

这篇文章聊聊跟前端文件下载相关的一些知识。
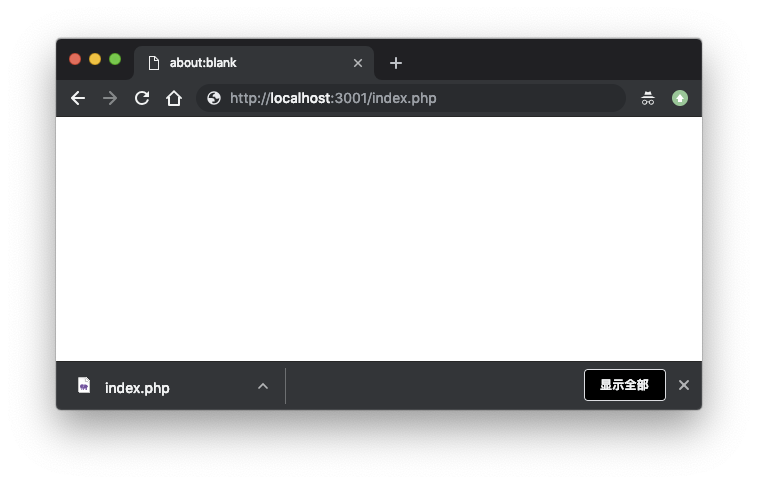
说到前端下载文件,我最先想到的是在学校的时候,自己搭建 nginx + php 环境,之后打开页面 http://localhost:80/index.php, 却奇怪的发现,每次打开都会变成文件下载。
后来我才知道,请求头里面会有 Accept 字段,响应头里面会有 Content-Type 字段,前者用来告诉 S 端能接受哪些类型的内容,后者告诉 C 端返回来的又是什么类型的内容。
MIME
MIME 是一种标准化的方式来表示文档的性质和格式,浏览器通常使用 MIME 来确定类型(而不是文件扩展名)。
content-type 使用的都是 MIME 类型,jpg 文件对应 image/jpeg , js 文件对应 application/javascript,xlsx 则是 application/vnd.openxmlformats-officedocument.spreadsheetml.sheet。
MIME 有两种默认类型:
text/plain表示文本文件的默认值。一个文本文件应当是人类可读的,并且不包含二进制数据。application/octet-stream表示所有其他情况的默认值。一种未知的文件类型应当使用此类型。
👆index.php 会变成文件下载的原因是我由于安装错误,没有正确解析 php 文件,nginx 直接访问到文件,并加上默认 contentType application/octet-stream。因为 Chrome 不能执行 application/octet-stream 格式的文件,默认操作是把它下载下来,(不同浏览器对待不能处理的文件执行的操作不一样,有些浏览器则会尝试去嗅探)。
这也能解释为什么我们直接访问https://xxx/foo/bar.zip 等资源的时候,浏览器会直接下载。
插播安全小课堂:
当服务端返回浏览器不支持的 MIME 类型,部分浏览器会尝试去嗅探它,帮大意的开发者修正这一错误,但这可能会导致你的网站遭受攻击。比方说,用户上传一张大熊猫图片,内容如下:
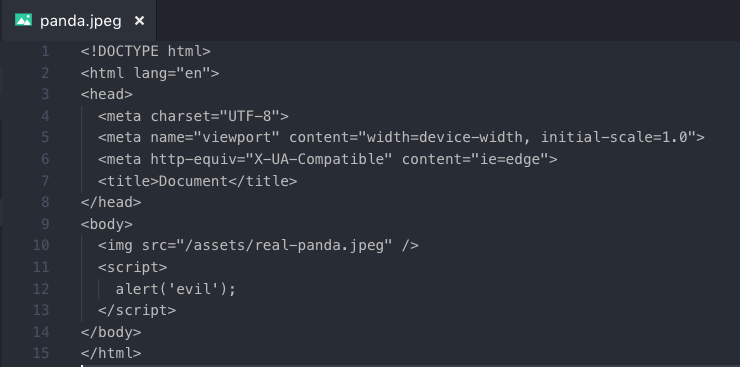
实际上是个 html 文件,但是后缀名写成 jpeg 上传。这时候服务端如果没有设置 contentType 直接读取文件返回给前端。
# koa router 演示代码
router.get('/assets/:file.jpeg', (ctx) => {
ctx.body = fs.createReadStream(`./public/assets/${ctx.params.file}.jpeg`);
});
好心的浏览器拿到 MIME type 为 application/octet-stream,再读取内容发现,诶,这是个 html 啊,我们应该展现直接展示出来。🌚🌚🌚
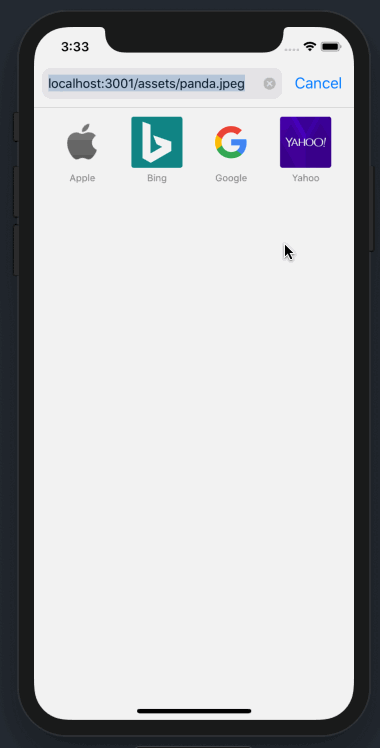
用户看到可爱的大熊猫同时,顺便把个人信息也告诉了黑客。
为了避免发生这种安全事故,设置
- 给返回内容加上对应的 contentType。
- 添加响应头
X-Content-Type-Options: nosniff,让浏览器不要尝试去嗅探
router.get('/assets/:file.jpeg', (ctx) => {
ctx.type = 'image/jpeg';
ctx.set('X-Content-Type-Options', 'nosniff');
ctx.body = fs.createReadStream(`./public/assets/${ctx.params.file}.jpeg`);
});
仅作为演示用,koa 提供静态资源服务应该用 koa-static 等开源包,它们会自动加上 contentType。
如何让浏览器下载图片
上面说了对应浏览器不支持的文档类型,默认会下载。那对于能处理的那些类型呢?比如图片,js,json 等内容呢?
以 json 为例,由于浏览器知道怎么解析,会在页面上打印出 json 的内容。
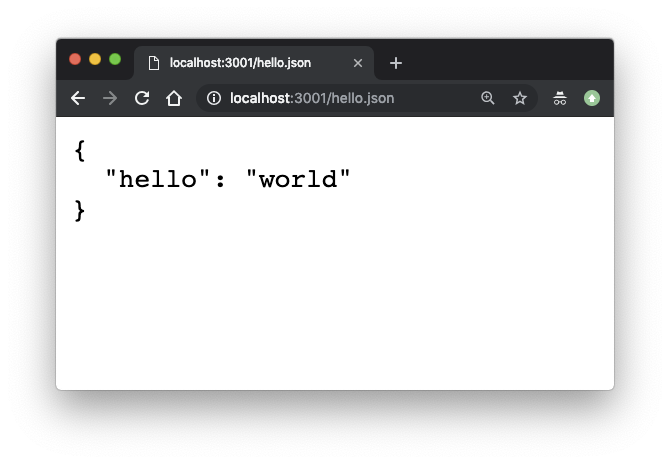
如果需求就是让用户下载 json 文件怎么办呢?
有另外一个响应头部字段 Conten-disposition 👹 ,Content-Disposition 指定响应的内容该以哪种形式展示,是以内联的形式(即网页或者页面的一部分),还是以附件的形式下载并保存到本地,分别对应 inline 和 attachment。
Content-Disposition: inline
Content-Disposition: attachment
attachment 模式,还可以指定下载文件的文件名和文件扩展名。
Content-Disposition: attachment; filename="filename.jpg"
示例代码:
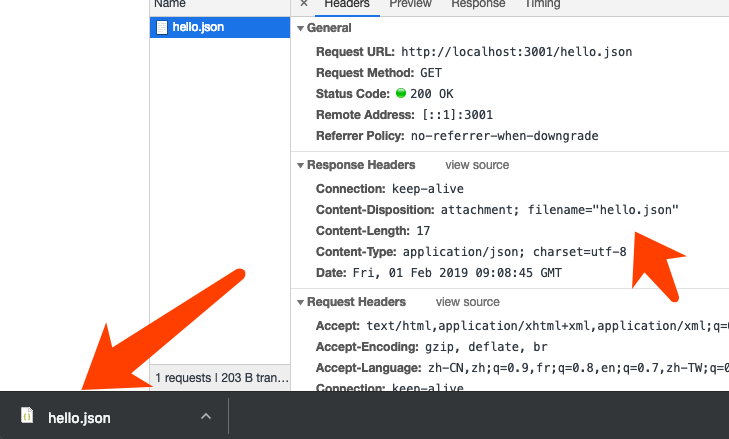
router.get('/hello.json', (ctx) => {
ctx.type = 'application/json';
ctx.set('Content-Disposition', 'attachment; filename="hello.json"');
// 上面两行代码,可以简写成 ctx.attachment('hello.json');
ctx.body = {
hello: 'world',
};
});
然后访问刚才的路由,就能看到文件下载下来了。
HTML Download 属性
还有一种方式让浏览器把文件保存到本地。就是 html5 a 标签增加的 download 属性。
<a href="/images/xxx.jpg" download="panda.jpg" >My Panda</a>
当用户点击标签时会去下载 href 指定的文件,并且 download 属性的 value 对应的就是下载文件的名字。更灵活地方式是封装成方法,动态创建 link,触发 click 直接下载并另存为。
<script>
function downloadAs (url, fileName) {
const link = document.createElement('a');
link.href = url;
link.download = fileName;
link.target = '_blank'
document.body.appendChild(link);
link.click();
link.remove();
}
downloadAs('http://localhost:3001/hello.json', 'world.json');
</script>
发起异步获取资源再下载
还有些场景,只能通过异步请求返回二进制内容再由前端下载。
借助 download 属性,结合 Blob, Url.createObjectURL() 可以实现前端异步请求资源并导出文件。
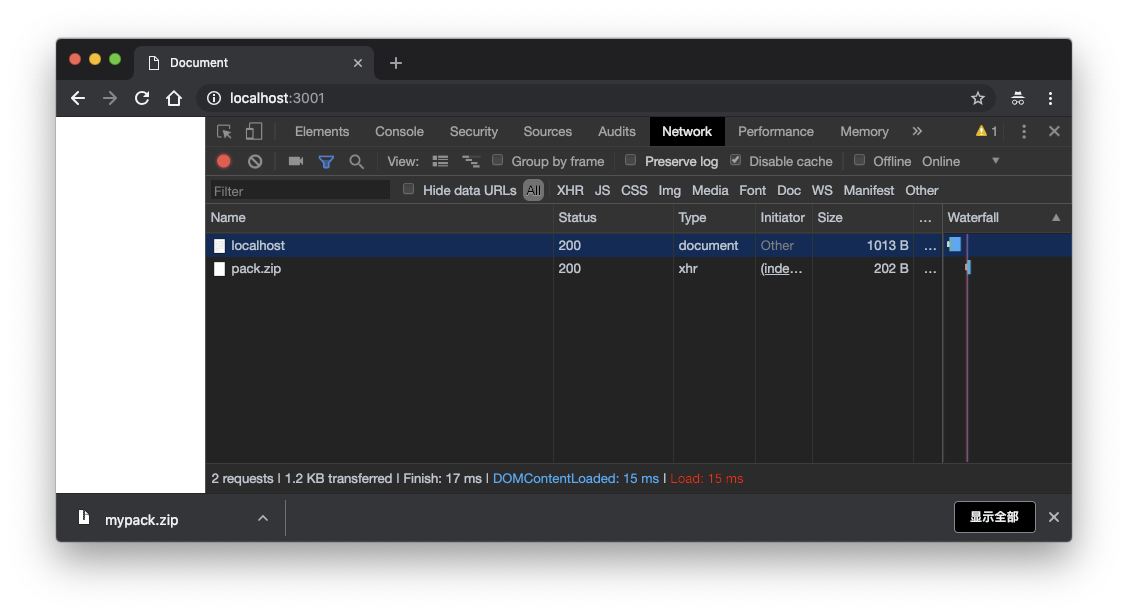
const xhr = new XMLHttpRequest();
xhr.open('GET', 'http://localhost:3001/pack.zip');
xhr.responseType = 'blob';
xhr.onload = function () {
const blob = xhr.response;
const url = URL.createObjectURL(blob);
downloadAs(url, 'mypack.zip');
URL.revokeObjectURL(url);
};
xhr.send();
设置 xhr.responseType = 'blob' 那么请求正常完成时 xhr.response 得到的就是 Blob 对象,URL.createObjectURL(Blob),得到一个 blob 的链接,形如:blob:http://localhost:3001/11a01a60-e10c-4515-825f-fb4a4219b33b。然后就能直接当成普通 url 给 a 标签设置 href。
Blob 对象表示一个不可变、原始数据的类文件对象。File 对象也是基于它扩展的,暂时理解为抽象的文件对象。
通过 URL.createObjectURL 会创建一个链接到 Blob 或 File 对象的 URL。这个 URL 的生命周期跟窗口绑定,避免内存泄漏用完应该调用URL.revokeObjectURL()释放。
Blob 可以接受的 Javascript 原生类型数据作为参数,比方说纯前端造 mock 数据,并导出成 csv 文件。
const rows = [
["id", "firstname", "lastname"],
["1", "foo", "foo"],
["2", "bar", "baz"],
];
const data = rows.reduce(function(cur, next) {
return cur + next.join(',') + '\n';
}, '');
const blob = new Blob([data]);
const url = URL.createObjectURL(blob);
downloadAs(url, 'mock.csv');
兼容性
download 属性的兼容性并不高,目前只有只有 80%。可以直接使用 FileSaver.js 做了 fallback 处理。

扩展阅读
吐槽
这篇文章原本标题叫《宇宙最强前端拖拽上传和文件下载》,写到一半查资料的时候发现掘金已经有很多人写过类似的文章。
心态崩了,改稿已经来不及,就这样吧。(浪费了大半天时间)
祝大家春节快乐,年终奖红红火火。

