

问题描述
对于一个大型网站,用户访问量尝尝高达数十亿。对于数十亿是一个什么样的概念,我们这里可以简单的计算一下。对于一个用户,单次访问,我们通常会记录下哪些数据呢?
- 1、用户的id
- 2、用户访问的时间
- 3、用户逗留的时间
- 4、用户执行的操作
- 5、用户的其余数据(比如IP等等)
我们单单从用户id来说,比如10011802330414,这个ID,那么我们一个id差不多就是一个long类型,因为在大量数据存储的时候,我们都是采用文本存储。因此对于5亿个用户ID,完全存储在磁盘当中,大概是5G的大小,对于这个大小,并不能算是大数据。但是对于一个案例来说,已经非常足够了。
我们会产生一个5亿条ID的数据集,我们上面说到,这个数据集大小为5G(不压缩的情况下),因此我不会在GitHub上上传这样一个数据集,但是我们提供一个方法,来生成一个5亿条数据。
当然要解决这个问题,你可以依然在local模式下运行项目,但是你得有足够的磁盘空间和内存空间,大概8G磁盘空间(因为除了数据本身,spark运行过程还要产生一些临时数据),5G内存(要进行reduceByKey)。为了真正展示spark的特性,我们这个案例,将会运行在spark集群上。
关于如何搭建集群,我准备在后续的章节补上。但是在网上有大量的集群搭建教程,其中不乏一些详细优秀的教程。当然,这节我们不讲如何搭建集群,但是我们仍然可以开始我们的案例。
问题分析
那么现在我们拥有了一个5亿条数据(实际上这个数据并不以文本存储,而是在运行的时候生成),从五亿条数据中,找出访问次数最多的人,这看起来并不难。但实际上我们想要通过这个案例了解spark的真正优势。
5亿条ID数据,首先可以用map将其缓存到RDD中,然后对RDD进行reduceByKey,最后找出出现最多的ID。思路很简单,因此代码量也不会很多
实现
scala实现
首先是ID生成方法:
RandomId.class
import scala.Serializable;
public class RandomId implements Serializable {
private static final long twist(long u, long v) {
return (((u & 0x80000000L) | (v & 0x7fffffffL)) >> 1) ^ ((v & 1) == 1 ? 0x9908b0dfL : 0);
}
private long[] state= new long[624];
private int left = 1;
public RandomId() {
for (int j = 1; j < 624; j++) {
state[j] = (1812433253L * (state[j - 1] ^ (state[j - 1] >> 30)) + j);
state[j] &= 0xfffffffffL;
}
}
public void next_state() {
int p = 0;
left = 624;
for (int j = 228; --j > 0; p++)
state[p] = state[p+397] ^ twist(state[p], state[p + 1]);
for (int j=397;--j>0;p++)
state[p] = state[p-227] ^ twist(state[p], state[p + 1]);
state[p] = state[p-227] ^ twist(state[p], state[0]);
}
public long next() {
if (--left == 0) next_state();
return state[624-left];
}
}
然后是用它生成5亿条数据
import org.apache.spark.{SparkConf, SparkContext}
object ActiveVisitor {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("spark://master:7077").setAppName("ActiveVisitor")
val sc = new SparkContext(conf)
val list = 1 until 100000
val id =new RandomId()
var max = 0
var maxId = 0L
val lastNum = sc.parallelize(list).flatMap(num => {
var list2 = List(id.next())
for (i <- 1 to 50000){
list2 = id.next() :: list2
}
println(num +"%")
list2
}).map((_,1)).reduceByKey(_+_).foreach(x => {
if (x._2 > max){
max = x._2
maxId = x._1
println(x)
}
})
}
}
处理5亿条数据
import org.apache.spark.{SparkConf, SparkContext}
object ActiveVisitor {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("spark://master:7077").setAppName("ActiveVisitor")
val sc = new SparkContext(conf)
//生成一个0-9999的列表
val list = 1 until 10000
val id =new RandomId()
//这里记录最大的次数
var max = 0
//这里记录最大次数的ID
var maxId = 0L
val lastNum = sc.parallelize(list)
//第一步生成5亿条数据
.flatMap(num => {
//遍历list列表
//总共遍历1万次每次生成5万个ID
var list2 = List(id.next())
for (i <- 1 to 50000){
list2 = id.next() :: list2
}
//这里记录当前生成ID的百分比
println(num/1000.0 +"%")
//返回生成完成后的list
//每次循环里面都包含5万个ID
list2
})
//遍历5亿条数据
//为每条数据出现标记1
.map((_,1))
//对标记后的数据进行处理
//得到每个ID出现的次数,即(ID,Count)
.reduceByKey(_+_)
//遍历处理后的数据
.foreach(x => {
//将最大值存储在max中
if (x._2 > max){
max = x._2
maxId = x._1
//若X比之前记录的值大,则输出该id和次数
//最后一次输出结果,则是出现次数最多的的ID和以及其出现的次数
//当然出现次数最多的可能有多个ID
//这里只输出一个
println(x)
}
})
}
}
运行得到结果
将其提交到spark上运行,观察日志
1%
5000%
2%
5001%
3%
5002%
4%
5003%
5%
5004%
6%
5005%
7%
5006%
8%
5007%
9%
5008%
10%
5009%
11%
5010%
12%
5011%
5012%
13%
5013%
14%
15%
5014%
...
...
...

再看日志另一部分
5634%
5635%
5636%
5637%
5638%
5639%
5640%
5641%
5642%
5643%
5644%
5645%
2019-03-05 11:52:14 INFO ExternalSorter:54 - Thread 63 spilling in-memory map of 1007.3 MB to disk (2 times so far)
647%
648%
649%
650%
651%
652%
653%
654%
655%
656%
注意到这里,spilling in-memory map of 1007.3 MB to disk,spilling操作将map中的 1007.3 MB的数据溢写到磁盘中。这是由于spark在处理的过程中,由于数据量过于庞大,因此将多的数据溢写到磁盘,当再次用到时,会从磁盘读取。对于实时性操作的程序来说,多次、大量读写磁盘是绝对不被允许的。但是在处理大数据中,溢写到磁盘是非常常见的操作。
事实上,在完整的日志中,我们可以看到有相当一部分日志是在溢写磁盘的时候生成的,大概49次(这是我操作过程中的总数)
如图:
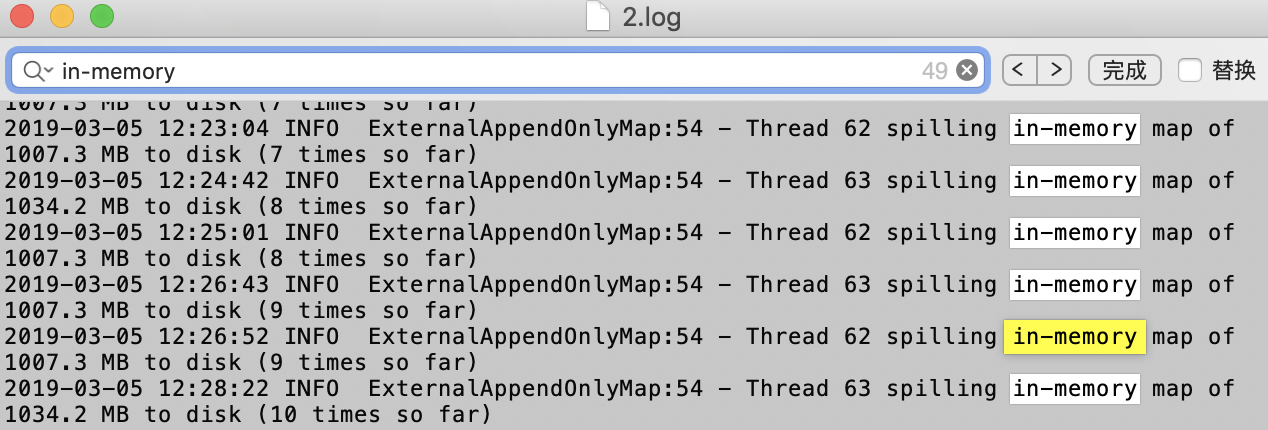
总共出现49条溢写操作的日志,每次大概是1G,这也印证了我们5亿条数据,占据空间5G的一个说法。事实上,我曾将这5亿条数据存储在磁盘中,的确其占据的空间是5G左右。
结果
最终,我们可以在日志中看到结果。
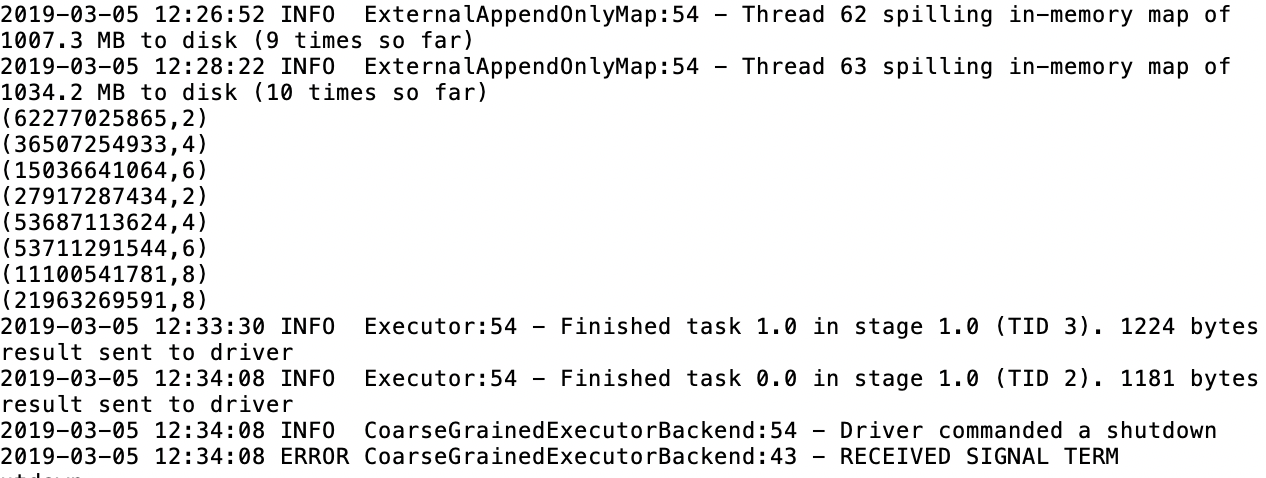
整个过程持续了将近47min,当然在庞大的集群中,时间能够大大缩短,要知道,我们现在只采用了4个节点。
我们看到了次数2、4、6、8居然分别出现了两次,这并不奇怪,因为集群并行运行,异步操作,出现重复结果十分正常,当然我们也可以用并发机制,去处理这个现象。这个在后续的案例中,我们会继续优化结果。
从结果上看,我们发现5亿条数据中,出现最多的ID也仅仅出现了8次,这说明了在大量数据中,很多ID可能只出现了1次、2次。这也就是为什么最后我采用的是foreach方法去寻找最大值,而不采用如下的方法
import org.apache.spark.{SparkConf, SparkContext}
object ActiveVisitor {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("spark://master:7077").setAppName("ActiveVisitor")
val sc = new SparkContext(conf)
//生成一个0-9999的列表
val list = 1 until 10000
val id =new RandomId()
//这里记录最大的次数
var max = 0
//这里记录最大次数的ID
var maxId = 0L
val lastNum = sc.parallelize(list)
//第一步生成5亿条数据
.flatMap(num => {
//遍历list列表
//总共遍历1万次每次生成5万个ID
var list2 = List(id.next())
for (i <- 1 to 50000){
list2 = id.next() :: list2
}
//这里记录当前生成ID的百分比
println(num/1000.0 +"%")
//返回生成完成后的list
//每次循环里面都包含5万个ID
list2
})
//遍历5亿条数据
//为每条数据出现标记1
.map((_,1))
//对标记后的数据进行处理
//得到每个ID出现的次数,即(ID,Count)
.reduceByKey(_+_)
//为数据进行排序
//倒序
.sortByKey(false)
//次数最多的,在第一个,将其输出
println(lastNum.first())
}
}
这个方法中,我们对reduceByKey结果进行排序,输出排序结果的第一个,即次数最大的ID。这样做似乎更符合我们的要求。但是实际上,为了得到同样的结果,这样做,会消耗更多的资源。如我们所说,很多ID启其实只出现了一次,两次,排序的过程中,仍然要对其进行排序。要知道,由于很多ID只出现一次,排序的数据集大小很有可能是数亿的条目。
根据我们对排序算法的了解,这样一个庞大数据集进行排序,势必要耗费大量资源。因此,我们能够容忍输出一些冗余信息,但不影响我们的得到正确结果。
至此,我们完成了5亿数据中,找出最多出现次数的数据。如果感兴趣,可以尝试用这个方法解决50亿条数据,出现最多的数据条目。但是这样做的话,你得准备好50G的空间。尽管用上述的程序,属于阅后即焚,但是50亿数据仍然会耗费大量的时间。
