

本文参考了多篇入门和进阶文章,主要介绍了 ES 安装部署、ES 基本概念、映射和索引模板相关的内容。
一、安装部署
1、Windows 单节点部署
对于 Windows 系统,安装 Elasticsearch 最为简单,直接从官方网址下载 ES 的安装包(.zip),下载完成后解压到本地磁盘的某个文件夹;待解压完成后,进入安装根路径的 bin 目录,双击 elasticsearch.bat 即可开始使用。
安装使用 ES 前,请保证 Java 已经安装成功,确保已设置
JAVA_HOME环境变量。
2、Linux 单节点部署
Linux 单节点部署请参考下面的 Linux 集群部署。
3、Linux 集群部署
集群部署可以参考文章:CentOS 7.4 下安装 ES 6.5.1 搜索集群
二、基本概念
部分内容来源:Elasticsearch安装与配置
1、NRT
Elasticsearch 是一个接近实时(Near Real Time)的搜索平台,也就是说,从建立索引,到这个索引可以被搜索需要很小的延迟,通常是 1 秒。
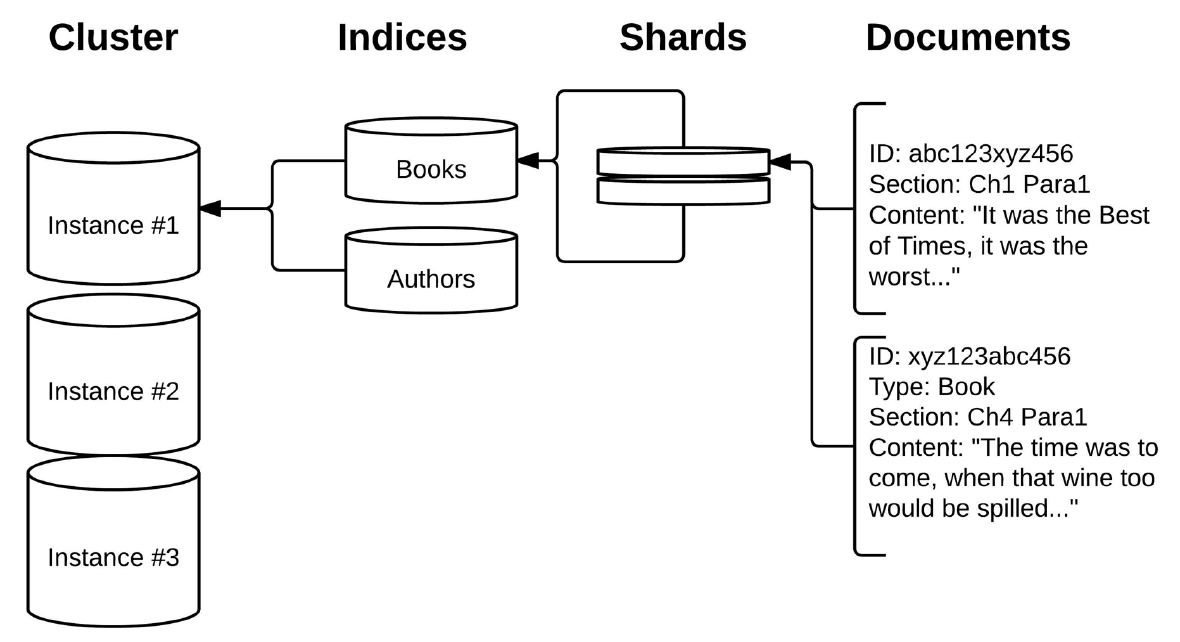
2、Cluster
一个集群就是由一个或多个节点组织在一起,这些节点共同持有全部的索引数据,并共同提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字很重要,一个节点只能通过指定某个集群的名字,来加入这个集群。
3、Node
一个节点就是集群中的一个服务,作为集群的一部分,它可以用来存储数据,参与集群的索引和搜索功能。对于许多应用场景来说,部署一个单节点的 ElasticSearch 服务就足够了;但是考虑到容错性和数据过载,配置多节点的 ElasticSearch 集群是明智的选择。
4、Index
一个索引就是一个拥有相似特征的文档(Document)的集合,ElasticSearch 把数据存放到一个或者多个索引中;一个索引由一个名字来标识,并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
5、Type
- ES 6.0 之前:在一个索引中,可以定义一种或多种类型;一个类型是索引的一个逻辑上的分类/分区;通常,会为具有一组相同字段的文档定义一个类型。
- ES 6.0 及更高版本:创建的索引只包含单个映射类型,映射类型将在 ES 7.0 中将完全移除。
许多人喜欢将index比喻为关系型数据库中的database,将type比喻为关系型数据库中的table,实际上这个比喻非常不贴切。因为在关系型数据库中,表中的字段都是独立的,但是在Elasticsearch中,在不同的type中,如果filed具有相同的名字,则这些不同的filed实际上是由相同的Lucene Filed提供支持的,因此这种比喻并不恰当;另一方面,在同一索引中存储具有很少或没有共同字段的不同实体会干扰Lucene有效压缩文档的能力。
6、Document
一个文档是可被索引的基础信息单元,文档以 JSON 格式来表示,在一个 index/type 里面,可以存储任意多的文档。文档由一个或者多个字段(Field)组成,每个字段(Field)由一个字段名和一个或者多个值组成。
7、Shards and Replicas
一个索引可以存储超出单个节点硬件限制的数据,例如一个具有 100 亿文档的索引占据 10TB 的磁盘空间,而任一节点可能没有这样大的磁盘空间来存储,或者单个节点处理搜索请求,响应会太慢。
Shards
为了解决这个问题,Elasticsearch 提供了将索引划分成多片的能力,这些片叫做分片。当用户创建一个索引的时候,可以指定分片的数量(默为 5,但是在 7.0 版本中默认会变为 1);每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许水平分割/扩展内容容量;
- 允许在分片(位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
Replicas
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由 Elasticsearch 管理的,对于用户来说,这些都是透明的。在一个网络/云的环境里,失败随时都可能发生。在某个分片/节点因为某些原因处于离线状态或者消失的情况下,故障转移机制是非常有用且强烈推荐的。为此,Elasticsearch 允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因:
- 在分片/节点失败的情况下,复制提供了高可用性;
- 复制分片不与原/主要分片放置再相同节点上;
- 搜索可以在所有的复制上并行运行,复制可以扩展你的搜索量/吞吐量。
总之,每个索引可以被分成多个分片,一个索引也可以被复制 0 次或多次;分片和复制的数量可以在索引创建的时候指定,索引创建之后,可以在任何时候动态地改变复制的数量,但是不能再改变分片的数量。
8、Field、Term、Token
- Field:它是 Document 的组成部分,由两部分组成,名称(name)和值(value);
- Term:它是搜索的基本单位,其表现形式为文本中的一个词;
- Token:它是单个 Term 在所属 Field 中文本的呈现形式,包含了 Term 内容、Term 类型、Term 在文本中的起始及偏移位置。
三、Mapping and Index Template
部分内容来源:论 Elasticsearch 数据建模的重要性
1、Mapping
映射(Mapping)是定义文档(Document)及其包含的字段(Field)的存储和索引方式的过程。
例如,使用映射来定义:
- 哪些字符串字段需要进行全文检索;
- 哪些字段数据类型为数字)、日期或地理位置;
- 是否应将文档中所有字段的值索引到
_all字段中; - 日期类型的格式(format);
- 用于控制动态添加字段的映射的自定义规则。
数据建模
数据类型
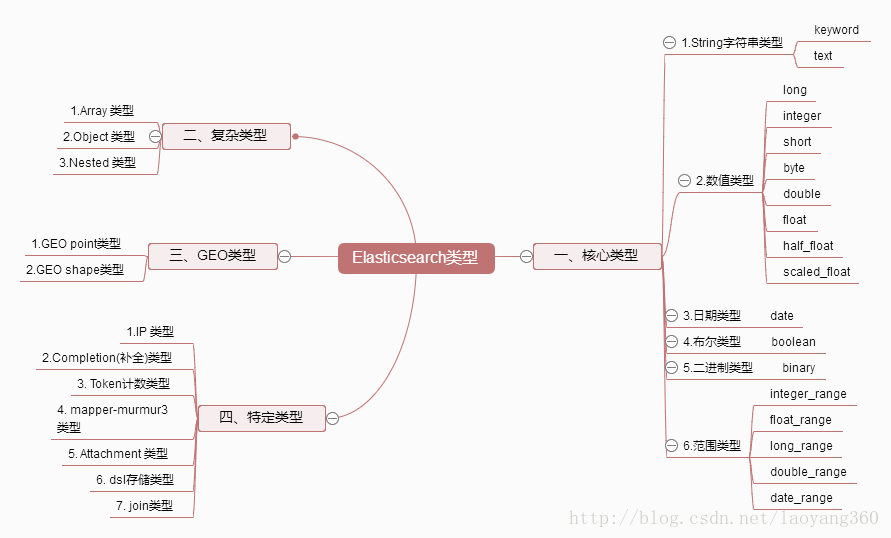
text 类型
- 特性:分词,将大段的文字根据分词器切分成独立的词或者词组,以便全文检索;
- 适用:email 内容、产品的描述等需要分词并全文检索的字段;
- 不适用:精准查询、过滤、排序或聚合(Significant Terms 聚合例外)。
keyword 类型
- 特性:无需分词、整段完整精确匹配;
- 适用:email 地址、状态码、分类 tags、电话号码、主外键等;
- 也适用:支持类似 mysql
like的查询; - 特别适用:精准查询、过滤、排序或聚合;
- 不适用:需要全文检索、内容过长的字段。
数值类型
long:带符号的 64 位整数;integer:带符号的 32 位整数;short:带符号的 16 位整数;byte:带符号的 8 位整数;double:双精度 64 位 IEEE 754 浮点数;float:单精度 32 位 IEEE 754 浮点数;half_float:半精度 16 位 IEEE 754 浮点数;- scaled_float:由长度固定的缩放因子支持的浮点数。
日期类型
日期支持时间戳和字符串,具体根据日期字段 format 的设置;
epoch_millis:时间戳(毫秒);strict_date_optional_time:通用 ISO 日期时间解析器,其中日期是必需的,时间是可选的。
"dtm_field": {
"mapping": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy/MM/dd HH:mm:ss||strict_date_optional_time||epoch_millis",
"store": "true"
}
}
可以通过设置索引 mapping 的
dynamic_date_formats参数来设置索引动态日期检测所匹配的日期格式。
布尔类型
false:false,“false”,“off”,“no”,“0”,“”(空字符串),0,0.0;true:以上 false 示例的反面,一切非假值。
二进制类型
二进制类型接受二进制值作为 Base64 编码字符串,该字段默认情况下不存储,不可搜索;可用于存储小图片,小文档等。
范围类型
integer_range:整型范围类型;float_range:单精度浮点范围类型;long_range:长整型范围类型;double_range:双精度范围类型;date_range:时间范围类型;ip_range:IP 范围类型
Array 数组类型
默认情况下,任何字段都可以包含零个或多个值,但是数组中的所有值必须是相同的数据类型。数组类型将单个数组元素做为一个数据单元,如果是分词的话也只是会依单个数组元素作为词源进行分词,不会将所有的数组元素整合到一起。在查询的时候如果数组里面的元素有一个能够命中那么将视为命中。
当使用 script 脚本时,使用
doc['xxxx'][0]即可获取字段的值,等同于常规情况下的doc['xxxx'].value。
object 对象类型
文档可能包含内部对象,而内部对象又可能包含其他内部对象。
## 用户写入
{
"region": "US",
"manager": {
"age": 30,
"name": {
"first": "John",
"last": "Smith"
}
}
}
## 实际存储
{
"region": "US",
"manager.age": 30,
"manager.name.first": "John",
"manager.name.last": "Smith"
}
nested 嵌套类型
nested 嵌套类型是 object 数据类型的特定版本,允许对象数组彼此独立地进行索引和查询。
## 用户写入
{
"group" : "fans",
"user" : [
{
"first" : "John",
"last" : "Smith"
},
{
"first" : "Alice",
"last" : "White"
}
]
}
## 实际存储
{
"group" : "fans",
"user.first" : [ "alice", "john" ],
"user.last" : [ "smith", "white" ]
}
默认情况下,每个索引最多创建 50 个嵌套文档,可以通过索引设置选项:
index.mapping.nested_fields.limit修改默认的限制。
ip 类型
存储 IPV4 或 IPV6 地址。
geo_point 类型
geo_point 类型字段存储经纬度信息,可以用于:
- 在边界框内,在中心点的特定距离内或在多边形内查找地理点;
- 通过地理位置或距离中心点的距离来聚合文档;
- 将距离整合到文档的相关性分数中;
- 按距离对文件进行排序。
completion 类型
请参考文章:Elasticsearch Suggester详解
Mapping 设置
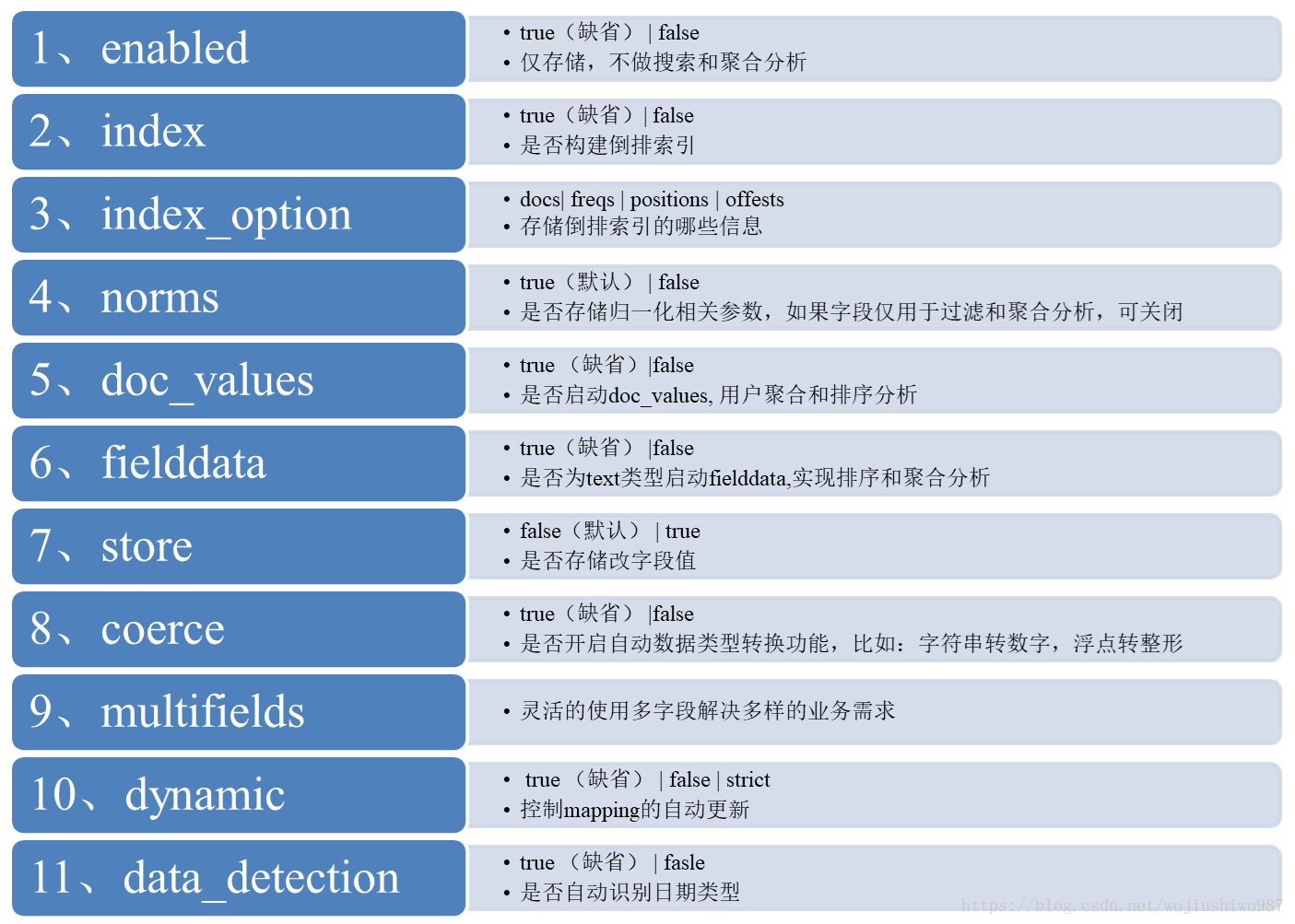
类型选择
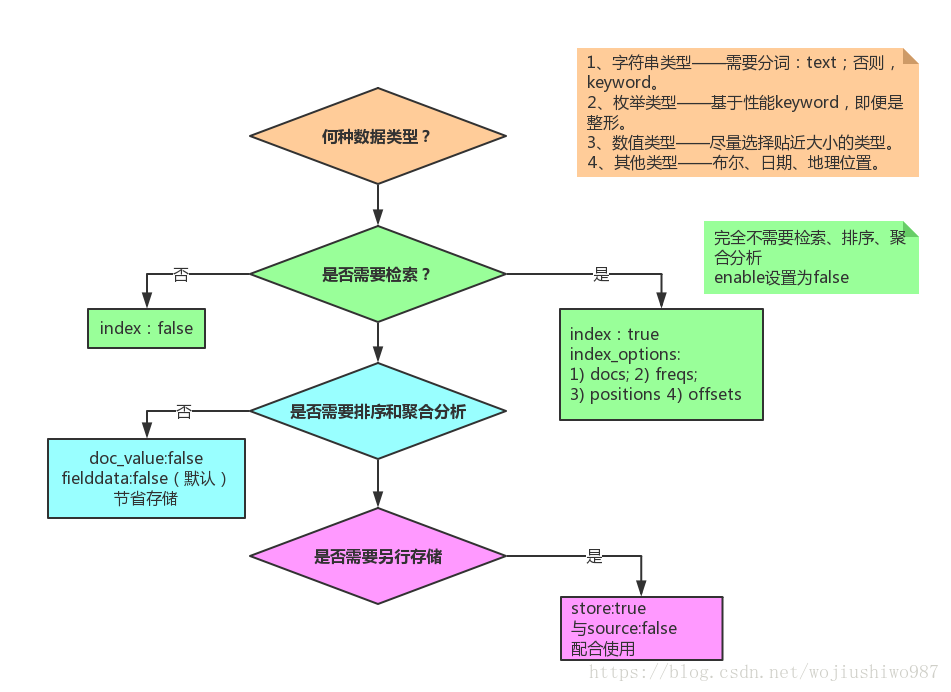
2、Index Template
请参考文章:基于 IK 分词器的 ES 通用索引模板
四、推荐阅读
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。

