您甚至可以选择基于 CDN 的 静态主机平台,这样就可以通过给页面添加可交互组件的方式来丰富你的页面( JAMStack )。事实上,其中一些生成器(比如 React 上面的 Gatsby )实际上是 网站编译器,提供了许多自动优化功能。随着编译器不断地添加优化,编译后的输出会越来越小,速度也会越来越快。
请注意,CDN 也是可以托管并卸载(offload)动态内容的,所以咱们没有必要把 CDN 的服务范围限定在静态资源。(另外需要你记住的是),不管你的 CDN 是否执行内容压缩(GZip)、内容转换、HTTP/2 传输以及 ESI(一种标记语言,可以用它把网页划分为单独的可缓存的实体)等操作,我们还是需要复核上述操作的,这是因为上述操作不仅会在 CDN 的 edge 处(服务器最接近用户的地方)聚合页面中的静态以及动态内容,也还会执行其它任务。
注意:根据 Patrick Meenan 和 Andy Davies 的研究,HTTP / 2 在 许多CDN上 被 有效打破,因此我们不应该对其性能提升过于乐观。
