

前言
今天是中国传统佳节“猿宵节”,是程序猿通宵赶代码的佳节。
AI考拉的技术小伙伴志在打破传统,以“我们不加班”为口号,以“我们提早下班”为指导中心,在这里安利技术知识给大家,祝大家节日快乐,提前下班,过真正的元宵节!
需求
在金融业务系统里面,判断用户是否是黑名单,这种场景应该很常见。
假设我们系统里面有一百万个黑名单用户,用手机号表示,现在有一个人想借款,我们要判断他是否在黑名单中,怎么做?
一般方法
最直接的方法,是在数据库中查询,目前数据库上实现的索引,虽然可以做到 O(logn) 或者理论O(1) 的时间复杂度,但毕竟是磁盘操作,跟内存操作不是一个数量级的。
于是,我们可以把黑名单中的手机号缓存到内存中,用一个数组储存起来,这种方法有两个问题,一是查找时间复杂度是 O(n),非常慢,二是占用大量内存。
查找速度上可以再优化,将数组变成Set,内部实现可以选择平衡二叉树或者哈希,这样子插入和查找的时间复杂度能做到 O(logn)或者理论O(1),但是带来的是空间上的灾难,比使用数组会更占用空间。
现在来看一下代码,对比一下这两种方法:
import random
import sys
def generate_random_phone():
"""
随机生成11位的字符串
"""
phone = ''
for j in range(0, 11):
phone += str(random.randint(0, 9))
return phone
# 10万个黑名单用户
black_list = []
for i in range(0, 100000):
black_list.append(generate_random_phone())
# 转成集合
black_set = set(black_list)
print(len(black_list), len(black_set))
# 看一下两种数据结构的空间占用
print("size of black_list: %f M" % (sys.getsizeof(black_list) / 1024 / 1024))
print("size of black_set: %f M" % (sys.getsizeof(black_set) / 1024 / 1024))
def brute_force_find():
"""
直接列表线性查找,随机查一个存在或者不存在的元素, O(n)
"""
if random.randint(0, 10) % 2:
target = black_list[random.randint(0, len(black_list))]
return __brute_force_find(target)
else:
return __brute_force_find(generate_random_phone())
def __brute_force_find(target):
for i in range(0, len(black_list)):
if target == black_list[i]:
return True
return False
def set_find():
"""
集合查找,随机查一个存在或者不存在的元素, O(1)
"""
if random.randint(0, 10) % 2:
target = black_list[random.randint(0, len(black_list))]
return __set_find(target)
else:
return __set_find(generate_random_phone())
def __set_find(target):
return target in black_set
print(brute_force_find())
print(set_find())
可以看到,数组和集合的长度相等,说明元素都是唯一的。列表的空间占用为0.78M,而集合的空间占用为4M,主要是因为哈希表的数据结构需要较多指针连接冲突的元素,空间占用大概是列表的5倍。这是10w个手机号,如果有1亿个手机号,将需要占用3.9G的空间。
下面来看一下性能测试:
import timeit
print(timeit.repeat('brute_force_find()', number=100, setup="from __main__ import brute_force_find"))
print(timeit.repeat('set_find()', number=100, setup="from __main__ import set_find"))
[0.0016423738561570644, 0.0013590981252491474, 0.0014535998925566673]
可以看到,直接线性查询大概需要0.85s, 而集合的查询仅需要0.0016s,速度上是质的提升,但是空间占用太多了!
有没有一种数据结构,既可以做到集体查找的时间复杂度,又可以省空间呢?
答案是布隆过滤器,只是它有误判的可能性,当一个手机号经过布隆过滤器的查找,返回属于黑名单时,有一定概率,这个手机号实际上并不属于黑名单。 回到我们的业务中来,如果一个借款人有0.001%的概率被我们认为是黑名单而不借钱给他,其实是可以接受的,用风控的一句话说: 宁可错杀一百,也不放过一个。说明,利用布隆过滤器来解决这个问题是合适的。
布隆过滤器原理
原理非常简单,维护一个非常大的位图,设长度为m,选取k个哈希函数。
初始时,这个位图,所有元素都置为0。 对于黑名单中的每一个手机号,用k个哈希函数计算出来k个索引值,把位图中这k个位置都置为1。 当查询某个元素时,用k个哈希函数计算出来k个索引值,如果位图中k个位置的值都为1,说明这个元素可能存在,如果有一个位置不为1,则一定不存在。
这里的查询,说的可能存在,是因为哈希函数可能会出现冲突,一个不存在的元素,通过k个哈希函数计算出来索引,可能跟另外一个存在的元素相同,这个时间就出现了误判。所以,要降低误判率,明显是通过增大位图的长度和哈希函数的个数来实现的。
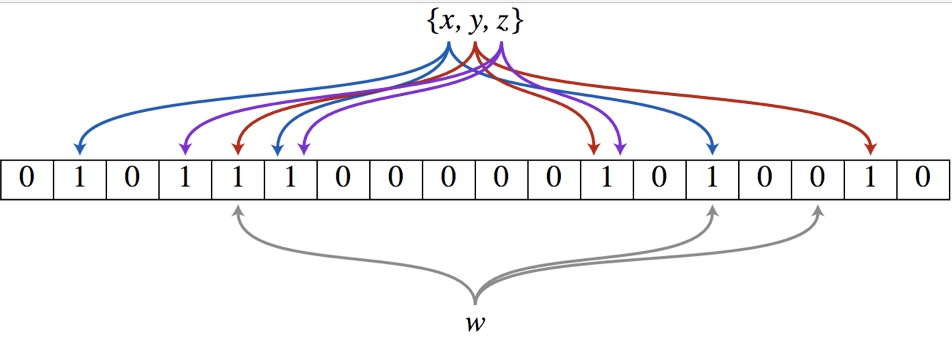
来看一下代码:
from bitarray import bitarray
import mmh3
class BloomFilter:
def __init__(self, arr):
# 位图长度暂定为20倍黑名单库的大小
self.SIZE = 20 * len(arr)
self.bit_array = bitarray(self.SIZE)
self.bit_array.setall(0)
for item in arr:
for pos in self.get_positions(item):
self.bit_array[pos] = 1
def get_positions(self, val):
# 使用10个哈希函数,murmurhash算法,返回索引值
return [mmh3.hash(val, i) % self.SIZE for i in range(40, 50)]
def find(self, val):
for pos in self.get_positions(val):
if self.bit_array[pos] == 0:
return False
return True
bloomFilter = BloomFilter(black_list)
print("size of bloomFilter's bit_array: %f M" % (sys.getsizeof(bloomFilter.bit_array) / 1024 / 1024))
def get_error_rate():
# 用1w个随机手机号,测试布隆过滤器的错误率
size = 10000
error_count = 0
for i in range(0, size):
phone = generate_random_phone()
bloom_filter_result = bloomFilter.find(phone)
set_result = __set_find(phone)
if bloom_filter_result != set_result:
error_count += 1
return error_count / size
print(get_error_rate())
size of bloomFilter's bit_array: 0.000092 M
0.0001
可以看到,虽然位图的长度是原数据的20倍,但是占用的空间却很小,这是因为位图的8个元素才占用1个字节,而原数据列表中1个元素就占用了将近11个字节。
错误率大约为0.0001,可以尝试不同的位图长度,比如改成30倍,错误率就会降低到0。
最后来看一下3种算法的性能测试:
def bloom_filter_find():
if random.randint(0, 10) % 2:
target = black_list[random.randint(0, len(black_list))]
return bloomFilter.find(target)
else:
return bloomFilter.find(generate_random_phone())
print(timeit.repeat('brute_force_find()', number=100, setup="from __main__ import brute_force_find"))
print(timeit.repeat('set_find()', number=100, setup="from __main__ import set_find"))
print(timeit.repeat('bloom_filter_find()', number=100, setup="from __main__ import bloom_filter_find"))
[0.70748823415488, 0.7686979519203305, 0.7785645266994834]
[0.001686999574303627, 0.002007704693824053, 0.0013333242386579514]
[0.001962156966328621, 0.0018132571130990982, 0.0023592300713062286]
可以看到,布隆过滤器的查找速度接近集合的查找速度,有时候甚至更快,在很低的误判率可以接受的情况下,选用布隆过滤器是即省时间又省空间的,是最佳的选择。
参考链接
著作权归本文作者所有,未经授权,请勿转载,谢谢。
