

4.2.1 卷积神经网络进阶(alexnet)
-
为什么要将不同的网络结构
- 不同的网络结构解决的问题不同
- 不同的网络结构使用的技巧不同(有的子手段可以被应用到其他的模型上)
- 不同的网络结构应用的场景不同(比如移动端需要模型越小越快越好)
-
模型的进化
- 更深更宽—AlexNet到VGGNet
- 不同的模型结构—VGG到InceptionNet/ResNet
- 优势组合—Inception+ Res = InceptionResNet
- 自我学习—NASNet
- 使用—MobileNet
-
AlexNet(本节的重点)
-
深度学习的引爆点
在2010年的比赛中,在1000个图片的分类任务上,能够达到15.3%的错误率,而传统的方法的错误率是26.2%

-
网络结构
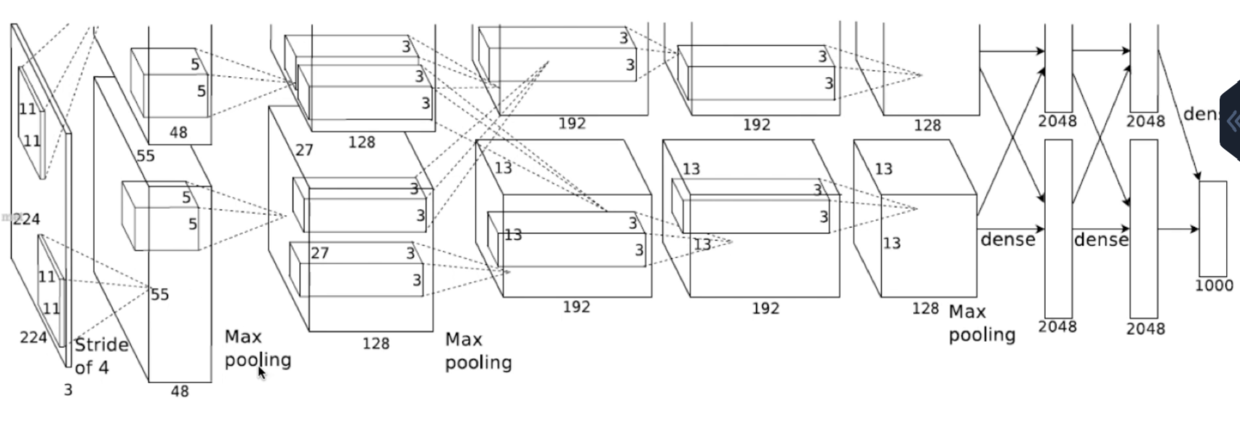
-
横向上:
- 输入是224*224的三通道的图像
- 然后经过一个卷积层,卷积层后面带pooling(池化)
- 再经过第二个卷积层,后面也带pooling
- 然后经过第三个,第四个,第五个卷积层
- 第五个卷积后又带pooling
- 然后经过一个全连接层到输出
-
纵向上:
- 有一个分割,代表的是网络分布在两个gpu上,两个gpu把卷积核分成了两部分,分别是48个卷积核,两部分做的是同样的事情
- 到第三个卷积层有一个交叉,第三个卷积层的两个卷积核的输入分别是前面神经元提取出来的综合
- 到第四个第五个卷积核又保持了独立性
- 到全连接层就又合到一起了
- 两个gpu可以使得神经网络更大更快

-
第一层:
- 输入224*224
- stride = 4,卷积核 11*11
- 输出大小 = (输入大小-卷积核大小+padding)/stride + 1 = 55 (这里padding等于3)
- 参数数目 = 3*(11*11)*96 = 35k
-
Alexnet首次使用了Relu激活函数
训练速度非常快,下图横坐标是迭代次数,纵坐标是错误率,sigmoid激活函数时虚线,relu是实线,可以看到relu训练的时间是sigmoid的6倍左右
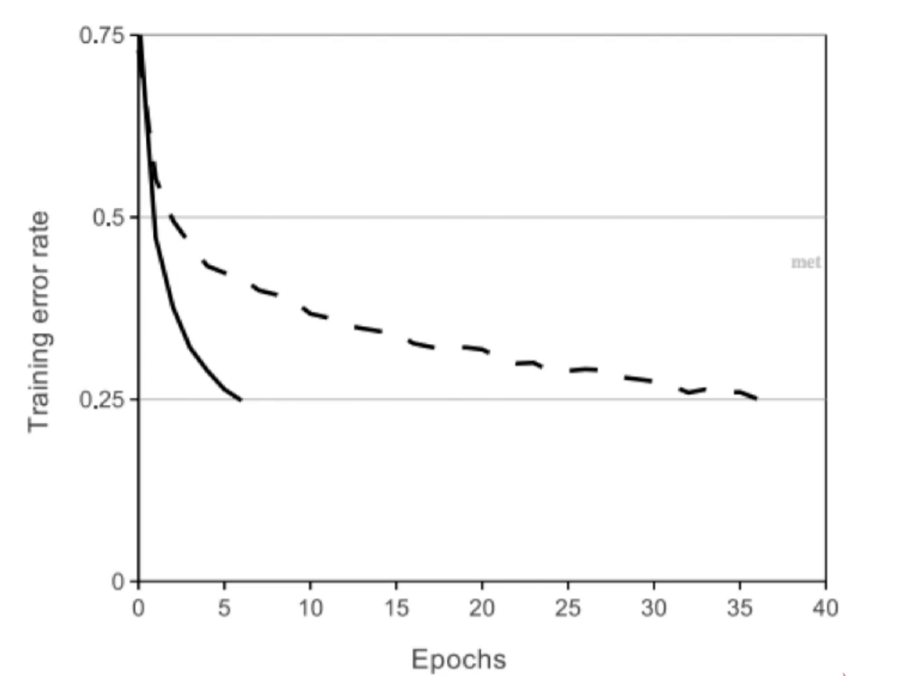
-
2-GPU并行结构
-
1,2,5卷积层后面都跟随着max-pooling
并不是所有的卷积层都要跟着pooling层,可以使用步长大于1的方式也可以使得图像变小
-
两个全连接层使用了dropout
每次都随机的把上一层的神经元置成0,使得他对下层的神经元不起贡献作用。
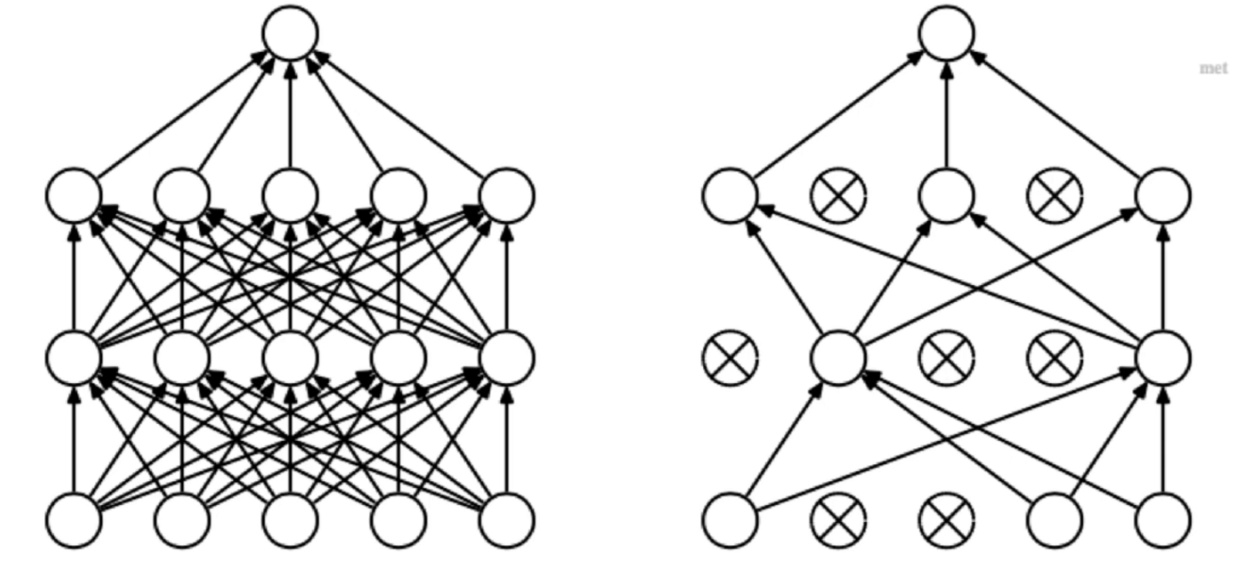
-
为什么把dropout用到全连接层上
- 全连接层参数占全部参数数目的大部分,容易过拟合
-
dropout原理解释
-
组合解释
- 每次dropout都相当于训练了一个子网络
- 最后的结果相当于很多子网络组合
-
动机解释
消除了神经单元之向的依赖,增强泛化能力(过拟合是神经元记住了所有的数据,记住数据需要多个神经元配合,而dropout每次都随机的删除了一些神经元,这时他对数据的记忆就不存在了)
-
数据解释
- 对于dropout后的结果,总能找到一个样本与其对应(例:原有一个全连接的输出是(1,2,3,4,5,6),dropout后可能变成了(1,0,3,4,0,6),删除了2,5。可以认为,总能找到一个新的样本,这个样本就是(1,0,3,4,0,6),所以dropout相当于是增加了样本数)
- 相当于数据增强
-
-
其他细节
- 数据增强,图片随机采样
- [256,256] 采样[224,224] ,相当于输入一张图像,可能会从不同角度采样出很多张
- Dropout = 0.5
- Batch Size = 128
- SGD momentum = 0.9
- Learning rate = 0.01,过一定次数降低为1/10
- 7个CNN做ensemble:18.2%->15.4%
- 数据增强,图片随机采样
-
-
