

前言
canal 是什么? 引用一下官方回答:
阿里巴巴mysql数据库binlog的增量订阅&消费组件
canal 能做什么?
基于日志增量订阅&消费支持的业务:
- 数据库镜像
- 数据库实时备份
- 多级索引 (卖家和买家各自分库索引)
- search build
- 业务cache刷新
- 价格变化等重要业务消息
比如 LZ 目前就使用 canal 实现数据实时复制,搜索引擎数据构建等功能。既然要使用,就好好的研究一下。
时间有限,一起来简单看看。
软件架构
关于 canla 的工作原理,我就不展开了,有兴趣的可以看看官方文档,或者这个 ppt : docs.google.com/presentatio…
说白了, canal 就是伪装成 mysql 的 slave,dump binlog,解析 binlog,然后传递给应用程序,总体还是蛮简单的。
好,我们来看看 canal 的代码架构。
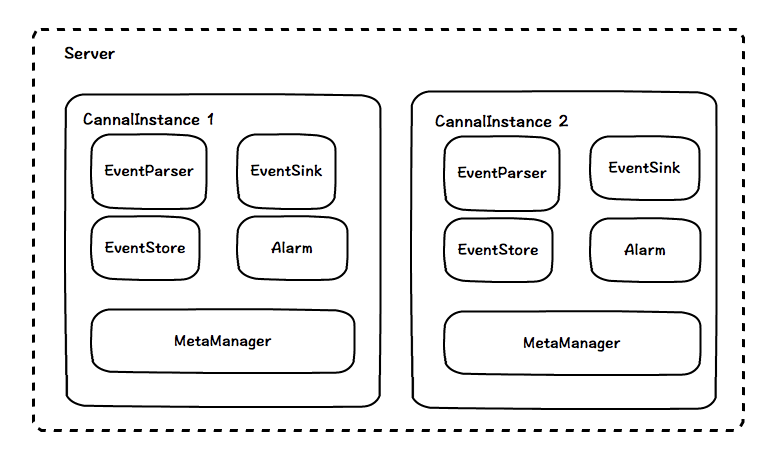
我们看到,canal server 内部由几个模块组成, 最外部的是 Server,该 Server 接收 Canal Client 请求,并返回 Client 数据。一个 Server 就是一个 JVM。每个 Server 内部由多个 CanalInstance,每个 CanalInstance 其实就是我们设置的 destination,通常是一个数据库。
每个 CanalInstance 内部由 5 个模块,分别是 parser 解析,sink 过滤,store 存储,metaManager 元数据管理,Alarm 报警。
这 5 个模块是干嘛的呢?
简单说一下:
当 Canal Server 启动后,会根据配置启动 N 个 CanalInstance, 每个 CanalInstance 都会使用 socket 连接 mysql,dump binlog,然后将数据交给 parser 解析,sink 过滤,store 存储,当 client 连接时,会从 zk 上读取该 client 的信息,而 metaManager 元数据管理就是管理 zk(当然有多种实现,比如存储在文件中) 信息的,如果发生错误了,就调用 Alarm 发送报警信息(你可以接入自己公司的监控系统),目前是打印日志。
Canal 启动流程
canal 代码量目前有 6 万多行,去除 2 个 ProtocolBuffer 生成类大概 1.7 万行,也还有 4.3 万行,代码还是不少的。
启动过程也比较绕。这里我简单画了一个流程图:
解释一下这个图:
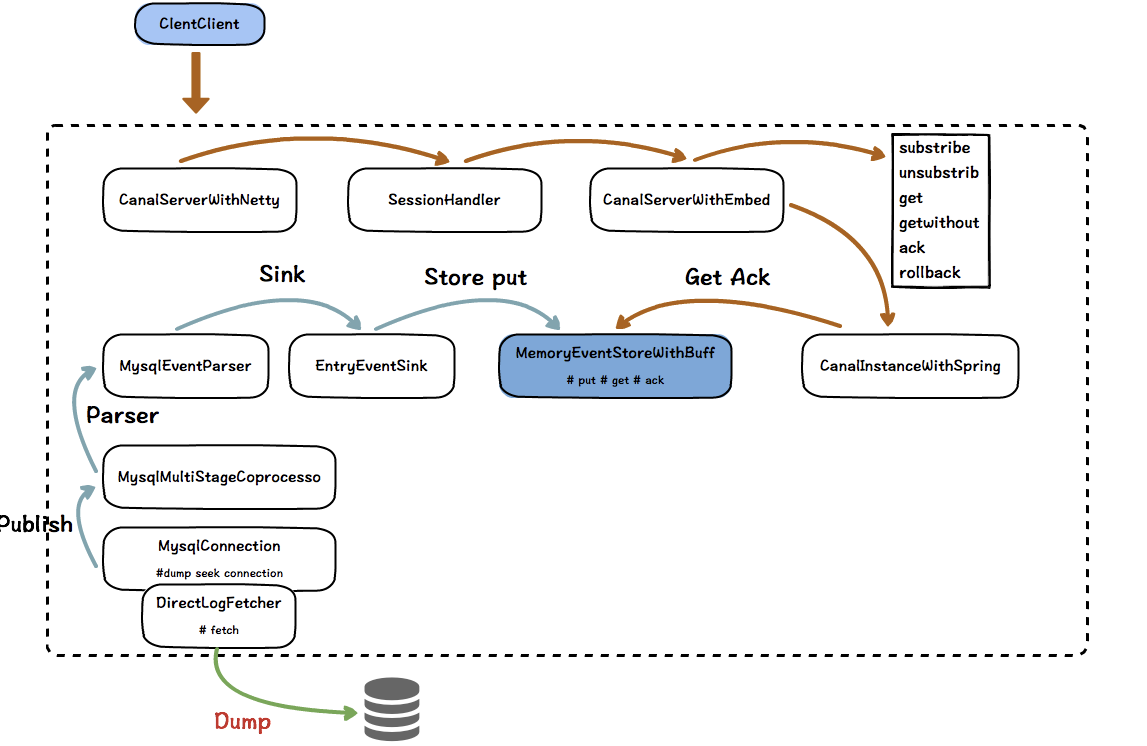
canal 脚本从 CanalLauncher main 方法启动,然后调用 CanalController 的 start 方法,CanalController 调用 InstanceConfigMonitor 的 start 方法,最后调用 canal 关键组件 CanalServerWithEmbedded 的 start 方法。
在 Canal 内部, 有 CanalServerWithEmbedded 和 CanalServerWithNetty,前者是没有 Server 端口的,是一个无端口的代理。后者是基于 Netty 实现的服务器,在 channelRead 方法中,会调用 CanalServerWithEmbedded 的相关方法。
CanalServerWithEmbedded 是单例的, 内部会有多个 CanalInstance, 他有多个实现,独立版本中使用的是 CanalInstanceWithSpring 版本,基于 Spring 管理组件的生命周期。
每个 CanalInstance 内部有 5 个组件,也就是上面说的几个组件,他们会分别启动。
其中,比较关键的是 parser,sink,store。
CanalEventParser 启动后,会启动一个叫做 parseThread 线程,不停的循环。主要是:构造与 mysql 的连接,然后启动心跳线程,然后开始 dump binlog。
dump 出来的 binlog 通过 disruptor 无锁队列发布,内部由 3 个消费者按照顺序消费 binlog,处理完之后,交给了 sink 模块。
然后是 sink,这个比较简单,就不说了。sink 处理完之后,交给了 store 模块。
store 模式是一个类似 RingBuffer 的循环数组,存储着从 mysql dump 出来的数据,client 也是从这里获取数据的。该数组维护着 3 个指针,get,put, ack。
这里比较奇怪的是,为什么不使用责任链模式够组装组件?
Canal 数据流向
看了启动流程,再来看看 canal 内部运行的数据流向是什么样子的。我这里简单画了一个图。
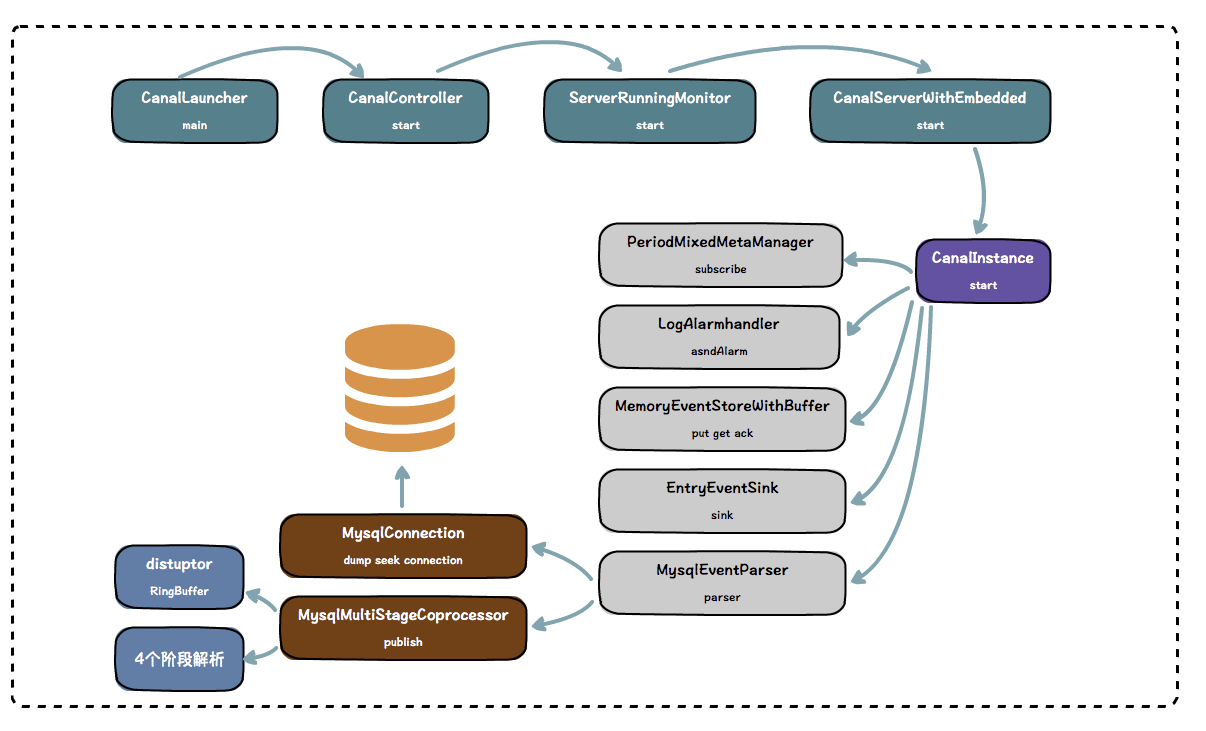
独立版本的 Canal 使用 Netty 暴露端口,使用自己构造的 SessionHandler 处理 TCP 请求,SessionHandler 将请求交给 CanalServerWithEmbedded 来处理。
我们看 CanalServerWithEmbedded 的一些方法,例如 subscribe,get,ack 等,都是和 client 对应的方法,也就是说,CanalServerWithEmbedded 是和 client 打交道的一个类。
CanalServerWithEmbedded 内部管理所有的 CanalInstance,通过 Client 的信息,找到 Client 订阅的 CanalInstance,然后调用 CanalInstance 内部的 Store 模块,也就是那个 RingBuffer 的 get 方法,获取 RingBuffer 的数据。
从 Myslq 的角度看,MysqlConnection 从 Myslq dump 数据,交给 parser 解析,parser 解析完,交给 sink,sink 处理完,交给 store 保存,等待 client 前来获取。
看完了数据流向,如果对哪里有什么疑问,就可以看看哪个模块对应的代码是什么,直接看是看就好了。
总结
花了点时间看了看 Canal 的代码,总体上还是非常好的,只是有些地方有点疑问,例如 parser,sink,store 为什么不使用过滤器模式。
Client 和 CanalServerWithEmbedded 为什么不使用 RPC 的方式交互,这样更简单明了。
代码里回调方法太多太长,影响阅读。
但总体瑕不掩瑜,值得一读。
