

1 前言
在开始正题之前,先闲聊几句。有人说,计算机科学这个学科,软件方向研究到头就是数学,硬件方向研究到头就是物理,最轻松的是中间这批使用者,可以不太懂物理,不太懂数学,依旧可以使用计算机作为自己谋生的工具。这个规律具有普适应,看看“定时器”这个例子,往应用层研究,有 Quartz,Spring Schedule 等框架;往分布式研究,又有 SchedulerX,ElasticJob 等分布式任务调度;往底层实现看,又有多种定时器实现方案的原理、工作效率、数据结构可以深究…简单上手使用一个框架,并不能体现出个人的水平,如何与他人构成区分度?我觉得至少要在某一个方向有所建树:
- 深入研究某个现有框架的实现原理,例如:读源码
- 将一个传统技术在分布式领域很好地延伸,很多成熟的传统技术可能在单机 work well,但分布式场景需要很多额外的考虑。
- 站在设计者的角度,如果从零开始设计一个轮子,怎么利用合适的算法、数据结构,去实现它。
回到这篇文章的主题,我首先会围绕第三个话题讨论:设计实现一个定时器,可以使用什么算法,采用什么数据结构。接着再聊聊第一个话题:探讨一些优秀的定时器实现方案。
2 理解定时器
很多场景会用到定时器,例如
- 使用 TCP 长连接时,客户端需要定时向服务端发送心跳请求。
- 财务系统每个月的月末定时生成对账单。
- 双 11 的 0 点,定时开启秒杀开关。
定时器像水和空气一般,普遍存在于各个场景中,一般定时任务的形式表现为:经过固定时间后触发、按照固定频率周期性触发、在某个时刻触发。定时器是什么?可以理解为这样一个数据结构:
存储一系列的任务集合,并且 Deadline 越接近的任务,拥有越高的执行优先级 在用户视角支持以下几种操作: NewTask:将新任务加入任务集合 Cancel:取消某个任务 在任务调度的视角还要支持: Run:执行一个到期的定时任务
判断一个任务是否到期,基本会采用轮询的方式,每隔一个时间片 去检查 最近的任务 是否到期,并且,在 NewTask 和 Cancel 的行为发生之后,任务调度策略也会出现调整。
说到底,定时器还是靠线程轮询实现的。
3 数据结构
我们主要衡量 NewTask(新增任务),Cancel(取消任务),Run(执行到期的定时任务)这三个指标,分析他们使用不同数据结构的时间/空间复杂度。
3.1 双向有序链表
在 Java 中,LinkedList 是一个天然的双向链表
NewTask:O(N) Cancel:O(1) Run:O(1) N:任务数
NewTask O(N) 很容易理解,按照 expireTime 查找合适的位置即可;Cancel O(1) ,任务在 Cancel 时,会持有自己节点的引用,所以不需要查找其在链表中所在的位置,即可实现当前节点的删除,这也是为什么我们使用双向链表而不是普通链表的原因是 ;Run O(1),由于整个双向链表是基于 expireTime 有序的,所以调度器只需要轮询第一个任务即可。
3.2 堆
在 Java 中,PriorityQueue 是一个天然的堆,可以利用传入的 Comparator 来决定其中元素的优先级。
NewTask:O(logN) Cancel:O(logN) Run:O(1) N:任务数
expireTime 是 Comparator 的对比参数。NewTask O(logN) 和 Cancel O(logN) 分别对应堆插入和删除元素的时间复杂度 ;Run O(1),由 expireTime 形成的小根堆,我们总能在堆顶找到最快的即将过期的任务。
堆与双向有序链表相比,NewTask 和 Cancel 形成了 trade off,但考虑到现实中,定时任务取消的场景并不是很多,所以堆实现的定时器要比双向有序链表优秀。
3.3 时间轮
Netty 针对 I/O 超时调度的场景进行了优化,实现了 HashedWheelTimer 时间轮算法。
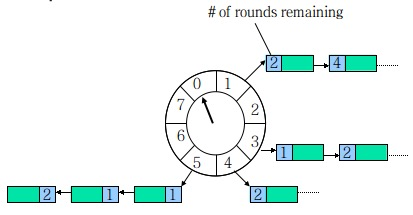
HashedWheelTimer 是一个环形结构,可以用时钟来类比,钟面上有很多 bucket ,每一个 bucket 上可以存放多个任务,使用一个 List 保存该时刻到期的所有任务,同时一个指针随着时间流逝一格一格转动,并执行对应 bucket 上所有到期的任务。任务通过取模决定应该放入哪个 bucket 。和 HashMap 的原理类似,newTask 对应 put,使用 List 来解决 Hash 冲突。
以上图为例,假设一个 bucket 是 1 秒,则指针转动一轮表示的时间段为 8s,假设当前指针指向 0,此时需要调度一个 3s 后执行的任务,显然应该加入到 (0+3=3) 的方格中,指针再走 3 次就可以执行了;如果任务要在 10s 后执行,应该等指针走完一轮零 2 格再执行,因此应放入 2,同时将 round(1)保存到任务中。检查到期任务时只执行 round 为 0 的, bucket 上其他任务的 round 减 1。
再看图中的 bucket5,我们可以知道在 后,有两个任务需要执行,在
后有一个任务需要执行。
NewTask:O(1) Cancel:O(1) Run:O(M) Tick:O(1) M: bucket ,M ~ N/C ,其中 C 为单轮 bucket 数,Netty 中默认为 512
时间轮算法的复杂度可能表达有误,比较难算,仅供参考。另外,其复杂度还受到多个任务分配到同一个 bucket 的影响。并且多了一个转动指针的开销。
传统定时器是面向任务的,时间轮定时器是面向 bucket 的。
构造 Netty 的 HashedWheelTimer 时有两个重要的参数:tickDuration 和 ticksPerWheel。
tickDuration:即一个 bucket 代表的时间,默认为 100ms,Netty 认为大多数场景下不需要修改这个参数;ticksPerWheel:一轮含有多少个 bucket ,默认为 512 个,如果任务较多可以增大这个参数,降低任务分配到同一个 bucket 的概率。
3.4 层级时间轮
Kafka 针对时间轮算法进行了优化,实现了层级时间轮 TimingWheel
如果任务的时间跨度很大,数量也多,传统的 HashedWheelTimer 会造成任务的 round 很大,单个 bucket 的任务 List 很长,并会维持很长一段时间。这时可将轮盘按时间粒度分级:
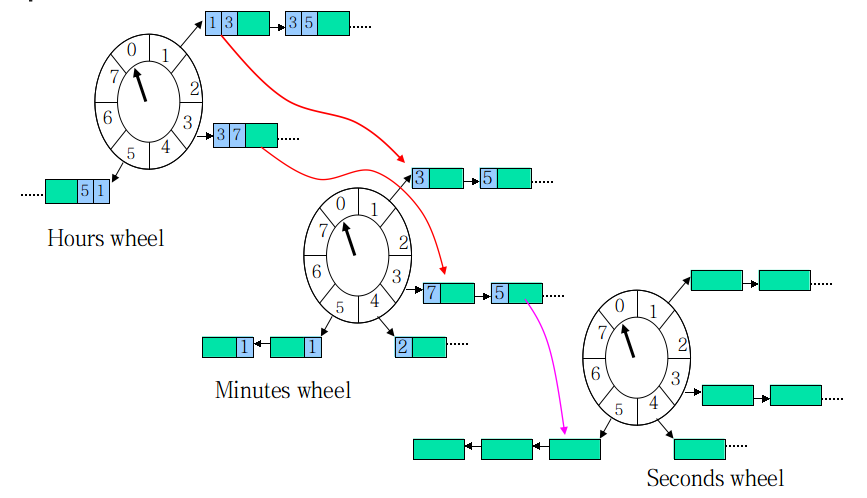
现在,每个任务除了要维护在当前轮盘的 round,还要计算在所有下级轮盘的round。当本层的round为0时,任务按下级 round 值被下放到下级轮子,最终在最底层的轮盘得到执行。
NewTask:O(H) Cancel:O(H) Run:O(M) Tick:O(1) H:层级数量
设想一下一个定时了 3 天,10 小时,50 分,30 秒的定时任务,在 tickDuration = 1s 的单层时间轮中,需要经过: 次指针的拨动才能被执行。但在 wheel1 tickDuration = 1 天,wheel2 tickDuration = 1 小时,wheel3 tickDuration = 1 分,wheel4 tickDuration = 1 秒 的四层时间轮中,只需要经过
次指针的拨动!
相比单层时间轮,层级时间轮在时间跨度较大时存在明显的优势。
4 常见实现
4.1 Timer
JDK 中的 Timer 是非常早期的实现,在现在看来,它并不是一个好的设计。
// 运行一个一秒后执行的定时任务
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
// do sth
}
}, 1000);
使用 Timer 实现任务调度的核心是 Timer 和 TimerTask。其中 Timer 负责设定 TimerTask 的起始与间隔执行时间。使用者只需要创建一个 TimerTask 的继承类,实现自己的 run 方法,然后将其丢给 Timer 去执行即可。
public class Timer {
private final TaskQueue queue = new TaskQueue();
private final TimerThread thread = new TimerThread(queue);
}
其中 TaskQueue 是使用数组实现的一个简易的堆。另外一个值得注意的属性是 TimerThread,Timer 使用唯一的线程负责轮询并执行任务。Timer 的优点在于简单易用,但也因为所有任务都是由同一个线程来调度,因此整个过程是串行执行的,同一时间只能有一个任务在执行,前一个任务的延迟或异常都将会影响到之后的任务。
轮询时如果发现 currentTime < heapFirst.executionTime,可以 wait(executionTime - currentTime) 来减少不必要的轮询时间。这是普遍被使用的一个优化。
Timer只能被单线程调度TimerTask中出现的异常会影响到Timer的执行。
由于这两个缺陷,JDK 1.5 支持了新的定时器方案 ScheduledExecutorService。
4.2 ScheduledExecutorService
// 运行一个一秒后执行的定时任务
ScheduledExecutorService service = Executors.newScheduledThreadPool(10);
service.scheduleA(new Runnable() {
@Override
public void run() {
//do sth
}
}, 1, TimeUnit.SECONDS);
相比 Timer,ScheduledExecutorService 解决了同一个定时器调度多个任务的阻塞问题,并且任务异常不会中断 ScheduledExecutorService。
ScheduledExecutorService 提供了两种常用的周期调度方法 ScheduleAtFixedRate 和 ScheduleWithFixedDelay。
ScheduleAtFixedRate 每次执行时间为上一次任务开始起向后推一个时间间隔,即每次执行时间为 : ,
,
, …
ScheduleWithFixedDelay 每次执行时间为上一次任务结束起向后推一个时间间隔,即每次执行时间为:,
,
, ...
由此可见,ScheduleAtFixedRate 是基于固定时间间隔进行任务调度,ScheduleWithFixedDelay 取决于每次任务执行的时间长短,是基于不固定时间间隔的任务调度。
ScheduledExecutorService 底层使用的数据结构为 PriorityQueue,任务调度方式较为常规,不做特别介绍。
4.3 HashedWheelTimer
Timer timer = new HashedWheelTimer();
//等价于 Timer timer = new HashedWheelTimer(100, TimeUnit.MILLISECONDS, 512);
timer.newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
//do sth
}
}, 1, TimeUnit.SECONDS);
前面已经介绍过了 Netty 中 HashedWheelTimer 内部的数据结构,默认构造器会配置轮询周期为 100ms,bucket 数量为 512。其使用方法和 JDK 的 Timer 十分相似。
private final Worker worker = new Worker();// Runnable
private final Thread workerThread;// Thread
由于篇幅限制,我并不打算做详细的源码分析,但上述两行来自 HashedWheelTimer 的代码阐释了一个事实:HashedWheelTimer 内部也同样是使用单个线程进行任务调度。与 JDK 的 Timer 一样,存在”前一个任务执行时间过长,影响后续定时任务执行“的问题。
理解 HashedWheelTimer 中的 ticksPerWheel,tickDuration,对二者进行合理的配置,可以使得用户在合适的场景得到最佳的性能。
5 最佳实践
5.1 选择合适的定时器
毋庸置疑,JDK 的 Timer 使用的场景是最窄的,完全可以被后两者取代。如何在 ScheduledExecutorService 和 HashedWheelTimer 之间如何做选择,需要区分场景,做一个简单的对比:
ScheduledExecutorService是面向任务的,当任务数非常大时,使用堆(PriorityQueue)维护任务的新增、删除会导致性能下降,而HashedWheelTimer面向 bucket,设置合理的 ticksPerWheel,tickDuration ,可以不受任务量的限制。所以在任务非常多时,HashedWheelTimer可以表现出它的优势。- 相反,如果任务量少,
HashedWheelTimer内部的 Worker 线程依旧会不停的拨动指针,虽然不是特别消耗性能,但至少不能说:HashedWheelTimer一定比ScheduledExecutorService优秀。 HashedWheelTimer由于开辟了一个 bucket 数组,占用的内存会稍大。
上述的对比,让我们得到了一个最佳实践:在任务非常多时,使用 HashedWheelTimer 可以获得性能的提升。例如服务治理框架中的心跳定时任务,服务实例非常多时,每一个客户端都需要定时发送心跳,每一个服务端都需要定时检测连接状态,这是一个非常适合使用 HashedWheelTimer 的场景。
5.2 单线程与业务线程池
我们需要注意HashedWheelTimer 使用单线程来调度任务,如果任务比较耗时,应当设置一个业务线程池,将HashedWheelTimer 当做一个定时触发器,任务的实际执行,交给业务线程池。
如果所有的任务都满足: taskNStartTime - taskN-1StartTime > taskN-1CostTime,即任意两个任务的间隔时间小于先执行任务的执行时间,则无需担心这个问题。
5.3 全局定时器
实际使用 HashedWheelTimer 时,应当将其当做一个全局的任务调度器,例如设计成 static 。时刻谨记一点:HashedWheelTimer 对应一个线程,如果每次实例化 HashedWheelTimer,首先是线程会很多,其次是时间轮算法将会完全失去意义。
5.4 为 HashedWheelTimer 设置合理的参数
ticksPerWheel,tickDuration 这两个参数尤为重要,ticksPerWheel 控制了时间轮中 bucket 的数量,决定了冲突发生的概率,tickDuration 决定了指针拨动的频率,一方面会影响定时的精度,一方面决定 CPU 的消耗量。当任务数量非常大时,考虑增大 ticksPerWheel;当时间精度要求不高时,可以适当加大 tickDuration,不过大多数情况下,不需要 care 这个参数。
5.5 什么时候使用层级时间轮
当时间跨度很大时,提升单层时间轮的 tickDuration 可以减少空转次数,但会导致时间精度变低,层级时间轮既可以避免精度降低,又避免了指针空转的次数。如果有时间跨度较长的定时任务,则可以交给层级时间轮去调度。此外,也可以按照定时精度实例化多个不同作用的单层时间轮,dayHashedWheelTimer、hourHashedWheelTimer、minHashedWheelTimer,配置不同的 tickDuration,此法虽 low,但不失为一个解决方案。Netty 设计的 HashedWheelTimer 是专门用来优化 I/O 调度的,场景较为局限,所以并没有实现层级时间轮;而在 Kafka 中定时器的适用范围则较广,所以其实现了层级时间轮,以应对更为复杂的场景。
6 参考资料
[2] novoland.github.io/并发/2014/07/…
[3] www.cs.columbia.edu/~nahum/w699…
欢迎关注我的微信公众号:「Kirito的技术分享」,关于文章的任何疑问都会得到回复,带来更多 Java 相关的技术分享。

