

4.3.1 adagrad_adam
我们之前将了随机梯度下降和动量梯度下降,不过,还有很多其他的优化算法可以使得模型稳定。
先来回顾随机梯度下降和动量梯度下降
随机梯度下降有两个问题:局部极值问题和saddle point 问题,动量梯度下降可以一定程度上解决这两个问题
因为他可以使用之前积累的梯度方向。
不过这两个方法还有其他的两个问题:
-
受初始学习率影响太大
初始化的学习率比较大,不管用哪种梯度下降,都会导致梯度爆炸,模型不收敛
-
每一个梯度的学习率都是一样的
α是针对全局的,而不是每一个维度定制的。
这个在图像上应用还不是特别明显,如果是针对稀疏的问题来说,就比较明显了,会使得我们丢失很多稀疏数据上的信息。
因为对w求导数的时候,根据链式求导法则,最终都会到w对x的偏导,这时候如果x=0,那么他的参数更新也是0,对于稀疏数据来说,因为他很稀疏,所以很多值都是0,很多时候是得不到梯度的更新的。
但是
但是其他维度的数据是很多的,这时候如果统一把学习率调小,会使得稀疏数据学习不到足够的信息
最好的解决方法是给每一个维度都设置不同的学习率
针对这两个问题,还有哪些其他的算法呢?
-
AdaGrad
学习率是逐渐衰减的,用以往梯度的平方和作为学习率的分母,从而使得整个学习率随着训练次数的增加而越来越小,这样也摆脱了学习率对初始值的依赖
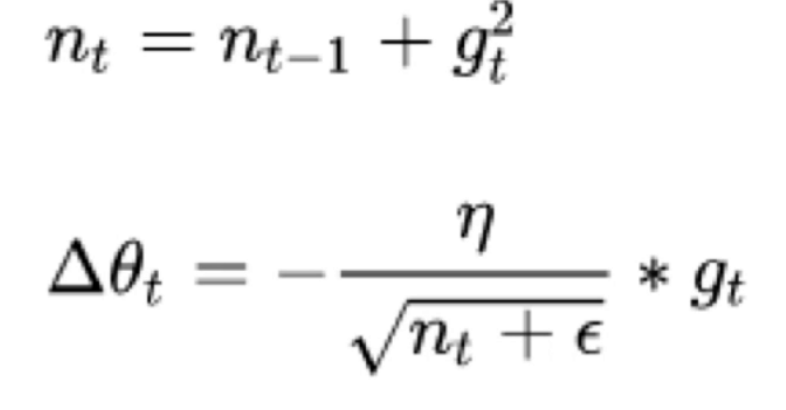
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared += dx ** 2
# + 1e-7 加一个比较小的值以防止初始值为0
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
* 优点
* 前期, regularizer较小,放大梯度
* 后期, regularizer较大,缩小梯度
* 梯度随训练次数降低(可以防止一直跳过极值区域)
* 每个分量有不同的学习率
* 缺点
* 学习率设置太大,导致regularizer影响过于敏感
* 后期,regularizer累积值太大,提前结束训练
-
RMSProp
-
AdaGrad 的变种
-
由累积平方梯度变为平均平方梯度
-
解决了后期提前结束训练的问题
-
grad_squared = 0
while True:
dx = compute_gradient(x)
# 平方和变成了平均值
grad_squared += decay_rate * grad_squared + (1 - decay_rate) * (dx ** 2)
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
-
Adam
-
所有的上述算法都会用learning_ rate来做参数,但是Adam和上面讲的几种算法会在后期给每个维度一个定制的学习率
-
Adam在以下场景比较有效
-
Beta1 = 0.9
-
Beta2 = 0.999
-
Learning_rate = 1e-3 or 5e-4(初始值比较小,可以通过冲量和累积梯度去放大他)
-
Adam结合了Momentum(动量梯度下降)(学习稳定)和Adagrad(可以随着训练次数和维度的变化而变化)的优点

[图片上传失败...(image-9a19d6-1538918434302)]
校准的意义在于通过这种方式使得开始的时候first_moment和second_moent变的相对大一些来加速训练
-
