

什么是Hash表
先看一下hash表的结构图:
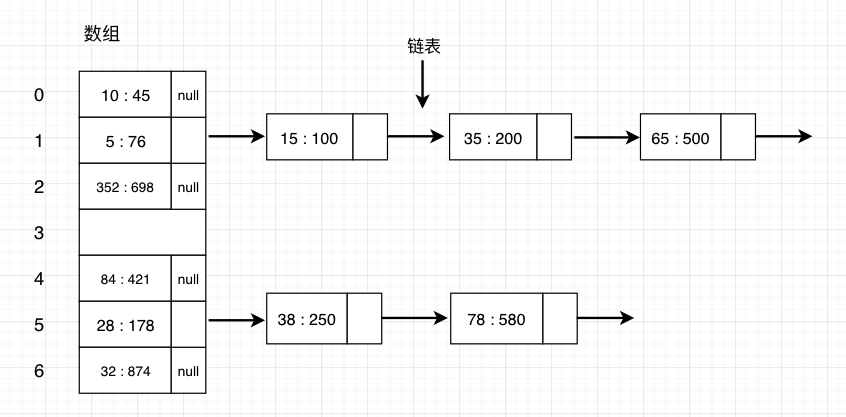
数组 + 链表
哈希表(Hash table,也叫散列表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
白话一点的说就是通过把Key通过一个固定的算法函数(hash函数)转换成一个整型数字,然后就对该数字对数组的长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
当使用hash表查询时,就是使用hash函数将key转换成对应的数组下标,并定位到该下标的数组空间里获取value,这样就充分利用到数组的定位性能进行数据定位。
(上面的话,需细细品味)
先了解一下下面几个常说的几个关键字是什么:
key:我们输入待查找的值
value:我们想要获取的内容
hash值:key通过hash函数算出的值(对数组长度取模,便可得到数组下标)
hash函数(散列函数):存在一种函数F,根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个遍历比较。这样就预先知道key在的位置,直接找到数据,提升效率。
即
地址index=F(key)
hash函数就是根据key计算出该存储地址的位置,hash表就是基于hash函数建立的一种查找表。
Hash函数的构造方法
方法
方法有很多种,比如直接定址法、数字分析法、平方取中法、折叠法、随机数法、除留余数法等,网上相关介绍有很多,这里就不重点说这个了
hash函数设计的考虑因素
- 计算hash地址所需时间(没有必要搞一个很复杂的函数去计算)
- 关键字的长度
- 表长
- 关键字分布是否均匀,是否有规律可循
- 尽量减少冲突
hash冲突
什么是hash冲突
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=f(k2),或f(k1) MOD 容量 =f(k2) MOD 容量,这种现象称为碰撞,亦称冲突。
通过构造性能良好的hash函数,可以减少冲突,但一般不可能完全避免冲突,因此解决冲突是hash表的另一个关键问题。
创建和查找hash表都会遇到冲突,两种情况下解决冲突的方法应该一致。
解决hash冲突
- 开放定址法
这种方法也称再散列法,基本思想是:当关键字key的hash地址p=F(key)出现冲突时,以p为基础,产生另一个hash地址p1,如果p1仍然冲突,再以p为基础,再产生另一个hash地址p2,。。。知道找出一个不冲突的hash地址pi,然后将元素存入其中。
通用的再散列函数的形式:
H = (F(key) + di) MOD m
其中i=1,2,。。。,m-1 为碰撞次数
m为表长。
F(key)为hash函数。
di为增量序列,增量序列的取值方式不同,相应的再散列方式也不同。
1) 线性探测再散列
di = 1,2,3,。。。,m-1
冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
2)二次探测再散列
di = 1^2, -1^2, 2^2, -2^2,..., k^2, -k^2 (k <= m-1)
发生冲突时,在表的左右进行跳跃式探测,比较灵活。
3)伪随机数探测再散列
di = 伪随机序列
下面有个网上的示列: 现有一个长度为11的哈希表,已填有关键字分别为17,60,29的三条记录。其中采用的哈希函数为f(key)= key MOD 11。现有第四个记录,关键字为38。根据以上哈希算法,得出哈希地址为5,跟关键字60的哈希地址一样,产生了冲突。根据增量d的取法的不同,有一下三种场景:
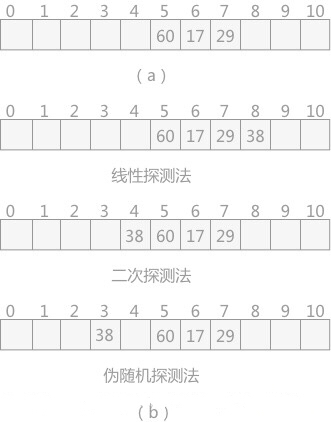
线性探测法: 当发生冲突时,因为f(key) + d,所以首先5 + 1 = 6,得到下一个hash地址为6,又冲突,依次类推,最后得到空闲的hash地址是8,然后将数据填入hash地址为8的空闲区域。
二次探测法: 当发生冲突时,因为d = 1^2,所以5 + 1 = 6,得到的下一个hash地址为6,又冲突,因为d = -1^2,所以5 + (-1) = 4,得到下一个hash地址为4,是空闲则将数据填入该区域。
伪随机数探测法: 随机数法就是完全根据伪随机序列来决定的,如果根据一个随机数种子得到一个伪随机序列{1,-2,2,。。。,k},那么首先得到的地址为6,第二个是3,依次类推,空闲则将数据填入。
开放定址法在iOS中的应用还是有很多的,具体可参考笔记-集合NSSet、字典NSDictionary的底层实现原理
- 链地址法(拉链法,位桶法)
将产生冲突的关键字的数据存储在冲突hash地址的一个线性链表中。实现时,一种策略是散列表同一位置的所有冲突结果都是用栈存放的,新元素被插入到表的前端还是后端完全取决于怎样方便。
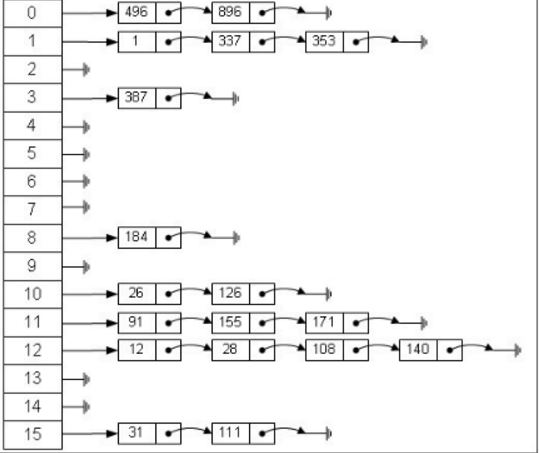
负载因子(load factor)
这里要提到两个参数:初始容量,加载因子,这两个参数是影响hash表性能的重要参数。
容量: 表示hash表中数组的长度,初始容量是创建hash表时的容量。
加载因子: 是hash表在其容量自动增加之前可以达到多满的一种尺度(存储元素的个数),它衡量的是一个散列表的空间的使用程度。
loadFactor = 加载因子 / 容量
一般情况下,当loadFactor <= 1时,hash表查找的期望复杂度为O(1).
对使用链表法的散列表来说,负载因子越大,对空间的利用更充分,然后后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。系统默认负载因子为0.75。
扩容
当hash表中元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对数组进行扩容。而在数组扩容之后,最消耗性能的点就出现了,原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是扩容。
什么时候进行扩容呢?当表中元素个数超过了容量 * loadFactor时,就会进行数组扩容。
用OC粗略的实现了一下扩容的:
- (void)resizeOfNewCapacity:(NSInteger)newCapacity {
NSInteger oldCapacity = _elementArray.count;
if (oldCapacity == MAX_CAPACITY) { // 扩容前的数组大小如果已经达到最大2^30
_threshold = oldCapacity - 1; // 修改阈值为int的最大值(2^30 - 1),这样以后就不会扩容了
return;
}
// 初始化一个新的数组
NSMutableArray *newArray = [NSMutableArray arrayWithCapacity:newCapacity];
for (int i = 0; i < newCapacity; i ++) {
[newArray addObject:@""];
}
[self transferWithNewTable:newArray]; // 将数据转移到新的数组里
[_elementArray removeAllObjects];
[_elementArray addObjectsFromArray:newArray]; // hash表的数组引用新建的数组
_threshold = (NSInteger)_capacity * _loadFactor; // 修改阈值
}
- (void)transferWithNewTable:(NSMutableArray *)array {
// 遍历旧数组,将元素转移到新数组中
for (int i = 0; i < _elementArray.count; i ++) {
if ([[[_elementArray objectAtIndex:i] class] isEqual:[SingleLinkedNode class]]) {
SingleLinkedNode *node = _elementArray[i];
if (node != NULL) {
do {
[self insertElementToArrayWith:array andNode:node];
node = node.next;
} while (node != NULL);
}
}
}
}
- (void)insertElementToArrayWith:(NSMutableArray *)array andNode:(SingleLinkedNode *)node {
NSInteger index = [node.key integerValue] % _capacity; // 计算每个元素在新数组中的位置
if (![[[array objectAtIndex:index] class] isEqual:[SingleLinkedNode class]]) {
[array replaceObjectAtIndex:index withObject:node];
}else {
SingleLinkedNode *headNode = [array objectAtIndex:index];
while (headNode != NULL) {
headNode = headNode.next;
}
// 直接把元素插入
headNode.next = node;
}
}
OC语言的实现
构建HashTable对象
HashTable.h文件
#import <Foundation/Foundation.h>
@class SingleLinkedNode;
NS_ASSUME_NONNULL_BEGIN
@interface HashTable : NSObject
@property (nonatomic, strong) NSMutableArray *elementArray;
@property (nonatomic, assign) NSInteger capacity; // 容量 数组(hash表)长度
@property (nonatomic, assign) NSInteger modCount; // 计数器,计算put的元素个数(不包括重复的元素)
@property (nonatomic, assign) float threshold; // 阈值
@property (nonatomic, assign) float loadFactor; // 加载因子
/**
初始化Hash表
@param capacity 数组的长度
@return hash表
*/
- (instancetype)initWithCapacity:(NSInteger)capacity;
/**
插入
@param newNode 存入的键值对newNode
*/
- (void)insertElementByNode:(SingleLinkedNode *)newNode;
/**
查询
@param key key值
@return 想要获取的value
*/
- (NSString *)findElementByKey:(NSString *)key;
@end
NS_ASSUME_NONNULL_END
HashTable.m文件:
#define MAX_CAPACITY pow(2, 30)
#import "HashTable.h"
#import "SingleLinkedNode.h"
@implementation HashTable
- (instancetype)initWithCapacity:(NSInteger)capacity {
self = [super init];
if (self) {
_capacity = capacity;
_loadFactor = 0.75;
_threshold = (NSInteger) _loadFactor * _capacity;
_modCount = 0;
// 直接初始化数组,这里为了方便理解hash,所以就直接给定capacity,java中默认是16
_elementArray = [NSMutableArray arrayWithCapacity:capacity];
for (int i = 0; i < capacity; i ++) {
[_elementArray addObject:@""];
}
}
return self;
}
- (void)insertElementByNode:(SingleLinkedNode *)newNode {
if (newNode.key.length == 0) {
return;
}
// 判断是否需要扩容
if (_threshold < _modCount * _capacity) {
_capacity *= 2;
[self resizeOfNewCapacity:_capacity];
}
// 计算存储位置
NSInteger keyValue = [newNode.key integerValue]; // F(x) = x; 得到hash值
NSInteger index = keyValue % _capacity; // hash值 MOD 容量 = 数组下标
newNode.hashValue = keyValue;
// 如果插入的区域是空闲的,则直接把数据存入该空间区域
if (![[[_elementArray objectAtIndex:index] class] isEqual:[SingleLinkedNode class]]) {
[_elementArray replaceObjectAtIndex:index withObject:newNode];
_modCount++;
}else {
// 发生冲突,通过链表法解决冲突
SingleLinkedNode *headNode = [_elementArray objectAtIndex:index];
while (headNode != NULL) {
// 插入的key重复,则覆盖原来的元素
if ([headNode.key isEqualToString:newNode.key]) {
headNode.value = newNode.value;
return;
}
headNode = headNode.next;
}
_modCount++;
// 直接把元素插入
headNode.next = newNode;
}
}
- (NSString *)findElementByKey:(NSString *)key {
if (key.length == 0) {
return nil;
}
// 计算存储位置
NSInteger keyValue = [key integerValue];
NSInteger index = keyValue % _capacity; // hash函数keyValue % _capacity (0~9)
if (index >= _capacity) {
return nil;
}
if (![[[_elementArray objectAtIndex:index] class] isEqual:[SingleLinkedNode class]]) {
return nil;
}else {
// 遍历链表,知道找到key值相等的node,然后返回value
SingleLinkedNode *headNode = [_elementArray objectAtIndex:index];
while (headNode != NULL) {
if ([headNode.key isEqualToString:key]) {
return headNode.value;
}
headNode = headNode.next;
}
return nil;
}
}
- (void)resizeOfNewCapacity:(NSInteger)newCapacity {
NSInteger oldCapacity = _elementArray.count;
if (oldCapacity == MAX_CAPACITY) { // 扩容前的数组大小如果已经达到最大2^30
_threshold = oldCapacity - 1; // 修改阈值为int的最大值(2^30 - 1),这样以后就不会扩容了
return;
}
// 初始化一个新的数组
NSMutableArray *newArray = [NSMutableArray arrayWithCapacity:newCapacity];
for (int i = 0; i < newCapacity; i ++) {
[newArray addObject:@""];
}
[self transferWithNewTable:newArray]; // 将数据转移到新的数组里
[_elementArray removeAllObjects];
[_elementArray addObjectsFromArray:newArray]; // hash表的数组引用新建的数组
_threshold = (NSInteger)_capacity * _loadFactor; // 修改阈值
}
- (void)transferWithNewTable:(NSMutableArray *)array {
// 遍历旧数组,将元素转移到新数组中
for (int i = 0; i < _elementArray.count; i ++) {
if ([[[_elementArray objectAtIndex:i] class] isEqual:[SingleLinkedNode class]]) {
SingleLinkedNode *node = _elementArray[i];
if (node != NULL) {
do {
[self insertElementToArrayWith:array andNode:node];
node = node.next;
} while (node != NULL);
}
}
}
}
- (void)insertElementToArrayWith:(NSMutableArray *)array andNode:(SingleLinkedNode *)node {
// 下面这个方法没有成功的获取到新数组中的位置
// NSInteger index = [self indexForHashValue:node.hashValue andNewCapacity:array.count];
NSInteger index = [node.key integerValue] % _capacity; // 计算每个元素在新数组中的位置
if (![[[array objectAtIndex:index] class] isEqual:[SingleLinkedNode class]]) {
[array replaceObjectAtIndex:index withObject:node];
}else {
SingleLinkedNode *headNode = [array objectAtIndex:index];
while (headNode != NULL) {
headNode = headNode.next;
}
// 直接把元素插入
headNode.next = node;
}
}
- (NSInteger)indexForHashValue:(NSInteger)hash andNewCapacity:(NSInteger)newCapacity {
return hash & (newCapacity - 1);
}
@end
SingleLinkedNode.h文件:
#import <Foundation/Foundation.h>
NS_ASSUME_NONNULL_BEGIN
@interface SingleLinkedNode : NSObject <NSCopying>
@property (nonatomic, strong) NSString *key;
@property (nonatomic, strong) NSString *value;
@property (nonatomic, strong) SingleLinkedNode *next;
@property (nonatomic, assign) NSInteger hashValue;
- (instancetype)initWithKey:(NSString *)key value:(NSString *)value;
@end
NS_ASSUME_NONNULL_END
SingleLinkedNode.m文件:
#import "SingleLinkedNode.h"
@implementation SingleLinkedNode
- (instancetype)initWithKey:(NSString *)key value:(NSString *)value {
if (self = [super init]) {
_key = key;
_value = value;
}
return self;
}
@end
上面代码看起来或许有些乱,感兴趣的小伙伴可以在这里下载demo传送门
总结: 这篇文章主要是了解hash表,以及hash表的实现特性,并且使用OC语言简单的粗略的实现了Hash表,如果有什么错误,希望小伙伴们留言告知,谢谢。
