

What is the Execution Context & Stack in JavaScript?
在这篇文章中,我将深入探讨JavaScript的最基本部分之一,即Execution Context(执行上下文)。 在本文结束时,你应该对解释器了解得更清楚:为什么在声明它们之前可以使用某些函数或变量?以及它们的值是如何确定的?
什么是执行上下文?
JavaScript的执行环境非常重要,当JavaScript代码在行时,会被预处理为以下情况之一:
- Global code - 首次执行代码的默认环境。
- Function code - 每当执行流程进入函数体时。
- Eval code - 要在eval函数内执行的文本。
你可以阅读大量涉及作用域的在线资料,不过为了使事情更容易理解,让我们将术语“执行上下文”视为当前代码的运行环境或作用域。接下来让我们看一个包含global和function / local上下文的代码示例。
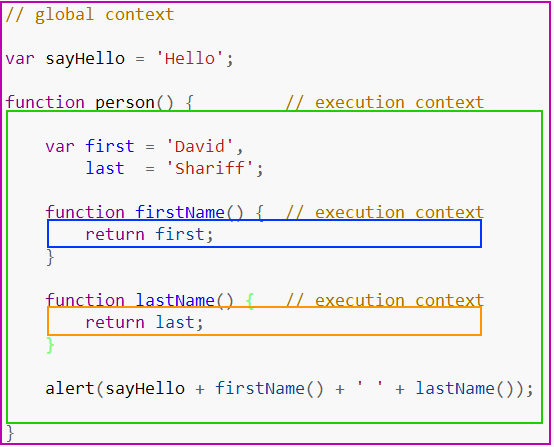
这里没有什么特别之处,我们有一个由紫色边框表示的全局上下文,和由绿色,蓝色和橙色边框表示的3个不同的函数上下文。 只能有1个全局上下文,可以从程序中的任何其他上下文访问。
你可以拥有任意数量的函数上下文,并且每个函数调用都会创建一个新的上下文,从而创建一个私有作用域,其中无法从当前函数作用域外直接访问函数内部声明的任何内容。 在上面的示例中,函数可以访问在其当前上下文之外声明的变量,但外部上下文无法访问在其中声明的变量或函数。 为什么会这样呢? 这段代码究竟是如何处理的?
Execution Context Stack(执行上下文堆栈)
浏览器中的JavaScript解释器被实现为单个线程。 实际上这意味着在浏览器中一次只能做一件事,其他动作或事件在所谓的执行堆栈中排队。 下图是单线程堆栈的抽象视图:
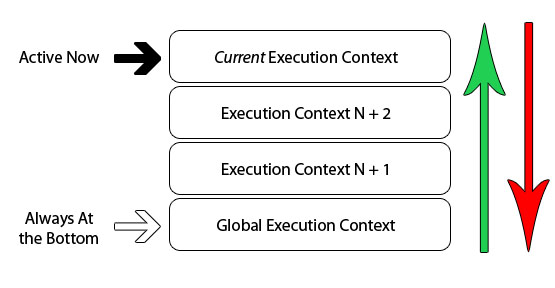
我们已经知道,当浏览器首次加载脚本时,它默认进入全局上下文执行。 如果在全局代码中调用函数,程序的顺序流进入被调用的函数,创建新的执行上下文并将其推送到执行堆栈的顶部。
如果在当前函数中调用另一个函数,则会发生同样的事情。 代码的执行流程进入内部函数,该函数创建一个新的执行上下文,该上下文被推送到现有堆栈的顶部。 浏览器将始终执行位于堆栈顶部的当前执行上下文,并且一旦函数执行完当前执行上下文后,它将从栈顶部弹出,把控制权返回到当前栈中的下一个上下文。 下面的示例显示了递归函数和程序的执行堆栈:
(function foo(i) {
if (i === 3) {
return;
}
else {
foo(++i);
}
}(0));
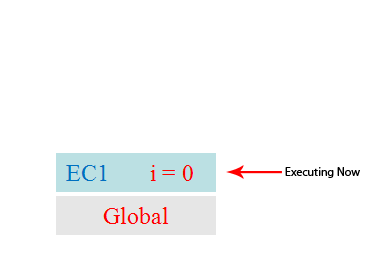
代码简单地调用自身3次,并将i的值递增1。每次调用函数foo时,都会创建一个新的执行上下文。 一旦上下文完成执行,它就会弹出堆栈并且讲控制返回到它下面的上下文,直到再次达到全局上下文。
关于执行堆栈execution stack有5个关键要点:
- 单线程。
- 同步执行。
- 一个全局上下文。
- 任意多个函数上下文。
- 每个函数调用都会创建一个新的执行上下文
execution context,甚至是对自身的调用。
执行上下文的细节
所以我们现在知道每次调用一个函数时,都会创建一个新的执行上下文。 但是,在JavaScript解释器中,对执行上下文的每次调用都有两个阶段:
-
创建阶段 [调用函数时,但在执行任何代码之前]:
- 创建
作用域链。 - 创建变量,函数和参数。
- 确定
“this”的值。
- 创建
-
激活/代码执行阶段:
- 分配值,引用函数和解释/执行代码。
可以将每个执行上下文在概念上表示为具有3个属性的对象:
executionContextObj = {
'scopeChain': { /* variableObject + 所有父执行上下文的variableObject */ },
'variableObject': { /* 函数实参/形参,内部变量和函数声明 */ },
'this': {}
}
激活对象/变量对象 [AO/VO]
在调用该函数,并且在实际执行函数之前,会创建这个executionContextObj。 这被称为第1阶段,即创造阶段。 这时解释器通过扫描函数传递的实参或形参、本地函数声明和局部变量声明来创建executionContextObj。 此扫描的结果将成为executionContextObj中的variableObject。
以下是解释器如何预处理代码的伪代码概述:
- 找一些代码来调用一个函数。
- 在执行功能代码之前,创建
执行上下文。 - 进入创建阶段:
- 初始化作用域链。
- 创建
variable object:- 创建
arguments object,检查参数的上下文,初始化名称和值并创建引用副本。 - 扫描上下文以获取函数声明:
- 对于找到的每个函数,在
variable object中创建一个属性,该属性是函数的确切名称,该属性存在指向内存中函数的引用指针。 - 如果函数名已存在,则将覆盖引用指针值。
- 对于找到的每个函数,在
- 扫描上下文以获取变量声明:
- 对于找到的每个变量声明,在
variable object中创建一个属性作为变量名称,并将该值初始化为undefined。 - 如果变量名称已存在于
variable object中,则不执行任何操作并继续扫描。
- 对于找到的每个变量声明,在
- 创建
- 确定上下文中
“this”的值。
- 激活/执行阶段:
- 在上下文中运行/解释函数代码,并在代码逐行执行时分配变量值。
我们来看一个例子:
function foo(i) {
var a = 'hello';
var b = function privateB() {
};
function c() {
}
}
foo(22);
在调用foo(22)时,创建阶段如下所示:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: undefined,
b: undefined
},
this: { ... }
}
如你所见,创建阶段处理定义属性的名称,而不是为它们赋值,但正式的形参/实参除外。创建阶段完成后,执行流程进入函数,激活/代码执行阶段在函数执行完毕后如下所示:
fooExecutionContext = {
scopeChain: { ... },
variableObject: {
arguments: {
0: 22,
length: 1
},
i: 22,
c: pointer to function c()
a: 'hello',
b: pointer to function privateB()
},
this: { ... }
}
关于hoisting
你可以找到许多使用JavaScript定义术语hoisting的在线资源,解释变量和函数声明被hoisting到其函数范围的顶部。 但是没有人能够详细解释为什么会发生这种情况,掌握了关于解释器如何创建激活对象的新知识,很容易理解为什么。 请看下面的代码示例:
(function() {
console.log(typeof foo); // function pointer
console.log(typeof bar); // undefined
var foo = 'hello',
bar = function() {
return 'world';
};
function foo() {
return 'hello';
}
}());
我们现在可以回答的问题是:
- 为什么我们可以在声明foo之前就能访问?
- 如果我们理解了
创建阶段,就知道在激活/代码执行阶段之前已经创建了变量。因此,当函数流开始执行时,已经在激活对象中定义了foo。
- 如果我们理解了
- Foo被声明两次,为什么foo显示为
function而不是undefined或string?- 即使
foo被声明两次,我们通过创建阶段知道函数在变量之前就被创建在激活对象上了,而且如果激活对象上已经存在了属性名称,我们只是绕过了声明这一步骤。 - 因此,首先在
激活对象上创建对函数foo()的引用,并且当解释器到达var foo时,我们已经看到属性名称foo存在,因此代码不执行任何操作并继续处理。
- 即使
- 为什么
bar未定义?bar实际上是一个具有函数赋值的变量,我们知道变量是在创建阶段被创建的,但它们是使用undefined值初始化的。
总结
希望到这里你已经能够很好地掌握了JavaScript解释器如何预处理你的代码。 理解执行上下文和堆栈可以让你了解背后的原因:为什么代码预处理后的值和你预期的不一样。
你认为学习解释器的内部工作原理是多此一举还是非常必要的呢? 了解执行上下文阶段是否能够帮你你写出更好的JavaScript呢?
