

导读:阅读文本你将能够了解到C标准库对快速排序的支持、简单的索引技术、Thunk技术的原理以及应用、C++虚函数调用以及接口多重继承实现、动态库中函数调用的实现原理、以及在iOS等各操作系统平台上Thunk程序的实现方法、内存映射文件技术。
在说Thunk程序之前,我想先通过一个实际中排序的例子来引出本文所要介绍的Thunk技术的方方面面。
C标准库对排序的支持
C语言的标准库<stdlib.h>中提供了一个用于快速排序的函数qsort,函数的签名如下:
/*
@note: 实现快速排序功能
@param: base 要排序的数组指针
@param: nmemb 数组中元素的个数
@param: size 数组中每个元素的size
@param: compar 排序元素比较函数指针, 用于比较两个元素。返回值分别为-1, 0, 1。
*/
void qsort(void *base, size_t nmemb, size_t size, int(*compar)(const void *, const void *));
这个函数要求提供一个排序的数组指针base, 数组的元素个数nmemb, 数组中每个元素的尺寸size,以及一个排序的比较器函数compar四个参数。下面的例子演示了这个函数的使用方法:
#include <stdlib.h>
typedef struct
{
int age;
char *name;
}student_t;
//按年龄升序排序的比较器函数
int agecomparfn(const student_t *s1, const student_t *s2)
{
return s1->age - s2->age;
}
int main(int argc, const char * argv[])
{
student_t students[] = {{20,"Tom"},{15,"Jack"},{30,"Bob"},{10,"Lily"},{30,"Joe"}};
size_t count = sizeof(students)/sizeof(student_t);
qsort(students, count, sizeof(student_t), &agecomparfn);
for (size_t i = 0; i < count; i++)
{
printf("student:[age:%d, name:%s]\n", students[i].age, students[i].name);
}
return 0;
}
函数排序后会将students中元素的内存存储顺序打乱。如果需求变为在不将students中的元素打乱情况下,仍希望按age的大小进行排序输出显示呢?
为了解决这个问题可以为students数组建立一个索引数组,然后对索引数组进行排序即可。因为打乱的是索引数组中的顺序,而访问元素时又可以通过索引数组来间接访问,这样就可以实现原始数据内存存储顺序不改变的情况下进行有序输出。代码实现改为如下:
#include <stdlib.h>
typedef struct
{
int age;
char *name;
}student_t;
student_t students[] = {{20,"Tom"},{15,"Jack"},{30,"Bob"},{10,"Lily"},{30,"Joe"}};
size_t count = sizeof(students)/sizeof(student_t);
//按年龄升序索引排序的比较器函数
int ageidxcomparfn(const int *idx1ptr, const int *idx2ptr)
{
return students[*idx1ptr].age - students[*idx2ptr].age;
}
int main(int argc, const char * argv[])
{
//创建一个索引数组
int idxs[] = {0,1,2,3,4};
qsort(idxs, count, sizeof(int), &ageidxcomparfn);
for (size_t i = 0; i < count; i++)
{
//通过索引间接引用
printf("student[age:%d, name:%s]\n", students[idxs[i]].age, students[idxs[i]].name);
}
return 0;
}
从上面的代码中可以看出,排序时不再是对students数组进行排序了,而是对索引数组idxs进行排序了。同时在访问students中的元素时也不再直接通过下标访问,而是通过索引数组的下标来进行间接访问了。
索引技术是一种非常实用的技术,尤其是在数据库系统上应用最广泛,因为原始记录存储成本和文件IO的原因,移动索引中的数据要比移动原始记录数据要快而且方便很多,而且性能上也会大大的提升。当大量数据存储在内存中也是如此,数据记录在内存中因为排序而进行位置的移动要比索引数组元素移动的开销和成本大很多,而且如果涉及到多线程下要对不同的成员进行原始记录的排序时还需要引入锁的机制。
因此在实践中对于那些大数据块进行排序时,改为通过引入索引来进行间接排序将会使你的程序性能得到质的提高。
对比上面两个排序的实例代码实现就会发现通过索引进行排序时不得不将students数组从一个局部变量转化为一个全局变量了,原因是由于排序比较器函数compar的定义限制导致的。
因为排序的对象从students变为idxs了,而排序比较器函数ageidxcomparfn的两个入参变为索引值的int类型的指针,如果不将students数组设置为全局变量那么比较器函数内部是无法访问students中的元素的,所以只能将students定义为一个全局数组。
很明显这种解决方案是非常不友好而且无法进行扩展的,同一个比较器函数无法实现对不同的students数组进行排序。为了支持这种需要带扩展参数的间接排序,很多平台都提供了一个相应的非标准库扩充函数(比如Windows下的qsort_s, iOS/macOS的qsort_r, qsort_b等)。
下面是采用iOS系统下的qsort_r函数来解决上述问题的代码:
#include <stdlib.h>
typedef struct
{
int age;
char *name;
}student_t;
//按年龄升序索引排序的带扩展参数的排序比较器函数
int ageidxcomparfn(student_t students[], const int *idx1ptr, const int *idx2ptr)
{
return students[*idx1ptr].age - parray[*idx2ptr].age;
}
int main(int argc, const char * argv[])
{
student_t students[] = {{20,"Tom"},{15,"Jack"},{30,"Bob"},{10,"Lily"},{30,"Joe"}};
int idxs[] = {0,1,2,3,4};
size_t count = sizeof(students)/sizeof(student_t);
//qsort_r增加一个thunk参数,函数比较器中也增加了一个参数。
qsort_r(idxs, count, sizeof(int), students, &ageidxcomparfn);
for (size_t i = 0; i < count; i++)
{
printf("student[age:%d, name:%s]\n", students[idxs[i]].age, students[idxs[i]].name);
}
return 0
}
qsort_r函数的签名中增加了一个thunk参数,同时在排序比较器函数中也相应的增加了一个扩展的入参,其值就是qsort_t中的thunk参数,这样就不再需要将数组设置为全局变量了。
一个不幸的事实是这些扩展函数并不是C标准库中的函数,而且在标准库中还有非常多的类似的函数比如二分查找函数bsearch等等。当要编写的是跨平台的应用程序时就不得不放弃对这些非标准的扩展函数的使用了。所幸的是我们还可以借助一种称之为thunk的技术来解决qsort函数间接排序的问题,这也就是我下面要引入的本文的主题了。
Thunk技术
thunk技术的概念在维基百科中被定义如下:
In computer programming, a thunk is a subroutine that is created, often automatically, to assist a call to another subroutine. Thunks are primarily used to represent an additional calculation that a subroutine needs to execute, or to call a routine that does not support the usual calling mechanism. They have a variety of other applications to compiler code generation and modular programming.
Thunk程序中文翻译为形实转换程序,简而言之Thunk程序就是一段代码块,这段代码块可以在调用真正的函数前后进行一些附加的计算和逻辑处理,或者提供将对原函数的直接调用转化为间接调用的能力。
Thunk程序在有的地方又被称为跳板(trampoline)程序,Thunk程序不会破坏原始被调用函数的栈参数结构,只是提供了一个原始调用的hook的能力。Thunk技术可以在编译时和运行时两种场景下被使用。
在介绍用Thunk技术实现运行时用qsort函数实现索引排序之前,先介绍三种编译时Thunk技术的使用场景。
如果你不感兴趣编译时的场景则可以直接跳过这些小节。
一、程序调用动态库中函数的实现原理
在早期的实模式系统中可执行程序通常只有一个文件组成,对内存的访问也是直接的物理内存访问,程序加载时所存放的内存地址区域也是固定的。一个可执行程序中的所有代码则是由多个不同的函数或者类组成的。
当要使用某个函数提供的功能时,就需要在代码处调用对应的函数。每个函数在程序运行并加载到内存中时都有一个唯一的内存中地址来标识函数入口的开始位置,而调用函数的代码则会在编译链接后转化为对函数执行调用的机器指令(比如call或者bl指令)。
假设有如下的可执行程序源代码:
void main()
{
foo();
}
void foo()
{
}
假如操作系统在实模式下将可执行程序的指令代码固定加载到地址为0x1000处,那么当将这个程序源码进行编译和链接产生二进制的可执行文件运行时在内存中的数据为如下:
//本机器指令是x86系统下的机器指令
//main函数的起始地址是0x1000
0x1000: E8 03 ;这里的E8是call指令的机器码,03是表示调用从当前指令位置往下相对偏移3个字节位置的函数地址,也就是foo函数的地址。
0x1002: 22 ;这里的22是ret指令的机器码
//foo函数的起始地址是0x1003
0x1003: 22 ; 这里的22是ret指令的机器码
可以看出源代码中的函数调用的语句在编译链接后都会转化为call指令操作码后面跟着被调用函数与当前指令之间的相对偏移值操作数的机器指令。函数调用地址采用相对偏移值而不采用绝对值的好处在于当对内存中的程序进行重定向或者动态调整程序加载到内存中的基地址时就不需要改变二进制可执行程序的内容。
随着保护模式技术的实现以及多任务系统的诞生,操作系统为每个进程提供了独立的虚拟内存空间。为了对代码进行复用,操作系统提供了对动态链接库的支持能力。这种情况下一个程序就可能由一个可执行程序和多个动态库组成了。
动态库也是一段可被执行的二进制代码,只不过它并没有定义像main函数之类的入口函数且不能被单独执行。当一个程序被运行时操作系统会将可执行程序文件以及显式链接的所有动态库文件的映像(image)随机的加载到进程的虚拟内存空间中去。而这时候就会产生出一个问题:
当所有的函数都定义在一个可执行文件内时,因为可执行文件中的这些函数在编译链接时的位置都已经固定了,所以转化为函数调用的机器指令时,每个函数的相对偏移位置是很容易被计算出来的。而如果可执行程序中调用的是一个由动态库所提供的函数呢?因为这个动态库和可执行程序文件是两个不同的文件,并且动态库的基地址被加载到进程的虚拟内存空间的位置是不固定的而且随机的,可执行程序image和动态库image所加载到的内存区域并不一定是连续的内存区域,因此可执行程序是无法在编译链接时得到动态库中的函数地址在内存中的位置和调用指令的在内存中位置之间的相对偏移量的。
解决这个问题的方法就是在编译一个可执行文件时,将可执行程序代码中调用的外部动态库中定义的每一个函数都在本程序内分别建立一个对应的被称为stub的本地函数代码块,同时在可执行程序中的数据段中建立一个表格,这个表格的内容保存的就是可执行程序调用的每个外部动态库中定义的函数的真实地址,我们称这个表格为导入地址表。然后对应的每个本地stub函数块中的实现就是将调用跳转到导入地址表中对应的真实函数实现的数组索引中去。在可执行程序启动时这个导入地址表中的值全部都是0,而一旦动态库被加载并确定了基地址后,操作系统就会将动态库中定义的被可执行程序调用的函数的真实的绝对地址,更新到可执行程序数据段中的导入地址表中的对应位置。
这样每当可执行程序调用外部动态库中的函数时,其实被调用的是外部函数对应的本地的stub函数,然后stub函数内部再跳转到真实的动态库定义的函数中去。这样就解决了调用外部函数时call指令中的操作数仍然还是相对偏移值,只不过这个偏移值并不是相对于动态库中定义的函数的地址,而是相对于可执行程序本身内部定义的本地stub函数的函数地址。
下面的例子说明了可执行程序调用了C标准库动态库中的abs函数和printf函数的源代码:
#include <stdlib.h>
int foo()
{
return 0;
}
int main(int argc, char *argv[])
{
int a = abs(-1);
printf("%d",a); //上面两个都是动态库中定义和提供的函数
foo(); //这个是本地定义的函数
return 0;
}
那在代码被编译后实际的伪代码应该是如下:
#include <stdlib.h>
//定义导入地址表结构
typdef struct
{
char *fnname;
void *fnptr;
}iat_t;
iat_t _giat[] = {{"abs", 0}, {"printf",0}};
int foo()
{//本地函数不会在导入地址表中
return 0;
}
int main(int argc, char *argv[])
{
int a = _stub_abs(-1);
_stub_printf("%d", a);
foo();
}
int _stub_abs(int v)
{
return _giat[0].fnptr(v);
}
void _stub_printf(char *fmt, ...)
{
_giat[1].fnptr(fmt, ...);
}
通过上面的代码可以看出来在将可执行程序编译链接时,所有的函数调用call指令中的地址值部分都可以指定为相对偏移值。对于程序中调用到的动态库中定义的函数,则会在main函数运行前,动态库被加载后更新_giat表中的所有函数的真实地址,这样就实现了动态库中的函数调用了。
当然了上面介绍的动态库函数调用的原理在每种操作系统下可能会有一些差异。Facebook所提供的一个开源的iOS库fishhook的内部实现就是通过修改_giat表中的真实函数地址来实现函数调用的替换的。
当你了解到了动态库中函数调用的机制后,其实你也是可以任意修改一个程序中调用的所有外部动态库的函数的逻辑的,因为导入地址表存放在数据段,其值可以被任意修改,因此你也可以将某个函数调用的真实实现变为你想要的任意实现。很多越狱后的应用就是通过修改导入地址表中的函数地址而实现函数调用的重定向的逻辑的。
再来考察一下_stub_xxx函数的实现,如果你切换到程序的汇编指令代码视图时,你就会发现几乎所有的_stub_xxx函数的代码都是一样的。这里的_stub_xxx函数块就是thunk技术的一种实际应用场景。下面是iOS的arm64位系统中关于动态库函数调用实现:

你会发现每个_stub函数只有3条指令:
_stub_obj_msgSend:
nop
ldr x16, 0x1640
br x16
一条是nop空指令、一条是将导入符号表中真实函数地址保存到x16寄存器中、一条是跳转指令。这里的跳转指令不用blr而用br的原因是如果采用blr则将会再次形成一个调用栈的生成,这样在调试和断点时看到的将不是真实的函数调用,而是_stub_xxx函数的调用,而跳转指令只是简单的将函数的调用跳转到真实的函数入口地址中去,并且不需要再次进行函数调用进栈和出栈处理,正是这样的设置使得对于外面而言就像是直接调用动态库的函数一样。因此可以看出thunk技术其实是一种代码重定向的技术,并且这种重定向并不会影响到函数参数的入栈和出栈处理,对于调用者来说就好像是直接调用的真实函数一样。
iOS系统中一个程序中的所有stub函数的符号和实现分别存放在代码段__TEXT的_stubs和_stub_helper两个section中。
二、C++中虚函数调用的实现原理。
C++语言是一门面向对象的语言,面向对象思想中对多态的支持是其核心能力。所谓多态描述的是对象的行为可以在运行时来决定。对象的行为在语义层面上表现为类中定义的方法函数。一般情况下对具体函数的调用会在编译时就被确定下来,那如何能将函数的调用转化为运行时再进行确定呢? 在C++中通过将成员函数定义为虚函数(virtual function)就能达到这个效果。来看一下如下代码:
class CA
{
public:
void foo1()
{
printf("CA::foo1\n");
}
virtual void foo2()
{
printf("CA::foo2\n");
}
virtual void foo3()
{
printf("CA::foo3\n");
}
};
class CB: public CA
{
public:
void foo1()
{
printf("CB::foo1\n");
}
virtual void foo2()
{
printf("CB::foo2\n");
}
virtual void foo4()
{
printf("CB::foo4\n");
}
};
void func(CA *p)
{
p->foo1();
p->foo2();
p->foo3();
}
int main(int argc, char *argv[])
{
CA *p1 = new CA;
CB *p2 = new CB;
func(p1);
func(p2);
delete p1;
delete p2;
return 0;
}
示例代码中CA定义了一个普通成员函数foo1和两个虚函数foo2, foo3。CB继承自CA并覆写foo1函数和重载了foo2函数。上述代码运行得到如下的结果:
CA::foo1
CA::foo2
CA::foo3
CA::foo1
CB::foo2
CA::foo3
可以看出来在func函数内无论你传递的对象是基类CA的实例还是派生类CB的实例当调用foo1函数时总是打印的是基类的foo1函数中的内容,而调用foo2函数时就会区分是基类对象的实现还是派生类对象的实现。在函数func中它的参数指向的总是一个CA对象,因为编译器是不知道运行时传递的到底是基类还是派生类的对象实例,那么系统又是如何实现这种多态的特性的呢?
在C++中,一旦类中有成员函数被定义为虚函数(带有virtual关键字)就会在编译链接时为这个类建立一个全局的虚函数表(virtual table),这个虚函数表中每个条目的内容保存着被定义为虚函数的函数地址指针。每当实例化一个定义有虚函数的对象时,就会将对象的中的一个隐藏的数据成员指针(这个指针称之为vtbptr)指向为类所定义的虚函数表的开始地址。整个结构就如下面的图中展示的一样:
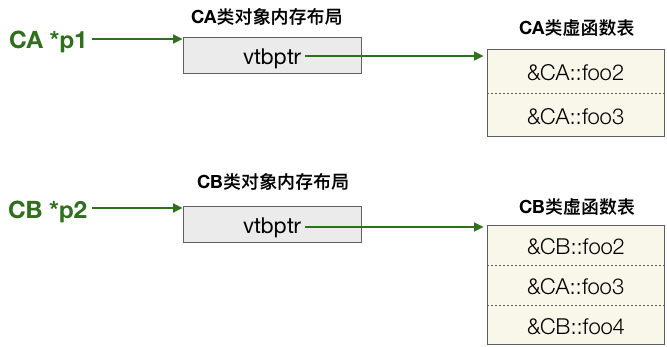
因此上面的代码在被编译后其实就会转化为如下的完整伪代码:
struct CA
{
void *vtbptr;
};
struct CB
{
void *vtbptr;
};
//因为C++中有函数命名修饰,实际的名字不应该是这样的,这里是为了让大家更好的理解函数的定义和实现
void CA::foo1(CA * const this)
{
printf("CA::foo1\n");
}
void CA::foo2(CA *const this)
{
printf("CA::foo2\n");
}
void CA::foo3(CA *const this)
{
printf("CA::foo3\n");
}
void CB::foo1(CB *const this)
{
printf("CB::foo1\n");
}
void CB::foo2(CB *const this)
{
printf("CB::foo2\n");
}
//定义2个类的全局虚拟函数表
void * _gCAvtb[] = {&CA::foo2, &CA::foo3};
void * _gCBvtb[] = {&CB::foo2, &CA::foo3, &CB::foo4};
void func(CA *p)
{
CA::foo1(p); //这里被编译为正常函数的调用
p->vtbptr[0](p); //这里被编译为虚函数调用的实现代码。
p->vtbptr[1](p);
}
int main(int argc, char *argv[])
{
CA *p1 = (CA*)malloc(sizeof(CA));
p1->vtbptr = _gCAvtbl;
CB *p2 = (CB*)malloc(sizeof(CB));
p2->vtbptr = _gCBvtbl;
func(p1);
func(p2);
free(p1);
free(p2);
return 0;
}
观察上面函数func的实现可以看出来,当对程序进行编译时,如果发现调用的函数是非虚函数那么就会在代码中直接调用类中定义的函数,如果发现调用的是虚函数时那么在代码中将会使用间接调用的方法,也就是通过调用虚函数表中记录的函数地址,这样就实现了所谓的多态和运行时动态确定行为的效果。从上面的代码实现中您也许会发现这里和前面关于动态库函数调用实现有类似的一些机制:都定义了一个表格,表格中存放的是真正要调用的函数地址,而在外部调用这些函数时,并不是直接调用定义的函数的地址,而是采用了间接调用的方式来实现,这个间接调用方式都是用比较统一和相似的代码块来实现。查看虚函数的调用对应的汇编代码时你可能会看到如下的代码片段:
//macOS中的x86_64位下的汇编代码
movq -0x8(%rbp), %rdi ;CA对象的p1保存到%rdi寄存器中。
callq 0x100000e80 ;非虚函数CA::foo1采用直接调用的方式
movq (%rdi), %rax ;将p1中的虚函数表vtbptr指针取出保存到%rax中
callq *(%rax) ;间接调用虚函数表中的第一项也就是foo2函数所保存的位置
callq *0x8(%rax) ;间接调用虚函数表中的第二项也就是foo3函数所保存的位置
可见在C++中对虚拟函数进行调用的代码的实现也是用到了thunk技术。除了虚函数调用这里使用了thunk技术外,C++还在另外一种场景中使用到了thunk技术。
严格来说其实C++的虚函数调用机制的实现不应该纳入thunk技术的一种实现,但是某种意义上虚函数调用确实又是高级语言直接调用而在编译后又通过安插特定代码来实现真实的函数调用的。
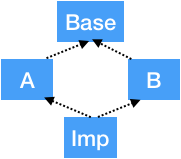
三、C++中基于接口的多重继承中对thunk技术的使用
在C++的基于接口编程的一些技术解决方案中(比如早期Windows的COM技术)。往往会设计一个系统公用的基接口(比如COM的IUnknown接口),然后所有的接口都从这个基接口进行派生,而一个实现类往往会实现多个接口。整个设计结构可用如下代码表示:
//定义共有抽象基接口
class Base
{
public:
virtual void basefn() = 0;
};
//定义派生接口
class A : public Base
{
public:
virtual void afn() = 0;
};
//定义派生接口
class B : public Base
{
public:
virtual void bfn() = 0;
};
//实现类Imp同时实现A和B接口。
class Imp: public A, public B
{
public:
virtual void basefn() { printf("basefn\n");}
virtual void afn() { printf("afn\n");}
virtual void bfn() { printf("bfn\n");}
int m_;
};
int main(int argc, char *argv[])
{
Imp *pImp = new Imp;
A *pA = pImp;
B *pB = pImp;
pImp->basefn();
pA->basefn();
pB->basefn();
delete pImp;
return 0;
}
上面的这种继承关系图如下:
根据C++对虚函数的支持实现以及多重继承支持,上面的Imp类的对象实例的内存布局以及虚函数表的布局结构如下:
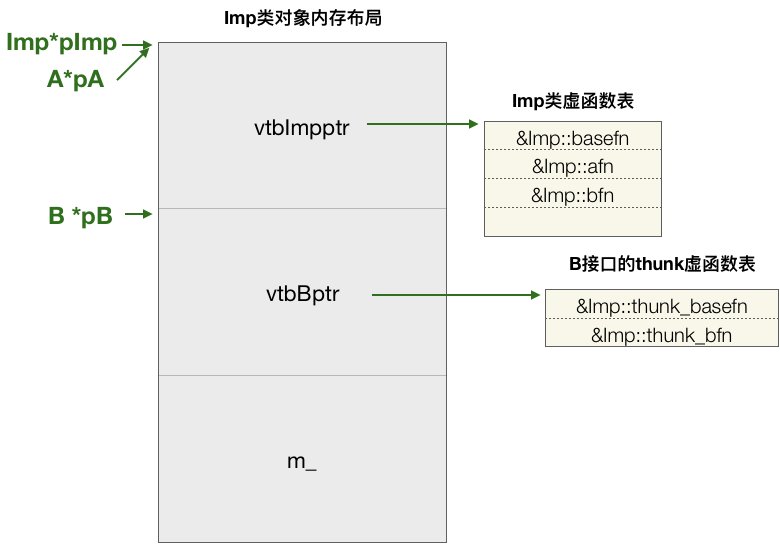
因此上面的代码在编译后真实的伪代码实现如下:
struct Base
{
void *vtbptr;
};
struct A
{
void *vtbptr;
};
struct B
{
void *vtbptr;
};
struct Imp
{
void *vtbImpptr;
void *vtbBptr;
int m_;
};
void Imp::basefn(Imp * const this)
{
printf("basefn\n");
}
void Imp::afn(Imp *const this)
{
printf("afn\n");
}
void Imp::bfn(Imp *const this)
{
printf("bfn\n");
}
void Imp::thunk_basefn(B * const this)
{
Imp *pThis = this - 1;
Imp::basefn(pThis);
}
void Imp::thunk_bfn(B *const this)
{
Imp *pThis = this - 1;
Imp::bfn(pThis);
}
//定义2个的全局虚函数表
void * _gImpvtb[] = {&Imp::basefn, &Imp::afn, &Imp::bfn};
void * _gImpthunkBvtb[] = {&Imp::thunk_basefn, &Imp::thunk_bfn};
int main(int argc, char *argv[])
{
Imp *pImp = (Imp*)malloc(sizeof(Imp));
pImp->vtbImpptr = _gImpvtb;
pImp->vtbBptr = _gImpthunkBvtb;
A *pA = pImp;
B *pB = pImp;
pImp->vtbImpptr[0](pImp);
pA->vtbImpptr[0](pA);
pB->vtbBptr[0](pB);
free(pImp);
return 0;
}
仔细观察第二个虚函数表中的两个条目,会发现B接口类虚函数表中的函数地址并不是Imp::basefn和Imp::bfn,而是两个特殊的并未公开的函数,这两函数实现如下:
void Imp::thunk_basefn(B * const this)
{
Imp *pThis = this - 1;
Imp::basefn(pThis);
}
void Imp::thunk_bfn(B * const this)
{
Imp *pThis = this - 1;
Imp::bfn(pThis);
}
两个函数内部只是简单的将对象指针转化为了派生类对象的指针并调用真实的函数实现。那为什么B接口虚函数表中的函数地址不是真实的函数地址而是一个thunk函数的地址呢?其实从上面的对象的内存布局结构就能找出答案。因为Imp是从B进行的多重继承,所以当将一个Imp类对象的指针,转化为基类B的指针时,其实指针的值是增加了8个字节(如果是32位就4个字节)。又因为B和A都是从Base派生的,因此不管是B还是A都可以调用fnBase函数,但这样就会出现入参的地址不一致的问题。举例来说,假如实例化一个Imp对象并且为其分配在内存中的地址为0x1000,就如如下代码:
Imp *pImp = new Imp; //假设这里分配的地址是0x1000, 也就是pImp == 0x1000
A *pA = pImp; //因为A是Imp的第一个基类,所以根据类型转换规则得到的pA == 0x1000 ,pA和pImp指向同一个地址。
B *pB = pImp; //因为B是Imp的第二个基类,所以根据类型转换规则得到pB == 0x1008,pB等于pImp的值往下偏移8个字节。
pImp->basefn(); //转化为pImp->vtbImpptr[0](0x1000);
pA->basefn(); //转化为pA->vtbptr[0](0x1000);
pB->basefn(); //转化为pB->vtbptr[0](0x1008);
可以看出如果基接口B中的虚函数表的第一个条目保存的也是Imp::basefn的话,因为最终的实现是Imp类,而且basefn接收的参数也是Imp指针,但是因为调用者是pB,对象指针被偏移了8个字节,这样就产生了同一个函数实现接收两个不一致的this地址的问题,从而产生错误的结果,因此为了纠正转化为B类指针时调用会产生的问题,就必须将B接口的虚函数表中的所有条目改成为一个个thunk函数,这些thunk函数的作用就是对this指针的地址进行真实的调整,从而保证函数调用的一致性。可以看出在这里thunk技术又再次的被应用到实际的问题解决中来了。下面是这个thunk代码块的macOS系统下x86_64位的汇编代码实现:
xxxx`non-virtual thunk to Imp::bfn():
0x100000f30 <+0>: pushq %rbp
0x100000f31 <+1>: movq %rsp, %rbp
0x100000f34 <+4>: subq $0x10, %rsp
0x100000f38 <+8>: movq %rdi, -0x8(%rbp)
0x100000f3c <+12>: movq -0x8(%rbp), %rdi
0x100000f40 <+16>: addq $-0x8, %rdi //指针位置修正
0x100000f44 <+20>: callq 0x100000ee0 ; Imp::bfn at main.cpp:43
0x100000f49 <+25>: addq $0x10, %rsp
0x100000f4d <+29>: popq %rbp
0x100000f4e <+30>: retq
运行时使用thunk技术的方法和实现
上面介绍的3种使用thunk技术的地方都是在编译阶段通过插入特定的thunk代码块来完成的,在编译高级语言时会自动生成一些thunk代码块函数,并且会对一些特殊的函数调用改为对thunk代码块的调用,这些调用逻辑一旦确定后就无法再进行改变了。因此我们不可能使用编译时的thunk技术来解答文本的qsort函数排序的需求。那除了由编译器生成thunk代码块外,在程序运行时是否可以动态的来构造一个thunk代码块呢?答案是可以的,要想动态来构造一个thunk代码块,首先要了解函数的调用实现过程。
下面举例中的机器指令以及参数传递主要是iOS的arm64位下面的规定,如果没有做其他说明则默认就是指的iOS的arm64位系统。
函数调用以及参数传递的机器指令实现
一个函数签名中除了有函数名外,还可能会定义有参数。函数的调用者在调用函数时除了要指定调用的函数名时还需要传入函数所需要的参数,函数参数从调用者传递给实现者。在编译代码时会将对函数的调用转化为call/bl指令和对应的函数的地址。那么编译器又是来解决参数的传递的呢?为了解决这个问题就需要在调用者和实现者之间形成一个统一的标准,双方可以约定一个特定的位置,这样当调用函数前,调用者先把参数保存到那个特定的位置,然后再执行函数调用call/bl指令,当执行到函数内部时,函数实现者再从那个特定的位置将数据读取出来并处理。参数存放的最佳位置就是栈内存区域或者CPU中的寄存器中,至于是采用哪种方法则是根据不同操作系统平台以及不同CPU体系结构而不同,有些可能规定为通过栈内存传递,而有些规定则是通过寄存器传递,有些则采用两者的混合方式进行传递。就以iOS的64位arm系统来说几乎所有函数调用的参数传递都是通过寄存器来实现的,而当函数的参数超过8个时才会用到栈内存空间来进行参数传递,并且进一步规定非浮点数参数的保存从左到右依次保存到x0-x8中去,并且函数的返回值一般都保存在x0寄存器中。因此下面的函数调用和实现高级语言的代码:
int foo(int a, int b, int c)
{
return a + b + c;
}
int main(int argc, char *argv[])
{
int ret = foo(10, 20, 30);
return 0;
}
最终在转化为arm64位汇编伪代码就变为了如下指令:
//真实中并不一定有这些指令,这里这些伪指令主要是为了让大家容易去理解
int foo(int a, int b, int c)
{
mov a, x0 ;把调用者存放在x0寄存器中的值保存到a中。
mov b, x1 ;把调用者存放在x1寄存器中的值保存到b中。
mov c, x2 ;把调用者存放在x2寄存器中的值保存到c中。
add x0, a, b, c ;执行加法指令并保存到x0寄存器中供返回。
ret
}
int main(int argc, char *argv[])
{
mov x0, #10 ;将10保存到x0寄存器中
mov x1, #20 ;将20保存到x1寄存器中
mov x2, #30 ;将30保存到x2寄存器中
bl foo ;调用foo函数指令
mov ret, x0 ;将foo函数返回的结果保存到ret变量中。
mov x0, #0 ;将main函数的返回结果0保存到x0寄存器中
ret
}
至此,我们基本了解到了函数的调用和参数传递的实现原理,可见无论是函数调用还是参数传递都是通过机器指令来实现的。
动态构建内存指令块
一个运行中的程序无论是其指令代码还是数据都是以二进制的形式存放在内存中,程序代码段中的指令代码是在编译链接时就已经产生了的固定指令序列。当然,只要在内存中存放的二进制数据符合机器指令的格式,那么这块内存中存储的二进制数据就可以送到CPU当中去执行。换句话说就是机器指令除了可以在编译链接时静态生成还可以在程序运行过程中动态生成。这个结论的意义在于我们甚至可以将指令数据从远端下载到本地进程中,并且在程序运行时动态的改变程序的运行逻辑。
参考上面关于函数调用以及参数传递的实现可以得出,qsort函数接收一个比较器compar函数指针,函数指针其实就是一块可执行代码的内存首地址。而每次在进行两个元素的比较时都会先将两个元素参数分别保存到x0,x1两个寄存器中,然后再通过 bl compar指令实现对比较器函数的调用。为了让qsort能够支持对带扩展参数的比较器函数调用,我们可以动态的构造出一段指令代码(这段指令代码就是一个thunk程序块)。代码块的指令序列如下:
- 将寄存器x1的值保存到x2中。
- 将寄存器x0的值保存到x1中。
- 将扩展参数的值保存到x0中。
- 将带扩展参数的真实比较器函数的地址保存到x3中去
- 跳转到x3寄存器所保存的带扩展参数的真实比较器函数中去。
然后再将这些指令对应的二进制机器码保存到某个已经分配好的内存块中,最后再将这块分配好的内存块首地址(thunk比较器函数地址),作为qsort的compar函数比较器指针的参数。这样当qsort内部在需要比较时就先把两个比较的元素分别存放入x0,x1中并调用这个thunk比较器函数。而当执行进入thunk比较器函数内部时,就会如上面所写的把原先的x0,x1两个寄存器中的值移动到x1,x2中去,并把扩展参数移动到x0中,然后再跳转一个真实的带扩展参数的比较器函数中去,等真实的带扩展参数的比较器函数比较完成返回时,thunk比较器函数就会将结果返回给qsort函数来告诉qsort比较的结果。这个过程中其实真正进行比较的是一个带扩展参数的真实比较器函数,但是我们却通过thunk技术欺骗了qsort函数,让qsort函数以为执行的仍然是一个不带扩展参数的比较器函数。
可执行代码的执行权限
为了方便管理和安全的需要,操作系统对一个进程中的虚拟内存空间进行了权限的划分。某些区域被设置为仅可执行,比如代码段所加载的内存区域;而某些区域则被设置为可读写,比如数据段所加载的内存区域;而某些区域则被设置为了只读,比如常量数据段所加载的内存区域;而某些区域则被设置了无读写访问权限,比如进程的虚拟内存的首页地址区域(0到4096这块区域)。程序中代码段所加载的内存区域只供可执行,可执行表明这块区域的内存中的数据可以被CPU执行以及进行读取访问,但是不能进行改写。不能改写的原因很简单,假如这块区域的内容可以被改写的话,那就可以在运行时动态变更可执行逻辑,这样整个程序的逻辑就会乱套和结果未可知。因此几乎所有操作系统中的进程内存中的代码要想被执行则这块内存区域必须具有可执行权限。有些操作系统甚至更加严格的要求可执行的代码所属的内存区域必须只能具有可执行权限,而不能具有写权限。
内存映射文件技术实现权限动态调整
上一个小结中我们说到可以在程序运行时动态的在内存中构建出一块指令代码来让CPU执行。如果是这样的话那就和可执行的内存区域只能是可执行权限互相矛盾了。为了解决让动态分配的内存块具有可执行的权限,可以借助内存映射文件的技术来达到目的。内存映射文件技术是用于将一个磁盘中的文件映射到一块进程中的虚拟内存空间中的技术,这样我们要对文件进行读写时就可以用内存地址进行读写访问的方式来进行,而不需要借助文件的IO函数来执行读写访问操作。内存映射文件技术大大简化了对文件进行读写操作的方式。而且其实当可执行程序在运行时,操作系统就是通过内存映射文件技术来将可执行程序映射到进程的虚拟内存空间中来实现程序的加载的。内存映射文件技术还可以指定和动态修改文件映射到内存空间中的访问权限。而且内存映射文件技术还可以在不关联具体的文件的情况下来实现虚拟内存的分配以及对分配的内存进行权限的设置和修改的能力。因此可以借助内存映射文件技术来实现对内存区域的可执行保护设置。下面的代码就演示了这种能力:
#include <sys/mman.h>
int main(int argc, char *argv[])
{
//分配一块长度为128字节的可读写和可执行的内存区域
char *bytes = (char *)mmap(0, 128, PROT_EXEC|PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0);
memcpy(bytes, "Hello world!", 13);
//修改内存的权限为只可读,不可写。
mprotect(bytes, 128, PROT_READ);
printf(bytes);
memcpy(bytes, "Oops!", 6); //oops! 内存不可写!
return 0;
}
iOS上的thunk代码实现
前面介绍了动态构建内存指令的技术,以及让qsort支持带扩展参数的函数比较器的方法介绍,以及内存映射文件技术的介绍,这里将用具体的代码示例来实现一个在iOS的64位arm系统下的thunk代码实现。
#include <sys/mman.h>
//因为结构体定义中存在对齐的问题,但是这里要求要单字节对齐,所以要加#pragma pack(push,1)这个编译指令。
#pragma pack (push,1)
typedef struct
{
unsigned int mov_x2_x1;
unsigned int mov_x1_x0;
unsigned int ldr_x0_0x0c;
unsigned int ldr_x3_0x10;
unsigned int br_x3;
void *arg0;
void *realfn;
}thunkblock_t;
#pragma pack(pop)
typedef struct
{
int age;
char *name;
}student_t;
//按年龄升序排列的函数
int ageidxcomparfn(student_t students[], const int *idx1ptr, const int *idx2ptr)
{
return students[*idx1ptr].age - students[*idx2ptr].age;
}
int main(int argc, const char *argv[])
{
student_t students[5] = {{20,"Tom"},{15,"Jack"},{30,"Bob"},{10,"Lily"},{30,"Joe"}};
int idxs[5] = {0,1,2,3,4};
//第一步: 构造出机器指令
thunkblock_t tb = {
/* 汇编代码
mov x2, x1
mov x1, x0
ldr x0, #0x0c
ldr x3, #0x10
br x3
arg0:
.quad 0
realfn:
.quad 0
*/
//机器指令: E2 03 01 AA E1 03 00 AA 60 00 00 58 83 00 00 58 60 00 1F D6
.mov_x2_x1 = 0xAA0103E2,
.mov_x1_x0 = 0xAA0003E1,
.ldr_x0_0x0c = 0x58000060,
.ldr_x3_0x10 = 0x58000083,
.br_x3 = 0xD61F0060,
.arg0 = students,
.realfn = ageidxcomparfn
};
//第二步:分配指令内存并设置可执行权限
void *thunkfn = mmap(0, 128, PROT_EXEC|PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0);
memcpy(thunkfn, &tb, sizeof(thunkblock_t));
mprotect(thunkfn, sizeof(thunkblock_t), PROT_EXEC);
//第三步:为排序函数传递thunk代码块。
qsort(idxs, 5, sizeof(int), (int (*)(const void*, const void*))thunkfn);
for (int i = 0; i < 5; i++)
{
printf("student:[age:%d, name:%s]\n", students[idxs[i]].age, students[idxs[i]].name);
}
munmap(thunkfn, 128);
return 0;
}
因为arm64系统中每条指令都占用4个字节,因此为了方便实现前面介绍的逻辑可以建立一个如下的结构体:
#pragma pack (push, 1)
typedef struct
{
unsigned int mov_x2_x1; //保存 mov x2, x1 的机器指令
unsigned int mov_x1_x0; //保存 mov x1, x0 的机器指令
unsigned int ldr_x0_0x0c; //将arg0中的值保存到x0中的机器指令
unsigned int ldr_x3_0x10; //将realfn中的值保存到x3中的机器指令
unsigned int br_x3; // 保存 br x3 的机器指令
void *arg0;
void *realfn;
}thunkblock_t;
#pragma pack (pop)
上述结构体中第三个和第四个数据成员所描述的指令如下:
ldr x0, #0xc0
ldr x3, #0x10
第三条指令的意思是将从当前位置偏移0xc0个字节位置中的内存中的数据保存到x0寄存器中,根据偏移量可以得出刚好arg0的位置和指令当前位置偏移0xc0个字节。同理可以得到第四条指令是将realfn的值保存到x3寄存器中。这里设计为这样的原因是为了方便数据的读取,因为动态构造的指令块对和指令自身连续存储的内存地址访问要比访问其他不连续的特定内存地址访问要简单得多,只需要简单的读取当前指令偏移特定值的地址即可。
再接下来的代码中可以看出初始化这个结构体的代码:
thunkblock_t tb = {
/* 汇编代码
mov x2, x1
mov x1, x0
ldr x0, #0x0c
ldr x3, #0x10
br x3
arg0:
.quad 0
realfn:
.quad 0
*/
//机器指令: E2 03 01 AA E1 03 00 AA 60 00 00 58 83 00 00 58 60 00 1F D6
.mov_x2_x1 = 0xAA0103E2,
.mov_x1_x0 = 0xAA0003E1,
.ldr_x0_0x0c = 0x58000060,
.ldr_x3_0x10 = 0x58000083,
.br_x3 = 0xD61F0060,
.arg0 = students, //第一个参数保存的就是扩展的参数students数组
.realfn = ageidxcomparfn //真实的带扩展参数的比较器函数地址ageidxcomparfn
};
这段代码可以看到thunk程序块的汇编指令和对应的16进制机器指令,因此在构造结构体的数据成员时,只需要将特定的16进制值赋值给对应的数据成员即可,在最后的arg0中保存的是扩展参数students的指针,而realfn中保存的就是真实的带扩展参数的比较器函数地址。 当thunkblock_t结构体初始化完成后,结构体tb中的内容就是一段可被执行的thunk程序块了,接下来就需要借助内存映射文件技术,将这块代码存放到一个只有可执行权限的内存区域中去,这就是上面实例代码的第二步所做的事情。最后第三步则只需要将内存映射生成的可执行thunk程序块的首地址作为qsort函数的最后一个参数即可。
注意!!! 在iOS系统中如果您的应用需要提交到appstore进行审核,那么当你用Distrubution证书和provison配置文件所打出来的应用程序包是不支持将某个内存区域设置为可执行权限的!也就是上面的mprotect函数执行时会失效。因为iOS系统内核会对从appstore下载的应用程序中的可执行代码段进行签名校验,而我们动态分配的可执行内存区域是无法通过签名校验的,所以代码必定会运行失败。iOS系统这样设置的目的还是为了防止我们通过动态指令下载来实现热修复的技术。但是上述的代码是可以在开发者证书以及模拟器上运行通过的,因此切不可将这个技术解决方案用在需要发布证书签名校验的程序中。虽然如此但是我们还是可以用这项技术在开发版本和测试版本中来实现一些主线程检测、代码插桩的能力而不影响程序的性能的情况下来构建一些测试和检查的能力。
一个多平台下的完整thunk代码实现
除了实现iOS64位arm系统的thunk的例子外,下面是一段完整的thunk代码,它分别在windows64位操作系统、树莓派linux系统、macOS系统、以及iOS的x86_64位模拟器、arm、arm64位系统下验证通过,因为不同的操作系统以及不同CPU下的指令集不一样,以及函数调用的参数传递规则不一样,所以不同的系统下实现会略有差异,但是总体的原理是大同小异的。这里就不再详细介绍不同系统的差异了,从注释中的汇编代码你就能将逻辑和原理搞清楚。而且这段代码还可以复用到所有需要使用扩展参数但是又不支持扩展参数的那些回调函数中去。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#if defined(_MSC_VER)
#include <windows.h>
#else
#include <sys/mman.h>
#endif
void * createthunkfn(void *arg0, void *realfn)
{
#pragma pack (push,1)
typedef struct
{
#ifdef __arm__
unsigned int mov_r2_r1;
unsigned int mov_r1_r0;
unsigned int ldr_r0_pc_0x04;
unsigned int ldr_r3_pc_0x04;
unsigned int bx_r3;
#elif __arm64__
unsigned int mov_x2_x1;
unsigned int mov_x1_x0;
unsigned int ldr_x0_0x0c;
unsigned int ldr_x3_0x10;
unsigned int br_x3;
#elif __x86_64__
unsigned char ins[22];
#elif _MSC_VER && _WIN64
//windows
unsigned char ins[19];
#else
#warning "not support!"
#endif
void *arg0;
void *realfn;
}thunkblock_t;
#pragma pack(pop)
thunkblock_t tb = {
#if !defined(_MSC_VER)
#ifdef __arm__
/* 汇编代码
mov r2, r1
mov r1, r0
ldr r0, [pc, #0x04]
ldr r3, [pc, #0x04]
bx r3
arg0:
.long 0
realfn:
.long 0
*/
//机器指令: 01 20 A0 E1 00 10 A0 E1 04 00 9F E5 04 30 9F E5 13 FF 2F E1
.mov_r2_r1 = 0xE1A02001,
.mov_r1_r0 = 0xE1A01000,
.ldr_r0_pc_0x04 = 0xE59F0004,
.ldr_r3_pc_0x04 = 0xE59F3004,
.bx_r3 = 0xE12FFF13,
#elif __arm64__
/* 汇编代码
mov x2, x1
mov x1, x0
ldr x0, #0x0c
ldr x3, #0x10
br x3
arg0:
.quad 0
realfn:
.quad 0
*/
//机器指令: E2 03 01 AA E1 03 00 AA 60 00 00 58 83 00 00 58 60 00 1F D6
.mov_x2_x1 = 0xAA0103E2,
.mov_x1_x0 = 0xAA0003E1,
.ldr_x0_0x0c = 0x58000060,
.ldr_x3_0x10 = 0x58000083,
.br_x3 = 0xD61F0060,
#elif __x86_64__
/* 汇编代码
movq %rsi, %rdx
movq %rdi, %rsi
movq 0x09(%rip), %rdi
movq 0x0a(%rip), %rax
jmpq *%rax
arg0:
.quad 0
realfn:
.quad 0
*/
//机器指令: 48 89 F2 48 89 FE 48 8B 3D 09 00 00 00 48 8B 05 0A 00 00 00 FF E0
.ins = {0x48,0x89,0xF2,0x48,0x89,0xFE,0x48,0x8B,0x3D,0x09,0x00,0x00,0x00,0x48,0x8B,0x05,0x0A,0x00,0x00,0x00,0xFF,0xE0},
#endif
.arg0 = arg0,
.realfn = realfn
#elif _WIN64
/* 汇编代码
mov r8,rdx
mov rdx,rcx
mov rcx,qword ptr [arg0]
jmp qword ptr [realfn]
arg0 qword 0
realfn qword 0
*/
//机器指令:4c 8b c2 48 8b d1 48 8b 0d 06 00 00 00 ff 25 08 00 00 00
{0x4c,0x8b,0xc2,0x48,0x8b,0xd1,0x48,0x8b,0x0d,0x06,0x00,0x00,0x00,0xff,0x25,0x08,0x00,0x00,0x00},arg0,realfn
#endif
};
#if defined(_MSC_VER)
void *thunkfn = VirtualAlloc(NULL, 128, MEM_COMMIT, PAGE_EXECUTE_READWRITE);
#else
void *thunkfn = mmap(0, 128, PROT_EXEC|PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANON, -1, 0);
#endif
if (thunkfn != NULL)
{
memcpy(thunkfn, &tb, sizeof(thunkblock_t));
#if !defined(_MSC_VER)
mprotect(thunkfn, sizeof(thunkblock_t), PROT_EXEC);
#endif
}
return thunkfn;
}
void releasethunkfn(void *thunkfn)
{
if (thunkfn != NULL)
{
#if defined(_MSC_VER)
VirtualFree(thunkfn,128, MEM_RELEASE);
#else
munmap(thunkfn, 128);
#endif
}
}
typedef struct
{
int age;
char *name;
}student_t;
//按年龄升序排列的函数
int ageidxcomparfn(student_t students[], const int *idx1ptr, const int *idx2ptr)
{
return students[*idx1ptr].age - students[*idx2ptr].age;
}
int main(int argc, const char *argv[])
{
student_t students[5] = {{20,"Tom"},{15,"Jack"},{30,"Bob"},{10,"Lily"},{30,"Joe"}};
int idxs[5] = {0,1,2,3,4};
void *thunkfn = createthunkfn(students, ageidxcomparfn);
if (thunkfn != NULL)
qsort(idxs, 5, sizeof(int), (int (*)(const void*, const void*))thunkfn);
for (int i = 0; i < 5; i++)
{
printf("student:[age:%d, name:%s]\n", students[idxs[i]].age, students[idxs[i]].name);
}
releasethunkfn(thunkfn);
return 0;
}
后记
最早接触thunk技术其实是在10多年前的Windows的ATL库实现中,ATL库中通过thunk技术巧妙的将一个窗口句柄操作转化为了类的操作。当时觉得这个解决方案太神奇了,后来依葫芦画瓢将thunk技术应用到了一个快速排序的Windows程序中去,也就是本文例子中的原型,然后在开发中又发现了很多的thunk技术,所以就想写这么一篇thunk技术原理以及应用相关的文章。thunk技术还可以在比如函数调用的采集、埋点、主线程检测等等应用场景中使用。
欢迎大家访问欧阳大哥2013的github地址
