

个人技术博客:www.zhenganwen.top
单调栈结构
原始问题
给你一个数组,找出数组中每个数左边离它最近的比它大的数和右边离它最近的比它大的数。
思路:使用一个栈,要求每次元素进栈后要维持栈中从栈底到栈顶元素值是从大到小排列的约定。将数组中的元素依次进栈,如果某次元素进栈后会违反了上述的约定(即该进栈元素比栈顶元素大),就先弹出栈顶元素,并记录该栈顶元素的信息:
- 该元素左边离它最近的比它大的是该元素出栈后的栈顶元素,如果出栈后栈空,那么该元素左边没有比它大的数
- 该元素右边离它最近的比它大的是进栈元素
然后再尝试将进栈元素进栈,如果进栈后还会违反约定那就重复操作“弹出栈顶元素并记录该元素信息”,直到符合约定或栈中元素全部弹出时再将该进栈元素进栈。当数组所有元素都进栈之后,栈势必不为空,弹出栈顶元素并记录信息:
- 该元素右边没有比它大的数
- 该元素左边离它最近的比它大的数是该元素从栈弹出后的栈顶元素,如果该元素弹出后栈为空,那么该元素左边没有比它大的数
由于每个元素仅进栈一次、出栈一次,且出栈时能得到题目所求信息,因此时间复杂度为
O(N)
示例代码:
public static void findLeftAndRightBigger(int arr[]){
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < arr.length; i++) {
//check the agreement before push the index of element
while (!stack.empty() && arr[stack.peek()] < arr[i]) {
//pop and record the info(print or save)
int index = stack.pop();
System.out.print("index:" + index + ",element:" + arr[index] + ",right bigger is:" + arr[i]);
if (stack.empty()) {
System.out.print(",hasn't left bigger\n");
} else {
System.out.println(",left bigger is:" + arr[stack.peek()]+"\n");
}
}
//push
stack.push(i);
}
while (!stack.empty()) {
int index = stack.pop();
System.out.print("index:" + index + ",element:" + arr[index] + ",hasn't right bigger");
if (stack.empty()) {
System.out.print(",hasn't left bigger\n");
} else {
System.out.println(",left bigger is:" + arr[stack.peek()]+"\n");
}
}
}
public static void main(String[] args) {
int[] arr = {2, 1, 7, 4, 5, 9, 3};
findLeftAndRightBigger(arr);
}
给你一些数,创建一棵大根堆二叉树
思路:使用一个栈底到栈顶单调递减的单调栈,将这些数
arr[]依次入栈,记录每个数左边离它最近的比它大的数,保存在left[]中(下标和arr[]一一对应),记录每个数右边离它最近的比它大的数,保存在right[]中。遍历
arr[]建树:left[i]和right[i]都不存在的,说明arr[i]是最大的数,将其作为根节点;对于其他任何一个数arr[i],left[i]和right[i]必有一个存在,如果都存在则将arr[i]作为Math.min(left[i],right[i])的孩子节点,如果只有一个存在(如left[i])那就将arr[i]作为left[i]的孩子节点
思考:这样建出的树会不会是森林,会不会不是二叉树?
找出矩阵中一片1相连的最大矩形
矩阵中的数只会是0或1,求矩阵中一片1形成的最大长方形区域的面积。
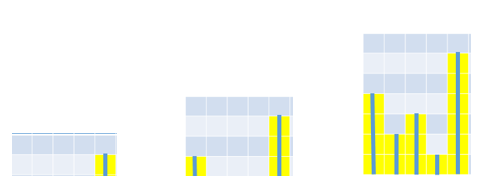
此题可借鉴在直方图中找最大矩形的方法。首先一个数组可以对应一个直方图,如下所示:
接着,遍历数组,以当前遍历元素值为杆子的高并尝试向左右移动这根杆子(约定杆子不能出黄色区域):
如上图,0号杆子向左右移动一格都会使杆子出界(黄色区域),因此0号杆子的活动面积是4x1=4(杆长x能活动的格子数);1号杆子向左、向右都只能移动一格,因此其活动面积是2x3=6;2号杆子的活动面积是3x1=3;3号杆子的活动面积是1x5=5;4号杆子的活动面积是6x1=6。因此该直方图中最大矩形面积就是所有杆子的活动面积中最大的那个,即6。
如果现在给你一个矩阵,比如
0 0 0 0 1
0 0 0 0 1
1 0 0 0 1
1 0 1 0 1
1 1 1 0 1
1 1 1 1 1
你能否将其中相连的一片1看成直方图中的黄色区域,如此的话求矩阵由一片1形成的最大矩形区域就是求直方图中最大矩形面积了。
所以对于输入的矩形,我们只要遍历每一行,以该行作为直方图的x轴,求出直方图的最大矩形面积,再比较所有行对应的最大矩形面积就能得出整个矩阵的一片1形成的最大矩形区域了。
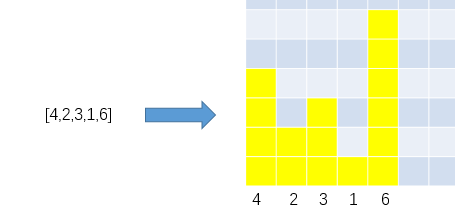
以上面的矩阵为例,第一行、第三行、最后一行对应的直方图如下所示:
分别可以用数组[0,0,0,0,1]、[1,0,0,0,3]、[4,2,3,1,6]来表示,那么此题关键的点就是遍历每一行并求出以该行为x轴的直方图的数组表示之后,如何得出此直方图的最大矩形面积。下面就使用单调栈来解决此问题:
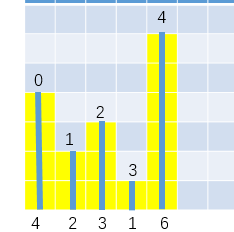
以[4,2,3,1,6]的求解过程为例,使用一个栈底到栈顶单调递增的栈将数组中的数的下标作为该数的代表依次压栈(数的下标->数值),首先能压的是0->4,接着准备压1->2,发现2比栈顶的4小,压人后会违反栈底到栈顶单调递增的约定,因此弹出0->4并记录0号杆子的活动面积(0->4弹出后栈为空,说明0号杆子左移到x轴的-1就跑出黄色区域了,由于是1->2让它弹出的,所以0号杆子右移到x轴的1就出界了,因此0号杆子只能在x轴上的0位置上活动,活动面积是4x1=4,称这个记录的过程为结算)。由于弹出0->4之后栈空了,所以可以压入1->2、2->3,接着准备压3->1时发现1比栈顶3小,因此结算2->3(由于弹出2->3之后栈顶为1->2,因此2号杆子左移到x轴1位置时出界了,由于是3->1让其弹出的,所以2号杆子右移到x轴3位置就出界了,因此2号杆子的活动面积是3x1=3)。接着再准备压3->1,发现1比栈顶1->2的2小,因此结算1->2(弹出1->2后栈空,因此1号杆子左移到x轴-1时才出界,3->1让其出界的,因此右移到3时才出界,活动面积为2x3=6)……
所有数压完之后,栈肯定不为空,那么栈中剩下的还需要结算,因此依次弹出栈顶进行结算,比如[4,2,3,1,6]压完之后,栈中还剩3->1,4->6,因此弹出4->6并结算(由于4->6不是因为一个比6小的数要进来而让它弹出的,所以4号杆子右移到x轴arr.length=5位置才出界,由于弹出后栈不空且栈顶为3->1,所以左移到x轴的3位置上才出界的,所以活动面积为6x1=6;同样的方法结算3->1……直到栈中的都被结算完,整个过程结束。
示例代码:
public static int maxRectangleArea(int matrix[][]){
int arr[] = new int[matrix[0].length];
int maxArea = Integer.MIN_VALUE;
for (int i = 0; i < matrix.length; i++) {
for (int j = 0; j < matrix[i].length; j++) {
arr[j] = matrix[i][j] == 1 ? arr[j]+1 : 0;
}
System.out.println(Arrays.toString(arr));
maxArea = Math.max(maxArea, maxRecAreaOfThRow(arr));
}
return maxArea;
}
public static int maxRecAreaOfThRow(int arr[]){
int maxArea = Integer.MIN_VALUE;
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < arr.length; i++) {
while (!stack.empty() && arr[i] < arr[stack.peek()]) {
int index = stack.pop();
int leftBorder = stack.empty() ? -1 : stack.peek();
maxArea = Math.max(maxArea, arr[index] * (i - leftBorder - 1));
}
stack.push(i);
}
while (!stack.empty()) {
int index = stack.pop();
int rightBorder = arr.length;
int leftBorder = stack.empty() ? -1 : stack.peek();
maxArea = Math.max(maxArea, arr[index] * (rightBorder - leftBorder - 1));
}
return maxArea;
}
public static void main(String[] args) {
int matrix[][] = {
{0, 0, 0, 0, 1},
{0, 0, 0, 0, 1},
{1, 0, 0, 0, 1},
{1, 0, 1, 0, 1},
{1, 1, 1, 0, 1},
{1, 1, 1, 1, 1}
};
System.out.println(maxRectangleArea(matrix));//6
}
烽火相望
【网易原题】给你一个数组,数组中的每个数代表一座山的高度,这个数组代表将数组中的数从头到尾连接而成的环形山脉。比如数组[2,1,3,4,5]形成的环形山脉如下:
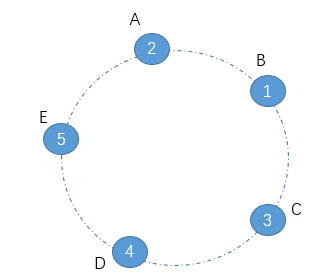
其中蓝色的圆圈就代表一座山,圈中的数字代表这座山的高度。现在在每座山的山顶都点燃烽火,假设你处在其中的一个山峰上,要想看到另一座山峰的烽火需满足以下两个条件中的一个:
- 你想看的山峰在环形路径上与你所在的山峰相邻。比如你在山峰A上,那么你能够看到B和E上的烽火。
- 如果你想看的山峰和你所在的山峰不相邻,那么你可以沿环形路径顺时针看这座山也可以沿环形路径逆时针看这座山,只要你放眼望去沿途经过的山峰高度小于你所在的山峰和目标山峰,那么也能看到。比如C想看E,那么可以通过C->B->A->E的方式看,也可以通过C->D->E的方式看。前者由于经过的山峰的高度1和2比C的高度3和E的高度5都小,因此能看到;但后者经过的山峰D的高度4大于C的高度3,因此C在通过C->D->E这个方向看E的时候视线就被山峰D给挡住了。
问:所有山峰中,能互相看到烽火的两两山峰的对数。以[2,1,3,4,5]为例,能互相看见的有:2,1,1,3,3,4,4,5,5,2,2,3,3,5,共7对。
此题分一下两种情况
1、数组中无重复的数
这种情况下,答案可以直接通过公式2*N-3可以求得(其中N为数组长度),证明如下:
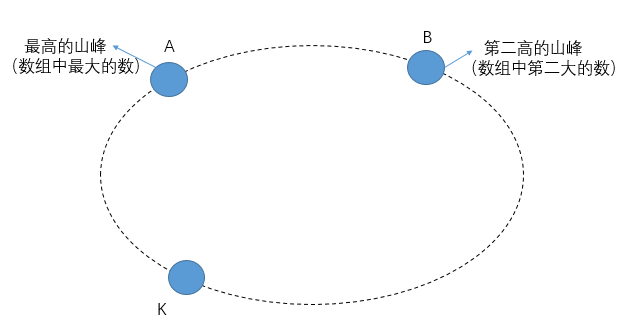
假设A是在山峰中最高,B在所有山峰中第二高。那么环形路径上介于A和B之间的任意一座山峰(比如K),逆时针方向在到达A之前或到达A时一定会遇到第一座比它高的山峰,记这座山峰和K是一对;顺时针方向,在到达B之前或到达B时,一定会遇到第一个比K高的山峰,记这座山峰和K是一对。也就是说对于除A,B之外的所有山峰,都能找到两对符合标准的,这算下来就是(N-2)*2了,最后AB也算一对,总数是(N-2)*2+1=2N-3。
但如果数组中有重复的数就不能采用上述的方法了
2、数组中可能有重复的数
利用单调栈
首先找出数组中最大数第一次出现的位置,记为M。从这个数开始遍历数组并依次压栈(栈底到栈底从大到小的单调栈),以如下的环形山脉为例:
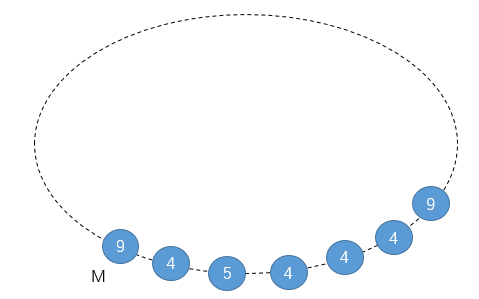
从M开始压栈,同时附带一个计数器:
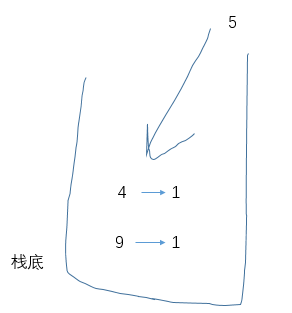
当压入5时,违反单调栈约定因此结算4(4左边第一个比它高的是9,右边第一个比它高的是5,因此能和4配对的有两对);接着再压入5、压入4,重点来了:连续两次再压入4该如何处理:
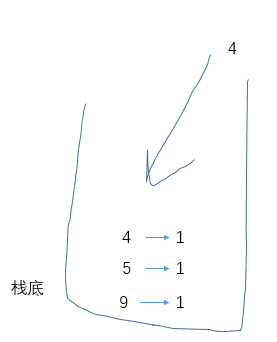
这是数组中有重复的数时,如何使用单调栈解决此题的关键:如果压入的元素与栈顶元素相同,将栈顶元素的计数器加1,那么再压入两个4之后栈中情况:
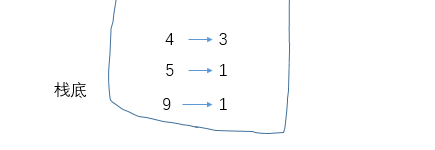
然后压入9,导致弹出并结算4。那么如何结算计数器大于1的数据呢?首先,这3座高度相同的山峰两两配对能够组成C(3,2)=3对,此外其中的每座山峰左边离它最近的比它高的是5、右边离它近的比它大的是9,因此这3座山峰每座都能和5、9配对,即3*2=6,因此结算结果为3+6=9……
如果数据压完了,那就从栈顶弹出数据进行结算,直到结算栈底上一个元素之前(栈底元素是最大值),弹出数据的结算逻辑都是C(K,2)+K*2(其中K是该数据的计数器数值)。
倒数第二条数据的结算逻辑有点复杂,如图,以结算4为例:
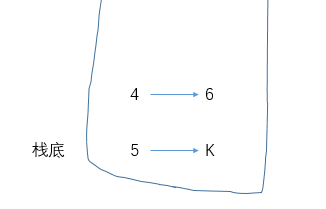
如果K的数值大于1,那么这6座高度为4的山峰结算逻辑还是上述公式。但如果K为1,那么结算公式就是C(K,2)+K*1了。
最后对于最大值M的结算,假设其计数器的值为K,如果K=1,那么结算结果为0;如果K>1,那么结算结果为C(K,2)。
示例代码:
public static class Record{
int value;
int times;
public Record(int value) {
this.value = value;
this.times = 1;
}
}
public static int comunications(int[] arr) {
//index of first max value
int maxIndex = 0;
for (int i = 0; i < arr.length; i++) {
maxIndex = arr[maxIndex] < arr[i] ? i : maxIndex;
}
Stack<Record> stack = new Stack<>();
stack.push(new Record(arr[maxIndex]));
int res = 0;
int index = nextIndex(arr, maxIndex);
while (index != maxIndex) {
while (!stack.empty() && arr[index] > stack.peek().value) {
Record record = stack.pop();
res += getInternalPairs(record.times) + record.times * 2;
}
if (arr[index] == stack.peek().value) {
stack.peek().times++;
} else {
stack.push(new Record(arr[index]));
}
index = nextIndex(arr, index);
}
while (!stack.empty()) {
Record record = stack.pop();
res += getInternalPairs(record.times);
if (!stack.empty()) {
res += record.times;
if (stack.size() > 1) {
res += record.times;
} else {
res += stack.peek().times > 1 ? record.times : 0;
}
}
}
return res;
}
//C(K,2)
public static int getInternalPairs(int times){
return (times * (times - 1)) / 2;
}
public static int nextIndex(int[] arr, int index) {
return index < arr.length - 1 ? index + 1 : 0;
}
public static void main(String[] args) {
int[] arr = {9, 4, 5, 4, 4, 4, 9,1};
System.out.println(comunications(arr));
}
搜索二叉树
搜索二叉树的定义:对于一棵二叉树中的任意子树,其左子树上的所有数值小于头结点的数值,其右子树上所有的数值大于头结点的数值,并且树中不存在数值相同的结点。也称二叉查找树。
平衡二叉树/AVL树
平衡性
经典的平衡二叉树结构:在满足搜索二叉树的前提条件下,对于一棵二叉树中的任意子树,其左子树和其右子树的高度相差不超过1。
典型搜索二叉树——AVL树、红黑树、SBT树的原理
AVL树
AVL树是一种具有严苛平衡性的搜索二叉树。什么叫做严苛平衡性呢?那就是所有子树的左子树和右子树的高度相差不超过1。弊端是,每次发现因为插入、删除操作破坏了这种严苛的平衡性之后,都需要作出相应的调整以使其恢复平衡,调整较为频繁。
红黑树
红黑树是每个节点都带有颜色属性的搜索二叉树,颜色或红色或黑色。在搜索二叉树强制一般要求以外,对于任何有效的红黑树我们增加了如下的额外要求:
- 性质1. 节点是红色或黑色。
- 性质2. 根节点是黑色。
- 性质3 每个叶节点(NIL节点,空节点)是黑色的。
- 性质4 每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 性质5. 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。
这些约束强制了红黑树的关键性质: 从根到叶子的最长的可能路径不多于最短的可能路径的两倍长。结果是这个树大致上是平衡的。因为操作比如插入、删除和查找某个值的最坏情况时间都要求与树的高度成比例,这个在高度上的理论上限允许红黑树在最坏情况下都是高效的,而不同于普通的二叉查找树。
要知道为什么这些特性确保了这个结果,注意到性质4导致了路径不能有两个毗连的红色节点就足够了。最短的可能路径都是黑色节点,最长的可能路径有交替的红色和黑色节点。因为根据性质5所有最长的路径都有相同数目的黑色节点,这就表明了没有路径能多于任何其他路径的两倍长。
SBT树
它是由中国广东中山纪念中学的陈启峰发明的。陈启峰于2006年底完成论文《Size Balanced Tree》,并在2007年的全国青少年信息学奥林匹克竞赛冬令营中发表。相比红黑树、AVL树等自平衡二叉查找树,SBT更易于实现。据陈启峰在论文中称,SBT是“目前为止速度最快的高级二叉搜索树”。SBT能在O(log n)的时间内完成所有二叉搜索树(BST)的相关操作,而与普通二叉搜索树相比,SBT仅仅加入了简洁的核心操作Maintain。由于SBT赖以保持平衡的是size域而不是其他“无用”的域,它可以很方便地实现动态顺序统计中的select和rank操作。
SBT树的性质是:对于数中任意结点,以该结点为根节点的子树的结点个数不能比以该结点的叔叔结点为根节点的子树的结点个数大。

由于红黑树的实现较为复杂,因此现在工程中大多使用SBT树作为平衡二叉树的实现。
旋转——Rebalance
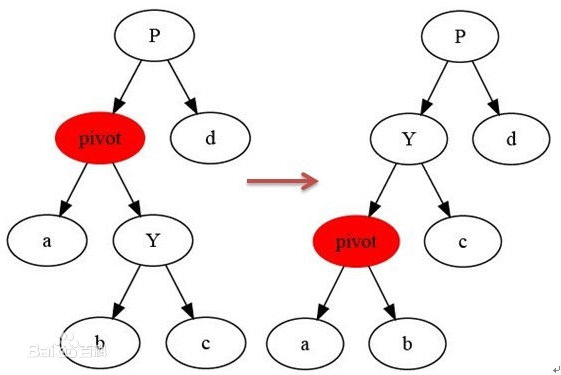
左旋:
右旋:
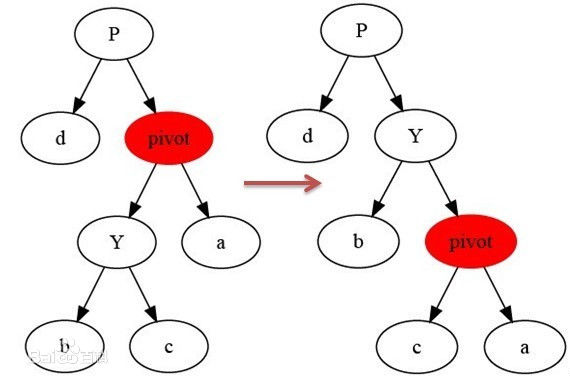
每种平衡二叉树都有自己的一套在插入、删除等操作改变树结构而破坏既定平衡性时的应对措施(但都是左旋操作和右旋操作的组合),以AVL数为例(有四种平衡调整操作,其中的数字只是结点代号而非结点数值):
-
LL调整:2号结点的左孩子的左孩子导致整个树不平衡,2号结点右旋一次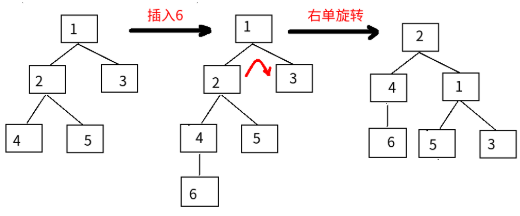
-
RR调整:3号结点的右孩子的右孩子导致树不平衡,3号结点左旋一次: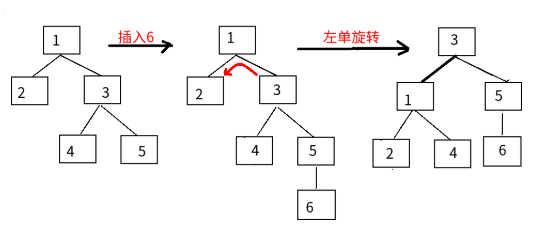
-
LR调整:先左后右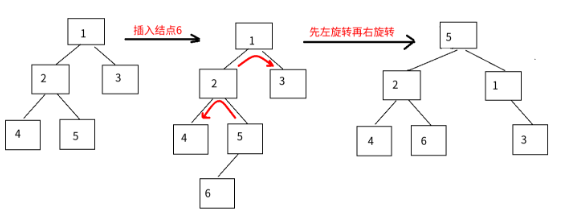
-
RL调整:先右后左: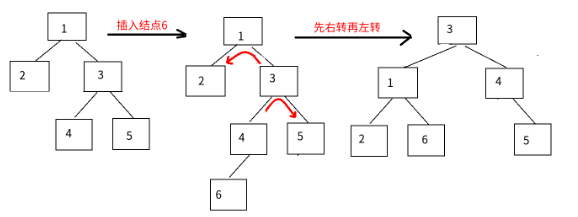
红黑树的调整也是类似的,只不过调整方案更多。面试中一般不会让你手写红黑树(若有兴趣可参见文末附录),但我们一定能说清这些查找二叉树的性质,以及调整平衡的基本操作,再就是这些结构的使用。
Java中红黑树的使用
Java中红黑树的实现有TreeSet和TreeMap,前者结点存储的是单一数据,而后者存储的是<key,value>的形式。
public static void main(String[] args) {
TreeMap<Integer,String> treeMap = new TreeMap();
treeMap.put(5, "tom");
treeMap.put(11, "jack");
treeMap.put(30,"tony");
treeMap.put(18, "alice");
treeMap.put(25, "jerry");
//红黑树中最右边的结点
System.out.println(treeMap.lastEntry());
System.out.println(treeMap.lastKey());
//红黑树最左边的结点
System.out.println(treeMap.firstKey());
//如果有13这个key,那么返回这条记录,否则返回树中比13大的key中最小的那一个
System.out.println(treeMap.ceilingEntry(13));
//如果有21这个key,那么返回这条记录,否则返回树中比21小的key中最大的那一个
System.out.println(treeMap.floorEntry(21));
//比11大的key中,最小的那一个
System.out.println(treeMap.higherKey(11));
//比25小的key中,最大的那一个
System.out.println(treeMap.lowerKey(25));
//遍历红黑树,是按key有序遍历的
for (Map.Entry<Integer, String> record : treeMap.entrySet()) {
System.out.println("age:"+record.getKey()+",name:"+record.getValue());
}
}
TreeMap的优势是key在其中是有序组织的,因此增加、删除、查找key的时间复杂度均为log(2,N)。
案例
The Skyline Problem
水平面上有 N 座大楼,每座大楼都是矩阵的形状,可以用一个三元组表示 (start, end, height),分别代表其在x轴上的起点,终点和高度。大楼之间从远处看可能会重叠,求出 N 座大楼的外轮廓线。
外轮廓线的表示方法为若干三元组,每个三元组包含三个数字 (start, end, height),代表这段轮廓的起始位置,终止位置和高度。
给出三座大楼:
[
[1, 3, 3],
[2, 4, 4],
[5, 6, 1]
]
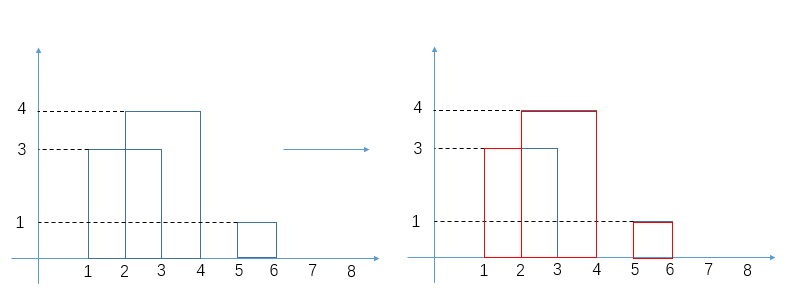
外轮廓线为:
[
[1, 2, 3],
[2, 4, 4],
[5, 6, 1]
]
解析:
-
将一座楼的表示
[start,end,height]拆分成左右两个边界(边界包含:所处下标、边界高度、是楼的左边界还是右边界),比如[1,3,3]就可以拆分成[1,3,true]和[3,3,false]的形式(true代表左边界、false代表右边界)。 -
将每座楼都拆分成两个边界,然后对边界按照边界所处的下标进行排序。比如
[[1,3,3],[2,4,4],[5,6,1]拆分之后为[[1,3,true],[3,3,false],[2,4,true],[,4,4,false],[5,1,true],[6,1,false]],排序后为[[1,3,true],[2,4,true],[3,3,false],[4,4,false],[5,1,true],[6,1,false]] -
将边界排序后,遍历每个边界的高度并依次加入到一棵
TreeMap红黑树中(记为countOfH),以该高度出现的次数作为键值(第一次添加的高度键值为1),如果遍历过程中有重复的边界高度添加,要判断它是左边界还是右边界,前者直接将该高度在红黑树中的键值加1,后者则减1。以步骤2中排序后的边界数组为例,首先判断countOfH是否添加过边界[1,3,true]的高度3,发现没有,于是put(3,1);接着对[2,4,true],put[4,1];然后尝试添加[3,3,false]的3,发现countOfH中添加过3,而[3,3,false]是右边界,因此将countOfH.get(3)的次数减1,当countOfH中的记录的键值为0时直接移除,于是移除高度为3的这一条记录;……对于遍历过程经过的每一个边界,我们还需要一棵
TreeMap红黑树(记为maxHOfPos)来记录对我们后续求外轮廓线有用的信息,也就是每个边界所处下标的最大建筑高度: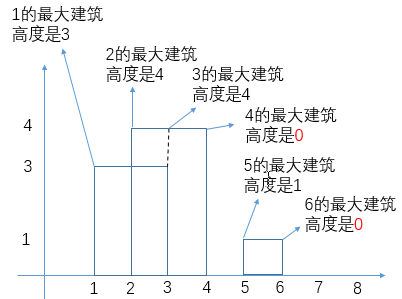
这里有个细节要注意一下,那就是如果添加某个边界之后,
countOfH树为空了,那么该边界所处下标的建筑高度要记为0,表示一片相邻建筑的结束,比如上图中下标为4和6的边界。这也是为了后续求外轮廓线提供判断的依据。 -
遍历
maxHOfPos中的记录,构造整个外轮廓线数组:
起初没有遍历边界时,记
start=0,height=0,接着遍历边界,如果边界高度curHeight!=height如上图中的1->2:height=0,curHeight=3,那么记start=1,height=3表示第一条组外轮廓线的start和height,接下来就是确定它的end了。确定了一条轮廓线的start和height之后会有两种情况:下一组轮廓线和这一组是挨着的(如上图2->3)、下一组轮廓线和这一组是相隔的(如上图中3->4)。因此在遍历到边界[index:2,H:4]时,发现curHeight=4 != height=3,于是可以确定轮廓线start:1,heigth:3的end:2。确定一条轮廓线后就要更新一下start=2,heigth=4表示下一组轮廓线的起始下标和高度,接着遍历到边界[index:3,H:4],发现curHeight=4=height于是跳过;接着遍历到边界[index:4,H:0],发现curHeight=0,根据步骤3中的逻辑可知一片相邻的建筑到此结束了,因此轮廓线start:2,height:4的end=4。
示例代码:
package top.zhenganwen.lintcode;
import java.util.*;
public class T131_The_SkylineProblem {
public class Border implements Comparable<Border> {
public int index;
public int height;
public boolean isLeft;
public Border(int index, int height, boolean isLeft) {
this.index = index;
this.height = height;
this.isLeft = isLeft;
}
@Override
public int compareTo(Border border) {
if (this.index != border.index) {
return this.index - border.index;
}
if (this.isLeft != border.isLeft) {
return this.isLeft ? -1 : 1;
}
return 0;
}
}
/**
* @param buildings: A list of lists of integers
* @return: Find the outline of those buildings
*/
public List<List<Integer>> buildingOutline(int[][] buildings) {
//1、split one building to two borders and sort by border's index
Border[] borders = new Border[buildings.length * 2];
for (int i = 0; i < buildings.length; i++) {
int[] oneBuilding = buildings[i];
borders[i * 2] = new Border(oneBuilding[0], oneBuilding[2], true);
borders[i * 2 + 1] = new Border(oneBuilding[1], oneBuilding[2], false);
}
Arrays.sort(borders);
//2、traversal borders and record the max height of each index
//key->height value->the count of the height
TreeMap<Integer, Integer> countOfH = new TreeMap<>();
//key->index value->the max height of the index
TreeMap<Integer, Integer> maxHOfPos = new TreeMap<>();
for (int i = 0; i < borders.length; i++) {
int height = borders[i].height;
if (!countOfH.containsKey(height)) {
countOfH.put(height, 1);
}else {
int count = countOfH.get(height);
if (borders[i].isLeft) {
countOfH.put(height, count + 1);
} else {
countOfH.put(height, count - 1);
if (countOfH.get(height) == 0) {
countOfH.remove(height);
}
}
}
if (countOfH.isEmpty()) {
maxHOfPos.put(borders[i].index, 0);
} else {
//lastKey() return the maxHeight in countOfH RedBlackTree->log(2,N)
maxHOfPos.put(borders[i].index, countOfH.lastKey());
}
}
//3、draw the buildings outline according to the maxHOfPos
int start = 0;
int height = 0;
List<List<Integer>> res = new ArrayList<>();
for (Map.Entry<Integer, Integer> entry : maxHOfPos.entrySet()) {
int curPosition = entry.getKey();
int curMaxHeight = entry.getValue();
if (height != curMaxHeight) {
//if the height don't be reset to 0,the curPosition is the end
if (height != 0) {
List<Integer> record = new ArrayList<>();
record.add(start);
record.add(curPosition);//end
record.add(height);
res.add(record);
}
//reset the height and start
height = curMaxHeight;
start = curPosition;
}
}
return res;
}
public static void main(String[] args) {
int[][] buildings = {
{1, 3, 3},
{2, 4, 4},
{5, 6, 1}
};
System.out.println(new T131_The_SkylineProblem().buildingOutline(buildings));
}
}
跳表
跳表有着和红黑树、SBT树相同的功能,都能实现在O(log(2,N))内实现对数据的增删改查操作。但跳表不是以二叉树为原型的,其设计细节如下:
记该结构为SkipList,该结构中可以包含有很多结点(SkipListNode),每个结点代表一个被添加到该结构的数据项。当实例化SkipList时,该对象就会自带一个SkipListNode(不代表任何数据项的头结点)。
添加数据
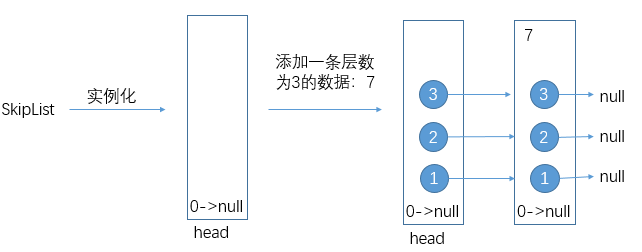
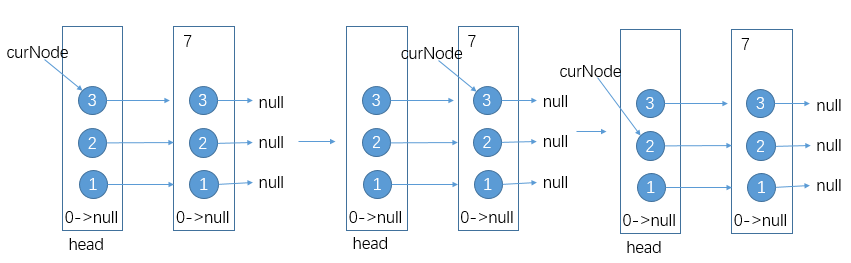
当你向其中添加数据之前,首先会抛硬币,将第一次出现正面朝上时硬币被抛出的次数作为该数据的层数(level,最小为1),接着将数据和其层数封装成一个SkipListNode添加到SkipList中。结构初始化时,其头结点的层数为0,但每次添加数据后都会更新头结点的层数为所添数据中层数最大的。比如实例化一个SkipList后向其中添加一条层数为3的数据7:
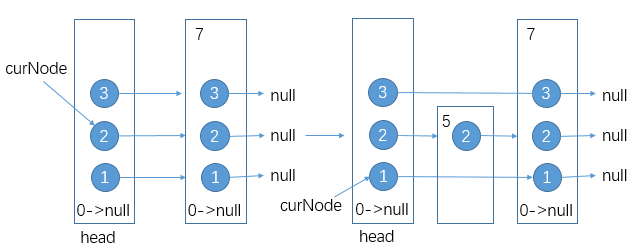
这时如果再添加一条层数为2的数据5呢?首先游标curNode会从head的最高层出发往右走,走到数据项为7的结点,发现7>5,于是又退回来走向下一层:
接着再尝试往右走,还是发现7>5,于是还是准备走向下一层,但此时发现curNode所在层数2是数据项5的最高层,于是先建出数据项5的第二层,curNode再走向下一层:
同样的,curNode尝试往右走,但发现7>5,curNode所在层为1,但数据5的第一层还没建,于是建出,curNode再往下走。当curNode走到null时,建出数据5根部的null:
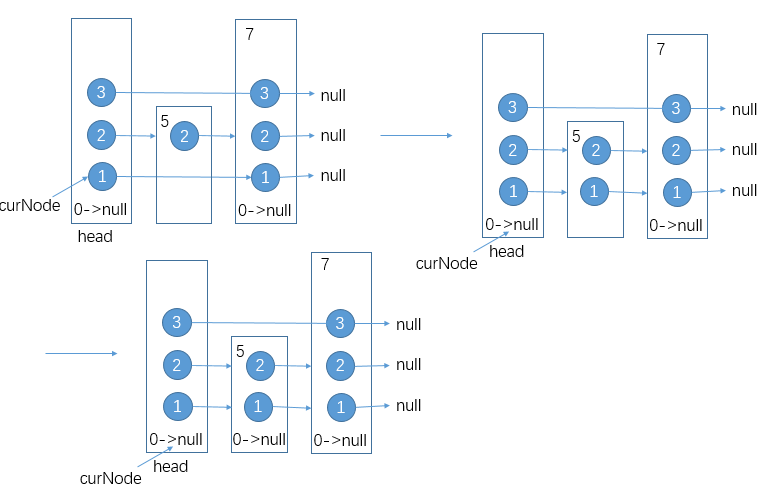
至此层数为2的数据项5的添加操作完毕。
那如果添加一个层数较高的数据项该如何处理呢?以添加层数为4的数据10为例:
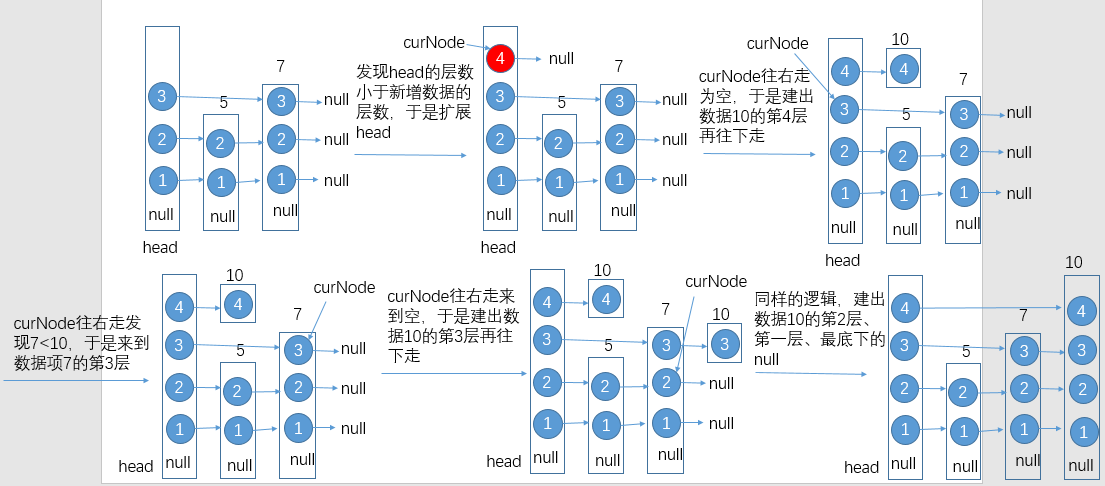
添加操作对应的代码示例:
import java.util.ArrayList;
/**
* A stored structure.Its add,delete,update,find operation are log(2,N)
*
* @author zhenganwen
*/
public class SkipList {
private SkipListNode head;
private int maxLevel;
private int size;
public static final double PROBABILITY = 0.5;
public SkipList() {
this.head = new SkipListNode(Integer.MIN_VALUE);
/**
* the 0th level of each SkipListNode is null
*/
this.head.nextNodes.add(null);
this.maxLevel = 0;
this.size = 0;
}
private class SkipListNode {
int value;
/**
* nextNodes represent the all levels of a SkipListNode the element on
* one index represent the successor SkipListNode on the indexth level
*/
ArrayList<SkipListNode> nextNodes;
public SkipListNode(int newValue) {
this.value = newValue;
this.nextNodes = new ArrayList<SkipListNode>();
}
}
/**
* put a new data into the structure->log(2,N)
*
* @param newValue
*/
public void add(int newValue) {
if (!contains(newValue)) {
// generate the level
int level = 1;
while (Math.random() < PROBABILITY) {
level++;
}
// update max level
if (level > maxLevel) {
int increment = level - maxLevel;
while (increment-- > 0) {
this.head.nextNodes.add(null);
}
maxLevel = level;
}
// encapsulate value
SkipListNode newNode = new SkipListNode(newValue);
// build all the levels of new node
SkipListNode cur = findInsertionOfTopLevel(newValue, level);
while (level > 0) {
if (cur.nextNodes.get(level) != null) {
newNode.nextNodes.add(0, cur.nextNodes.get(level));
} else {
newNode.nextNodes.add(0, null);
}
cur.nextNodes.set(level, newNode);
level--;
cur = findNextInsertion(cur, newValue, level);
}
newNode.nextNodes.add(0, null);
size++;
}
}
/**
* find the insertion point of the newNode's top level from head's maxLevel
* by going right or down
*
* @param newValue newNode's value
* @param level newNode's top level
* @return
*/
private SkipListNode findInsertionOfTopLevel(int newValue, int level) {
int curLevel = this.maxLevel;
SkipListNode cur = head;
while (curLevel >= level) {
if (cur.nextNodes.get(curLevel) != null
&& cur.nextNodes.get(curLevel).value < newValue) {
// go right
cur = cur.nextNodes.get(curLevel);
} else {
// go down
curLevel--;
}
}
return cur;
}
/**
* find the next insertion from cur node by going right on the level
*
* @param cur
* @param newValue
* @param level
* @return
*/
private SkipListNode findNextInsertion(SkipListNode cur, int newValue,
int level) {
while (cur.nextNodes.get(level) != null
&& cur.nextNodes.get(level).value < newValue) {
cur = cur.nextNodes.get(level);
}
return cur;
}
/**
* check whether a value exists->log(2,N)
*
* @param value
* @return
*/
public boolean contains(int value) {
if (this.size == 0) {
return false;
}
SkipListNode cur = head;
int curLevel = maxLevel;
while (curLevel > 0) {
if (cur.nextNodes.get(curLevel) != null) {
if (cur.nextNodes.get(curLevel).value == value) {
return true;
} else if (cur.nextNodes.get(curLevel).value < value) {
cur = cur.nextNodes.get(curLevel);
} else {
curLevel--;
}
} else {
curLevel--;
}
}
return false;
}
public static void main(String[] args) {
SkipList skipList = new SkipList();
skipList.add(1);
skipList.add(2);
skipList.add(3);
skipList.add(4);
skipList.add(5);
//mark a break point here to check the memory structure of skipList
System.out.println(skipList);
}
}
查找数据
查找数据项的操作和添加数据项的步骤类似,也是游标curNode从head的最高层出发,每次先尝试向右走来到nextNode,如果nextNode封装的数据大于查找的目标target或nextNode为空,那么curNode回退并向下走;如果nextNode封装的数据小于target,那么curNode继续向右走,直到curNode走到的结点数据与target相同表示找到了,否则curNode走到了某一结点的根部null,那么说明结构中不存在该数据。->contains()
删除数据
了解添加数据的过程之后,删除数据其实就是将逻辑倒过来:解除该数据结点的前后引用关系。下图是我在写好上述add()方法后,向其中放入1、2、3、4、5后形成的结构:
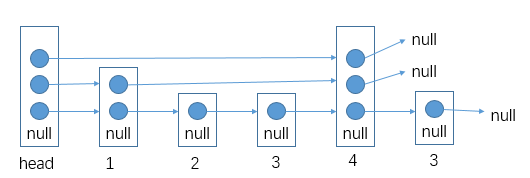
如果此时删除数据3:
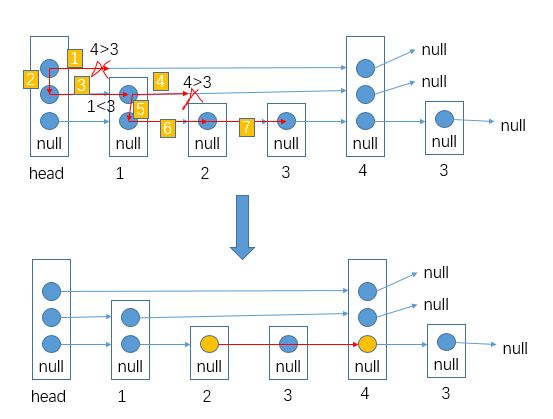
首先应该从head的最高层出发,通过向右或向下找到数据3的最高层(如图2->3->5->6->7),将该层移除整体结构并处理好该层上,其前后结点的关系。同样的逻辑,将数据3剩下的层移除。
示例代码:
/**
* delete skipListNode by the value
*
* @param value
*/
public void delete(int value) {
//if exists
if (contains(value)) {
//find the node and its level
SkipListNode deletedNode = head;
int deletedLevels = maxLevel;
//because exists,so must can find
while (deletedLevels > 0) {
if (deletedNode.nextNodes.get(deletedLevels) != null) {
if (deletedNode.nextNodes.get(deletedLevels).value == value) {
deletedNode = deletedNode.nextNodes.get(deletedLevels);
break;
} else if (deletedNode.nextNodes.get(deletedLevels).value < value) {
deletedNode = deletedNode.nextNodes.get(deletedLevels);
} else {
deletedLevels--;
}
} else {
deletedLevels--;
}
}
//release the node and adjust the reference
while (deletedLevels > 0) {
SkipListNode pre = findInsertionOfTopLevel(value, deletedLevels);
if (deletedNode.nextNodes.get(deletedLevels) != null) {
pre.nextNodes.set(deletedLevels, deletedNode.nextNodes.get(deletedLevels));
} else {
pre.nextNodes.set(deletedLevels, null);
}
deletedLevels--;
}
size--;
}
}
public static void main(String[] args) {
SkipList skipList = new SkipList();
skipList.add(1);
skipList.add(2);
skipList.add(3);
skipList.add(4);
skipList.add(5);
//mark a break point here to check the memory structure of skipList
skipList.delete(3);
System.out.println(skipList);
}
遍历数据
需要遍历跳表中的数据时,我们可以根据每个数据的层数至少为1的特点(每个结点的第一层引用的是比该结点数据大的结点中数据最小的结点)。
示例代码:
class SkipListIterator implements Iterator<Integer> {
private SkipListNode cur;
public SkipListIterator(SkipList skipList) {
this.cur = skipList.head;
}
@Override
public boolean hasNext() {
return cur.nextNodes.get(1) != null;
}
@Override
public Integer next() {
int value = cur.nextNodes.get(1).value;
cur = cur.nextNodes.get(1);
return value;
}
}
@Override
public String toString() {
SkipListIterator iterator = new SkipListIterator(this);
String res = "[ ";
while (iterator.hasNext()) {
res += iterator.next()+" ";
}
res += "]";
System.out.println();
return res;
}
public static void main(String[] args) {
SkipList skipList = new SkipList();
skipList.add(1);
skipList.add(2);
skipList.add(3);
skipList.add(4);
skipList.add(5);
System.out.println(skipList);
skipList.delete(3);
System.out.println(skipList);
}
从暴力尝试到动态规划
动态规划不是玄学,也无需去记那些所谓的刻板的“公式”(例如状态转换表达式等),其实动态规划是从暴力递归而来。并不是说一个可以动态规划的题一上来就可以写出动态规划的求解步骤,我们只需要能够写出暴力递归版本,然后对重复计算的子过程结果做一个缓存,最后分析状态依赖寻求最优解,即衍生成了动态规划。本节将以多个例题示例,展示求解过程是如何从暴力尝试,一步步到动态规划的。
换钱的方法数
题目:给定数组arr,arr中所有的值都为正数且不重复。每个值代表一种面值的货币,每种面值的货币可以使用任意张,再给定一个整数aim代表要找的钱数,求换钱有多少种方法。
举例:arr=[5,10,25,1],aim=0:成0元的方法有1种,就是所有面值的货币都不用。所以返回1。arr=[5,10,25,1],aim=15:组成15元的方法有6种,分别为3张5元、1张10元+1张5元、1张10元+5张1元、10张1元+1张5元、2张5元+5张1元和15张1元。所以返回6。arr=[3,5],aim=2:任何方法都无法组成2元。所以返回0。
暴力尝试
我们可以将该题要求解的问题定义成一个过程:对于下标index,arr中在index及其之后的所有面值不限张数任意组合,该过程最终返回所有有效的组合方案。因此该过程可以描述为int process(int arr[],int index,int aim),题目的解就是调用process(arr,0,aim)。那么函数内部具体该如何解决此问题呢?
其实所有面值不限张数的任意组合就是对每一个面值需要多少张的一个决策,那我们不妨从碰到的第一个面值开始决策,比如 arr=[5,10,25,1],aim=15时,( 选0张5元之后剩下的面值不限张数组合成15元的方法数 + 选1张5元之后剩下的面值不限张数组合成10元方法数 + 选2张5元之后剩下的面值不限张数组合成5元方法数 + 选3张5元之后剩下的面值不限张数组合成0元方法数 )就是所给参数对应的解,其中“剩下的面值不限张数组合成一定的钱数”又是同类问题,可以使用相同的过程求解,因此有了如下的暴力递归:
/**
* arr中的每个元素代表一个货币面值,使用数组index及其之后的面值(不限张数)
* 拼凑成钱数为aim的方法有多少种,返回种数
* @param arr
* @param index
* @param aim
* @return
*/
public static int process(int arr[], int index, int aim) {
if (index == arr.length) {
return aim == 0 ? 1 : 0;
}
int res = 0;
//index位置面值的决策,从0张开始
for (int zhangshu = 0; arr[index] * zhangshu <= aim; zhangshu++) {
res += process(arr, index + 1, aim - (arr[index] * zhangshu));
}
return res;
}
public static int swapMoneyMethods(int arr[], int aim) {
if (arr == null) {
return 0;
}
return process(arr, 0, aim);
}
public static void main(String[] args) {
int arr[] = {5, 10, 25, 1};
System.out.println(swapMoneyMethods(arr, 15));
}
缓存每个状态的结果,以免重复计算
上述的暴力递归是极其暴力的,比如对于参数 arr=[5,3,1,30,15,20,10],aim=100来说,如果已经决策了3张5元+0张3元+0张1元的接着会调子过程process(arr, 3, 85);如果已经决策了0张5元+5张3元+0张1元接着也会调子过程process(arr, 3, 85);如果已经决策了0张5元+0张3元+15张1元接着还是会调子过程process(arr, 3, 85)。
你会发现,这个已知面额种类和要凑的钱数,求凑钱的方法的解是固定的。也就是说不管之前的决策是3张5元的,还是5张3元的,又或是15张1元的,对后续子过程的[30,15,20,10]凑成85这个问题的解是不影响的,这个解该是多少还是多少。这也是无后效性问题。无后效性问题就是某一状态的求解不依赖其他状态,比如著名的N皇后问题就是有后效性问题。
因此,我们不妨再求解一个状态之后,将该状态对应的解做个缓存,在后续的状态求解时先到缓存中找是否有该状态的解,有则直接使用,没有再求解并放入缓存,这样就不会有重复计算的情况了:
public static int swapMoneyMethods(int arr[], int aim) {
if (arr == null) {
return 0;
}
return process2(arr, 0, aim);
}
/**
* 使用哈希表左缓存容器
* key是某个状态的代号,value是该状态对应的解
*/
static HashMap<String,Integer> map = new HashMap();
public static int process2(int arr[], int index, int aim) {
if (index == arr.length) {
return aim == 0 ? 1 : 0;
}
int res = 0;
for (int zhangshu = 0; arr[index] * zhangshu <= aim; zhangshu++) {
//使用index及其之后的面值拼凑成aim的方法数这个状态的代号:index_aim
String key = String.valueOf(index) + "_" + String.valueOf(aim);
if (map.containsKey(key)) {
res += map.get(key);
} else {
int value = process(arr, index + 1, aim - (arr[index] * zhangshu));
key = String.valueOf(index + 1) + "_" + String.valueOf(aim - (arr[index] * zhangshu));
map.put(key, value);
res += value;
}
}
return res;
}
public static void main(String[] args) {
int arr[] = {5, 10, 25, 1};
System.out.println(swapMoneyMethods(arr, 15));
}
确定依赖关系,寻找最优解
当然,借助缓存已经将暴力递归的时间复杂度拉低了很多,但这还不是最优解。下面我们将以寻求最优解为引导,挖掘出动态规划中的状态转换。
从暴力尝试到动态规划,我们只需观察暴力尝试版本的代码,甚至可以忘却题目,按照下面高度套路化的步骤,就可以轻易改出动态规划:
-
首先每个状态都有两个参数
index和aim(arr作为输入参数是不变的),因此可以对应两个变量的变化范围建立一张二维表: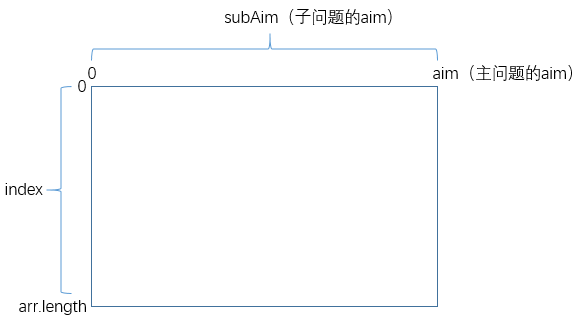
-
从
base case中找出特殊位置的解。比如if(index==arr.length) return aim==0?1:0,那么上述二维表的最后一行对应的所有状态可以直接求解: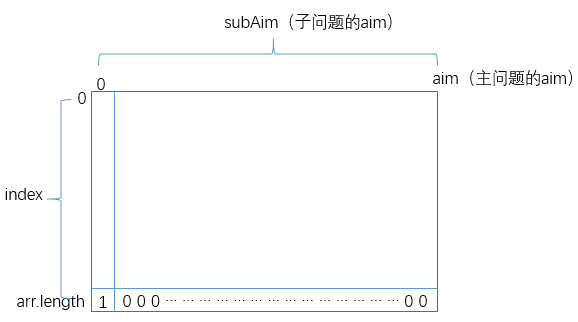
-
从暴力递归中找出普遍位置对应的状态所依赖的其他状态。比如:
for (int zhangshu = 0; arr[index] * zhangshu <= aim; zhangshu++) { res += process(arr, index + 1, aim - (arr[index] * zhangshu)); }那么对于二维表中的一个普遍位置
(i,j),它所依赖的状态如下所示: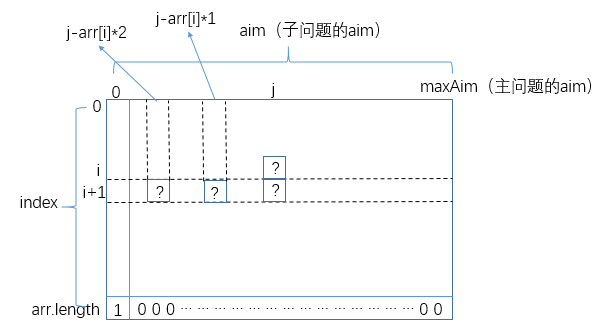
也就是说一个普遍位置的状态依赖它的下一行的几个位置上的状态。那么我们已经知道了最后一行所有位置上的状态,当然可以根据这个依赖关系推出倒数第二行的,继而推出倒数第三行的……整个二维表的所有位置上的状态都能推出来。
-
找出主问题对应二维表的哪个状态(
(0,maxAim)),那个状态的值就是问题的解。
示例代码:
public static int maxMethodsDp(int arr[], int aim) {
//二维表
int dp[][] = new int[arr.length + 1][aim + 1];
//base case
dp[arr.length][0] = 1;
//从倒数第二行开始推,推出整个二维表每个位置的状态
for (int i = arr.length - 1; i >= 0; i--) {
for (int j = 0; j <= aim; j++) {
//i对应的面值取0张
dp[i][j] = dp[i + 1][j];
//i对应的面值取1张、2张、3张……
for (int subAim = j - arr[i]; subAim >= 0; subAim = subAim - arr[i]) {
dp[i][j] += dp[i + 1][subAim];
}
}
}
return dp[0][aim];
}
public static void main(String[] args) {
int arr[] = {5, 10, 25, 1};
System.out.println(maxMethodsDp(arr, 15));
}
到这里也许你会送一口气,终于找到了最优解,其实不然,因为如果你再分析一下每个状态的求解过程,仍然存在瑕疵:
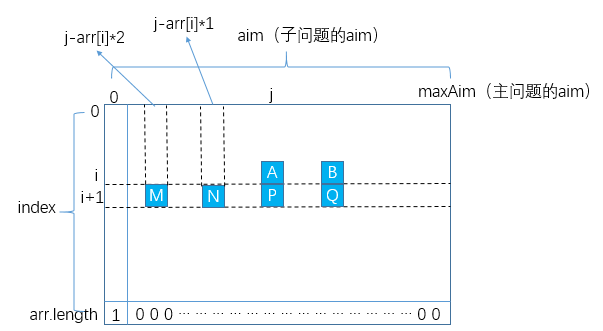
比如你在求解状态A时,可能会将其依赖的状态M,N,P的值累加起来;然后在求解状态B时,有需要将其依赖的状态M,N,P,Q累加起来,你会发现在这个过程中M+N+P的计算是重复的,因此还可以有如下优化:
for (int i = arr.length - 1; i >= 0; i--) {
for (int j = 0; j <= aim; j++) {
dp[i][j] = dp[i + 1][j];
if (j - arr[i] >= 0) {
dp[i][j] += dp[i][j - arr[i]];
}
}
}
至此,此题最优解的求解完毕。
排成一条线的纸牌博弈问题
**题目:**给定一个整型数组arr,代表分数不同的纸牌排成一条线。玩家A和玩家B依次拿走每张纸牌,规定玩家A先拿,玩家B后拿,但是每个玩家每次只能拿走最左或最右的纸牌,玩家A和玩家B都绝顶聪明。请返回最后获胜者的分数。
举例:arr=[1,2,100,4]。开始时玩家A只能拿走1或4。如果玩家A拿走1,则排列变为[2,100,4],接下来玩家B可以拿走2或4,然后继续轮到玩家A。如果开始时玩家A拿走4,则排列变为[1,2,100],接下来玩家B可以拿走1或100,然后继续轮到玩家A。玩家A作为绝顶聪明的人不会先拿4,因为拿4之后,玩家B将拿走100。所以玩家A会先拿1,让排列变为[2,100,4],接下来玩家B不管怎么选,100都会被玩家A拿走。玩家A会获胜,分数为101。所以返回101。arr=[1,100,2]。开始时玩家A不管拿1还是2,玩家B作为绝顶聪明的人,都会把100拿走。玩家B会获胜,分数为100。所以返回100。
动态规划的题难就难在暴力尝试这个“试”法,只要能够试出了暴力版本,那改为动态规划就是高度套路的。
暴力尝试
public static int maxScoreOfWinner(int arr[]) {
if (arr == null) {
return 0;
}
return Math.max(
f(arr, 0, arr.length-1),
s(arr, 0, arr.length-1));
}
public static int f(int arr[], int beginIndex, int endIndex) {
if (beginIndex == endIndex) {
return arr[beginIndex];
}
return Math.max(
arr[beginIndex] + s(arr, beginIndex + 1, endIndex),
arr[endIndex] + s(arr, beginIndex, endIndex - 1));
}
public static int s(int arr[], int beginIndex, int endIndex) {
if (beginIndex == endIndex) {
return 0;
}
return Math.min(
f(arr, beginIndex + 1, endIndex),
f(arr, beginIndex, endIndex - 1));
}
public static void main(String[] args) {
int arr[] = {1, 2, 100, 4};
System.out.println(maxScoreOfWinner(arr));//101
}
这个题的试法其实很不容易,笔者直接看别人写出的暴力尝试版本表示根本看不懂,最后还是搜了博文才弄懂。其中f()和s()就是整个尝试中的思路,与以往穷举法的暴力递归不同,这里是两个函数相互递归调用。
f(int arr[],int begin,int end)表示如果纸牌只剩下标在begin~end之间的几个了,那么作为先拿者,纸牌被拿完后,先拿者能达到的最大分数;而s(int arr[],int begin,int end)表示如果纸牌只剩下标在begin~end之间的几个了,那么作为后拿者,纸牌被拿完后,后拿者能达到的最大分数。
在f()中,如果只有一张纸牌,那么该纸牌分数就是先拿者能达到的最大分数,直接返回,无需决策。否则先拿者A的第一次决策只有两种情况:
- 先拿最左边的
arr[beginIndex],那么在A拿完这一张之后就会作为后拿者参与到剩下的(begin+1)~end之间的纸牌的决策了,这一过程可以交给s()来做。 - 先拿最右边的
arr[endIndex],那么在A拿完这一张之后就会作为后拿者参与到剩下的begin~(end-1)之间的纸牌的决策了,这一过程可以交给s()来做。
最后返回两种情况中,结果较大的那种。
在s()中,如果只有一张纸牌,那么作为后拿者没有纸牌可拿,分数为0,直接返回。否则以假设的方式巧妙的将问题递归了下去:
- 假设先拿者A拿到了
arr[beginIndex],那么去掉该纸牌后,对于剩下的(begin+1)~end之间的纸牌,后拿者B就转变身份成了先拿者,这一过程可以交给f()来处理。 - 假设先拿者A拿到了
arr[endIndex],那么去掉该纸牌后,对于剩下的begin~(end-1)之间的纸牌,后拿者B就转变身份成了先拿者,这一过程可以交给f()来处理。
这里取两种情况中结果较小的一种,是因为这两种情况是我们假设的,但先拿者A绝顶聪明,他的选择肯定会让后拿者尽可能拿到更小的分数。比如arr=[1,2,100,4],虽然我们的假设有先拿者拿1和拿4两种情况,对应f(arr,1,3)和f(arr,0,2),但实际上先拿者不会让后拿者拿到100,因此取两种情况中结果较小的一种。
改动态规划
这里是两个函数相互递归,每个函数的参数列表又都是beginIndex和endIndex是可变的,因此需要两张二维表保存(begin,end)确定时,f()和s()的状态值。
-
确定
base case对应的特殊位置上的状态值: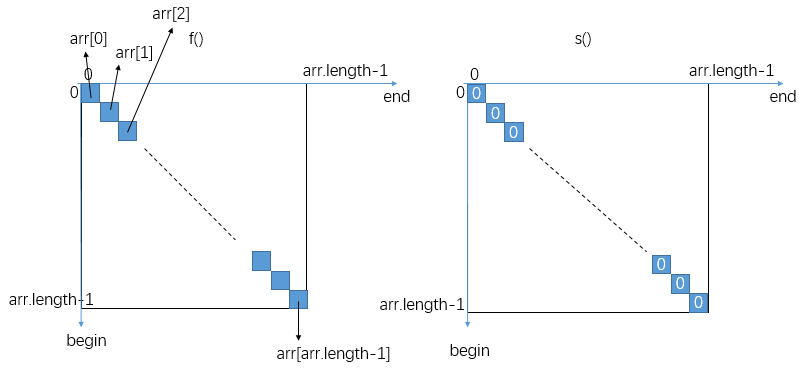
可以发现两张表的对角线位置上的状态值都是可以确定的,
begin<=end,因此对角线左下方的区域不用管。 -
由递归调用逻辑找出状态依赖。
f()依赖的状态:return Math.max( arr[beginIndex] + s(arr, beginIndex + 1, endIndex), arr[endIndex] + s(arr, beginIndex, endIndex - 1));F表的
(begin,end)依赖S表(begin+1,end)和(begin,end-1)。s()依赖的状态:return Math.min( f(arr, beginIndex + 1, endIndex), f(arr, beginIndex, endIndex - 1));S表的
(begin,end)依赖F表的(begin+1,end)和(begin,end-1)。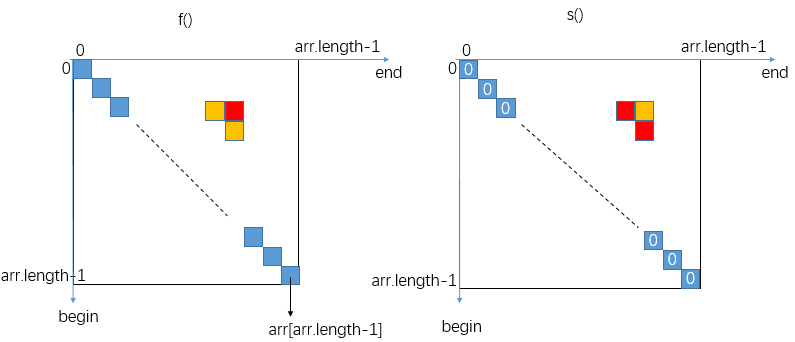
如此的话,对于对角线的右上区域,对角线位置上的状态能推出倒数第二长对角线位置上的状态,进而推出倒数第三长位置上的状态……右上区域每个位置的状态都能推出。
-
确定主问题对应的状态:
return Math.max( f(arr, 0, arr.length-1), s(arr, 0, arr.length-1));
示例代码:
public static int maxScoreOfWinnerDp(int arr[]) {
if (arr == null || arr.length == 0) {
return 0;
}
int F[][] = new int[arr.length][arr.length];
int S[][] = new int[arr.length][arr.length];
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length; j++) {
if (i == j) {
F[i][i] = arr[i];
}
}
}
//依次推出每条对角线,一共n-1条
for (int i = 1; i < arr.length; i++) {
for (int row = 0; row < arr.length - i; row++) {
int col = row + i;
F[row][col] = Math.max(arr[row] + S[row + 1][col], arr[col] + S[row][col - 1]);
S[row][col] = Math.min(F[row + 1][col], F[row][col - 1]);
}
}
return Math.max(F[0][arr.length - 1], S[0][arr.length - 1]);
}
public static void main(String[] args) {
int arr[] = {1, 2, 100, 4};
System.out.println(maxScoreOfWinnerDp(arr));
}
代码优化:
if (arr == null || arr.length == 0) {
return 0;
}
int[][] f = new int[arr.length][arr.length];
int[][] s = new int[arr.length][arr.length];
for (int j = 0; j < arr.length; j++) {
f[j][j] = arr[j];
for (int i = j - 1; i >= 0; i--) {
f[i][j] = Math.max(arr[i] + s[i + 1][j], arr[j] + s[i][j - 1]);
s[i][j] = Math.min(f[i + 1][j], f[i][j - 1]);
}
}
return Math.max(f[0][arr.length - 1], s[0][arr.length - 1]);
机器人走路问题
给你标号为1、2、3、……、N的N个位置,机器人初始停在M位置上,走P步后停在K位置上的走法有多少种。注:机器人在1位置上时只能向右走,在N位置上时只能向左走,其它位置既可向右又可向左。
public static int process(int N, int M, int P, int K) {
if (P == 0) {
return M == K ? 1 : 0;
}
if (M == 1) {
return process(N, M + 1, P - 1, K);
} else if (M == N) {
return process(N, M - 1, P - 1, K);
}
return process(N, M + 1, P - 1, K) + process(N, M - 1, P - 1, K);
}
public static void main(String[] args) {
System.out.println(process(5, 2, 3, 3));
}
这里暴力递归参数列表的可变变量有M和P,根据base case和其它特殊情况画出二维表:
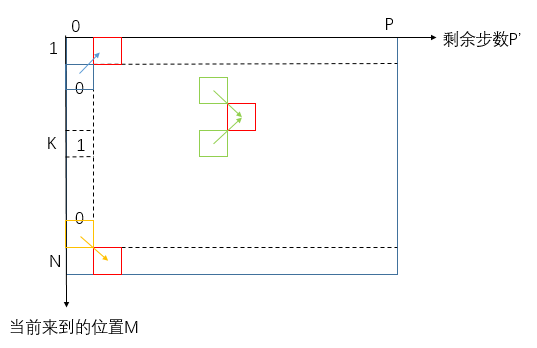
动态规划示例代码:
public static int robotWalkWaysDp(int N, int M, int P, int K) {
int dp[][] = new int[N + 1][P + 1];
dp[K][0] = 1;
for (int j = 1; j <= P; j++) {
for (int i = 1; i <= N; i++) {
if (i - 1 < 1) {
dp[i][j] = dp[i + 1][j - 1];
} else if (i + 1 > N) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = dp[i + 1][j - 1] + dp[i - 1][j - 1];
}
}
}
return dp[M][P];
}
public static void main(String[] args) {
System.out.println(robotWalkWaysDp(5, 2, 3, 3));
}
字符串正则匹配问题
给定字符串str,其中绝对不含有字符'.'和'*'。再给定字符串exp,其中可以含有'.'或'*','*'字符不能是exp的首字符,并且任意两个'*'字符不相邻。exp中的'.'代表任何一个字符,exp中的'*'表示'*'的前一个字符可以有0个或者多个。请写一个函数,判断str是否能被exp匹配。
举例:
str="abc",exp="abc",返回true。str="abc",exp="a.c",exp中单个'.'可以代表任意字符,所以返回true。str="abcd",exp=".*"。exp中'*'的前一个字符是'.',所以可表示任意数量的'.'字符,当exp是"...."时与"abcd"匹配,返回true。str="",exp="..*"。exp中'*'的前一个字符是'.',可表示任意数量的'.'字符,但是".*"之前还有一个'.'字符,该字符不受'*'的影响,所以str起码有一个字符才能被exp匹配。所以返回false。
暴力尝试
定义一个方法bool match(char[] str, int i, char[] exp, int j),表示str的下标i ~ str.length部分能否和exp的下标j ~ exp.length部分匹配,分情况讨论如下:
-
如果
j到了exp.length而i还没到str.length,返回false,否则返回true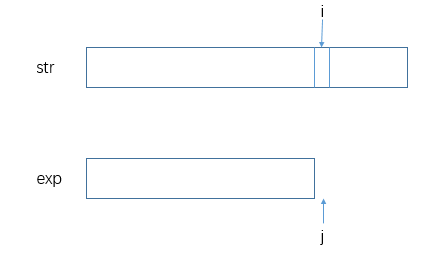
-
如果
i和j都没到右边界,并且j的后一个字符不是*或者越界,那么只有当str[i]=exp[j]或exp[j]='.'时,i和j才同时右移继续比较match(str, i+1, exp, j+1),否则返回false -
如果
i和j都没到右边界,并且j后一个字符是*,这时右有两种情况:-
str[i] = exp[j]或exp[j]='.'。比如a*可以匹配空串也可以匹配一个a,如果str[i]之后还有连续的相同字符,那么a*还可以匹配多个,不管是哪种情况,将匹配后右移的i和j交给子过程match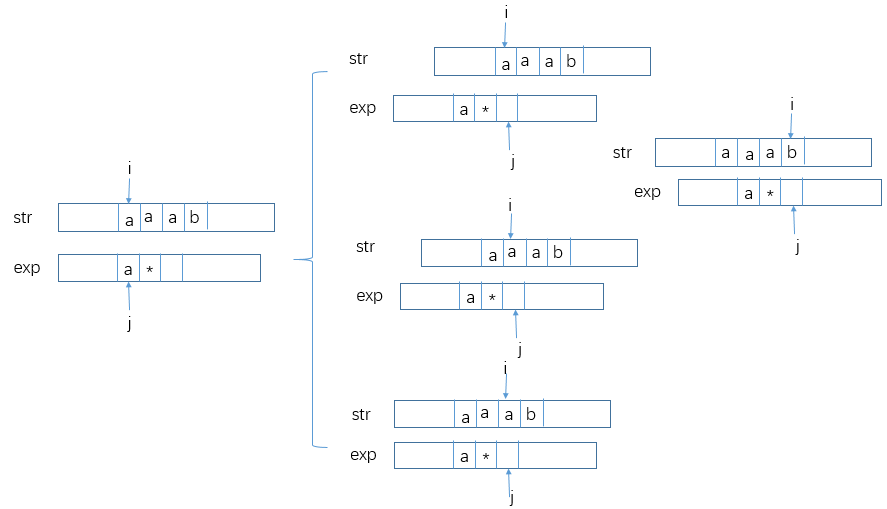
-
str[i] != exp[j]且exp[j] != ‘.’,那么exp[j]*只能选择匹配空串。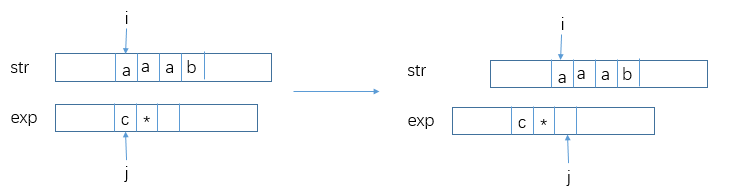
-
-
如果
i到了str.length而j还没到exp.length,那么j之后的字符只能是a*b*c*.*的形式,也就是一个字符后必须跟一个*的形式,这个检验过程同样可以交给match来做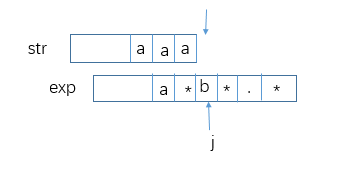
示例代码:
public static boolean match(char[] s, int i, char[] e, int j) {
if (j == e.length) {
return i == s.length;
}
//j下一个越界或者j下一个不是*
if (j + 1 == e.length || e[j + 1] != '*') {
if (i != s.length && s[i] == e[j] || e[j] == '.') {
return match(s, i + 1, e, j + 1);
}
return false;
}
//j下一个不越界并且j下一个是*
while (i != s.length && s[i] == e[j] || e[j] == '.') {
if (match(s, i, e, j + 2)) {
return true;
}
i++;
}
//如果上面的while是因为 s[i]!=e[j] 而停止的
return match(s, i, e, j + 2);
}
public static boolean isMatch(String str, String exp) {
if (str == null || exp == null) {
return false;
}
char[] s = str.toCharArray();
char[] e = exp.toCharArray();
return match(s, 0, e, 0);
}
public static void main(String[] args) {
System.out.println(isMatch("abbbbc","a.*b*c"));//T
System.out.println(isMatch("abbbbc","a.*bbc"));//T
System.out.println(isMatch("abbbbc","a.bbc"));//F
System.out.println(isMatch("abbbbc","a.bbbc"));//T
}
动态规划
match的参数列表中只有i和j是变化的,也就是说只要确定了i和j就能对应确定一个match的状态,画出二维表并将base case对应位置状态值标注出来:

再看普遍位置(i,j)的依赖,第6行的if表明(i,j)可能依赖(i+1, j+1),第13行的while表明(i,j)可能依赖(i, j+2)、(i+1, j+2)、(i+2, j+2)、……、(s.length-1, j+2):
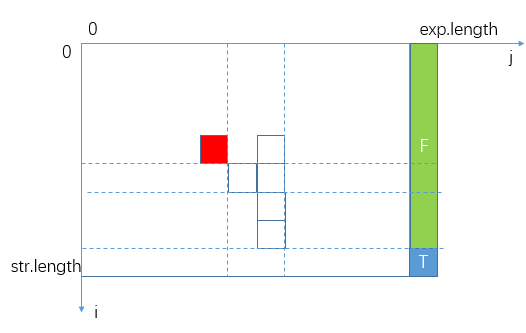
你会发现(i,j)依赖它下面一行和右边相邻两列的状态,也就是说要想推出普遍位置的状态值,起码需要最后一行、最后一列和倒数第二列上的状态值。而base case仅为我们提供了最后一列的状态值,主过程match(e, 0, s, 0)对应(0,0)位置的状态值,我们需要推出整张表所有位置的状态值才行。
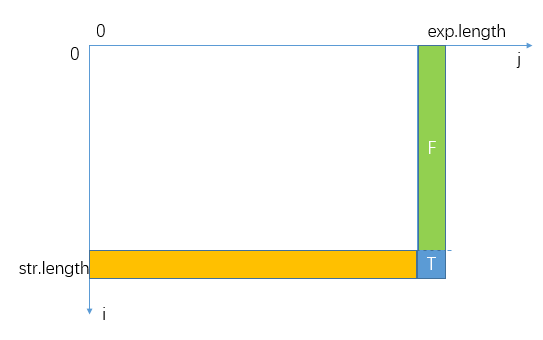
这时就要回归题意了,看倒数第二列和最后一行上的状态有什么特殊含义。
首先最后一行表示i到了str.length,此时如果j还没走完exp的话,从j开始到末尾的字符必须满足字符*字符*字符*的范式才返回true。因此最后一行状态值易求:
而对于倒数第二列,表示j来到了exp的末尾字符,此时如果i如果在str末尾字符之前,那么也是直接返回false的:
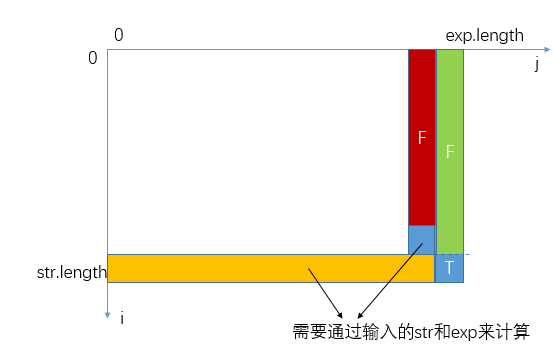
那么接下来就只剩下(str.length-1, exp.length-1)这个位置的状态值了,该位置标明i来到了str的末尾字符,j来到了exp的末尾字符,只有当这两个字符相等或exp的末尾字符为.才返回true否则false,也就是说该状态可以直接通过输入参数str和exp计算,它不依赖其他状态。二维表的初始化至此全部完成。
示例代码:
public static boolean isMatch(String str, String exp) {
if (str == null || exp == null) {
return false;
}
return matchDp(str, exp);
}
public static boolean matchDp(String str, String exp) {
if (str == null || exp == null) {
return false;
}
char s[] = str.toCharArray();
char e[] = exp.toCharArray();
boolean[][] dpMap = initDpMap(s, e);
//从倒数第二行开始推,每一行从右向左推
for (int i = s.length - 1; i > -1; i--) {
for (int j = e.length - 2; j > -1; j--) {
if (e[j + 1] != '*') {
dpMap[i][j] = (s[i] == e[j] || e[j] == '.') && dpMap[i + 1][j + 1];
} else {
int tmp = i;
while (tmp != s.length && (s[tmp] == e[j] || e[j] == '.')) {
if (dpMap[tmp][j + 2]) {
dpMap[i][j] = true;
break;
}
tmp++;
}
if (dpMap[i][j] != true) {
dpMap[i][j] = dpMap[i][j + 2];
}
}
}
}
return dpMap[0][0];
}
public static boolean[][] initDpMap(char[] s, char[] e) {
boolean[][] dpMap = new boolean[s.length + 1][e.length + 1];
//last column
dpMap[s.length][e.length] = true;
//last row -> i=s.length-1
for (int j = e.length - 2; j >= 0; j = j - 2) {
if (e[j] != '*' && e[j + 1] == '*') {
dpMap[s.length - 1][j] = true;
} else {
break;
}
}
//(str.length-1, e.length-1)
if (s[s.length - 1] == e[e.length - 1] || e[e.length - 1] == '.') {
dpMap[s.length - 1][e.length - 1] = true;
}
return dpMap;
}
缓存结构的设计
设计可以变更的缓存结构(LRU)
设计一种缓存结构,该结构在构造时确定大小,假设大小为K,并有两个功能:set(key,value):将记录(key,value)插入该结构。get(key):返回key对应的value值。
【要求】
- set和get方法的时间复杂度为O(1)。
- 某个key的set或get操作一旦发生,认为这个key的记录成了最经常使用的。
- 当缓存的大小超过K时,移除最不经常使用的记录,即set或get最久远的。
【举例】
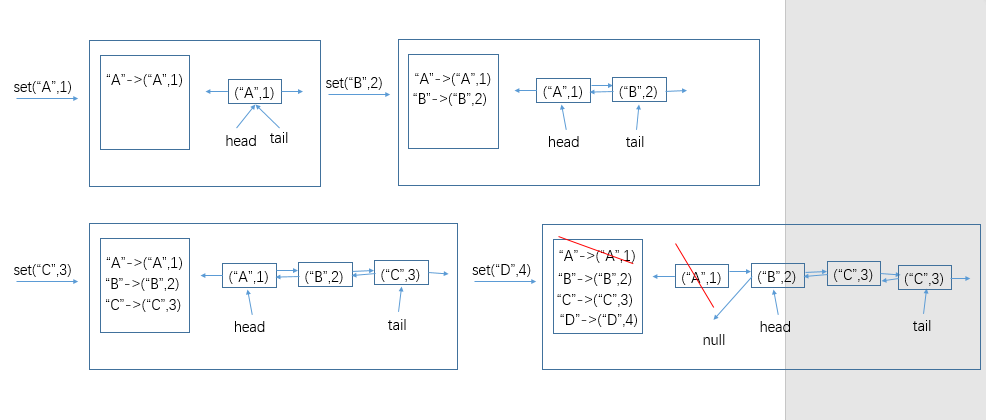
假设缓存结构的实例是cache,大小为3,并依次发生如下行为:
- cache.set("A",1)。最经常使用的记录为("A",1)。
- cache.set("B",2)。最经常使用的记录为("B",2),("A",1)变为最不经常的。
- cache.set("C",3)。最经常使用的记录为("C",2),("A",1)还是最不经常的。
- cache.get("A")。最经常使用的记录为("A",1),("B",2)变为最不经常的。
- cache.set("D",4)。大小超过了3,所以移除此时最不经常使用的记录("B",2),加入记录 ("D",4),并且为最经常使用的记录,然后("C",2)变为最不经常使用的记录
设计思路:使用一个哈希表和双向链表
示例代码:
package top.zhenganwen.structure;
import java.util.HashMap;
public class LRU {
public static class Node<K,V>{
K key;
V value;
Node<K,V> prev;
Node<K, V> next;
public Node(K key, V value) {
this.key = key;
this.value = value;
this.prev = null;
this.next = null;
}
}
/**
* the head is the oldest record and the tail is the newest record
*
* the add() will append the record to tail
*
* @param <K> key
* @param <V> value
*/
public static class DoubleLinkedList<K,V>{
Node<K,V> head;
Node<K, V> tail;
public DoubleLinkedList() {
this.head = null;
this.tail = null;
}
public void add(Node<K,V> node){
if (node == null) {
return;
}
if (this.head == null) {
this.head = node;
this.tail = node;
} else {
this.tail.next = node;
node.prev = this.tail;
this.tail = node;
}
}
public void moveToTail(Node<K,V> node){
if (node == this.tail) {
return;
}
if (node == this.head) {
Node<K, V> newHead = node.next;
newHead.prev = null;
this.head = newHead;
node.next = null;
node.prev = this.tail;
this.tail.next = node;
this.tail = node;
} else {
node.prev.next = node.next;
node.next.prev = node.prev;
node.next=null;
node.prev=this.tail;
this.tail.next = node;
this.tail = node;
}
}
public K removeHead() {
if (this.head != null) {
K deletedK = this.head.key;
if (this.head == this.tail) {
this.head = null;
this.tail = null;
} else {
Node<K, V> newHead = this.head.next;
newHead.prev = null;
this.head = newHead;
}
return deletedK;
}
return null;
}
}
public static class MyCache<K,V>{
HashMap<K, Node<K, V>> map = new HashMap<>();
DoubleLinkedList list = new DoubleLinkedList();
int capacity;
public MyCache(int capacity) {
this.capacity = capacity;
}
public void set(K key, V value) {
if (map.containsKey(key)) {
//swap value
//update map
Node<K, V> node = map.get(key);
node.value = value;
map.put(key, node);
//update list
list.moveToTail(node);
} else {
//save record
//if full,remove the oldest first and then save
if (map.size() == this.capacity) {
K deletedK = (K) list.removeHead();
map.remove(deletedK);
}
Node<K, V> record = new Node<>(key, value);
map.put(key, record);
list.add(record);
}
}
public V get(K key) {
if (map.containsKey(key)) {
Node<K, V> target = map.get(key);
list.moveToTail(target);
return target.value;
} else {
return null;
}
}
}
public static void main(String[] args) {
MyCache<String, Integer> myCache = new MyCache<>(3);
myCache.set("A", 1);
myCache.set("B", 2);
myCache.set("C", 3);
System.out.println(myCache.get("A"));
myCache.set("D", 4);
System.out.println(myCache.get("B"));
}
}
面试技巧:
在刷题时,如果感觉这个题明显在30分钟内解不出来就放弃,因为面试给出的题目一般会让你在30分内解出。
在面试时如果碰到自己遇到过的题也要装作没遇到过,假装一番苦思冥想、和面试官沟通细节,然后突然想通了的样子。
LFU
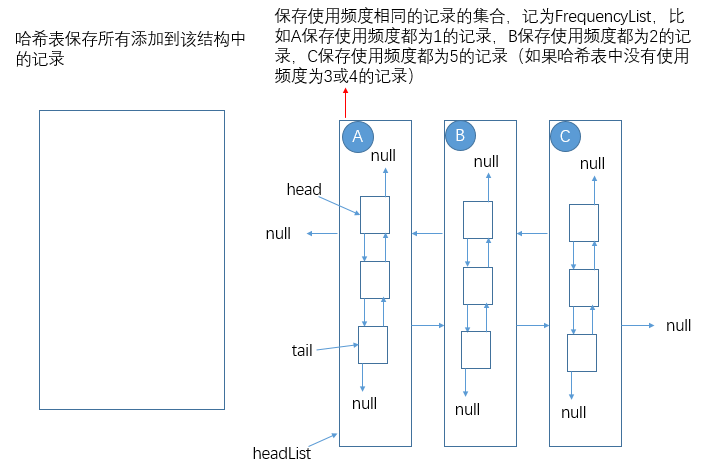
LFU也是一种经典的缓存结构,只不过它是以key的访问频度作为缓存替换依据的。
举例:set("A",Data)将会在LFU结构中放入一条key为“A”的记录,并将该记录的使用频度置为1,后续的set("A",newData)或get("A")都会将该key对应的记录的使用频度加1;当该结构容量已满还尝试往里添加记录时,会先将结构中使用频度最少的记录删除,再将新的记录添加进去。
设计思路:使用一个哈希表和一个二维双向链表(链表中包含链表)
示例代码:
import java.util.HashMap;
public class LFUCache<K,V>{
/**
* Save all record
*/
private HashMap<K, Record<K,V>> recordMap;
/**
* The reference of the FrequencyList whose frequency is the lowest
*/
private FrequencyList headList;
/**
* Save what FrequencyList a record belongs to
*/
private HashMap<Record,FrequencyList> listOfRecord;
/**
* How many recordMap the LFUCache can contain
*/
private int capacity;
/**
* how many recordMap has been saved
*/
private int size;
public LFUCache(int capacity) {
this.recordMap = new HashMap();
this.listOfRecord = new HashMap<>();
this.headList = null;
this.capacity = capacity;
this.size = 0;
}
/**
* add or update a record
* @param key
* @param value
*/
public void set(K key, V value) {
//update
if (this.recordMap.containsKey(key)) {
//update value and frequency
Record<K, V> record = recordMap.get(key);
record.value = value;
record.frequency++;
//adjust the record's position in FrequencyList
adjust(record, listOfRecord.get(record));
} else {
//add
if (size == capacity) {
//delete
recordMap.remove(headList.tail.key);
headList.deleteRecord(headList.tail);
size--;
modifyFrequencyList(headList);
}
Record<K, V> newRecord = new Record<>(key, value);
recordMap.put(key, newRecord);
size++;
if (headList == null) {
headList = new FrequencyList(newRecord);
} else if (headList.head.frequency != 1) {
FrequencyList frequencyList = new FrequencyList(newRecord);
headList.prev = frequencyList;
frequencyList.next = headList;
frequencyList.prev = null;
headList = frequencyList;
} else {
headList.addRecordToHead(newRecord);
}
listOfRecord.put(newRecord, headList);
}
}
/**
* get a record by a key,return null if not exists
* @param key
* @return
*/
public V get(K key) {
if (!recordMap.containsKey(key)) {
return null;
}
Record<K, V> record = recordMap.get(key);
record.frequency++;
adjust(record, listOfRecord.get(record));
return record.value;
}
/**
* When the record's frequency changed,split it from its current
* FrequencyList and insert to another one
*
* @param record
* @param frequencyList
*/
private void adjust(Record<K, V> record, FrequencyList frequencyList) {
//split
frequencyList.deleteRecord(record);
boolean deleted = modifyFrequencyList(frequencyList);
//insert to anther one
FrequencyList prevList = frequencyList.prev;
FrequencyList nextList = frequencyList.next;
if (nextList != null && record.frequency == nextList.head.frequency) {
nextList.addRecordToHead(record);
listOfRecord.put(record, nextList);
} else {
FrequencyList newList = new FrequencyList(record);
if (prevList == null) {
if (nextList != null) {
nextList.prev = newList;
}
newList.next = nextList;
newList.prev = null;
headList = newList;
} else if (nextList == null) {
prevList.next = newList;
newList.prev = prevList;
newList.next = null;
} else {
prevList.next = newList;
newList.prev = prevList;
newList.next = nextList;
nextList.prev = newList;
}
listOfRecord.put(record, newList);
}
}
/**
* return whether the frequencyList is deleted
* @param frequencyList
* @return
*/
private boolean modifyFrequencyList(FrequencyList frequencyList) {
if (!frequencyList.isEmpty()) {
return false;
}
if (frequencyList.prev == null) {
headList = frequencyList.next;
if (headList != null) {
headList.prev = null;
}
} else if (frequencyList.next == null) {
frequencyList.prev.next = null;
} else {
frequencyList.prev.next = frequencyList.next;
frequencyList.next.prev = frequencyList.prev;
}
return true;
}
/**
* The Record can be design to Record<K,V> or Record<V> used
* to encapsulate data
* @param <K> key
* @param <V> value
*/
private class Record<K,V> {
K key;
V value;
/**
* up->the predecessor pointer
* down->the successor pointer
*/
Record<K, V> up;
Record<K, V> down;
/**
* the frequency of use
*/
int frequency;
/**
* when the record was created , set the frequency to 1
*
* @param key
* @param value
*/
public Record(K key, V value) {
this.key = key;
this.value = value;
this.frequency = 1;
}
}
/**
* The FrequencyList save a series of Records that
* has the same frequency
*/
private class FrequencyList {
/**
* prev->the predecessor pointer
* next->the successor pointer
*/
FrequencyList prev;
FrequencyList next;
/**
* The reference of the internal RecordList's head and tail
*/
Record<K,V> head;
Record<K,V> tail;
public FrequencyList(Record<K, V> record) {
this.head = record;
this.tail = record;
}
public void addRecordToHead(Record<K, V> record) {
head.up = record;
record.down = head;
head = record;
}
public boolean isEmpty() {
return head == null;
}
public void deleteRecord(Record<K,V> record) {
if (head == tail) {
head = null;
tail = null;
} else if (record == head) {
head=head.down;
head.up = null;
} else if (record == tail) {
tail = tail.up;
tail.down = null;
} else {
record.up.down = record.down;
record.down.up = record.up;
}
}
}
public static void main(String[] args) {
LFUCache<String, Integer> cache = new LFUCache<>(3);
cache.set("A", 1);
cache.set("A", 1);
cache.set("A", 1);
cache.set("B", 2);
cache.set("B", 2);
cache.set("C", 3);
cache.set("D", 4);
System.out.println("break point");
}
}
附录
手写二叉搜索树
下列代码来源于
github
AbstractBinarySearchTree
/**
* Not implemented by zhenganwen
*
* Abstract binary search tree implementation. Its basically fully implemented
* binary search tree, just template method is provided for creating Node (other
* trees can have slightly different nodes with more info). This way some code
* from standart binary search tree can be reused for other kinds of binary
* trees.
*
* @author Ignas Lelys
* @created Jun 29, 2011
*
*/
public class AbstractBinarySearchTree {
/** Root node where whole tree starts. */
public Node root;
/** Tree size. */
protected int size;
/**
* Because this is abstract class and various trees have different
* additional information on different nodes subclasses uses this abstract
* method to create nodes (maybe of class {@link Node} or maybe some
* different node sub class).
*
* @param value
* Value that node will have.
* @param parent
* Node's parent.
* @param left
* Node's left child.
* @param right
* Node's right child.
* @return Created node instance.
*/
protected Node createNode(int value, Node parent, Node left, Node right) {
return new Node(value, parent, left, right);
}
/**
* Finds a node with concrete value. If it is not found then null is
* returned.
*
* @param element
* Element value.
* @return Node with value provided, or null if not found.
*/
public Node search(int element) {
Node node = root;
while (node != null && node.value != null && node.value != element) {
if (element < node.value) {
node = node.left;
} else {
node = node.right;
}
}
return node;
}
/**
* Insert new element to tree.
*
* @param element
* Element to insert.
*/
public Node insert(int element) {
if (root == null) {
root = createNode(element, null, null, null);
size++;
return root;
}
Node insertParentNode = null;
Node searchTempNode = root;
while (searchTempNode != null && searchTempNode.value != null) {
insertParentNode = searchTempNode;
if (element < searchTempNode.value) {
searchTempNode = searchTempNode.left;
} else {
searchTempNode = searchTempNode.right;
}
}
Node newNode = createNode(element, insertParentNode, null, null);
if (insertParentNode.value > newNode.value) {
insertParentNode.left = newNode;
} else {
insertParentNode.right = newNode;
}
size++;
return newNode;
}
/**
* Removes element if node with such value exists.
*
* @param element
* Element value to remove.
*
* @return New node that is in place of deleted node. Or null if element for
* delete was not found.
*/
public Node delete(int element) {
Node deleteNode = search(element);
if (deleteNode != null) {
return delete(deleteNode);
} else {
return null;
}
}
/**
* Delete logic when node is already found.
*
* @param deleteNode
* Node that needs to be deleted.
*
* @return New node that is in place of deleted node. Or null if element for
* delete was not found.
*/
protected Node delete(Node deleteNode) {
if (deleteNode != null) {
Node nodeToReturn = null;
if (deleteNode != null) {
if (deleteNode.left == null) {
nodeToReturn = transplant(deleteNode, deleteNode.right);
} else if (deleteNode.right == null) {
nodeToReturn = transplant(deleteNode, deleteNode.left);
} else {
Node successorNode = getMinimum(deleteNode.right);
if (successorNode.parent != deleteNode) {
transplant(successorNode, successorNode.right);
successorNode.right = deleteNode.right;
successorNode.right.parent = successorNode;
}
transplant(deleteNode, successorNode);
successorNode.left = deleteNode.left;
successorNode.left.parent = successorNode;
nodeToReturn = successorNode;
}
size--;
}
return nodeToReturn;
}
return null;
}
/**
* Put one node from tree (newNode) to the place of another (nodeToReplace).
*
* @param nodeToReplace
* Node which is replaced by newNode and removed from tree.
* @param newNode
* New node.
*
* @return New replaced node.
*/
private Node transplant(Node nodeToReplace, Node newNode) {
if (nodeToReplace.parent == null) {
this.root = newNode;
} else if (nodeToReplace == nodeToReplace.parent.left) {
nodeToReplace.parent.left = newNode;
} else {
nodeToReplace.parent.right = newNode;
}
if (newNode != null) {
newNode.parent = nodeToReplace.parent;
}
return newNode;
}
/**
* @param element
* @return true if tree contains element.
*/
public boolean contains(int element) {
return search(element) != null;
}
/**
* @return Minimum element in tree.
*/
public int getMinimum() {
return getMinimum(root).value;
}
/**
* @return Maximum element in tree.
*/
public int getMaximum() {
return getMaximum(root).value;
}
/**
* Get next element element who is bigger than provided element.
*
* @param element
* Element for whom descendand element is searched
* @return Successor value.
*/
// TODO Predecessor
public int getSuccessor(int element) {
return getSuccessor(search(element)).value;
}
/**
* @return Number of elements in the tree.
*/
public int getSize() {
return size;
}
/**
* Tree traversal with printing element values. In order method.
*/
public void printTreeInOrder() {
printTreeInOrder(root);
}
/**
* Tree traversal with printing element values. Pre order method.
*/
public void printTreePreOrder() {
printTreePreOrder(root);
}
/**
* Tree traversal with printing element values. Post order method.
*/
public void printTreePostOrder() {
printTreePostOrder(root);
}
/*-------------------PRIVATE HELPER METHODS-------------------*/
private void printTreeInOrder(Node entry) {
if (entry != null) {
printTreeInOrder(entry.left);
if (entry.value != null) {
System.out.println(entry.value);
}
printTreeInOrder(entry.right);
}
}
private void printTreePreOrder(Node entry) {
if (entry != null) {
if (entry.value != null) {
System.out.println(entry.value);
}
printTreeInOrder(entry.left);
printTreeInOrder(entry.right);
}
}
private void printTreePostOrder(Node entry) {
if (entry != null) {
printTreeInOrder(entry.left);
printTreeInOrder(entry.right);
if (entry.value != null) {
System.out.println(entry.value);
}
}
}
protected Node getMinimum(Node node) {
while (node.left != null) {
node = node.left;
}
return node;
}
protected Node getMaximum(Node node) {
while (node.right != null) {
node = node.right;
}
return node;
}
protected Node getSuccessor(Node node) {
// if there is right branch, then successor is leftmost node of that
// subtree
if (node.right != null) {
return getMinimum(node.right);
} else { // otherwise it is a lowest ancestor whose left child is also
// ancestor of node
Node currentNode = node;
Node parentNode = node.parent;
while (parentNode != null && currentNode == parentNode.right) {
// go up until we find parent that currentNode is not in right
// subtree.
currentNode = parentNode;
parentNode = parentNode.parent;
}
return parentNode;
}
}
// -------------------------------- TREE PRINTING
// ------------------------------------
public void printTree() {
printSubtree(root);
}
public void printSubtree(Node node) {
if (node.right != null) {
printTree(node.right, true, "");
}
printNodeValue(node);
if (node.left != null) {
printTree(node.left, false, "");
}
}
private void printNodeValue(Node node) {
if (node.value == null) {
System.out.print("<null>");
} else {
System.out.print(node.value.toString());
}
System.out.println();
}
private void printTree(Node node, boolean isRight, String indent) {
if (node.right != null) {
printTree(node.right, true, indent + (isRight ? " " : " | "));
}
System.out.print(indent);
if (isRight) {
System.out.print(" /");
} else {
System.out.print(" \\");
}
System.out.print("----- ");
printNodeValue(node);
if (node.left != null) {
printTree(node.left, false, indent + (isRight ? " | " : " "));
}
}
public static class Node {
public Node(Integer value, Node parent, Node left, Node right) {
super();
this.value = value;
this.parent = parent;
this.left = left;
this.right = right;
}
public Integer value;
public Node parent;
public Node left;
public Node right;
public boolean isLeaf() {
return left == null && right == null;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((value == null) ? 0 : value.hashCode());
return result;
}
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Node other = (Node) obj;
if (value == null) {
if (other.value != null)
return false;
} else if (!value.equals(other.value))
return false;
return true;
}
}
}
AbstractSelfBalancingBinarySearchTree
package advanced_class_03;
/**
* Not implemented by zhenganwen
*
* Abstract class for self balancing binary search trees. Contains some methods
* that is used for self balancing trees.
*
* @author Ignas Lelys
* @created Jul 24, 2011
*
*/
public abstract class AbstractSelfBalancingBinarySearchTree extends AbstractBinarySearchTree {
/**
* Rotate to the left.
*
* @param node Node on which to rotate.
* @return Node that is in place of provided node after rotation.
*/
protected Node rotateLeft(Node node) {
Node temp = node.right;
temp.parent = node.parent;
node.right = temp.left;
if (node.right != null) {
node.right.parent = node;
}
temp.left = node;
node.parent = temp;
// temp took over node's place so now its parent should point to temp
if (temp.parent != null) {
if (node == temp.parent.left) {
temp.parent.left = temp;
} else {
temp.parent.right = temp;
}
} else {
root = temp;
}
return temp;
}
/**
* Rotate to the right.
*
* @param node Node on which to rotate.
* @return Node that is in place of provided node after rotation.
*/
protected Node rotateRight(Node node) {
Node temp = node.left;
temp.parent = node.parent;
node.left = temp.right;
if (node.left != null) {
node.left.parent = node;
}
temp.right = node;
node.parent = temp;
// temp took over node's place so now its parent should point to temp
if (temp.parent != null) {
if (node == temp.parent.left) {
temp.parent.left = temp;
} else {
temp.parent.right = temp;
}
} else {
root = temp;
}
return temp;
}
}
AVLTree
/**
* Not implemented by zhenganwen
*
* AVL tree implementation.
*
* In computer science, an AVL tree is a self-balancing binary search tree, and
* it was the first such data structure to be invented.[1] In an AVL tree, the
* heights of the two child subtrees of any node differ by at most one. Lookup,
* insertion, and deletion all take O(log n) time in both the average and worst
* cases, where n is the number of nodes in the tree prior to the operation.
* Insertions and deletions may require the tree to be rebalanced by one or more
* tree rotations.
*
* @author Ignas Lelys
* @created Jun 28, 2011
*
*/
public class AVLTree extends AbstractSelfBalancingBinarySearchTree {
/**
* @see trees.AbstractBinarySearchTree#insert(int)
*
* AVL tree insert method also balances tree if needed. Additional
* height parameter on node is used to track if one subtree is higher
* than other by more than one, if so AVL tree rotations is performed
* to regain balance of the tree.
*/
@Override
public Node insert(int element) {
Node newNode = super.insert(element);
rebalance((AVLNode)newNode);
return newNode;
}
/**
* @see trees.AbstractBinarySearchTree#delete(int)
*/
@Override
public Node delete(int element) {
Node deleteNode = super.search(element);
if (deleteNode != null) {
Node successorNode = super.delete(deleteNode);
if (successorNode != null) {
// if replaced from getMinimum(deleteNode.right) then come back there and update heights
AVLNode minimum = successorNode.right != null ? (AVLNode)getMinimum(successorNode.right) : (AVLNode)successorNode;
recomputeHeight(minimum);
rebalance((AVLNode)minimum);
} else {
recomputeHeight((AVLNode)deleteNode.parent);
rebalance((AVLNode)deleteNode.parent);
}
return successorNode;
}
return null;
}
/**
* @see trees.AbstractBinarySearchTree#createNode(int, trees.AbstractBinarySearchTree.Node, trees.AbstractBinarySearchTree.Node, trees.AbstractBinarySearchTree.Node)
*/
@Override
protected Node createNode(int value, Node parent, Node left, Node right) {
return new AVLNode(value, parent, left, right);
}
/**
* Go up from inserted node, and update height and balance informations if needed.
* If some node balance reaches 2 or -2 that means that subtree must be rebalanced.
*
* @param node Inserted Node.
*/
private void rebalance(AVLNode node) {
while (node != null) {
Node parent = node.parent;
int leftHeight = (node.left == null) ? -1 : ((AVLNode) node.left).height;
int rightHeight = (node.right == null) ? -1 : ((AVLNode) node.right).height;
int nodeBalance = rightHeight - leftHeight;
// rebalance (-2 means left subtree outgrow, 2 means right subtree)
if (nodeBalance == 2) {
if (node.right.right != null) {
node = (AVLNode)avlRotateLeft(node);
break;
} else {
node = (AVLNode)doubleRotateRightLeft(node);
break;
}
} else if (nodeBalance == -2) {
if (node.left.left != null) {
node = (AVLNode)avlRotateRight(node);
break;
} else {
node = (AVLNode)doubleRotateLeftRight(node);
break;
}
} else {
updateHeight(node);
}
node = (AVLNode)parent;
}
}
/**
* Rotates to left side.
*/
private Node avlRotateLeft(Node node) {
Node temp = super.rotateLeft(node);
updateHeight((AVLNode)temp.left);
updateHeight((AVLNode)temp);
return temp;
}
/**
* Rotates to right side.
*/
private Node avlRotateRight(Node node) {
Node temp = super.rotateRight(node);
updateHeight((AVLNode)temp.right);
updateHeight((AVLNode)temp);
return temp;
}
/**
* Take right child and rotate it to the right side first and then rotate
* node to the left side.
*/
protected Node doubleRotateRightLeft(Node node) {
node.right = avlRotateRight(node.right);
return avlRotateLeft(node);
}
/**
* Take right child and rotate it to the right side first and then rotate
* node to the left side.
*/
protected Node doubleRotateLeftRight(Node node) {
node.left = avlRotateLeft(node.left);
return avlRotateRight(node);
}
/**
* Recomputes height information from the node and up for all of parents. It needs to be done after delete.
*/
private void recomputeHeight(AVLNode node) {
while (node != null) {
node.height = maxHeight((AVLNode)node.left, (AVLNode)node.right) + 1;
node = (AVLNode)node.parent;
}
}
/**
* Returns higher height of 2 nodes.
*/
private int maxHeight(AVLNode node1, AVLNode node2) {
if (node1 != null && node2 != null) {
return node1.height > node2.height ? node1.height : node2.height;
} else if (node1 == null) {
return node2 != null ? node2.height : -1;
} else if (node2 == null) {
return node1 != null ? node1.height : -1;
}
return -1;
}
/**
* Updates height and balance of the node.
*
* @param node Node for which height and balance must be updated.
*/
private static final void updateHeight(AVLNode node) {
int leftHeight = (node.left == null) ? -1 : ((AVLNode) node.left).height;
int rightHeight = (node.right == null) ? -1 : ((AVLNode) node.right).height;
node.height = 1 + Math.max(leftHeight, rightHeight);
}
/**
* Node of AVL tree has height and balance additional properties. If balance
* equals 2 (or -2) that node needs to be re balanced. (Height is height of
* the subtree starting with this node, and balance is difference between
* left and right nodes heights).
*
* @author Ignas Lelys
* @created Jun 30, 2011
*
*/
protected static class AVLNode extends Node {
public int height;
public AVLNode(int value, Node parent, Node left, Node right) {
super(value, parent, left, right);
}
}
}
RedBlackTree
/**
* Not implemented by zhenganwen
*
* Red-Black tree implementation. From Introduction to Algorithms 3rd edition.
*
* @author Ignas Lelys
* @created May 6, 2011
*
*/
public class RedBlackTree extends AbstractSelfBalancingBinarySearchTree {
protected enum ColorEnum {
RED,
BLACK
};
protected static final RedBlackNode nilNode = new RedBlackNode(null, null, null, null, ColorEnum.BLACK);
/**
* @see trees.AbstractBinarySearchTree#insert(int)
*/
@Override
public Node insert(int element) {
Node newNode = super.insert(element);
newNode.left = nilNode;
newNode.right = nilNode;
root.parent = nilNode;
insertRBFixup((RedBlackNode) newNode);
return newNode;
}
/**
* Slightly modified delete routine for red-black tree.
*
* {@inheritDoc}
*/
@Override
protected Node delete(Node deleteNode) {
Node replaceNode = null; // track node that replaces removedOrMovedNode
if (deleteNode != null && deleteNode != nilNode) {
Node removedOrMovedNode = deleteNode; // same as deleteNode if it has only one child, and otherwise it replaces deleteNode
ColorEnum removedOrMovedNodeColor = ((RedBlackNode)removedOrMovedNode).color;
if (deleteNode.left == nilNode) {
replaceNode = deleteNode.right;
rbTreeTransplant(deleteNode, deleteNode.right);
} else if (deleteNode.right == nilNode) {
replaceNode = deleteNode.left;
rbTreeTransplant(deleteNode, deleteNode.left);
} else {
removedOrMovedNode = getMinimum(deleteNode.right);
removedOrMovedNodeColor = ((RedBlackNode)removedOrMovedNode).color;
replaceNode = removedOrMovedNode.right;
if (removedOrMovedNode.parent == deleteNode) {
replaceNode.parent = removedOrMovedNode;
} else {
rbTreeTransplant(removedOrMovedNode, removedOrMovedNode.right);
removedOrMovedNode.right = deleteNode.right;
removedOrMovedNode.right.parent = removedOrMovedNode;
}
rbTreeTransplant(deleteNode, removedOrMovedNode);
removedOrMovedNode.left = deleteNode.left;
removedOrMovedNode.left.parent = removedOrMovedNode;
((RedBlackNode)removedOrMovedNode).color = ((RedBlackNode)deleteNode).color;
}
size--;
if (removedOrMovedNodeColor == ColorEnum.BLACK) {
deleteRBFixup((RedBlackNode)replaceNode);
}
}
return replaceNode;
}
/**
* @see trees.AbstractBinarySearchTree#createNode(int, trees.AbstractBinarySearchTree.Node, trees.AbstractBinarySearchTree.Node, trees.AbstractBinarySearchTree.Node)
*/
@Override
protected Node createNode(int value, Node parent, Node left, Node right) {
return new RedBlackNode(value, parent, left, right, ColorEnum.RED);
}
/**
* {@inheritDoc}
*/
@Override
protected Node getMinimum(Node node) {
while (node.left != nilNode) {
node = node.left;
}
return node;
}
/**
* {@inheritDoc}
*/
@Override
protected Node getMaximum(Node node) {
while (node.right != nilNode) {
node = node.right;
}
return node;
}
/**
* {@inheritDoc}
*/
@Override
protected Node rotateLeft(Node node) {
Node temp = node.right;
temp.parent = node.parent;
node.right = temp.left;
if (node.right != nilNode) {
node.right.parent = node;
}
temp.left = node;
node.parent = temp;
// temp took over node's place so now its parent should point to temp
if (temp.parent != nilNode) {
if (node == temp.parent.left) {
temp.parent.left = temp;
} else {
temp.parent.right = temp;
}
} else {
root = temp;
}
return temp;
}
/**
* {@inheritDoc}
*/
@Override
protected Node rotateRight(Node node) {
Node temp = node.left;
temp.parent = node.parent;
node.left = temp.right;
if (node.left != nilNode) {
node.left.parent = node;
}
temp.right = node;
node.parent = temp;
// temp took over node's place so now its parent should point to temp
if (temp.parent != nilNode) {
if (node == temp.parent.left) {
temp.parent.left = temp;
} else {
temp.parent.right = temp;
}
} else {
root = temp;
}
return temp;
}
/**
* Similar to original transplant() method in BST but uses nilNode instead of null.
*/
private Node rbTreeTransplant(Node nodeToReplace, Node newNode) {
if (nodeToReplace.parent == nilNode) {
this.root = newNode;
} else if (nodeToReplace == nodeToReplace.parent.left) {
nodeToReplace.parent.left = newNode;
} else {
nodeToReplace.parent.right = newNode;
}
newNode.parent = nodeToReplace.parent;
return newNode;
}
/**
* Restores Red-Black tree properties after delete if needed.
*/
private void deleteRBFixup(RedBlackNode x) {
while (x != root && isBlack(x)) {
if (x == x.parent.left) {
RedBlackNode w = (RedBlackNode)x.parent.right;
if (isRed(w)) { // case 1 - sibling is red
w.color = ColorEnum.BLACK;
((RedBlackNode)x.parent).color = ColorEnum.RED;
rotateLeft(x.parent);
w = (RedBlackNode)x.parent.right; // converted to case 2, 3 or 4
}
// case 2 sibling is black and both of its children are black
if (isBlack(w.left) && isBlack(w.right)) {
w.color = ColorEnum.RED;
x = (RedBlackNode)x.parent;
} else if (w != nilNode) {
if (isBlack(w.right)) { // case 3 sibling is black and its left child is red and right child is black
((RedBlackNode)w.left).color = ColorEnum.BLACK;
w.color = ColorEnum.RED;
rotateRight(w);
w = (RedBlackNode)x.parent.right;
}
w.color = ((RedBlackNode)x.parent).color; // case 4 sibling is black and right child is red
((RedBlackNode)x.parent).color = ColorEnum.BLACK;
((RedBlackNode)w.right).color = ColorEnum.BLACK;
rotateLeft(x.parent);
x = (RedBlackNode)root;
} else {
x.color = ColorEnum.BLACK;
x = (RedBlackNode)x.parent;
}
} else {
RedBlackNode w = (RedBlackNode)x.parent.left;
if (isRed(w)) { // case 1 - sibling is red
w.color = ColorEnum.BLACK;
((RedBlackNode)x.parent).color = ColorEnum.RED;
rotateRight(x.parent);
w = (RedBlackNode)x.parent.left; // converted to case 2, 3 or 4
}
// case 2 sibling is black and both of its children are black
if (isBlack(w.left) && isBlack(w.right)) {
w.color = ColorEnum.RED;
x = (RedBlackNode)x.parent;
} else if (w != nilNode) {
if (isBlack(w.left)) { // case 3 sibling is black and its right child is red and left child is black
((RedBlackNode)w.right).color = ColorEnum.BLACK;
w.color = ColorEnum.RED;
rotateLeft(w);
w = (RedBlackNode)x.parent.left;
}
w.color = ((RedBlackNode)x.parent).color; // case 4 sibling is black and left child is red
((RedBlackNode)x.parent).color = ColorEnum.BLACK;
((RedBlackNode)w.left).color = ColorEnum.BLACK;
rotateRight(x.parent);
x = (RedBlackNode)root;
} else {
x.color = ColorEnum.BLACK;
x = (RedBlackNode)x.parent;
}
}
}
}
private boolean isBlack(Node node) {
return node != null ? ((RedBlackNode)node).color == ColorEnum.BLACK : false;
}
private boolean isRed(Node node) {
return node != null ? ((RedBlackNode)node).color == ColorEnum.RED : false;
}
/**
* Restores Red-Black tree properties after insert if needed. Insert can
* break only 2 properties: root is red or if node is red then children must
* be black.
*/
private void insertRBFixup(RedBlackNode currentNode) {
// current node is always RED, so if its parent is red it breaks
// Red-Black property, otherwise no fixup needed and loop can terminate
while (currentNode.parent != root && ((RedBlackNode) currentNode.parent).color == ColorEnum.RED) {
RedBlackNode parent = (RedBlackNode) currentNode.parent;
RedBlackNode grandParent = (RedBlackNode) parent.parent;
if (parent == grandParent.left) {
RedBlackNode uncle = (RedBlackNode) grandParent.right;
// case1 - uncle and parent are both red
// re color both of them to black
if (((RedBlackNode) uncle).color == ColorEnum.RED) {
parent.color = ColorEnum.BLACK;
uncle.color = ColorEnum.BLACK;
grandParent.color = ColorEnum.RED;
// grandparent was recolored to red, so in next iteration we
// check if it does not break Red-Black property
currentNode = grandParent;
}
// case 2/3 uncle is black - then we perform rotations
else {
if (currentNode == parent.right) { // case 2, first rotate left
currentNode = parent;
rotateLeft(currentNode);
}
// do not use parent
parent.color = ColorEnum.BLACK; // case 3
grandParent.color = ColorEnum.RED;
rotateRight(grandParent);
}
} else if (parent == grandParent.right) {
RedBlackNode uncle = (RedBlackNode) grandParent.left;
// case1 - uncle and parent are both red
// re color both of them to black
if (((RedBlackNode) uncle).color == ColorEnum.RED) {
parent.color = ColorEnum.BLACK;
uncle.color = ColorEnum.BLACK;
grandParent.color = ColorEnum.RED;
// grandparent was recolored to red, so in next iteration we
// check if it does not break Red-Black property
currentNode = grandParent;
}
// case 2/3 uncle is black - then we perform rotations
else {
if (currentNode == parent.left) { // case 2, first rotate right
currentNode = parent;
rotateRight(currentNode);
}
// do not use parent
parent.color = ColorEnum.BLACK; // case 3
grandParent.color = ColorEnum.RED;
rotateLeft(grandParent);
}
}
}
// ensure root is black in case it was colored red in fixup
((RedBlackNode) root).color = ColorEnum.BLACK;
}
protected static class RedBlackNode extends Node {
public ColorEnum color;
public RedBlackNode(Integer value, Node parent, Node left, Node right, ColorEnum color) {
super(value, parent, left, right);
this.color = color;
}
}
}
