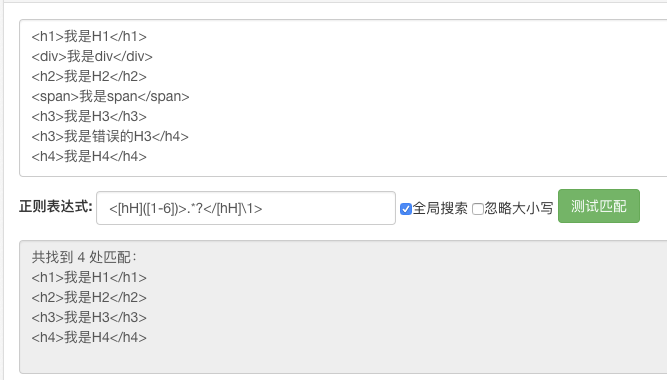
Q:将下面HTML片段中正确的标题标签(<h1>到<h6>)及其包含的内容匹配出来
<h1>我是H1</h1>
<div>我是div</div>
<h2>我是H2</h2>
<span>我是span</span>
<h3>我是H3</h3>
<h3>我是错误的H3</h4>
<h4>我是H4</h4>
概述
上述这个问题的难点包括:
- 必须匹配每个
<h1>到<h6> - 不能将包含在两个标题标签内的标签匹配到,如
<span>我是span</span> - 不能匹配格式不正确的标题标签,如
<h3>我是错误的H3</h4>
对于第二点,比较好解决,只要在一对标签内采用懒惰性的匹配就能够避免。但是对于第一和第三点,就需要借用正则的回溯引用了
正则的回溯引用
回溯引用指的是模式的后半部分引用在前半部分中定义的子表达式,且只能用来引用模式里的子表达式(子表达式即用元字符(和)括起来的部分)。简单理解,可以将回溯引用想象成对变量的引用。
使用方法
\1表示引用第1个子表达式,\2表示引用第2个子表达式,以此类推(通常,回溯引用从1开始匹配)。
注意事项
由于子表达式是按照其在表达式中的相对位置来引用的,因此有个不好之处在于,一旦改变了子表达式的相对位置,很容易引起正则的回溯引用失效。
答案来了
OK,现在就可以给出文章开头问题的答案了:
<[hH]([1-6])>.*?</[hH]\1>
其中\1指回溯引用第一个子表达式,即引用([1-6])。且开闭标签内采用懒惰性的匹配.*?,而不是贪婪式的.*。