

判别&生成
在机器学习中,对于监督学习我们可以将其分为两类模型:判别式模型和生成式模型。可以简单地说,生成式模型是针对联合分布进行建模,而判别式模型则针对条件分布建模。
从感性上认识,生成式能学习到更多信息,而判别式则较少,就好比学习英语,有类人只学会听懂这是英语,有类人学会了听懂这是英语并且知道说的是什么。另外,生成式模型在一定条件下也可以转换成判别式模型,比如通过贝叶斯公式进行转换。
常见生成式模型
- 混合高斯模型,估计了不同输入和类别的联合分布。
- 朴素贝叶斯,模型训练时采用联合概率分布积。
- 隐马尔科夫模型,建立了状态序列和观察序列的联合分布。
- 贝叶斯网络,概率图模型中的有向图网络,对联合分布建模,由各自局部条件概率分布相乘。
- 马尔科夫随机场,概率图模型中无向图网络,同样对联合分布建模,分解为极大团上势函数的乘积。
常见判别式模型
- 条件随机场,在观测序列上对目标序列进行建模。
- 线性回归,在X的条件下Y的分布。
- 逻辑回归,在x的条件下两个分类的概率。
- 支持向量机,它的训练过程是在学习分类边界。
- 传统神经网络,同样是学习分类边界。
一个简单例子
假设有训练样本:(1,0)、(1,0)、(2,0)、(2, 1),则
- 生成式模型学习的是联合概率p(x,y),
| y=0 | y=1 | |
|---|---|---|
| x=1 | 1/2 | 0 |
| x=2 | 1/4 | 1/4 |
- 判别式模型学习的是条件概率p(y|x),
| y=0 | y=1 | |
|---|---|---|
| x=1 | 1 | 0 |
| x=2 | 1/2 | 1/2 |
对比图
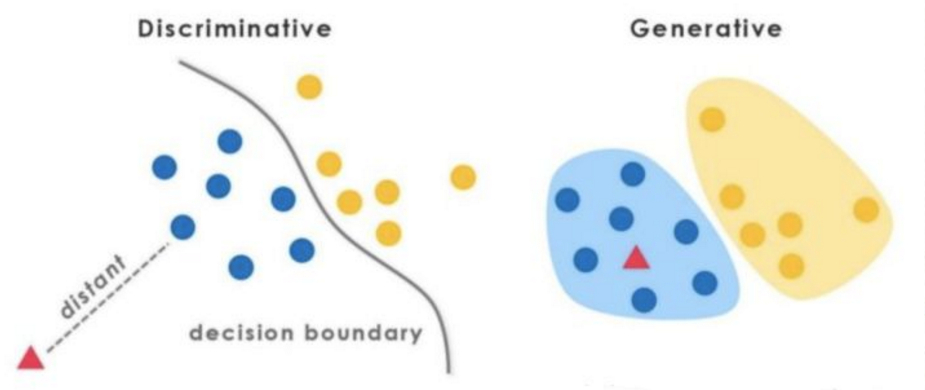
上图左边为判别式而右边为生成式,可以很清晰地看到差别,判别式模型是在寻找一个决策边界,通过该边界来将样本划分到对应类别。而生成式则不同,它学习了每个类别的边界,它包含了更多信息,可以用来生成样本。
生成式特点
- 对联合概率建模,学习所有分类数据的分布。
- 学习到的数据本身信息更多,能反应数据本身特性。
- 学习成本较高,需要更多的计算资源。
- 需要的样本数更多,样本较少时学习效果较差。
- 推断时性能较差。
- 一定条件下能转换成判别式。
判别式特点
- 对条件概率建模,学习不同类别之间最优边界。
- 捕捉不同类别特征的差异信息,不学习本身分布信息,无法反应数据本身特性。
- 学习成本较低,需要的计算资源较少。
- 需要的样本数可以较少,少样本也能很好学习。
- 预测时拥有较好性能。
- 无法转换成生成式。
-------------推荐阅读------------
我的开源项目汇总(机器&深度学习、NLP、网络IO、AIML、mysql协议、chatbot)
跟我交流,向我提问:

欢迎关注:

