

最近工作室开始了一个项目,由于需求方面的问题,数据库的设计开始往中型电商系统靠近。也趁此机会,学习一下数据库的优化策略,。
原文地址:blog.csdn.net/seudongnan/…
数据库的优化策略
随着互联网的普及,电商行业的发展,一个大型的电商平台将对数据库造成极大的负载。为了维持系统的稳定性和拓展性,通过数据切分来提高网站性能,横向扩展数据层已经成为架构人员首选方式。
水平切分数据库:可以降低单台机器的负载,同时最大限度的降低了宕机产生的损失。负载均衡策略:可以降低单台机器的访问负载,降低宕机的可能性。集群方案:解决了数据库宕机带来的单点数据库不能访问的问题。读写分离策略:最大限度提高了应用中读取数据的访问量和并发量
基本原理
数据切分
数据切分(Sharding)是水平扩展(Scale Out,或叫做横向扩展)的解决方案。
Sharding的主要目的
突破单节点数据库服务器的I/O能力限制,解决数据库扩展性的问题。
Sharding的实现策略
Sharding的实现是通过一系列的切分策略,将数据水平切分到不同的Database或者table中。在查询过程中,通过一定的路由策略,找到需要查询的具体Database或table,进行Query操作。
举个例子:
我们要对一张article表进行切分,article中有两个主要字段,article_id和user_id。我们可以采用这样的切分策略:将user_id在1~10000的数据写入DB1,10001~20000的数据写入DB2,以此类推,这就是数据库的切分。
当然,我们将切分策略反转,即可从一个给定的user_id来查询到具体的记录,这个过程被称为DB路由。
数据切分的方式
数据切分可以是物理上的,也就是对数据进行一系列的切分策略,分布到不同的DB服务器上,通过DB路由规则访问相应的数据库。以此降低单台机器的负载压力。
数据切分也可以是数据库内的,对数据进行一系列的切分策略,将数据分布到一个数据库不同的表中,比如将article分为article_001,article_002,若干个子表水平拼合有组成了逻辑上一个完整的article表,这样做的目的其实也是很简单的。举个例子说明,比如article表中现在有5000w条数据,此时我们需要在这个表中增加(insert)一条新的数据,insert完毕后,数据库会针对这张表重新建立索引,5000w行数据建立索引的系统开销还是不容忽视的。但是反过来,假如我们将这个表分成100 个table呢,从article_001一直到article_100,5000w行数据平均下来,每个子表里边就只有50万行数据,这时候我们向一张 只有50w行数据的table中insert数据后建立索引的时间就会呈数量级的下降,极大了提高了DB的运行时效率,提高了DB的并发量。当然分表的好处还不知这些,还有诸如写操作的锁操作等,都会带来很多显然的好处。
由此可见:分库降低了单点机器的负载;分表,提高了数据操作的效率。
接下来简单了解一下分库的方式和规则:
依然沿用之前的article表的例子
-
号段分区
user_id为1~1000在DB1,1001~2000在DB2,以此类推- 优点:可部分迁移
- 缺点:数据分布不均
-
hash取模分区
对
user_id进行hash,然后用一个数字对应一个具体的DB。比如有4个数据库,就将user_id%4,结果为0的对应DB1,结果为1的对应DB2,以此类推。这样一来就可以将数据均匀分布。- 优点:数据分布均匀
- 缺点:数据迁移麻烦,不能按照机器性能分摊数据
-
在认证库中保存数据库配置
就是建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
- 优点:灵活性强,一对一关系
- 缺点:每次查询之前都要多一次查询,性能大打折扣
分布式数据方案
-
提供分库规则和路由规则(RouteRule简称RR)
-
引入集群(Group)的概念,保证数据的高可用性
-
引入负载均衡策略(LoadBalancePolicy简称LB)
-
引入集群节点可用性探测机制,对单点机器的可用性进行定时的侦测,以保证LB策略的正确实施,以确保系统的高度稳定性
-
引入读/写分离,提高数据的查询速度。
集群
仅仅是分库分表的数据层设计也是不够完善的,当我们采用了数据库切分方案,也就是说有N台机器组成了一个完整的DB 。如果有一台机器宕机的话,也仅仅是一个DB的N分之一的数据不能访问而已,这是我们能接受的,起码比切分之前的情况好很多了,总不至于整个DB都不能访问。
一般的应用中,这样的机器故障导致的数据无法访问是可以接受的,假设我们的系统是一个高并发的电子商务网站呢?单节点机器宕机带来的经济损失是非常严重的。也就是说,现在我们这样的方案还是存在问题的,容错性能是经不起考验的。
问题总是有解决方案的。我们引入集群的概念,在此我称之为Group,也就是每一个分库的节点我们引入多台机器,每台机器保存的数据是一样的,一般情况下这多台机器分摊负载,当出现宕机情况,负载均衡器将分配负载给这台宕机的机器。这样一来,就解决了容错性的问题。
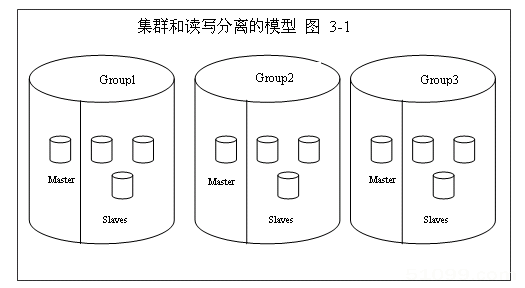
如上图所示,整个数据层有Group1,Group2,Group3三个集群组成,这三个集群就是数据水平切分的结果,当然这三个集群也就组成了一个包含完整数据的DB。
每一个Group包括1个Master(当然Master也可以是多个)和 N个Slave,这些Master和Slave的数据是一致的。 如果Group1中的一个slave发生了宕机现象,那么还有两个slave是可以用的,这样的模型总是不会造成某部分数据不能访问的问题,除非整个 Group里的机器全部宕掉。
在没有引入集群以前,我们的一次查询的过程大致如下:
- 请求数据层,并传递必要的分库区分字段 (通常情况下是user_id)
- 数据层根据区分字段Route到具体的DB,在这个确定的DB内进行数据操作。
引入集群以后,我们的路由器上规则和策略其实只能路由到具体的Group,也就是只能路由到一个虚拟的Group,这个Group并不是某个特定的物理服务器。接下来需要做的工作就是找到具体的物理的DB服务器,以进行具体的数据操作。
负载均衡器
基于这个环节的需求,我们引入了负载均衡器的概念 (LB),负载均衡器的职责就是定位到一台具体的DB服务器。
具体的规则如下:负载均衡器会分析当前sql的读写特性,如果是写操作或者是要求实时性很强的操作的话,直接将查询负载分到Master,如果是读操作则通过负载均衡策略分配一个Slave。
我们的负载均衡器的主要研究方向也就是负载分发策略,通常情况下负载均衡包括随机负载均衡和加权负载均衡。随机负载均衡很好理解,就是从N个Slave中随机选取一个Slave。这样的随机负载均衡是不考虑机器性能的,它默认为每台机器的性能是一样的。假如真实的情况是这样的,这样做也是无可厚非的。假如实际情况并非如此呢?每个Slave的机器物理性能和配置不一样的情况,再使用随机的不考虑性能的负载均衡,是非常不科学的,这样一来会给机器性能差的机器带来不必要的高负载,甚至带来宕机的危险,同时高性能的数据库服务器也不能充分发挥其物理性能。基于此考虑从,我们引入了加权负载均衡,也就是在我们的系统内部通过一定的接口,可以给每台DB服务器分配一个权值,然后再运行时LB根据权值在集群中的比重,分配一定比例的负载给该DB服务器。当然这样的概念的引入,无疑增大了系统的复杂性和可维护性。有得必有失,我们也没有办法逃过的。
集群节点的可用性探测
有了分库,有了集群,有了负载均衡器,是不是就万事大吉了呢? 事情远没有我们想象的那么简单。虽然有了这些东西,基本上能保证我们的数据层可以承受很大的压力,但是这样的设计并不能完全规避数据库宕机的危害。假如Group1中的slave2宕机了,那么系统的LB并不能得知,这样的话其实是很危险的,因为LB不知道,它还会以为slave2为可用状态,所以还是会给slave2分配负载。这样一来,问题就出来了,客户端很自然的就会发生数据操作失败的错误或者异常。
怎样解决这样的问题呢?我们引入集群节点的可用性探测机制,或者是可用性的数据推送机制。这两种机制有什么不同呢?首先说探测机制吧,顾名思义,探测即使,就是我的数据层客户端,不定时对集群中各个数据库进行可用性的尝试,实现原理就是尝试性链接,或者数据库端口的尝试性访问,都可以做到。
那数据推送机制又是什么呢?其实这个就要放在现实的应用场景中来讨论这个问题了,一般情况下应用的DB 数据库宕机的话我相信DBA肯定是知道的,这个时候DBA手动的将数据库的当前状态通过程序的方式推送到客户端,也就是分布式数据层的应用端,这个时候在更新一个本地的DB状态的列表。并告知LB,这个数据库节点不能使用,请不要给它分配负载。一个是主动的监听机制,一个是被动的被告知的机制。两者各有所长。但是都可以达到同样的效果。这样一来刚才假设的问题就不会发生了,即使就是发生了,那么发生的概率也会降到最低。
上面的文字中提到的Master和Slave ,我们并没有做太多深入的讲解。一个Group由1个Master和N个Slave组成。为什么这么做呢?其中Master负责写操作的负载,也就是说一切写的操作都在Master上进行,而读的操作则分摊到Slave上进行。这样一来的可以大大提高读取的效率。在一般的互联网应用中,经过一些数据调查得出结论,读/写的比例大概在 10:1左右 ,也就是说大量的数据操作是集中在读的操作,这也就是为什么我们会有多个Slave的原因。
但是为什么要分离读和写呢?熟悉DB的研发人员都知道,写操作涉及到锁的问题,不管是行锁还是表锁还是块锁,都是比较降低系统执行效率的事情。我们这样的分离是把写操作集中在一个节点上,而读操作其其他 的N个节点上进行,从另一个方面有效的提高了读的效率,保证了系统的高可用性。
