

从这篇文章开始,我会开始系统性地输出在大数据踩坑过程中的积累,后面会涉及到实战项目的具体操作,目前的规划是按照系列来更新,力争做到一个系列在5篇文章之内总结出最核心的干货,如果是涉及到理论方面的文章,会以画图的方式来讲解,如果是涉及到操作方面,会以实际的代码来演示。
这篇是MapReduce系列的第一篇,初识MapReduce的应用场景,在文章后面会有关于代码的演示。
前言
Hadoop作为Apache旗下的一个以Java语言实现的分布式计算开源框架,其由两个部分组成,一个是分布式的文件系统HDFS,另一个是批处理计算框架MapReduce。这篇文章作为MapReduce系列的第一篇文章,会从MapReduce的产生背景、框架的计算流程、应用场景和演示Demo来讲解,主要是让大家对MapReduce的这个批计算框架有个初步的了解及简单的部署和使用。
目录
MapReduce的产生背景
MapReduce的计算流程
MapReduce的框架架构
MapReduce的生命周期
应用场景
演示Demo
MapReduce的产生背景
Google 在2004年的时候在 MapReduce: Simplified Data Processing on Large Clusters 这篇论文中提出了MapReduce 的功能特性和设计理念,设计MapReduce 的出发点就是为了解决如何把大问题分解成独立的小问题,再并行解决。例如,MapReduce的经典使用场景之一就是对一篇长文进行词频统计,统计过程就是先把文章分为一句一句,然后进行分割,最后进行词的数量统计。
MapReduce的架构图
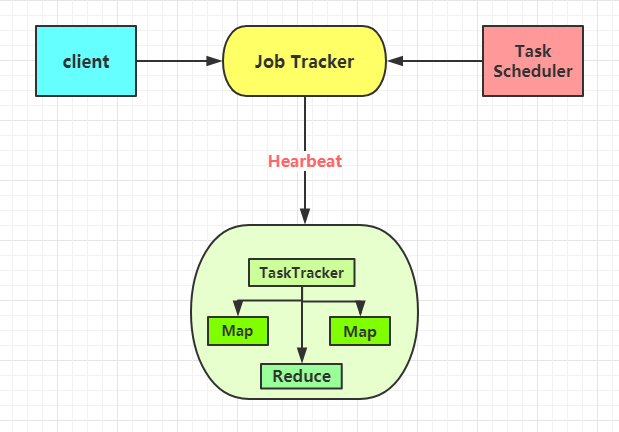
我们来讲解下不同的组件作用
Client
Client的含义是指用户使用MapReduce程序通过Client来提交任务到Job Tracker上,同时用户也可以使用Client来查看一些作业的运行状态。
Job Tracker
这个负责的是资源监控和作业调度。JobTracker会监控着TaskTracker和作业的健康状况,会把失败的任务转移到其他节点上,同时也监控着任务的执行进度、资源使用量等情况,会把这些消息通知任务调度器,而调度器会在资源空闲的时候选择合适的任务来使用这些资源。
任务调度器是一个可插拔的模块,用户可以根据自己的需要来设计相对应的调度器。
TaskTracker
TaskTracker会周期性地通过Hearbeat来向Job Tracker汇报自己的资源使用情况和任务的运行进度。会接受来自于JobTaskcker的指令来执行操作(例如启动新任务、杀死任务之类的)。
在TaskTracker中通过的是slot来进行等量划分一个节点上资源量,只用Task获得slot的时候才有机会去运行。调度器的作用就是进行将空闲的slot分配给Task使用,可以配置slot的数量来进行限定Task上的并发度。
Task
Task分为Map Task和Reduce Task,在MapReduce中的 split 就是一个 Map Task,split 的大小可以设置的,由 mapred.max.spilt.size 参数来设置,默认是 Hadoop中的block的大小,在Hadoop 2.x中默认是128M,在Hadoop 1.x中默认是64M。
在Task中的设置可以这么设置,一般来讲,会把一个文件设置为一个split,如果是小文件,那么就会存在很多的Map Task,这是特别浪费资源的,如果split切割的数据块的量大,那么会导致跨节点去获取数据,这样也是消耗很多的系统资源的。
MapReduce的生命周期
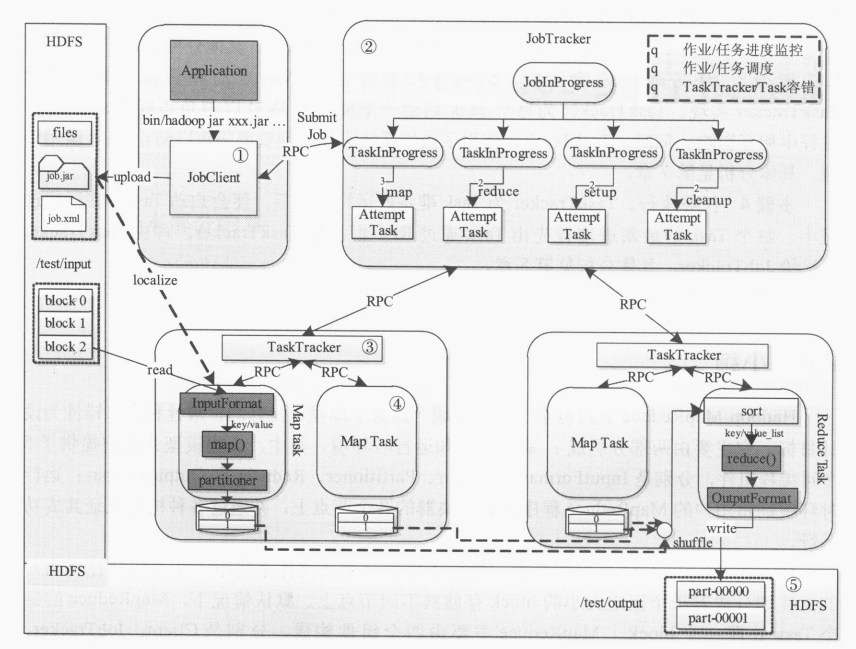
一共分为5个步骤:
- 作业的提交和初始化
由用户提交作业之前,需要先把文件上传到HDFS上,JobClient使用upload来加载关于打包好的jar包,JobClient会RPC创建一个JobInProcess来进行管理任务,并且创建一个TaskProcess来管理控制关于每一个Task。
- JobTracker调度任务
JobTracker会调度和管理任务,一发现有空闲资源,会按照一个策略选择一个合适的任务来使用该资源。
任务调度器有两个点:一个是保证作业的顺利运行,如果有失败的任务时,会转移计算任务,另一个是如果某一个Task的计算结果落后于同一个Task的计算结果时,会启动另一个Task来做计算,最后去计算结果最块的那个。
- 任务运行环境
TaskTracker会为每一个Task来准备一个独立的JVM从而避免不同的Task在运行过程中的一些影响,同时也使用了操作系统来实现资源隔离防止Task滥用资源。
- 执行任务
每个Task的任务进度通过RPC来汇报给TaskTracker,再由TaskTracker汇报给JobTracker。
- 任务结束,写入输出的文件到HDFS中。
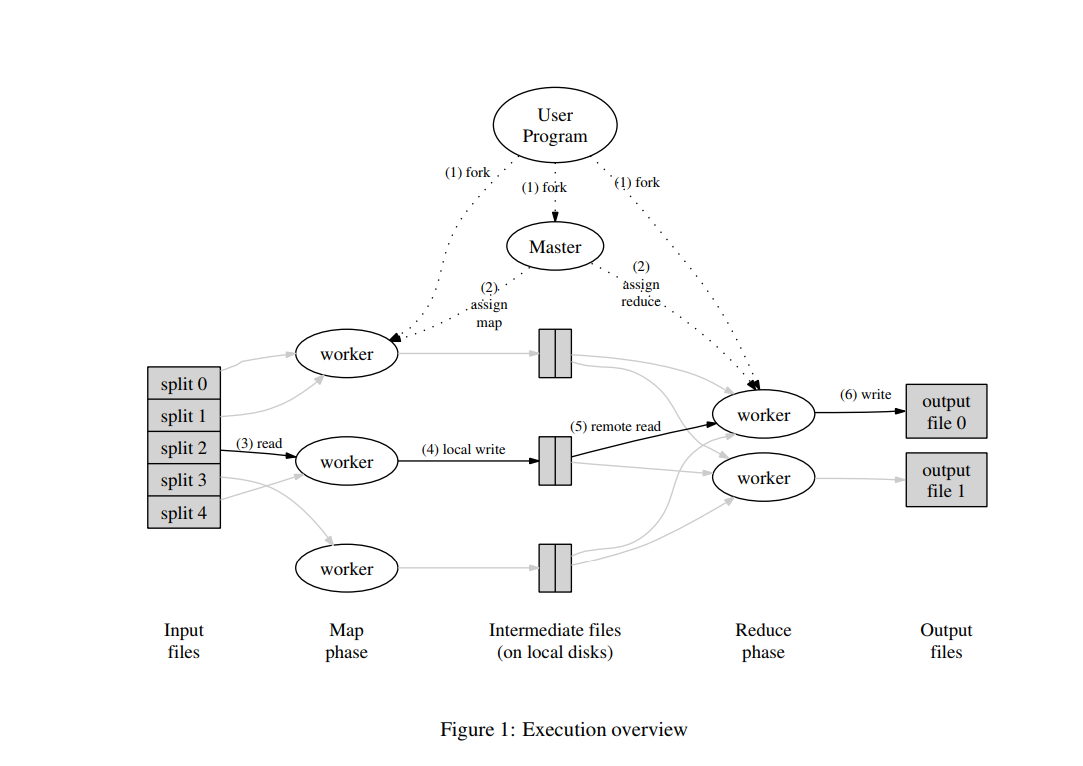
MapReduce 的计算流程
先来看一张图,系统地了解下 MapReduce 的运算流程。
为了方便大家理解,重新画了一张新的图,演示的是关于如何进行把一个长句进行分割,最后进行词频的统计(已忽略掉标点符号)。
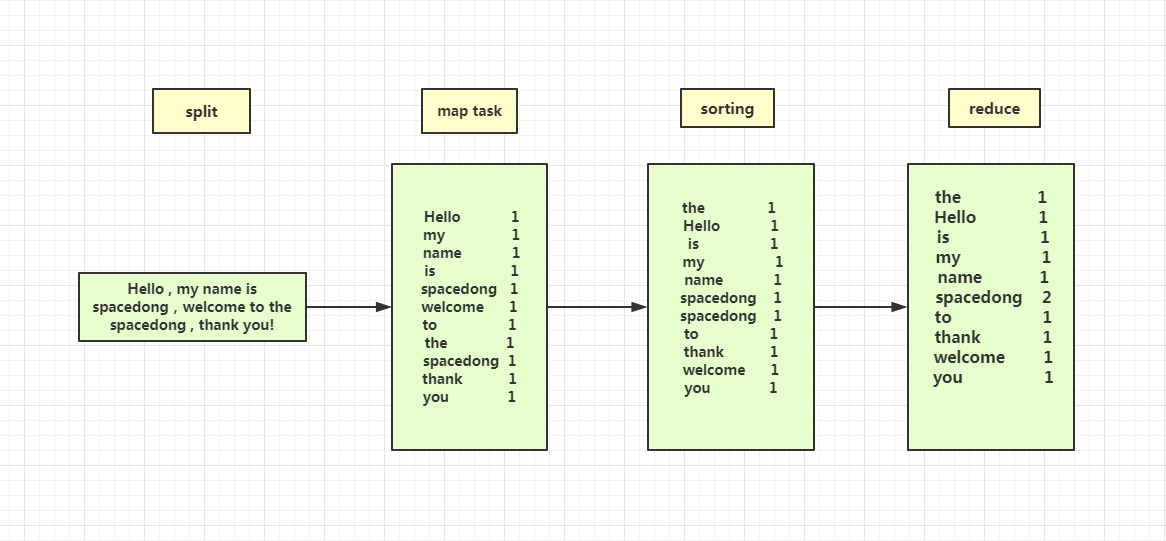
整个过程就是先读取文件,接着进行split切割,变成一个一个的词,然后进行 map task 任务,排列出所有词的统计量,接着 sorting 排序,按照字典序来排,接着就是进行 reduce task,进行了词频的汇总,最后一步就是输出为文件。例如图中的 spacedong 就出现了两次。
其中对应着的是 Hadoop Mapreduce 对外提供的五个可编程组件,分别是InputFormat、Mapper、Partitioner、Reduce和OutputFormat,后续的文章会详细讲解这几个组件。
用一句话简单地总结就是,Mapreduce的运算过程就是进行拆解-排序-汇总,解决的就是统计的问题,使用的思想就是分治的思想。
MapReduce的应用场景
MapReduce 的产生是为了把某些大的问题分解成小的问题,然后解决小问题后,大问题也就解决了。那么一般有什么样的场景会运用到这个呢?那可多了去,简单地列举几个经典的场景。
计算URL的访问频率
搜索引擎的使用中,会遇到大量的URL的访问,所以,可以使用 MapReduce 来进行统计,得出(URL,次数)结果,在后续的分析中可以使用。
倒排索引
Map 函数去分析文件格式是(词,文档号)的列表,Reduce 函数就分析这个(词,文档号),排序所有的文档号,输出(词,list(文档号)),这个就可以形成一个简单的倒排索引,是一种简单的算法跟踪词在文档中的位置。
Top K 问题
在各种的文档分析,或者是不同的场景中,经常会遇到关于 Top K 的问题,例如输出这篇文章的出现前5个最多的词汇。这个时候也可以使用 MapReduce来进行统计。
演示Demo
今天的代码演示从Python和Java两个版本的演示,Python版本的话便是不使用封装的包,Java版本的话则是使用了Hadoop的封装包。接下来便进行演示一个MapReduce的简单使用,如何进行词汇统计。
Java版本代码
- 先是准备一个数据集,包含着已经切割好的词汇,这里我们设置文件的格式是
txt格式的。文件名是WordMRDemo.txt,内容是下面简短的一句话,以空格分割开:
hello my name is spacedong welcome to the spacedong thank you
- 引入
Hadoop的依赖包
//这里使用的是2.6.5的依赖包,你可以使用其他版本的
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
- 新建
WordMapper.java文件,代码的作用是进行以空格的形式进行分词。
public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper.Context context)
throws java.io.IOException, InterruptedException {
String line = value.toString();
//StringTokenizer默认按照空格来切
StringTokenizer st = new StringTokenizer(line);
while (st.hasMoreTokens()) {
String world = st.nextToken();
//map输出
context.write(new Text(world), new IntWritable(1));
}
}
}
- 新建
WordReduce.java文件,作用是进行词汇的统计。
public class WordReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iterator, Context context)
throws java.io.IOException ,InterruptedException {
int sum = 0 ;
for(IntWritable i:iterator){
sum+=i.get();
}
context.write(key, new IntWritable(sum));
}
}
- 新建
WordMRDemo.java文件,作用是运行Job,开始分析句子。
public class WordMRDemo {
public static void main(String[] args) {
Configuration conf = new Configuration();
//设置mapper的配置,既就是hadoop/conf/mapred-site.xml的配置信息
conf.set("mapred.job.tracker", "hadoop:9000");
try {
//新建一个Job工作
Job job = new Job(conf);
//设置运行类
job.setJarByClass(WordMRDemo.class);
//设置要执行的mapper类
job.setMapperClass(WordMapper.class);
//设置要执行的reduce类
job.setReducerClass(WordReduce.class);
//设置输出key的类型
job.setMapOutputKeyClass(Text.class);
//设置输出value的类型
job.setMapOutputValueClass(IntWritable.class);
//设置ruduce任务的个数,默认个数为一个(一般reduce的个数越多效率越高)
//job.setNumReduceTasks(2);
//mapreduce 输入数据的文件/目录,注意,这里可以输入的是目录。
FileInputFormat.addInputPath(job, new Path("F:\\BigDataWorkPlace\\data\\input"));
//mapreduce 执行后输出的数据目录,不能预先存在,否则会报错。
FileOutputFormat.setOutputPath(job, new Path("F:\\BigDataWorkPlace\\data\\out"));
//执行完毕退出
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (Exception e) {
e.printStackTrace();
}
}
}
- 最后执行
WordMRDemo.java文件,然后得到的结果是out文件夹内的内容,它长这个样子: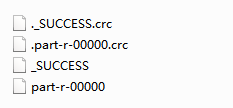
打开part-r-00000文件的内容如下
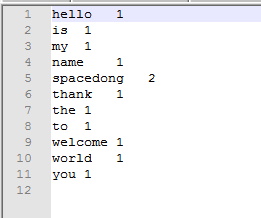
Python代码版本
- 新建
map.py文件,进行词汇的切割。
for line in sys.stdin:
time.sleep(1000)
ss = line.strip().split(' ')
for word in ss:
print '\t'.join([word.strip(), '1'])
- 新建
red.py文件,进行词汇的统计。
cur_word = None
sum = 0
for line in sys.stdin:
ss = line.strip().split('\t')
if len(ss) != 2:
continue
word, cnt = ss
if cur_word == None:
cur_word = word
if cur_word != word:
print '\t'.join([cur_word, str(sum)])
cur_word = word
sum = 0
sum += int(cnt)
print '\t'.join([cur_word, str(sum)])
- 新建
run.sh文件,直接运行即可。
HADOOP_CMD="/usr/local/src/hadoop-2.6.5/bin/hadoop"
STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.5/share/hadoop/tools/lib/hadoop-streaming-2.6.5.jar"
INPUT_FILE_PATH_1="/test.txt"
OUTPUT_PATH="/output"
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_PATH
# Step 1.
$HADOOP_CMD jar $STREAM_JAR_PATH \
-input $INPUT_FILE_PATH_1 \
-output $OUTPUT_PATH \
-mapper "python map.py" \
-reducer "python red.py" \
-file ./map.py \
-file ./red.py
以上的是演示demo的核心代码,完整的代码可以上github的代码仓库上获取。
仓库地址为:https://github.com/spacedong/bigDataNotes
以上的文章是MapReduce系列的第一篇,下篇预告是MapReduce的编程模型,敬请期待!
参考资料:
Hadoop的技术内幕:深入解析MapReduce架构设计及实现原理

